
彻底解决ChatGPT健忘症!突破Transformer输入限制:实测支持200万个有效token

- 王林转载
- 2023-05-13 14:07:062127浏览
ChatGPT,或者说Transformer类的模型都有一个致命缺陷,就是太容易健忘,一旦输入序列的token超过上下文窗口阈值,后续输出的内容和前文逻辑就对不上了。
ChatGPT只能支持4000个token(约3000个词)的输入,即便最新发布的GPT-4也只支持最大32000的token窗口,如果继续加大输入序列长度,计算复杂度也会成二次方增长。
最近来自DeepPavlov, AIRI, 伦敦数学科学研究所的研究人员发布了一篇技术报告,使用循环记忆Transformer(RMT)将BERT的有效上下文长度提升到「前所未有的200万tokens」,同时保持了很高的记忆检索准确性。
论文链接:https://www.php.cn/link/459ad054a6417248a1166b30f6393301
该方法可以存储和处理局部和全局信息,并通过使用循环让信息在输入序列的各segment之间流动。
实验部分证明了该方法的有效性,在增强自然语言理解和生成任务中的长期依赖处理方面具有非凡的潜力,可以为记忆密集型应用程序实现大规模上下文处理。
不过天下没有免费的午餐,虽然RMT可以不增加内存消耗,可以扩展到近乎无限的序列长度,但仍然存在RNN中的记忆衰减问题,并且需要更长的推理时间。

但也有网友提出了解决方案,RMT用于长期记忆,大上下文用于短期记忆,然后在夜间/维修期间进行模型训练。
循环记忆Transformer
2022年,该团队提出循环记忆Transformer(RMT)模型,通过在输入或输出序列中添加一个特殊的memory token,然后对模型进行训练以控制记忆操作和序列表征处理,能够在不改变原始Transformer模型的前提下,实现一个全新的记忆机制。

论文链接:https://arxiv.org/abs/2207.06881
发表会议:NeurIPS 2022
与Transformer-XL相比,RMT需要的内存更少,并可以处理更长序列的任务。
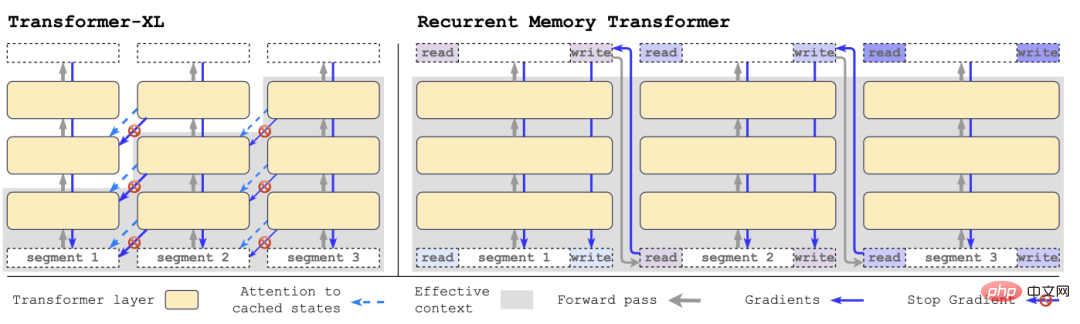
具体来说,RMT由m个实值的可训练向量组成,过长的输入序列被切分为几个segments,记忆向量被预置到第一个segment embedding中,并与segment token一起处理。
与2022年提出的原始RMT模型不同的是,对于像BERT这样的纯编码器模型,只在segment的开始部分添加一次记忆;解码模型将记忆分成读和写两部分。
在每个时间步长和segment中,按以下方式进行循环,其中N为Transformer的层数,t为时间步,H为segment
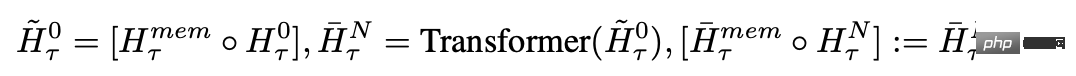
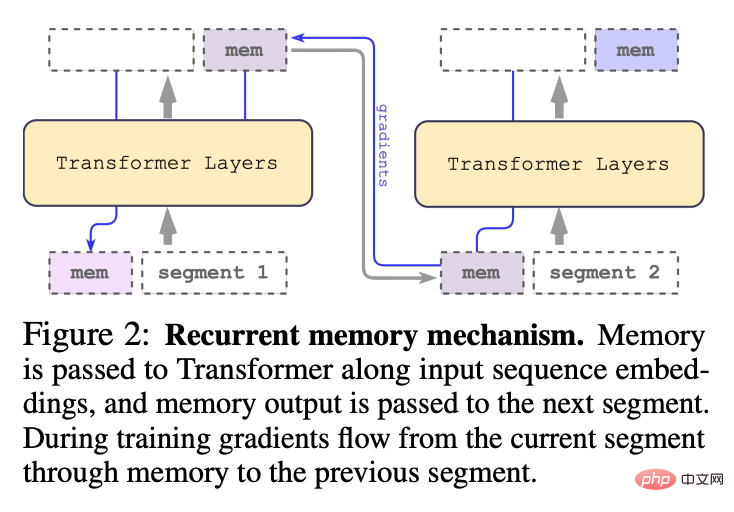
按顺序处理输入序列的segments后,为了实现递归连接,研究人员将当前segment的memory token的输出传递给下一个segment的输入:
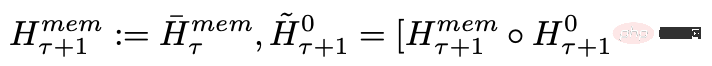
RMT中的记忆和循环都只基于全局memory token,可以保持骨干Transformer模型不变,使得RMT的记忆增强能力可以与任意的Transformer模型兼容。
计算效率
按照公式可以估算不同大小和序列长度的RMT和Transformer模型所需的FLOPs
在词汇量大小、层数、隐藏大小、中间隐藏大小和注意头数的参数配置上,研究人员遵循OPT模型的配置,并计算了前向传递后的FLOPs数量,同时考虑到RMT循环的影响。
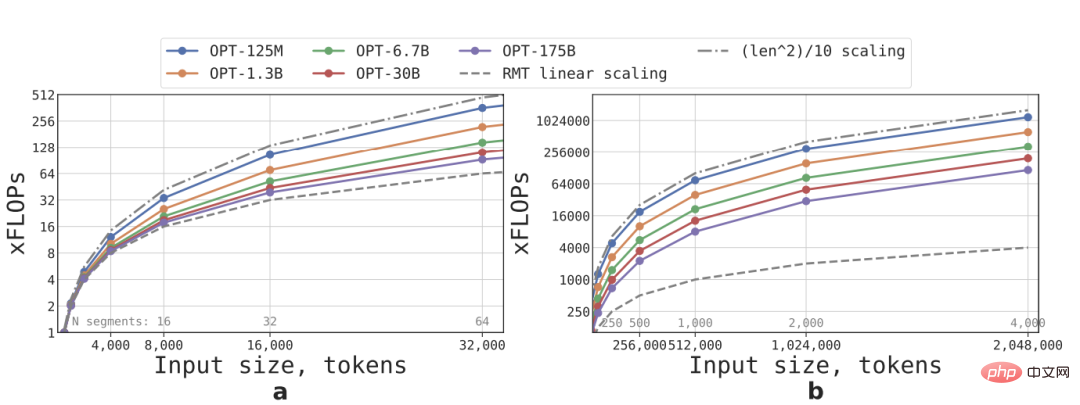
通过将一个输入序列划分为若干段,并仅在segment的边界内计算全部注意力矩阵来实现线性扩展,结果可以看到,如果segment长度固定,RMT的推理速度对任意模型尺寸都是线性增长的。
由于FFN层的计算量较大,所以较大的Transformer模型往往表现出相对于序列长度较慢的二次方增长速度,不过在长度大于32,000的极长序列上,FLOPs又回到了二次增长的状态。
对于有一个以上segment的序列(在本研究中大于512),RMT比非循环模型有更低的FLOPs,在尺寸较小的模型上最多可以将FLOPs的效率提升×295倍;在尺寸较大的模型如OPT-175B,可以提升×29倍。
记忆任务
为了测试记忆能力,研究人员构建了一个合成数据集,要求模型记忆简单的事实和基本推理。
任务输入包括一个或几个事实和一个只能用所有这些事实来回答的问题。
为了增加任务的难度,任务中还添加了与问题或答案无关的自然语言文本,这些文本可以看作是噪音,所以模型的任务实际上是将事实与不相关的文本分开,并使用事实文本来回答问题。

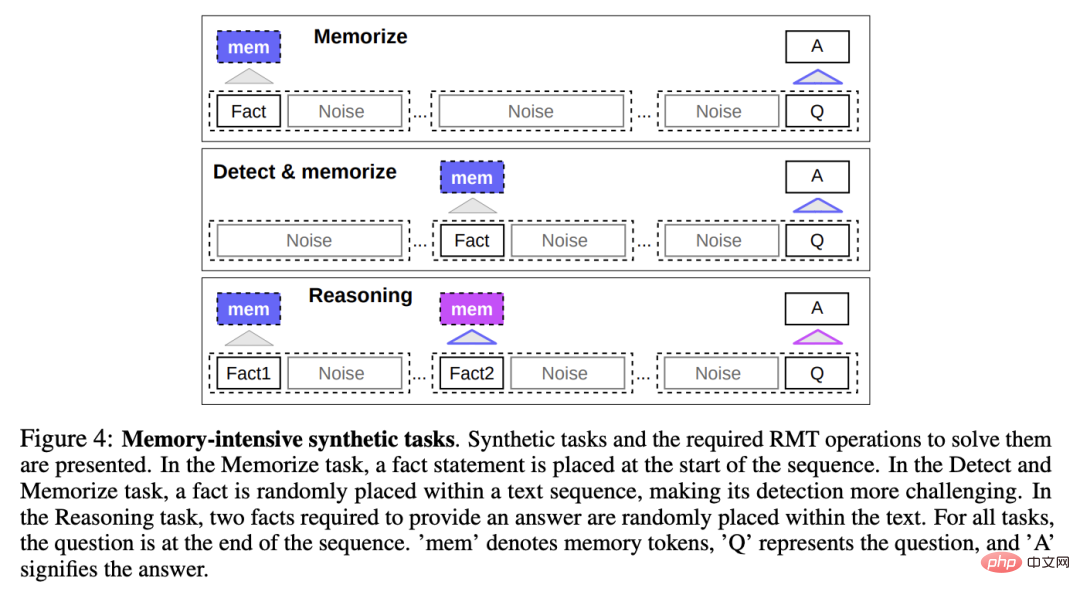
事实记忆
测试RMT在记忆中长时间写入和存储信息的能力:在最简单的情况下,事实位于输入的开头,问题在输入的最后,并逐渐增加问题和答案之间的不相关文本数量,直到模型无法一次性接受所有输入。

事实检测和记忆
事实检测通过将事实移到输入中的一个随机位置来增加任务难度,要求模型首先将事实与不相关的文本区分开来,将其写入记忆,然后回答位于最后的问题。
基于记忆事实进行推理
记忆的另一个重要操作是利用记忆的事实和当前的背景进行推理。
为了评估这个功能,研究人员引入了一个更复杂的任务,将生成两个事实并随机地放置在输入序列;在序列末尾提出的问题是必须选择用正确的事实来回答问题。

实验结果
研究人员使用HuggingFace Transformers中预训练的Bert-base-cased模型作为所有实验中RMT的主干,所有模型以记忆大小为10进行增强。
在4-8块英伟达1080Ti GPU上进行训练和评估;对于更长的序列,则切换到单张40GB的英伟达A100上进行加速评估。
课程学习(Curriculum Learning)
研究人员观察到,使用训练调度可以显著改善解决方案的准确性和稳定性。
刚开始让RMT在较短的任务版本上进行训练,在训练收敛后,通过增加一个segment来增加任务长度,将课程学习过程一直持续到达到理想的输入长度。
从适合单个segment的序列开始实验,实际segment的大小为499,因为从模型输入中保留了3个BERT的特殊标记和10个记忆占位符,总共大小为512。
可以注意到,在对较短的任务进行训练后,RMT更容易解决较长的任务,因为使用较少的训练步骤就能收敛到完美的解决方案。
外推能力(Extrapolation Abilities)
为了观察RMT对不同序列长度的泛化能力,研究人员评估了在不同数量的segment上训练的模型,以解决更大长度的任务。
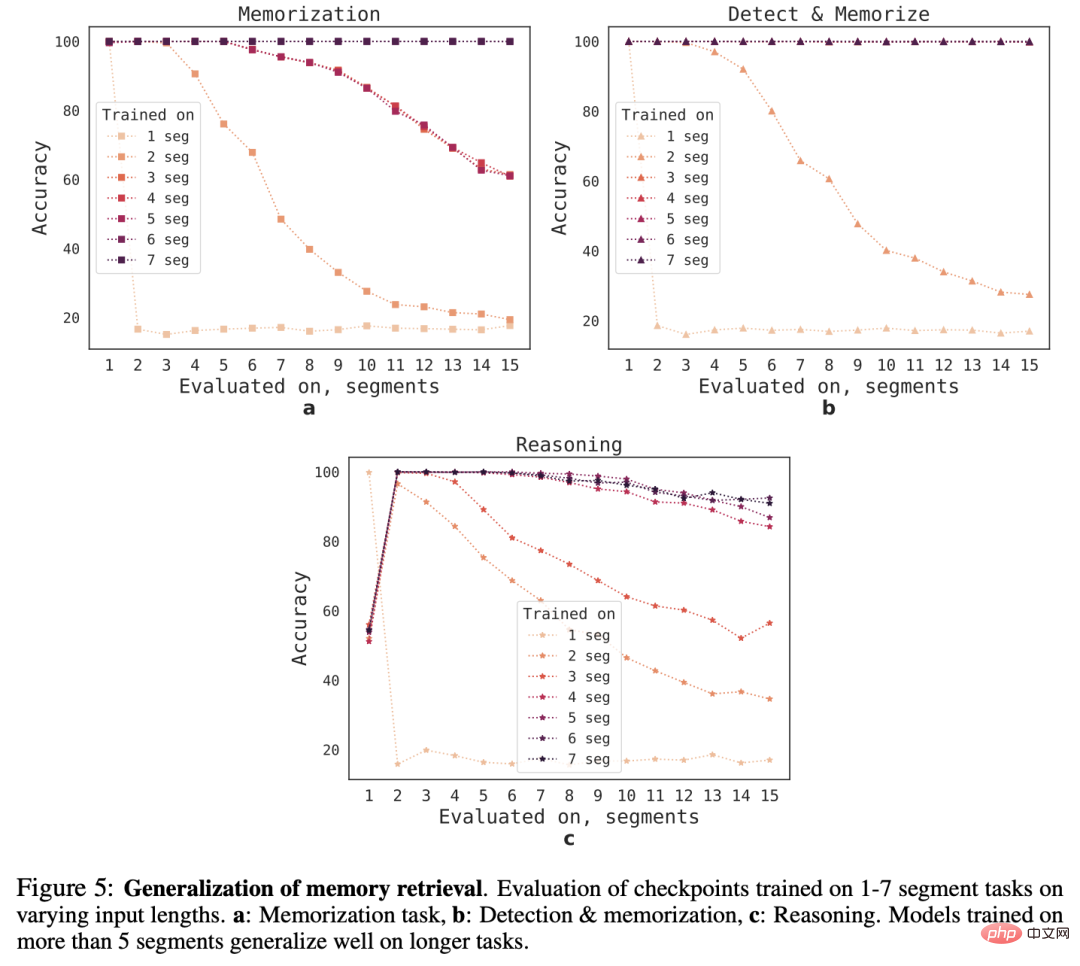
可以观察到,模型在较短的任务上往往表现良好,但在较长的序列上训练模型后,就很难处理单segment推理任务。
一个可能的解释是,由于任务规模超过了一个segment,模型在第一个segment就停止了对问题的预期,导致质量下降。
有趣的是,随着训练segment数量的增加,RMT对较长序列的泛化能力也出现了,在对5个或更多的segment进行训练后,RMT可以对两倍长的任务进行近乎完美的泛化。
为了测试泛化的极限,研究人员验证任务的规模增加到4096个segment(即2,043,904个tokens)。
RMT在如此长的序列上保持得出奇的好,其中「检测和记忆」任务是最简单的,推理任务是最复杂的。
参考资料:https://www.php.cn/link/459ad054a6417248a1166b30f6393301
以上是彻底解决ChatGPT健忘症!突破Transformer输入限制:实测支持200万个有效token的详细内容。更多信息请关注PHP中文网其他相关文章!