



前言
在变量、数组和对象中存储的数据是暂时存在的,程序结束后它们就会丢失。为了能够永久地保存创建的数据,需要将其保存在磁盘文件中,这样就可以在其他程序中使用它们。Java的I/O技术可以将数据保存到文本文件、二进制文件甚至是ZIP压缩文件中,已达到永久性保存数据的要求。掌握I/O处理技术能够提高对数据的处理能力。
一、流概述
流是一组有序的数据序列,根据操作的类型,可分为输入流和输出流两种。I/O(Input/Output,输入/输出)流提供了一条通道程序,可以使用这条通道把源中的字节序列送到目的地。虽然I/O流通常与磁盘文件存取有关,但是程序的源和目的地也可以是键盘、鼠标、内存或显示器窗口等。
Java由数据流处理输入/输出模式,程序从指向源的输入流中读取源中的数据,源可以是文件、网络、压缩包或其他数据源。
输出流的指向是数据要到达的目的地,程序通过向输出流中写入数据把信息传递到目的地。
二、输入/输出流
Java语言定义了许多类专门负责各种方式的输入/输出,这类类都被放在java.io包中。其中,所有输入流类都是抽象类InputStream(字节输入流)或抽象类Reader(字符输入流)的子类;而所有输出流都是抽象类OutputStream(字节输出流)或抽象类Writer(字符输出流)的子类。
1、输入流
InputStream类是字节输入流的抽象类,是所有字节输入流的父类。InputStream类的具体层次结构如下所示。
该类中所有方法遇到错误时都会引发IOException异常。下面是对该类中的一些方法的简要说明。
read()方法:从输入流中读取数据的下一个字节。返回0-255范围内的int字节值。如果因为已经到达流末尾而没有可用的字节,则返回值为-1。
read(byte[] b):从输入流中读入一定长度的字节,并以整数的形式返回字节数。
mark(int readlimit)方法:在输入流的当前位置放置一个标记,readlimit参数告知此输入流在标记位置失效之前允许读取的字节数。
reset()方法:将输入指针返回到当前所做的标记处。
skip(long n)方法:跳过输入流上的n个字节并返回实际跳过的字节数。
markSupported()方法:如果当前流支持mark()/reset()操作就返回true。
close方法:关闭此输入流并释放与该流关联的所有系统资源。
Java中的字符是Unicode编码,是双字节的。InputStream是用来处理字节的,并不适合处理字符文本。Java为字符文本的输入专门提供了一套单独的类Reader,但Reader类并不是InputStream类的替换者,只是处理字符串时简化了编程。Reader类是字符输入流的抽象类,所有字符输入流的实现都是它的子类。
Reader类中的方法与InputStream类中的方法类似,读者在需要时可查看JDK文档。
2、输出流
OutputStream类是字节输出流的抽象类,此抽象类是表示输出字节流的所有类的超类。
OutputStream类中的所有方法均返回void,在遇到错误时会引发IoException异常。下面对OutputStream类中的方法作简单的介绍。
write(int b)方法:将指定的字节写入此输出流。
write(byte[] b)方法:将b个字节从指定的byte数组写入此输出流。
write(byte[] b,int off, int len)方法:将指定byte数组中从偏移量off开始的len个字节写入此输出流。
flush()方法:彻底完成输出并清空缓存区。
close()方法:关闭输出流。
三、File类
File类是java.io包中唯一代表磁盘文件本身的对象。File类定义了一些与平台无关的方法来操作文件,可以通过调用File类中的方法,实现创建、删除、重命名文件等操作。File类的对象主要用来获取文件本身的一些信息,如文件所在的目录、文件的长度、文件读写权限等。数据流可以将数据写入到文件中,文件也是数据流最常用的数据媒体。
1、文件的创建与删除
可以使用File类创建一个文件对象。通常使用以下3种构造方法来创建文件对象。
1、File(String pathname)
该构造方法通过将给定路径名字符串转换为抽象路径名来创建一个新File实例。
语法如下:
new File(String pathname);
其中,pathname指定路径名称(包含文件名)。例如:
File file = new File(“d:/1.txt”);
2、File(String parent,String child)
该构造方法根据定义的父路径和子路径字符串(包含文件名)创建一个新的File对象。
语法如下:
new File(String parent,String child);
3、File(File f,String child)
该构造方法根据Parent抽象路径名和child路径名字符串创建一个新的File实例。
语法如下:
new File(File f,String child);
2、获取文件信息
File类提供了很多方法用于获取一些文件本身的信息。如下表
方法| 返回值 | 说明
-------- | -----
getName() | String| 获取文件的名称
canReda()| boolean |判断文件是否为可读的
canWrite()| boolean | 判断文件是否可被写入
exits()|boolean | 判断文件是否存在
length()|long | 获取文件的长度(以字节为单位)
getAbsolutePath() | String | 获取文件的绝对路径
getParent() | String | 获取文件的父路径
isFile() | boolean | 判断文件是否存在
isDirectory() | boolean | 判断文件是否为一个目录
isHidden() | boolean | 判断文件是否为隐藏文件
lastModified() | long | 获取文件最后修改时间
四、文件输入/输出流
程序运行期间,大部分数据都在内存中进行操作,当程序结束或关闭时,这些数据将消失。如果需要将数据永久保存,可使用文件输入/输出流与指定的文件建立连接,将需要的数据永久保存到文件中。
1、FillInputStream与FileOutputStream类
FileInputStream类与FileOUtputStream类都用来操作磁盘文件。如果用户的文件读取需求比较简单,则可以使用FileInputString类,该类继承自InputString类。FileOutputStream类与FileInputStream类对应,提供了基本的文件写入能力。FileOutputStream类是OutputStream类的子类。
FileInputStream类常用的构造方法如下:
FileInputStream(String name)
FileInputStream(File file)
2、FileReader和FileWriter类
使用FileOutputStream类向文件中写入数据与使用FileInputStream类从文件中将内容读出来,都存在一点不足,即这两个类都只提供了对字节或字节数组的读取方法。由于汉子在文件中占用两个字节,如果使用字节流,读取不好可能会出现乱码现象,此时采用字符流Reader或Writer类即可避免这种现象。
FileReader和FileWriter字符流对应了FileInputStream和FileOutputStream类。FileReader流顺序地读取文件,只要不关闭流,每次调用read()方法就顺序地读取源中其余的内容,直到源的末尾或流被关闭。
五、带缓存的输入/输出流
缓存是I/O的一种性能优化。缓存流为I/O流增加了内存缓存区。有了缓存区,使得在流上执行skip()、mark()和reset()方法都成为可能。
1、BufferedInputStream与BufferedOutputStream类
BufferedInputStream类可以对所有InputStream类进行带缓冲区的包装以达到性能的优化。BufferedInputStream类有两个构造方法:
BufferedInputStream(InputStream in)
BufferedInputStream(InputStream in,int size)
第一种构造方法创建一个有32个字节的缓存区,第二种构造方法以指定的大小来创建缓存区。
2、BufferedReader与BufferedWriter类
BufferedReader类与BufferedWriter类分别继承Reader类与Writer类。这两个类同样具有内部缓存机制,并可以以行为单位进行输入/输出。
六、数据输入/输出流
数据输入/输出流(DataInputStream类与DataOutputStream类)允许应用程序以与机器无关的方式从底层输入流中读取基本Java数据类型。也就是说,当读取一个数据时,不必再关心这个数值应当是哪种字节。
七、ZIP压缩输入/输出流
ZIP压缩管理文件(ZIP archive)是一种十分典型的文件压缩形式,使用它可以节省存储空间。关于ZIP压缩的I/O实现,在Java的内置类中提供了非常好用的相关类,所以其实现方式非常简单。本节将介绍使用java.util.zip包中的ZipOutputStream与ZipInputStream类来实现文件的压缩/解压缩。如要从ZIP压缩管理文件内读取某个文件,要先找到对应文件的“目录进入点”(从它可知该文件在ZIP文件内的位置),才能读取这个文件的内容。如果要将文件内容写入ZIP文件内,必须先写入对应于该文件的“目录进入点”,并且把要写入文件内容的位置移到此进入点所指的位置,然后再写入文件内容。
Java实现了I/O数据流与网络数据流的单一接口,因此数据的压缩、网络传输和解压缩的实现比较容易。ZipEntry类产生的对象,是用来代表一个ZIP压缩文件内的进入点(entry)。ZipInputStream用来写出ZIP压缩格式的文件,所支持的包括已压缩及未压缩的进入点(entry)。
ZipOutputStream类用来写出ZIp压缩格式的文件,而且所支持的包括已压缩及未压缩的进入点(entry)。下面介绍利用ZipEntry、
ZipInputStream和ZipOutputStream3个Java类实现ZIP数据压缩方式的编程方法。
1、压缩文件
利用ZipOutputStream类对象,可将文件压缩为.zip文件。ZipOutputStream类的构造方法如下:
ZipOutputStram(OutputStream out);
ZipOutputStream类的常用方法如表所示:
| 方法 | 返回值 | 说明 |
|---|---|---|
| putNextEntry(ZipEntry e) | void | 开始写一个新的ZipEntry,并将流内的位置移至此entry所指数据的开头 |
| write(byte[] b,int off,int len) | void | 将字节数组写入当前ZIP条目数据 |
| finish() | void | 完成写入ZIP输出流的内容,无须关闭它所配合的OutputStream |
| setComment(String comment) | void | 可设置此ZIP文件的注释文字 |
2、解压缩ZIP文件
ZipInputStream类可读取ZIP压缩格式的文件,包括已压缩和未压缩的条目(entry)。ZipInputStream类的构造方法如下:
ZipInputStream(InputStream in)
ZipInputStream类的常用方法如下表所示:
| 方法 | 返回值 | 说明 |
|---|---|---|
| read(byte[] b, int off , int len) | int | 读取目标b数组内off偏移量的位置,长度是len字节 |
| available() | int | 判断是否已读完目前entry所指定的数据。已读完返回0,否则返回1 |
| closeEntry() | void | 关闭当前ZIP条目并定位流以读取下一个条目 |
| skip(long n) | long | 跳过当前ZIP条目中指定的字节数 |
| getNextEntry() | ZipEntry | 读取下一个ZipEntry,并将流内的位置移至该entry所指数据的开头 |
| createZipEntry(String name) | ZipEntry | 以指定的name参数新建一个ZipEntry对象 |
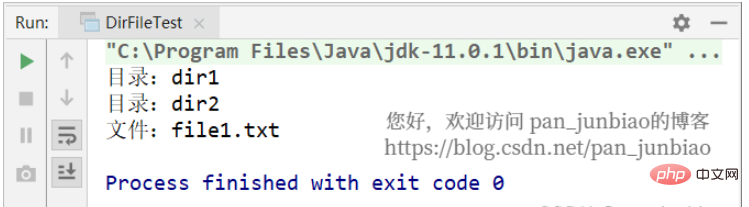
补充:获取目录下的所有目录和文件
示例:假设目录“D:\TestDir1”下有两个文件夹(dir1 和 dir2)和一个文件 file1.txt 。
File[] listFiles()方法:获取该目录下的所有子目录和文件,返回File类数组。
import java.io.File;
/**
* 获取目录下的所有目录和文件
* @author pan_junbiao
**/
public class DirFileTest
{
public static void main(String[] args)
{
File file = new File("D:\\TestDir1");
//判断目录是否存在
if (!file.exists())
{
System.out.println("目录不存在");
return;
}
//获取文件数组
File[] fileList = file.listFiles();
for (int i = 0; i < fileList.length; i++)
{
//判断是否为目录
if (fileList[i].isDirectory())
{
System.out.println("目录:" + fileList[i].getName());
}
else
{
System.out.println("文件:" + fileList[i].getName());
}
}
}
}执行结果:
以上是Java中I/O输入输出实例分析的详细内容。更多信息请关注PHP中文网其他相关文章!

 是否有任何威胁或增强Java平台独立性的新兴技术?Apr 24, 2025 am 12:11 AM
是否有任何威胁或增强Java平台独立性的新兴技术?Apr 24, 2025 am 12:11 AM新兴技术对Java的平台独立性既有威胁也有增强。1)云计算和容器化技术如Docker增强了Java的平台独立性,但需要优化以适应不同云环境。2)WebAssembly通过GraalVM编译Java代码,扩展了其平台独立性,但需与其他语言竞争性能。
 JVM的实现是什么,它们都提供了相同的平台独立性?Apr 24, 2025 am 12:10 AM
JVM的实现是什么,它们都提供了相同的平台独立性?Apr 24, 2025 am 12:10 AM不同JVM实现都能提供平台独立性,但表现略有不同。1.OracleHotSpot和OpenJDKJVM在平台独立性上表现相似,但OpenJDK可能需额外配置。2.IBMJ9JVM在特定操作系统上表现优化。3.GraalVM支持多语言,需额外配置。4.AzulZingJVM需特定平台调整。
 平台独立性如何降低发展成本和时间?Apr 24, 2025 am 12:08 AM
平台独立性如何降低发展成本和时间?Apr 24, 2025 am 12:08 AM平台独立性通过在多种操作系统上运行同一套代码,降低开发成本和缩短开发时间。具体表现为:1.减少开发时间,只需维护一套代码;2.降低维护成本,统一测试流程;3.快速迭代和团队协作,简化部署过程。
 Java的平台独立性如何促进代码重用?Apr 24, 2025 am 12:05 AM
Java的平台独立性如何促进代码重用?Apr 24, 2025 am 12:05 AMJava'splatformindependencefacilitatescodereusebyallowingbytecodetorunonanyplatformwithaJVM.1)Developerscanwritecodeonceforconsistentbehavioracrossplatforms.2)Maintenanceisreducedascodedoesn'tneedrewriting.3)Librariesandframeworkscanbesharedacrossproj
 您如何在Java应用程序中对平台特定问题进行故障排除?Apr 24, 2025 am 12:04 AM
您如何在Java应用程序中对平台特定问题进行故障排除?Apr 24, 2025 am 12:04 AM要解决Java应用程序中的平台特定问题,可以采取以下步骤:1.使用Java的System类查看系统属性以了解运行环境。2.利用File类或java.nio.file包处理文件路径。3.根据操作系统条件加载本地库。4.使用VisualVM或JProfiler优化跨平台性能。5.通过Docker容器化确保测试环境与生产环境一致。6.利用GitHubActions在多个平台上进行自动化测试。这些方法有助于有效地解决Java应用程序中的平台特定问题。
 JVM中的类加载程序子系统如何促进平台独立性?Apr 23, 2025 am 12:14 AM
JVM中的类加载程序子系统如何促进平台独立性?Apr 23, 2025 am 12:14 AM类加载器通过统一的类文件格式、动态加载、双亲委派模型和平台无关的字节码,确保Java程序在不同平台上的一致性和兼容性,实现平台独立性。
 Java编译器会产生特定于平台的代码吗?解释。Apr 23, 2025 am 12:09 AM
Java编译器会产生特定于平台的代码吗?解释。Apr 23, 2025 am 12:09 AMJava编译器生成的代码是平台无关的,但最终执行的代码是平台特定的。1.Java源代码编译成平台无关的字节码。2.JVM将字节码转换为特定平台的机器码,确保跨平台运行但性能可能不同。
 JVM如何处理不同操作系统的多线程?Apr 23, 2025 am 12:07 AM
JVM如何处理不同操作系统的多线程?Apr 23, 2025 am 12:07 AM多线程在现代编程中重要,因为它能提高程序的响应性和资源利用率,并处理复杂的并发任务。JVM通过线程映射、调度机制和同步锁机制,在不同操作系统上确保多线程的一致性和高效性。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

记事本++7.3.1
好用且免费的代码编辑器

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

