
耗时两年谷歌用强化学习打造23个机器人帮助垃圾分类

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2023-05-09 15:01:091112浏览
强化学习(RL)可以让机器人通过反复试错进行交互,进而学会复杂行为,并随着时间的推移变得越来越好。之前谷歌的一些工作探索了 RL 如何使机器人掌握复杂的技能,例如抓取、多任务学习,甚至是打乒乓球。虽然机器人强化学习已经取得了长足进步,但我们仍然没有在日常环境中看到有强化学习加持的机器人。因为现实世界是复杂多样的,并且随着时间的推移不断变化,这为机器人系统带来巨大挑战。然而,强化学习应该是应对这些挑战的优秀工具:通过不断练习、不断进步和在工作中学习,机器人应该能够适应不断变化的世界。
在谷歌的论文《 Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators 》中,研究人员探讨了如何通过最新的大规模实验解决这个问题,他们在两年内部署了一支由 23 个支持 RL 的机器人组成的群组,用于在谷歌办公楼中进行垃圾分类和回收。使用的机器人系统将来自真实世界数据的可扩展深度强化学习与来自模拟训练的引导和辅助对象感知输入相结合,以提高泛化能力,同时保留端到端训练优势,通过对 240 个垃圾站进行 4800 次评估试验来验证。

论文地址:https://rl-at-scale.github.io/assets/rl_at_scale.pdf
问题设置
如果人们没有正确分类垃圾,成批的可回收物品可能会受到污染,堆肥可能会被不当丢弃到垃圾填埋场。在谷歌的实验中,机器人在办公楼周围漫游,寻找 “垃圾站”(可回收垃圾箱、堆肥垃圾箱和其它垃圾箱)。机器人的任务是到达每个垃圾站进行垃圾分类,在不同垃圾箱之间运输物品,以便将所有可回收物品(罐头、瓶子)放入可回收垃圾箱,将所有可堆肥物品(纸板容器、纸杯)放入堆肥垃圾箱,其他所有东西都放在其它垃圾箱里。
其实这项任务并不像看起来那么容易。仅仅是捡起人们扔进垃圾箱的不同物品的子任务,就已经是一个巨大的挑战。机器人还必须为每个物体识别合适的垃圾箱,并尽可能快速有效地对它们进行分类。在现实世界中,机器人会遇到各种独特的情况,比如以下真实办公楼的例子:
从不同的经验中学习
在工作中不断学习是有帮助的,但在达到这一点之前,需要用一套基本的技能来引导机器人。为此,谷歌使用了四种经验来源:(1)简单的手工设计策略,成功率很低,但有助于提供初步经验;(2)模拟训练框架,使用模拟 - 真实的迁移来提供一些初步的垃圾分类策略;(3)“robot classrooms”,机器人使用有代表性的垃圾站不断练习(4)真实的部署环境,机器人在有真实垃圾的办公楼里练习。
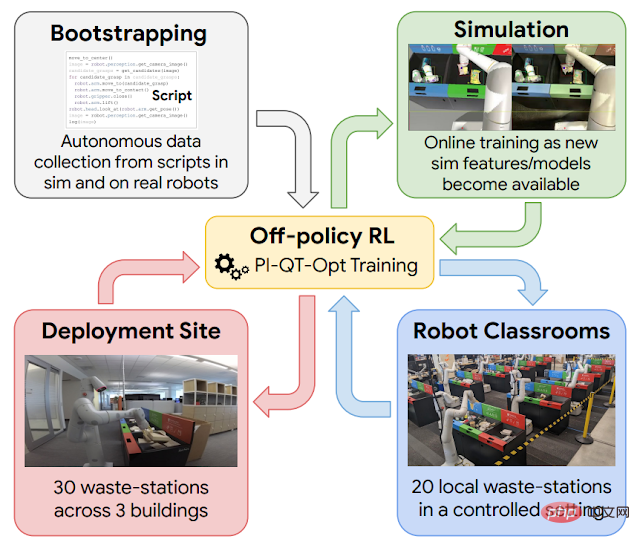
强化学习在该大规模应用中的示意图。使用脚本生成的数据引导策略的启动(左上图)。然后训练一个从仿真到实际的模型,在仿真环境中生成额外的数据(右上图)。在每个部署周期中,添加在 “robot classrooms” 中收集的数据(右下图)。在办公楼中部署和收集数据(左下图)。
这里使用的强化学习框架基于 QT-Opt,实验室环境下的不同垃圾的抓取以及一系列其他技能也是使用该框架。在仿真环境中从简单的脚本策略开始引导,应用强化学习,并使用基于 CycleGAN 的迁移方法,利用 RetinaGAN 使仿真图像看起来更加逼真。
到此就开始进入 “robot classrooms”。虽然实际的办公楼可以提供最真实的体验,但数据收集的吞吐量是有限的 —— 有些时间会有很多垃圾需要分类,有些时间则不会有那么多。机器人在 “robot classrooms” 中积累了大部分的经验。在下面展示的 “robot classrooms” 里,有 20 个机器人练习垃圾分类任务:

当这些机器人在 “robot classrooms” 接受训练时,其它机器人正在 3 座办公楼中的 30 个垃圾站上同时学习。
分类性能
最终,研究人员从 “robot classrooms” 收集了 54 万个试验数据,在实际部署环境收集了 32.5 万个试验数据。随着数据的不断增加,整个系统的性能得到了改善。研究者在 “robot classrooms” 中对最终系统进行了评估,以便进行受控比较,根据机器人在实际部署中看到的情况设置了场景。最终系统的平均准确率约为 84%,随着数据的增加,性能稳步提高。在现实世界中,研究人员记录了 2021 年至 2022 年实际部署的统计数据,发现系统可以按重量将垃圾桶中的污染物减少 40%至 50%。谷歌研究人员在论文提供了有关技术设计、各种设计决策的削弱研究以及实验的更详细统计数据的更深入见解。
结论和未来工作展望
实验结果表明,基于强化学习的系统可以使机器人在真实办公环境中处理实际任务。离线和在线数据的结合使得机器人能够适应真实世界中广泛变化的情况。同时,在更加受控的 “课堂” 环境中学习,包括在仿真环境和实际环境中,可以提供强大的启动机制,使得强化学习的 “飞轮” 开始转动,从而实现适应性。
虽然已经取得了重要成果,但还有很多工作需要完成:最终的强化学习策略并不总是成功的,需要更强大的模型来改善其性能,并将其扩展到更广泛的任务范围。除此之外,其它经验来源,包括来自其它任务、其它机器人,甚至是互联网视频,也可能会进一步补充从仿真和” 课堂 “中获得的启动经验。这些都是未来需要解决的问题。
以上是耗时两年谷歌用强化学习打造23个机器人帮助垃圾分类的详细内容。更多信息请关注PHP中文网其他相关文章!