



一、认识双向链表
单向链表不仅保存了当前的结点值,还保存了下一个结点的地址
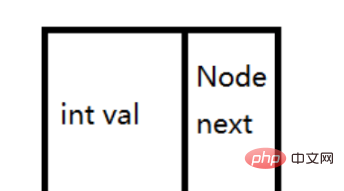
双向链表不仅保存了当前节点的值,还保存了上一个结点的地址和下一个结点的地址

定义一个双向链表的结点类:
结点中既要保存当前节点的值,还要保存此节点的前驱节点的地址和此节点的后继节点的地址
class DoubleNode{
public DoubleNode next;
DoubleNode prev;
int val;
DoubleNode tail;
public DoubleNode() {}
public DoubleNode(int val) {
this.val = val;
}
public DoubleNode(DoubleNode prev, int val, DoubleNode tail) {
this.prev = prev;
this.val = val;
this.tail = tail;
}
}定义一个双向链表类:
既可以从前向后,也可以从后向前,所以在这个类中,即保存一下头结点,也保存一下尾结点的值
public class DoubleLinkedList {
private int size;
private DoubleNode head;
private DoubleNode tail;
}二、双向链表的增删改查
1.插入
头插
在当前链表的头部插入一个节点,让当前链表的头结点head前驱指向要插入的节点node,然后让node的后继指向head,然后让head = node,让node成为链表的头结点
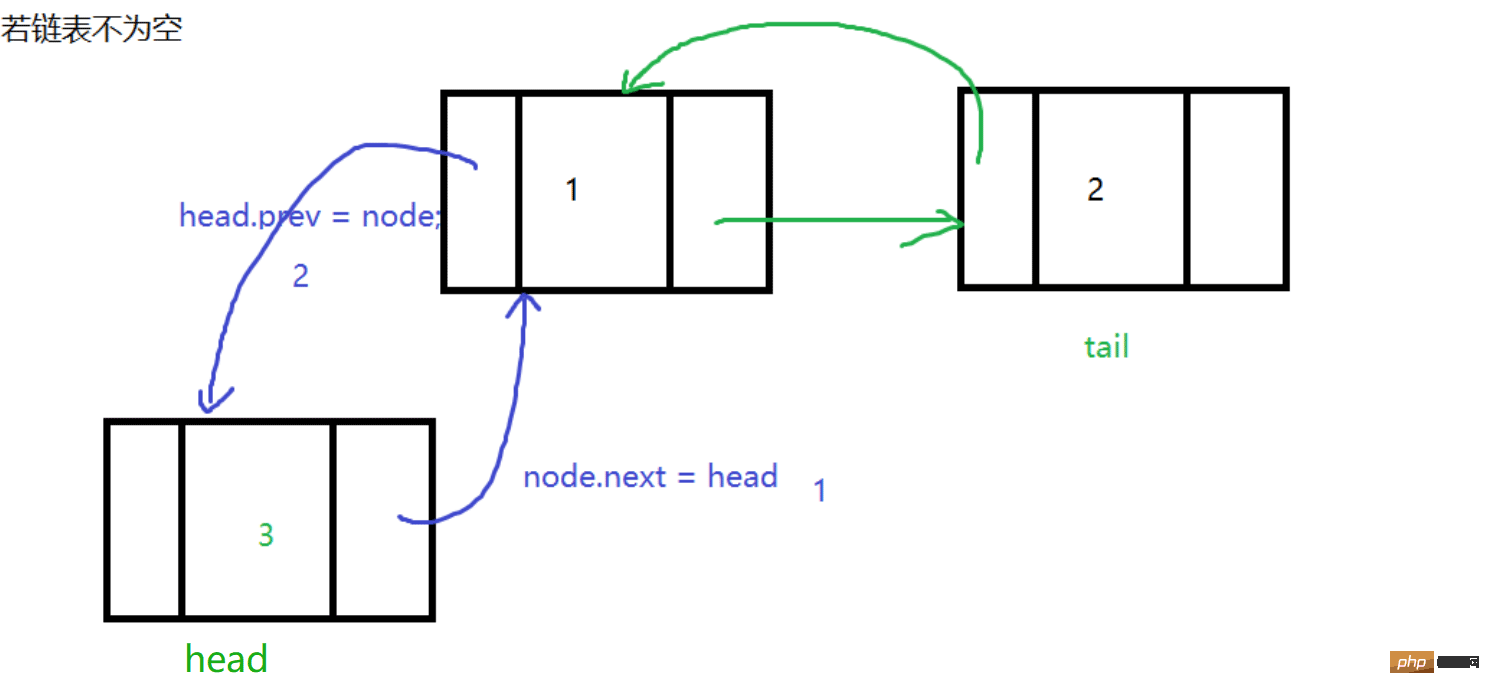
代码如下:
/**
* 头插
*/
public void addFirst(int val){
DoubleNode node = new DoubleNode(val);
if (head == null){
head = tail = node;
}else{
node.next = head;
head.prev = node;
head = node;
}
size++;
}尾插
和头插一样,只不过在链表的尾部插入
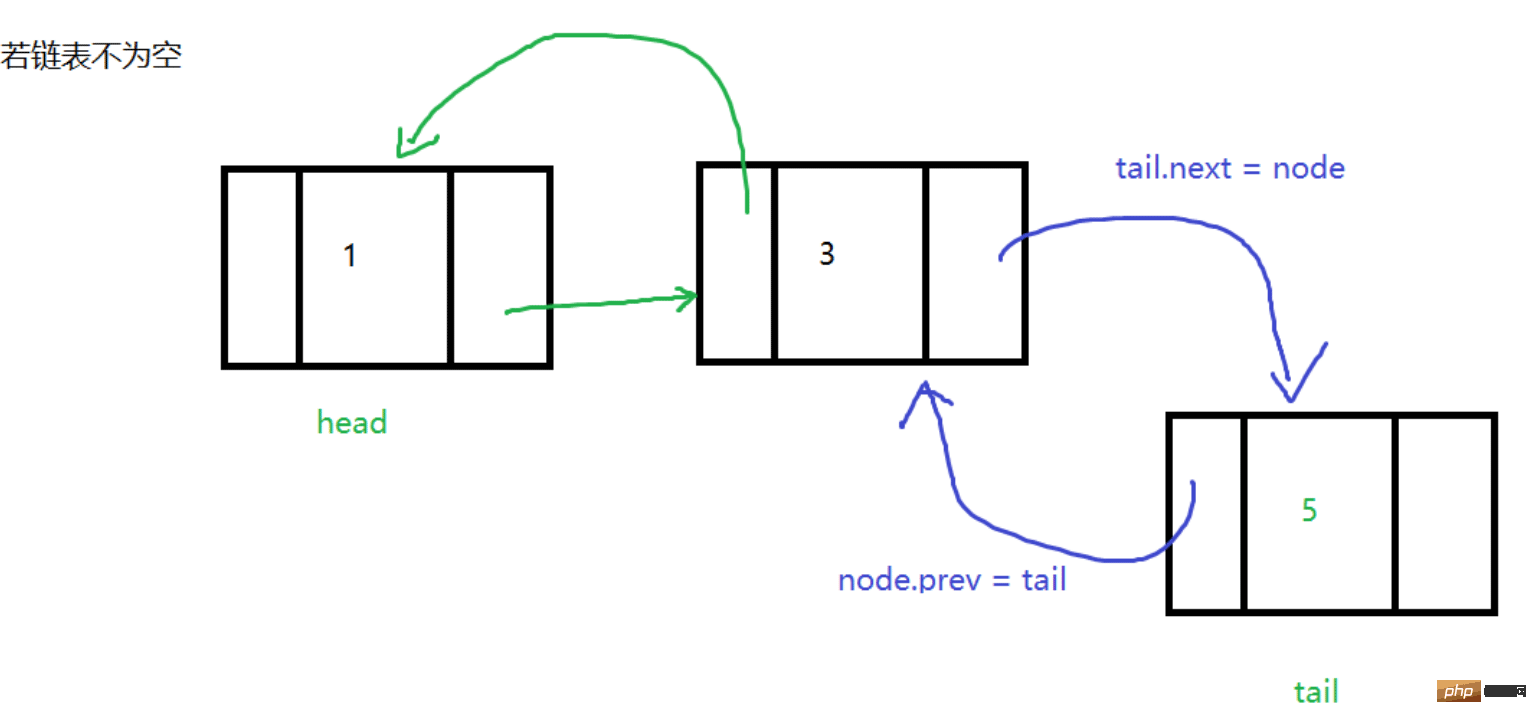
代码如下:
public void addLast(int val){
DoubleNode node = new DoubleNode(val);
if (head == null){
head = tail =node;
}else{
tail.next = node;
node.prev = tail;
tail = node;
}
size++;
}在index位置插入
在索引为index的位置插入值为val的节点:
插入还是要找前驱节点,但双向链表找前驱节点比单向链表找前驱节点要灵活很多,单向链表只能从头走到尾,假如此时有100个节点,要在索引为98的位置插入节点,那么双向链表就可以从尾结点开始找,会方便很多
如何判断从前向后找,还是从后向前找?
1.index f8242e50a71522c7c01919aac518d3db从前向后找,插入位置在前半部分
2.index > size / 2 – >从后向前找,插入位置在后半部分
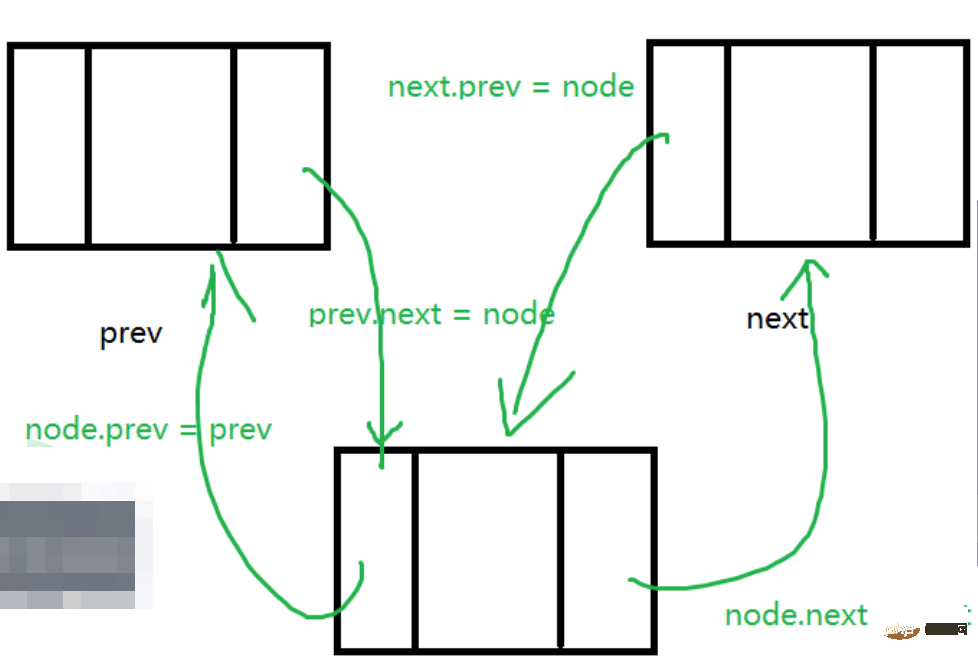
代码如下:
/**
* 在index位置插入
* @param index
* @param val
*/
public void add(int index,int val){
DoubleNode cur = new DoubleNode(val);
if (index < 0 || index > size){
System.err.println("add index illegal");
return;
}else{
if (index == 0){addFirst(val);}
else if (index == size){addLast(val);}
else{
DoubleNode prev = node(index-1);
DoubleNode next = prev.next;
cur.next = next;
next.prev = cur;
prev.next = cur;
cur.prev = prev;
}
}
size++;
}
/**
* 根据索引值找到对应的结点
* @param index
* @return
*/
private DoubleNode node(int index){
DoubleNode x = null;
if (index < size/2){
x = head;
for (int i = 0; i < index; i++) {
x = x.next;
}
}else{
x = tail;
for (int i = size - 1; i > index ; i--) {
x = x.prev;
}
}
return x;
}2.修改
代码如下:
/**
* 修改双向链表index位置的结点值为newVal
*/
public int set(int index,int newVal){
DoubleNode dummyHead = new DoubleNode();
dummyHead.next = head;
DoubleNode prev = dummyHead;
DoubleNode cur = prev.next;
if (index < 0 || index > size - 1){
System.err.println("set index illegal");
}else{
for (int i = 0; i < index; i++) {
prev = prev.next;
cur = cur.next;
}
}
int oldVal = cur.val;
cur.val = newVal;
return oldVal;
}3.查询
代码如下:
/**
* 查询index位置的结点值
*/
public int get(int index){
DoubleNode dummyHead = new DoubleNode();
dummyHead.next = head;
DoubleNode prev = dummyHead;
DoubleNode cur = prev.next;
if (index < 0 || index > size - 1){
System.err.println("get index illegal");
}else{
for (int i = 0; i < index; i++) {
prev = prev.next;
cur = cur.next;
}
}
return cur.val;
}4.删除
删除index位置的节点
代码如下:
//删除链表index位置的结点
public void removeIndex(int index){
if (index < 0 || index > size - 1){
System.err.println("remove index illegal");
return;
}
DoubleNode cur = node(index);
unlink(cur);
}
/**
* 删除当前双向链表的node结点
* 分治法
* @param node
*/
private void unlink (DoubleNode node){
DoubleNode prev = node.prev;
DoubleNode successor = node.next;
//1.先处理node的前半部分
if (prev == null){
head = successor;
}else{
//前驱不为空的情况
prev.next = successor;
node.prev = null;
}
if (successor == null){
tail = prev;
}else{
successor.prev = prev;
node.next = null;
}
size--;
}头删
调用删除任意位置的节点即可
代码如下:
//头删
public void removeFirst(){
removeIndex(0);
}尾删
调用删除任意位置的节点即可
代码如下:
//尾删
public void removeLast(){
removeIndex(size - 1);
}删除第一个值为val的节点
代码如下:
//删除第一个值为val的结点
public void removeValOnce(int val){
if (head == null){
return;
}
for (DoubleNode x = head;x != null;x = x.next){
if (x.val == val){
unlink(x);
break;
}
}
}
/**
* 删除当前双向链表的node结点
* 分治法
* @param node
*/
private void unlink (DoubleNode node){
DoubleNode prev = node.prev;
DoubleNode successor = node.next;
//1.先处理node的前半部分
if (prev == null){
head = successor;
}else{
//前驱不为空的情况
prev.next = successor;
node.prev = null;
}
if (successor == null){
tail = prev;
}else{
successor.prev = prev;
node.next = null;
}
size--;
}删除所有值为val的值
代码如下:
//删除链表中所有值为val的结点
public void removeAllVal(int val){
for (DoubleNode x = head;x != null;){
if (x.val == val){
//暂存一下x的下一个结点
DoubleNode next = x.next;
unlink(x);
x = next;
}else{
//val不是待删除的元素
x = x.next;
}
}
}
/**
* 删除当前双向链表的node结点
* 分治法
* @param node
*/
private void unlink (DoubleNode node){
DoubleNode prev = node.prev;
DoubleNode successor = node.next;
//1.先处理node的前半部分
if (prev == null){
head = successor;
}else{
//前驱不为空的情况
prev.next = successor;
node.prev = null;
}
if (successor == null){
tail = prev;
}else{
successor.prev = prev;
node.next = null;
}
size--;
}以上是Java双向链表的增删改查怎么实现的详细内容。更多信息请关注PHP中文网其他相关文章!

 是否有任何威胁或增强Java平台独立性的新兴技术?Apr 24, 2025 am 12:11 AM
是否有任何威胁或增强Java平台独立性的新兴技术?Apr 24, 2025 am 12:11 AM新兴技术对Java的平台独立性既有威胁也有增强。1)云计算和容器化技术如Docker增强了Java的平台独立性,但需要优化以适应不同云环境。2)WebAssembly通过GraalVM编译Java代码,扩展了其平台独立性,但需与其他语言竞争性能。
 JVM的实现是什么,它们都提供了相同的平台独立性?Apr 24, 2025 am 12:10 AM
JVM的实现是什么,它们都提供了相同的平台独立性?Apr 24, 2025 am 12:10 AM不同JVM实现都能提供平台独立性,但表现略有不同。1.OracleHotSpot和OpenJDKJVM在平台独立性上表现相似,但OpenJDK可能需额外配置。2.IBMJ9JVM在特定操作系统上表现优化。3.GraalVM支持多语言,需额外配置。4.AzulZingJVM需特定平台调整。
 平台独立性如何降低发展成本和时间?Apr 24, 2025 am 12:08 AM
平台独立性如何降低发展成本和时间?Apr 24, 2025 am 12:08 AM平台独立性通过在多种操作系统上运行同一套代码,降低开发成本和缩短开发时间。具体表现为:1.减少开发时间,只需维护一套代码;2.降低维护成本,统一测试流程;3.快速迭代和团队协作,简化部署过程。
 Java的平台独立性如何促进代码重用?Apr 24, 2025 am 12:05 AM
Java的平台独立性如何促进代码重用?Apr 24, 2025 am 12:05 AMJava'splatformindependencefacilitatescodereusebyallowingbytecodetorunonanyplatformwithaJVM.1)Developerscanwritecodeonceforconsistentbehavioracrossplatforms.2)Maintenanceisreducedascodedoesn'tneedrewriting.3)Librariesandframeworkscanbesharedacrossproj
 您如何在Java应用程序中对平台特定问题进行故障排除?Apr 24, 2025 am 12:04 AM
您如何在Java应用程序中对平台特定问题进行故障排除?Apr 24, 2025 am 12:04 AM要解决Java应用程序中的平台特定问题,可以采取以下步骤:1.使用Java的System类查看系统属性以了解运行环境。2.利用File类或java.nio.file包处理文件路径。3.根据操作系统条件加载本地库。4.使用VisualVM或JProfiler优化跨平台性能。5.通过Docker容器化确保测试环境与生产环境一致。6.利用GitHubActions在多个平台上进行自动化测试。这些方法有助于有效地解决Java应用程序中的平台特定问题。
 JVM中的类加载程序子系统如何促进平台独立性?Apr 23, 2025 am 12:14 AM
JVM中的类加载程序子系统如何促进平台独立性?Apr 23, 2025 am 12:14 AM类加载器通过统一的类文件格式、动态加载、双亲委派模型和平台无关的字节码,确保Java程序在不同平台上的一致性和兼容性,实现平台独立性。
 Java编译器会产生特定于平台的代码吗?解释。Apr 23, 2025 am 12:09 AM
Java编译器会产生特定于平台的代码吗?解释。Apr 23, 2025 am 12:09 AMJava编译器生成的代码是平台无关的,但最终执行的代码是平台特定的。1.Java源代码编译成平台无关的字节码。2.JVM将字节码转换为特定平台的机器码,确保跨平台运行但性能可能不同。
 JVM如何处理不同操作系统的多线程?Apr 23, 2025 am 12:07 AM
JVM如何处理不同操作系统的多线程?Apr 23, 2025 am 12:07 AM多线程在现代编程中重要,因为它能提高程序的响应性和资源利用率,并处理复杂的并发任务。JVM通过线程映射、调度机制和同步锁机制,在不同操作系统上确保多线程的一致性和高效性。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

SublimeText3汉化版
中文版,非常好用

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

SublimeText3 Linux新版
SublimeText3 Linux最新版

WebStorm Mac版
好用的JavaScript开发工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

