



spring-kafka 是基于 java版的 kafka client与spring的集成,提供了 KafkaTemplate,封装了各种方法,方便操作,它封装了apache的kafka-client,不需要再导入client依赖
<!-- kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>YML配置
kafka:
#bootstrap-servers: server1:9092,server2:9093 #kafka开发地址,
#生产者配置
producer:
# Kafka提供的序列化和反序列化类
key-serializer: org.apache.kafka.common.serialization.StringSerializer #序列化
value-serializer: org.apache.kafka.common.serialization.StringSerializer
retries: 1 # 消息发送重试次数
#acks = 0:设置成 表示 producer 完全不理睬 leader broker 端的处理结果。此时producer 发送消息后立即开启下 条消息的发送,根本不等待 leader broker 端返回结果
#acks= all 或者-1 :表示当发送消息时, leader broker 不仅会将消息写入本地日志,同时还会等待所有其他副本都成功写入它们各自的本地日志后,才发送响应结果给,消息安全但是吞吐量会比较低。
#acks = 1:默认的参数值。 producer 发送消息后 leader broker 仅将该消息写入本地日志,然后便发送响应结果给producer ,而无须等待其他副本写入该消息。折中方案,只要leader一直活着消息就不会丢失,同时也保证了吞吐量
acks: 1 #应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
batch-size: 16384 #批量大小
properties:
linger:
ms: 0 #提交延迟
buffer-memory: 33554432 # 生产端缓冲区大小
# 消费者配置
consumer:
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 分组名称
group-id: web
enable-auto-commit: false
#提交offset延时(接收到消息后多久提交offset)
# auto-commit-interval: 1000ms
#当kafka中没有初始offset或offset超出范围时将自动重置offset
# earliest:重置为分区中最小的offset;
# latest:重置为分区中最新的offset(消费分区中新产生的数据);
# none:只要有一个分区不存在已提交的offset,就抛出异常;
auto-offset-reset: latest
properties:
#消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发rebalance操作)
session.timeout.ms: 15000
#消费请求超时时间
request.timeout.ms: 18000
#批量消费每次最多消费多少条消息
#每次拉取一条,一条条消费,当然是具体业务状况设置
max-poll-records: 1
# 指定心跳包发送频率,即间隔多长时间发送一次心跳包,优化该值的设置可以减少Rebalance操作,默认时间为3秒;
heartbeat-interval: 6000
# 发出请求时传递给服务器的 ID。用于服务器端日志记录 正常使用后解开注释,不然只有一个节点会报错
#client-id: mqtt
listener:
#消费端监听的topic不存在时,项目启动会报错(关掉)
missing-topics-fatal: false
#设置消费类型 批量消费 batch,单条消费:single
type: single
#指定容器的线程数,提高并发量
#concurrency: 3
#手动提交偏移量 manual达到一定数据后批量提交
#ack-mode: manual
ack-mode: MANUAL_IMMEDIATE #手動確認消息
# 认证
#properties:
#security:
#protocol: SASL_PLAINTEXT
#sasl:
#mechanism: SCRAM-SHA-256
#jaas:config: 'org.apache.kafka.common.security.scram.ScramLoginModule required username="username" password="password";'简单工具类,能满足正常使用,主题是无法修改的
@Component
@Slf4j
public class KafkaUtils<K, V> {
@Autowired
private KafkaTemplate kafkaTemplate;
@Value("${spring.kafka.bootstrap-servers}")
String[] servers;
/**
* 获取连接
* @return
*/
private Admin getAdmin() {
Properties properties = new Properties();
properties.put("bootstrap.servers", servers);
// 正式环境需要添加账号密码
return Admin.create(properties);
}
/**
* 增加topic
*
* @param name 主题名字
* @param partition 分区数量
* @param replica 副本数量
* @date 2022-06-23 chens
*/
public R addTopic(String name, Integer partition, Integer replica) {
Admin admin = getAdmin();
if (replica > servers.length) {
return R.error("副本数量不允许超过Broker数量");
}
try {
NewTopic topic = new NewTopic(name, partition, Short.parseShort(replica.toString()));
admin.createTopics(Collections.singleton(topic));
} finally {
admin.close();
}
return R.ok();
}
/**
* 删除主题
*
* @param names 主题名字集合
* @date 2022-06-23 chens
*/
public void deleteTopic(List<String> names) {
Admin admin = getAdmin();
try {
admin.deleteTopics(names);
} finally {
admin.close();
}
}
/**
* 查询所有主题
*
* @date 2022-06-24 chens
*/
public Set<String> queryTopic() {
Admin admin = getAdmin();
try {
ListTopicsResult topics = admin.listTopics();
Set<String> set = topics.names().get();
return set;
} catch (Exception e) {
log.error("查询主题错误!");
} finally {
admin.close();
}
return null;
}
// 向所有分区发送消息
public ListenableFuture<SendResult<K, V>> send(String topic, @Nullable V data) {
return kafkaTemplate.send(topic, data);
}
// 指定key发送消息,相同key保证消息在同一个分区
public ListenableFuture<SendResult<K, V>> send(String topic, K key, @Nullable V data) {
return kafkaTemplate.send(topic, key, data);
}
// 指定分区和key发送。
public ListenableFuture<SendResult<K, V>> send(String topic, Integer partition, K key, @Nullable V data) {
return kafkaTemplate.send(topic, partition, key, data);
}
}发送消息 使用异步
@GetMapping("/{topic}")
public String test(@PathVariable String topic, @PathVariable Long index) throws ExecutionException, InterruptedException {
ListenableFuture future = null;
Chenshuang user = new Chenshuang(i, "陈爽", "123456", new Date());
String s = JSON.toJSONString(user);
KafkaUtils utils = new KafkaUtils();
future = kafkaUtils.send(topic, s);
// 异步回调,同步get,会等待 不推荐同步!
future.addCallback(new ListenableFutureCallback() {
@Override
public void onFailure(Throwable ex) {
System.out.println("发送失败");
}
@Override
public void onSuccess(Object result) {
System.out.println("发送成功:" + result);
}
});
return "发送成功";
}建立主题
如果broker端配置auto.create.topics.enable为true(默认为true),当收到客户端的元数据请求时则会创建topic。
向一个不存在的主题发送和消费都会创建一个新的主题,很多时候,非预期的创建主题,会导致很多意想不到的问题,建议关掉该特性。
Topic主题用来区分不同类型的消息,实际也就是适用于不同的业务场景,默认消息保存一周时间;
同一个Topic主题下,默认是一个partition分区,也就是只能有一个消费者来消费,如果想提升消费能力,就需要增加分区;
同一个Topic的多个分区,可以有三种方式分派消息(key,value)到不同的分区,指定分区、HASH路由、默认,同一个分区内的消息ID唯一,并顺序;
消费者消费partition分区内的消息时,是通过offsert来标识消息的位置;
GroupId用来解决同一个Topic主题下重复消费问题,比如一条消费需要多个消费者接收到,就可以通过设置不同的GroupId实现,
实际消息是存一份的,只是通过逻辑上设置标识来区分,系统会记录Topic主题下–》GroupId分组下–》partition分区下的offsert,来标识是否消费过。
发送消息的高可用—
集群模式,多副本方式实现;一条消息的提交,可能通过设置acks标识实现不同的可用性,=0时,发送成功就OK;=1时,master成功响应才OK,=all时,一半以上的响应才OK(真正的高可用)
消费消息的高可用—
可以关闭自动标识offsert模式,先拉取消息,消费完成后,再去设置offsert位置,来解决消费高可用
import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class KafkaTopic {
// yml自定义主题,项目启动就创建,
@Value("${spring.kafka.topic}")
String topic;
@Value("${spring.kafka.bootstrap-servers}")
String[] server;
/**
* 项目启动 初始化主题,如果存在不会覆盖主题的
*/
@Bean
public NewTopic batchTopic() {
// 最大复制因子 <= 经纪人broker数量.
return new NewTopic(topic, 10, (short) server.length);
}
}监听类 ,一条消息,各分组内的消费者只有一个消费者消费一次,如果消息在1区,指定分区1监听也会消费
也可以同个方法监听不同的主题,指定位移监听
同组会均匀消费,不同组会重复消费。
1、单播模式,只有一个消费者组
(1)topic只有1个partition,该组内有多个消费者时,此时同一个partition内的消息只能被该组中的一 个consumer消费。当消费者数量多于partition数量时,多余的消费者是处于空闲状态的,如图1所示。topic,test只有一个partition,并且只有1个group,G1,该group内有多个consumer,只能被其中一个消费者消费,其他的处于空闲状态。
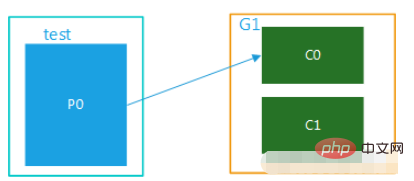
图一
(2)该topic有多个partition,该组内有多个消费者,比如test 有3个partition,该组内有2个消费者,那么可能就是C0对应消费p0,p1内的数据,c1对应消费p2的数据;如果有3个消费者,就是一个消费者对应消费一个partition内的数据了。图解分别如图2,图3.这种模式在集群模式下使用是非常普遍的,比如我们可以起3个服务,对应的topic设置3个partiition,这样就可以实现并行消费,大大提高处理消息的效率。
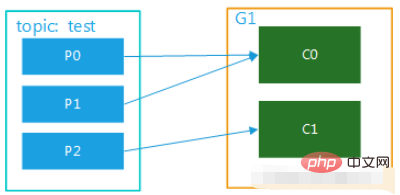
图二
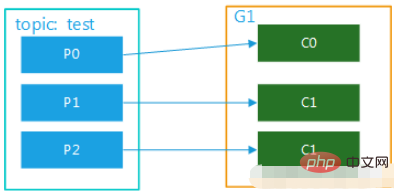
图三
2、广播模式,多个消费者组
如果想实现广播的模式就需要设置多个消费者组,这样当一个消费者组消费完这个消息后,丝毫不影响其他组内的消费者进行消费,这就是广播的概念。
(1)多个消费者组,1个partition
该topic内的数据被多个消费者组同时消费,当某个消费者组有多个消费者时也只能被一个消费者消费,如图4所示:
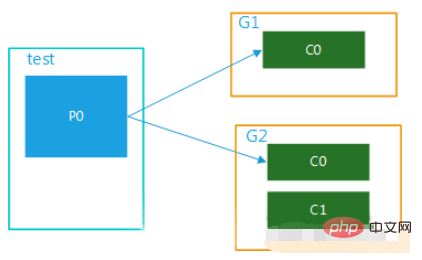
图四
(2)多个消费者组,多个partition
该topic内的数据可被多个消费者组多次消费,在一个消费者组内,每个消费者又可对应该topic内的一个或者多个partition并行消费,如图五:
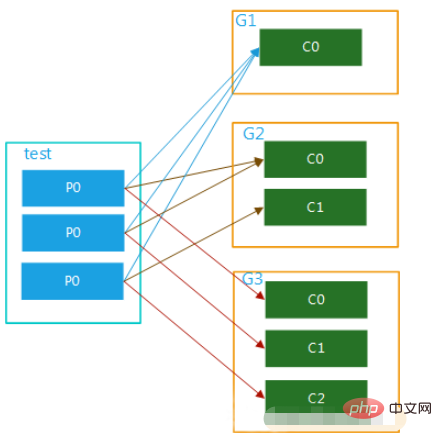
注意: 消费者的数量并不能决定一个topic的并行度。它是由分区的数目决定的。
再多的消费者,分区数少,也是浪费!
一个组的最大并行度将等于该主题的分区数。
@Component
@Slf4j
public class Consumer {
// 监听主题 分组a
@KafkaListener(topics =("${spring.kafka.topic}") ,groupId = "a")
public void getMessage(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息
ack.acknowledge();
}
// 监听主题 分组a
@KafkaListener(topics = ("${spring.kafka.topic}"),groupId = "a")
public void getMessage2(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息
ack.acknowledge();
}
// 监听主题 分组b
@KafkaListener(topics = ("${spring.kafka.topic}"),groupId = "b")
public void getMessage3(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息//确认收到消息
ack.acknowledge();
}
// 监听主题 分组b
@KafkaListener(topics = ("${spring.kafka.topic}"),groupId = "b")
public void getMessage4(ConsumerRecord message, Acknowledgment ack) {
//确认收到消息//确认收到消息
ack.acknowledge();
}
// 指定监听分区1的消息
@KafkaListener(topicPartitions = {@TopicPartition(topic = ("${spring.kafka.topic}"),partitions = {"1"})})
public void getMessage5(ConsumerRecord message, Acknowledgment ack) {
Long id = JSONObject.parseObject(message.value().toString()).getLong("id");
//确认收到消息//确认收到消息
ack.acknowledge();
}
/**
* @Title 指定topic、partition、offset消费
* @Description 同时监听topic1和topic2,监听topic1的0号分区、topic2的 "0号和1号" 分区,指向1号分区的offset初始值为8
* 注意:topics和topicPartitions不能同时使用;
**/
@KafkaListener(id = "c1",groupId = "c",topicPartitions = {
@TopicPartition(topic = "t1", partitions = { "0" }),
@TopicPartition(topic = "t2", partitions = "0", partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "8"))})
public void getMessage6(ConsumerRecord record,Acknowledgment ack) {
//确认收到消息
ack.acknowledge();
}
/**
* 批量消费监听goods变更消息
* yml配置listener:type 要改为batch
* ymk配置consumer:max-poll-records: ??(每次拉取多少条数据消费)
* concurrency = "2" 启动多少线程执行,应小于等于broker数量,避免资源浪费
*/
@KafkaListener(id="sync-modify-goods", topics = "${spring.kafka.topic}",concurrency = "4")
public void getMessage7(List<ConsumerRecord<String, String>> records){
for (ConsumerRecord<String, String> msg:records) {
GoodsChangeMsg changeMsg = null;
try {
changeMsg = JSONObject.parseObject(msg.value(), GoodsChangeMsg.class);
syncGoodsProcessor.handle(changeMsg);
}catch (Exception exception) {
log.error("解析失败{}", msg, exception);
}
}
}
}以上是SpringBoot怎么集成Kafka配置工具类的详细内容。更多信息请关注PHP中文网其他相关文章!

 JVM中的类加载程序子系统如何促进平台独立性?Apr 23, 2025 am 12:14 AM
JVM中的类加载程序子系统如何促进平台独立性?Apr 23, 2025 am 12:14 AM类加载器通过统一的类文件格式、动态加载、双亲委派模型和平台无关的字节码,确保Java程序在不同平台上的一致性和兼容性,实现平台独立性。
 Java编译器会产生特定于平台的代码吗?解释。Apr 23, 2025 am 12:09 AM
Java编译器会产生特定于平台的代码吗?解释。Apr 23, 2025 am 12:09 AMJava编译器生成的代码是平台无关的,但最终执行的代码是平台特定的。1.Java源代码编译成平台无关的字节码。2.JVM将字节码转换为特定平台的机器码,确保跨平台运行但性能可能不同。
 JVM如何处理不同操作系统的多线程?Apr 23, 2025 am 12:07 AM
JVM如何处理不同操作系统的多线程?Apr 23, 2025 am 12:07 AM多线程在现代编程中重要,因为它能提高程序的响应性和资源利用率,并处理复杂的并发任务。JVM通过线程映射、调度机制和同步锁机制,在不同操作系统上确保多线程的一致性和高效性。
 在Java的背景下,'平台独立性”意味着什么?Apr 23, 2025 am 12:05 AM
在Java的背景下,'平台独立性”意味着什么?Apr 23, 2025 am 12:05 AMJava的平台独立性是指编写的代码可以在任何安装了JVM的平台上运行,无需修改。1)Java源代码编译成字节码,2)字节码由JVM解释执行,3)JVM提供内存管理和垃圾回收功能,确保程序在不同操作系统上运行。
 Java应用程序仍然可以遇到平台特定的错误或问题吗?Apr 23, 2025 am 12:03 AM
Java应用程序仍然可以遇到平台特定的错误或问题吗?Apr 23, 2025 am 12:03 AMJavaapplicationscanindeedencounterplatform-specificissuesdespitetheJVM'sabstraction.Reasonsinclude:1)Nativecodeandlibraries,2)Operatingsystemdifferences,3)JVMimplementationvariations,and4)Hardwaredependencies.Tomitigatethese,developersshould:1)Conduc
 云计算如何影响Java平台独立性的重要性?Apr 22, 2025 pm 07:05 PM
云计算如何影响Java平台独立性的重要性?Apr 22, 2025 pm 07:05 PM云计算显着提升了Java的平台独立性。 1)Java代码编译为字节码,由JVM在不同操作系统上执行,确保跨平台运行。 2)使用Docker和Kubernetes部署Java应用,提高可移植性和可扩展性。
 Java的平台独立性在广泛采用中扮演着什么角色?Apr 22, 2025 pm 06:53 PM
Java的平台独立性在广泛采用中扮演着什么角色?Apr 22, 2025 pm 06:53 PMJava'splatformindependenceallowsdeveloperstowritecodeonceandrunitonanydeviceorOSwithaJVM.Thisisachievedthroughcompilingtobytecode,whichtheJVMinterpretsorcompilesatruntime.ThisfeaturehassignificantlyboostedJava'sadoptionduetocross-platformdeployment,s
 容器化技术(例如Docker)如何影响Java平台独立性的重要性?Apr 22, 2025 pm 06:49 PM
容器化技术(例如Docker)如何影响Java平台独立性的重要性?Apr 22, 2025 pm 06:49 PM容器化技术如Docker增强而非替代Java的平台独立性。1)确保跨环境的一致性,2)管理依赖性,包括特定JVM版本,3)简化部署过程,使Java应用更具适应性和易管理性。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

