
AI孙燕姿翻唱爆火,多亏这个开源项目!广西老表带头打造,上手指南已出

- 王林转载
- 2023-05-12 14:07:061043浏览
AI孙燕姿这么快翻唱了这么多首歌,到底是咋实现的?
关键在于一个开源项目。
最近,这波AI翻唱趋势大火,不仅是AI孙燕姿唱的歌越来越多,AI歌手的范围也在扩大,就连制作教程都层出不穷了。
而如果在各大教程中溜达一圈后就会发现,其中的关键秘诀,还是要靠一个名为so-vits-svc的开源项目。
它提供了一种音色替换的办法,项目在今年3月发布。
贡献成员应该大部分都来自国内,其中贡献量最高的还是一位玩明日方舟的广西老表。
如今,项目已经停止更新了,但是星标数量还在蹭蹭上涨,目前已经到了8.4k。
所以它到底实现了哪些技术能引爆这波趋势?
一起来看。
多亏了一个开源项目
这个项目名叫SoftVC VITS Singing Voice Conversion(歌声转换)。
它提供了一种音色转换算法,采用SoftVC内容编码器提取源音频语音特征,然后将矢量直接输入VITS,中间不转换成文本,从而保留了音高和语调。
此外,还将声码器改为NSF HiFiGAN,可以解决声音中断的问题。
具体分为以下几步:
- 预训练模型
- 准备数据集
- 预处理
- 训练
- 推理
其中,预训练模型这步是关键之一,因为项目本身不提供任何音色的音频训练模型,所以如果你想要做一个新的AI歌手出来,需要自己训练模型。
而预训练模型的第一步,是准备干声,也就是无音乐的纯人声。
很多博主使用的工具都是UVR_v5.5.0。
推特博主@歸藏介绍说,在处理前最好把声音格式转成WAV格式,因为So-VITS-SVC 4.0只认这个格式,方便后面处理。
想要效果好一些,需要处理两次背景音,每次的设置不同,能最大限度提高干声质量。
得到处理好的音频后,需要进行一些预处理操作。
比如音频太长容易爆显存,需要对音频切片,推荐5-15秒或者再长一点也OK。
然后要重新采样到44100Hz和单声道,并自动将数据集划分为训练集和验证集,生成配置文件。再生成Hubert和f0。
接下来就能开始训练和推理了。
具体的步骤可以移步GitHub项目页查看(指路文末)。
值得一提的是,这个项目在今年3月上线,目前贡献者有25位。从贡献用户的简介来看,很多应该都来自国内。
据说项目刚上线时也有不少漏洞并且需要编程,但是后面几乎每一天都有人在更新和修补,现在的使用门槛已经降低了不少。
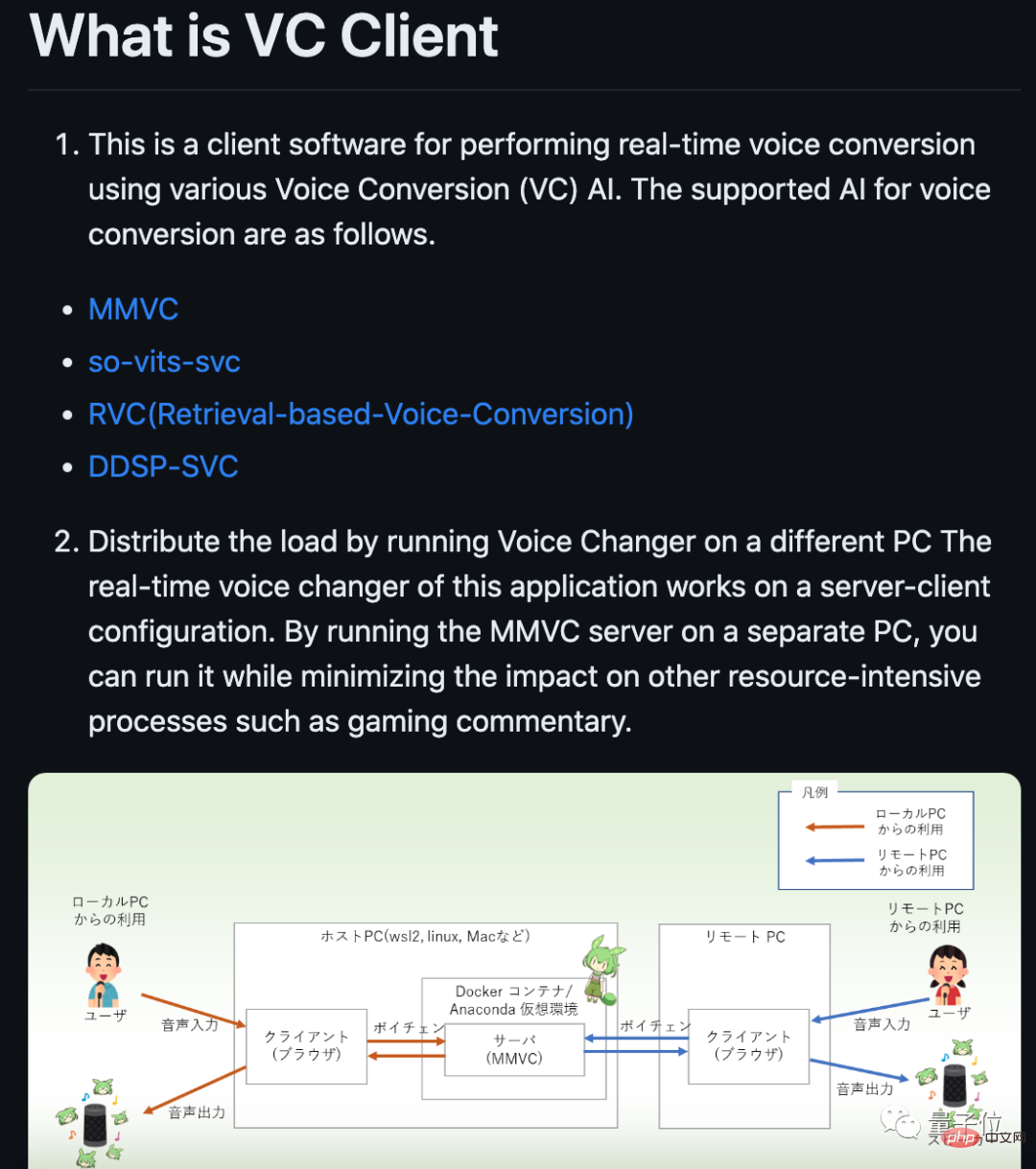
目前项目已经停止更新了,但还是有一些开发者创建了新的分支,比如有人做出了支持实时转换的客户端。
项目贡献量最多的一位开发者是Miuzarte,从简介地址判断应该来自广西。
随着想要上手使用的人越来越多,也有不少博主推出了上手难度更低、更详细的食用指南。
歸藏推荐的方法是使用整合包来推理(使用模型)和训练,还有B站的Jack-Cui展示了Windows下的步骤指南(https://www.bilibili.com/read/cv22375562)。
需要注意的是,模型训练对显卡要求还是比较高的,显存小于6G容易出现各类问题。
Jack-Cui建议使用N卡,他用RTX 2060 S,训练自己的模型大概用了14个小时。
训练数据也同样关键,越多高质量音频,就意味着最后效果可以越好。
还是会担心版权问题
值得一提的是,在so-vits-svc的项目主页上,着重强调了版权问题。
警告:请自行解决数据集的授权问题。因使用未经授权的数据集进行培训而产生的任何问题及其一切后果,由您自行承担责任。存储库及其维护者、svc开发团队,与生成结果无关!

这和AI画画爆火时有点相似。
因为AI生成内容的最初数据取材于人类作品,在版权方面的争论不绝于耳。
而且随着AI作品盛行,已经有版权方出手下架平台上的视频了。
据了解,一首AI合成的《Heart on My Sleeve》在Tik Tok上爆火,它合成了Drake和Weekend演唱的版本。
但随后,Drake和Weekend的唱片公司环球音乐将这个视频从平台上下架了,并在声明里向潜在的仿冒者发问,“是要站在艺术家、粉丝和人类创造性表达的一边,还是站在Deepfake、欺诈和拒付艺术家赔偿的一边?”
此外,歌手Drake对AI合成翻唱歌曲表达了不满。
而另一边,也有人选择拥抱这项技术。
加拿大歌手Grimes表示,她愿意让别人使用自己的声音合成歌曲,但是要给她一半版权费。
GitHub地址:https://github.com/svc-develop-team/so-vits-svc
以上是AI孙燕姿翻唱爆火,多亏这个开源项目!广西老表带头打造,上手指南已出的详细内容。更多信息请关注PHP中文网其他相关文章!