



进入正文之前,先考虑一下像 ChatGPT 这样的 Transformer 语言模型(LM)的 prompt:

随着每天产生数百万用户和查询,ChatGPT 使用自注意力机制对 prompt 进行反复编码,其时间和内存复杂度随输入长度呈二次方增长。缓存 prompt 的 transformer 激活可以防止部分重新计算,但随着缓存 prompt 数量的增加,这种策略仍然会产生很大的内存和存储成本。在大规模情况下,即使 prompt 长度稍微减少一点,也可能会带来计算、内存和存储空间的节省,同时还可以让用户将更多内容放入 LM 有限的上下文窗口中。
那么。应该如何降低 prompt 的成本呢?典型的方法是微调或蒸馏模型,使其在没有 prompt 的情况下表现得与原始模型相似,或许还可以使用参数高效的自适应方法。然而,这种方法的一个基本缺点是每次需要为新的 prompt 重新训练模型(下图 1 中间所示)。
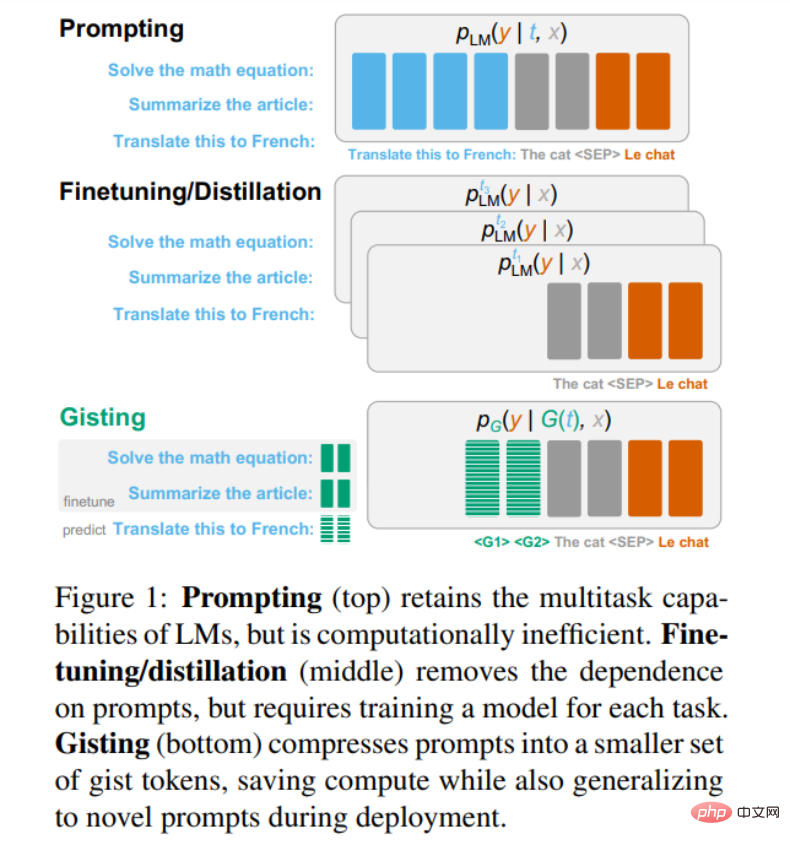
本文中,斯坦福大学的研究者提出了 gisting 模型(上图 1 底部),它将任意 prompt 压缩成一组更小的虚拟「Gist」 token,类似于前缀微调 。然而,前缀微调需要通过梯度下降为每个任务学习 prefix,而 Gisting 采用元学习方法,仅仅通过 prompt 预测 Gist prefix,而不需要为每个任务进行 prefix 学习。这样可以摊销每个任务 prefix 学习的成本,使得在没有额外训练的情况下泛化到未知的指令。
此外,由于「Gist」token 比完整 prompt 要短得多,因此 Gisting 允许 prompt 被压缩、缓存和重复使用,以提高计算效率。

论文地址:https://arxiv.org/pdf/2304.08467v1.pdf
研究者提出了一种非常简单的方法来学习指令遵循的 gist 模型:简单地进行指令微调,在 prompt 后插入 gish token,修改后的注意力掩膜阻止 gist token 后的 token 参考 gist token 前的 token。这使得模型同时学习 prompt 压缩和指令遵循,而无需额外的训练成本。
在 decodr-only(LLaMA-7B)和 encoder-decoder(FLAN-T5-XXL)LM 上,gisting 可实现高达 26 倍的即时压缩率,同时保持与原始模型相似的输出质量。这使得推理过程中 FLOPs 减少了 40%,延迟加速了 4.2%,与传统的 prompt 缓存方法相比,存储成本大大降低。
Gisting
研究者首先在指令微调的背景下描述 gisting。对于指令遵循数据集 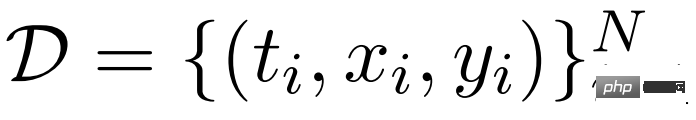
然而,连接 t 和 x 的这种模式具有缺点:基于 Transformer 的 LM 具有有限的上下文窗口,其受架构或计算能力所限。后者特别难解决,因为自注意力随输入长度呈二次方扩展。因此很长的 prompt,尤其那些被反复重用的 prompt,计算效率低下。有哪些选项可以用来降低 prompt 的成本呢?
一种简单的方法是针对特定任务 t 进行 LM 微调,即给定包含仅在任务 t 下的输入 / 输出示例的数据集 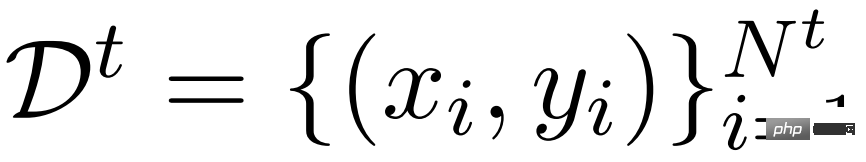
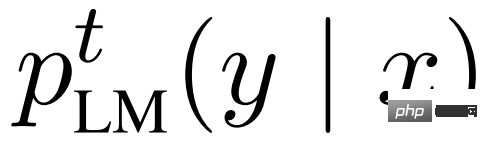
更好的是,prefix/prompt 微调或 adapter 等参数高效微调方法能够以比全面微调低得多的成本实现相同的目的。然而仍然存在问题:必须至少存储每个任务的一部分模型权重,并且更重要的是,对于每个任务 t,必须收集相应的输入 / 输出对数据集 D^t 并重新训练模型。
Gisting 是一种不同的方法,它摊销了两部分成本:(1)在 t 上条件化 p_LM 的推理时间成本,(2)学习每个 t 的新 p^t_LM 的训练时间成本。其思想是在微调期间学习 t 的压缩版本 G (t),使得从 p_G (y | G (t),x) 进行推理比从 p_LM (y|t,x) 更快。
在 LM 术语中,G (t) 将是一组「虚拟」的 Gist token,其数量比 t 中的 token 少,但仍会在 LM 中引起类似的行为。接着可以缓存并重复使用 G (t) 上的 transformer 激活(例如键和值矩阵)以提高计算效率。重要的是,研究者希望 G 可以泛化到未见过的任务:给定一个新任务 t,则可以预测并使用相应的 Gist 激活 G (t) 而无需进行任何额外训练。
通过掩膜学习 Gisting
上文描述了 Gisting 的一般框架,接下来将探讨一种学习此类模型的极简单方法:使用 LM 本身用作 Gist 预测器 G。这不仅利用了 LM 中的预存在知识,而且允许通过简单地执行标准指令微调来学习 gisting 并修改 Transformer 注意力掩膜来增强 prompt 压缩。这意味着 Gisting 不会产生额外训练成本,只需要基于标准指令微调即可!
具体来说,向模型词汇表和嵌入矩阵中添加一个特殊的 gist token,类似于此类模型中常见的句子开头 / 结尾 token。然后对于给定的(任务,输入)元组(t,x),使用 (t, g_1, . . . , g_k, x) 中一组 k 个连续的 gist token 将 t 和 x 连接在一起,例如 
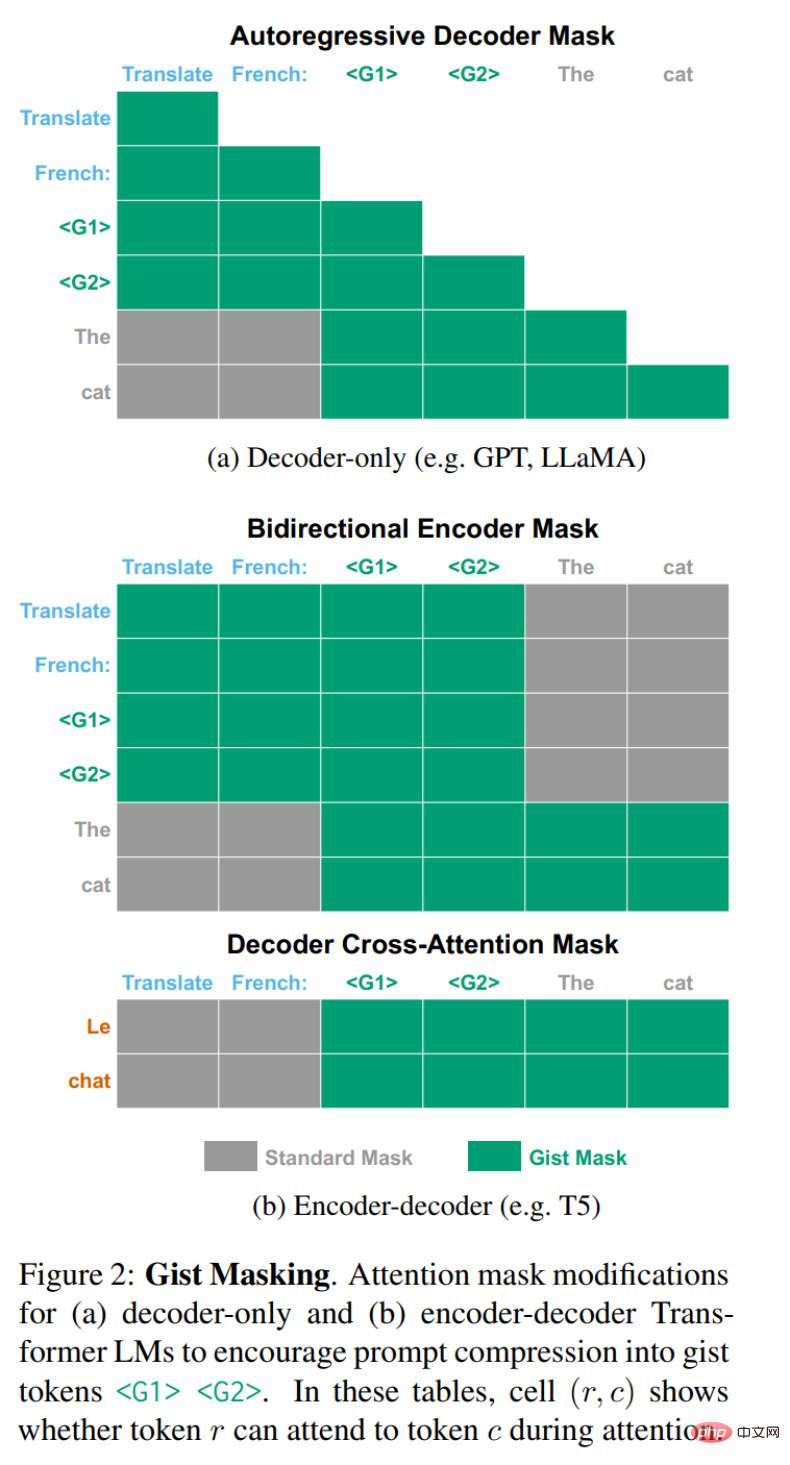
下图 2 展示了所需要的更改。对于 GPT-3 或 LLaMA 等通常采用自回归因果注意力掩膜的 decoder-only LM,只需 mask out 图 2a 所示的三角形左下角。对于具有双向编码器和自回归解码器的 encoder-decoder LM,则需要进行两项修改(图 2b 所示)。
首先,在通常没有掩膜的编码器中,阻止输入 token x 参考 prompt token t。但还必须防止 prompt t 和 gist token g_i 参考输入 token x,否则编码器将根据输入学习不同的 gist 表示。最后解码器正常运行,除了在交叉注意力期间,这时需要阻止解码器参考 prompt token t。
实验结果
对于不同数量的 gist token, LLaMA-7B 和 FLAN-T5-XXL 的 ROUGE-L 和 ChatGPT 评估结果如下图 3 所示。
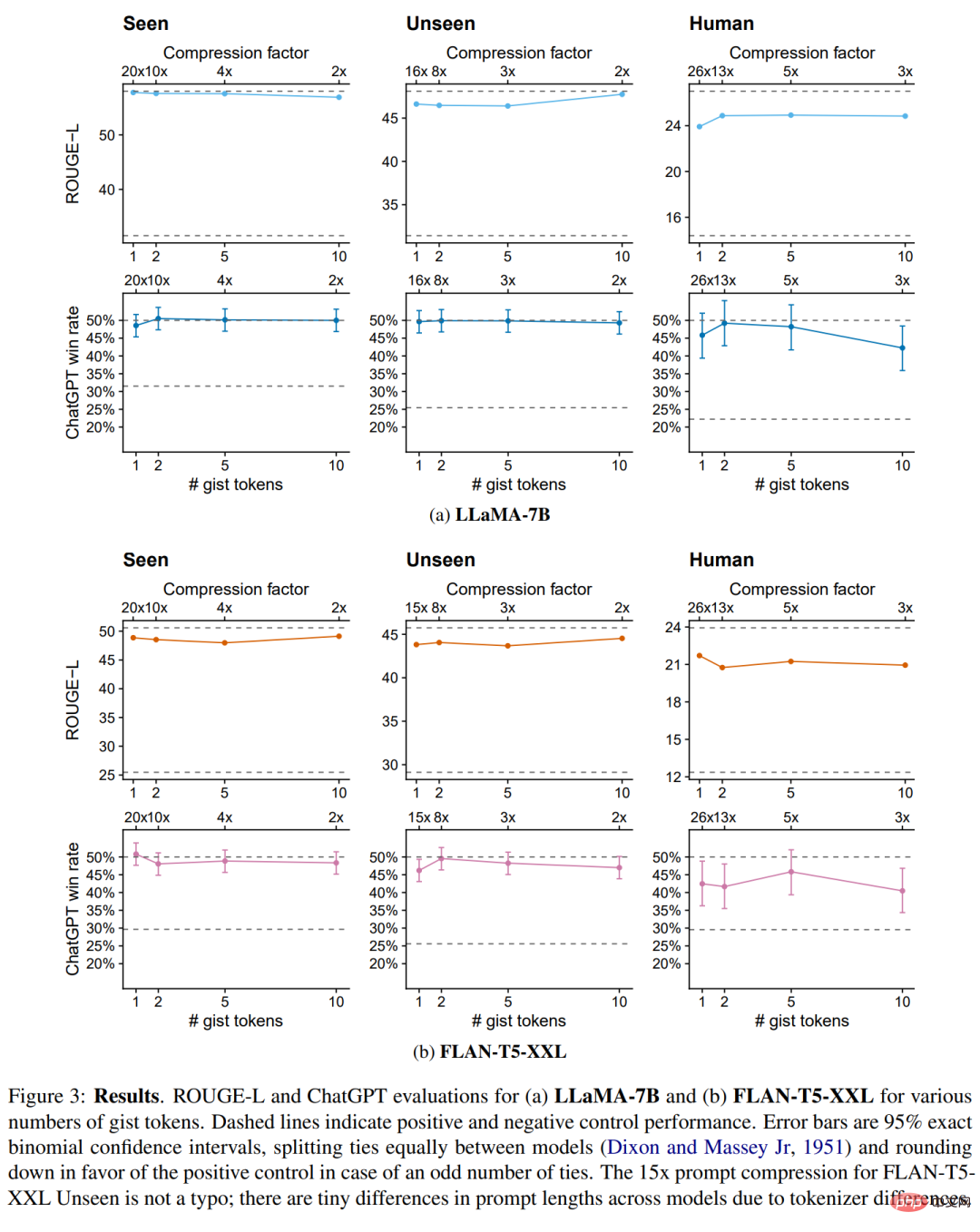
模型通常对 gist token 的数量 k 不敏感:将 prompt 压缩到单个 token 并不会导致显著性能下降。事实上,在某些情况下,过多的 gist token 会损害性能 (例如 LLaMA-7B, 10 gist tokens),这可能是因为增加的容量使训练分布过拟合。因此,研究者在下表 1 中给出了单 token 模型的具体数值,并在剩余实验中使用单个 gist 模型。
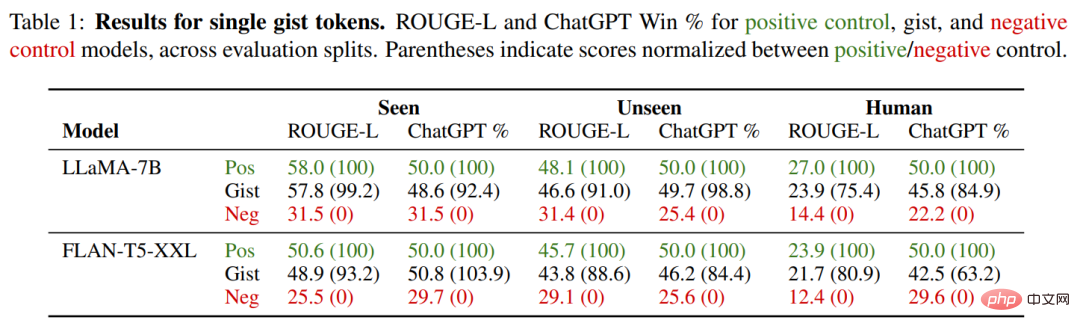
在见过的指令上,gist 模型获得了与其对应阳性对照模型几乎相同的 ROUGE 和 ChatGPT 性能,在 LLaMA-7B FLANT5-XXL 上的胜率分别为 48.6% 和 50.8%。这里研究者最感兴趣的是它们在未见过任务上的泛化能力,这需要通过另外两个数据集来衡量的。
在 Alpaca+ 训练数据集中未见过的 prompt 中,可以看到 gist 模型在未见过 prompt 上有着强大的泛化能力:与对照组相比,分别有 49.7%(LLaMA)和 46.2%(FLAN-T5)的胜率。在最具挑战性的 OOD Human split 上,gist 模型的胜率略微下降,分别为 45.8%(LLaMA)和 42.5%(FLANT5)。
本文的目的是让 gist 模型紧密地模仿原始模型的功能,因此有人可能会问究竟什么时候 gist 模型与对照组无差别。下图 4 说明了这种情况发生的频率:对于已见过任务(但是未见过的输入),gist 模型几乎有一半的时间与对照组不相上下。对于未见过的任务,这一数字下降到了 20-25%。对于 OOD Human 任务,这一数字又下降到 10%。无论如何,gist 模型输出的质量是很高的。
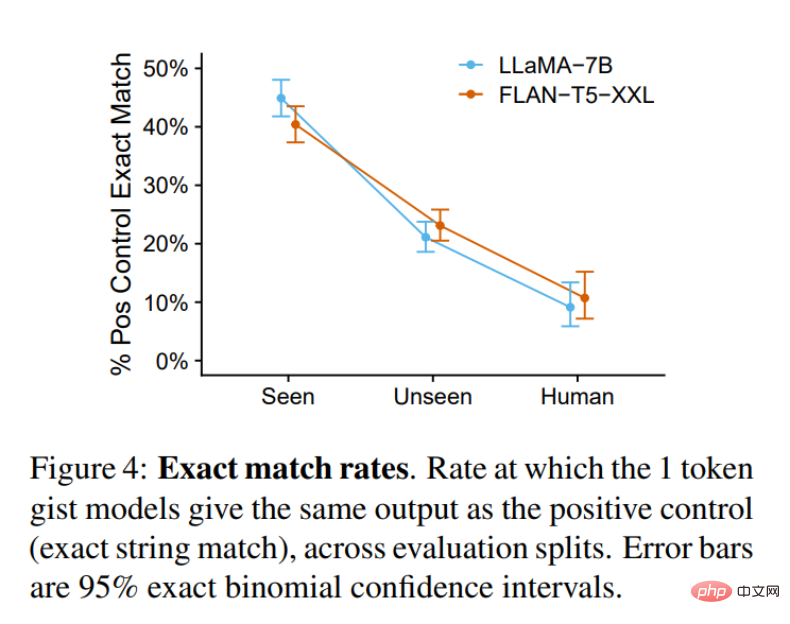
总的来说,这些结果表明,gist 模型可以可靠地压缩 prompt,甚至在训练分布之外的某些 prompt 上也可以做到这一点,特别是像 LLaMA 这样的 decoder-only 因果 LM。FLAN-T5 等 encoder-decoder 模型表现略差,一个可能的原因是 gist 掩膜抑制了编码器中的双向注意力流,这比仅 mask 自回归解码器的一部分 history 更具挑战性。未来需要进一步的工作来研究这个假设。
计算、内存和存储效率
最后,回到这项工作的核心动机之一:gisting 可以带来什么样的效率提升?
下表 2 展示了使用 PyTorch 2.0 分析器对模型进行单次前向传递的结果(即使用单个输入 token 的自回归解码的一步),并对 Human eval split 中的 252 个指令取平均值。与未经优化的模型相比,gist 缓存显著提高了效率。两种模型的 FLOPs 节约率达到了 40%,时钟时间降低了 4-7%。
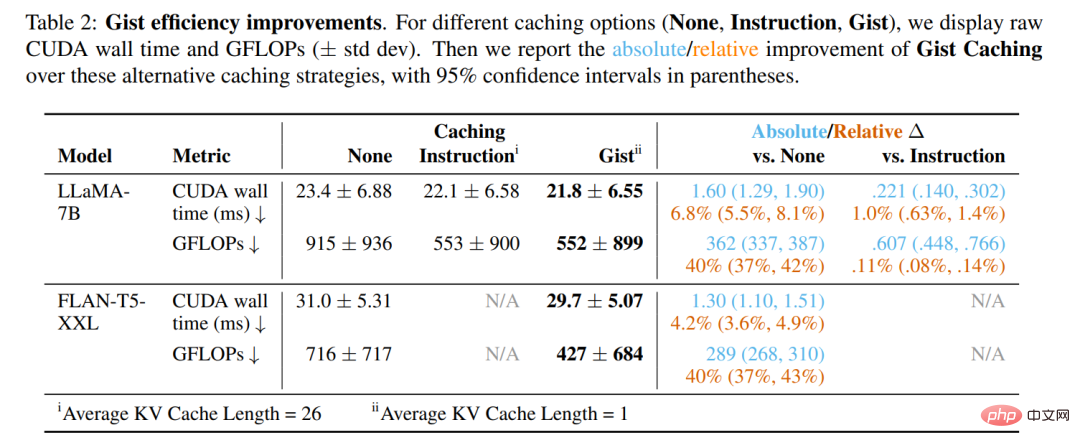
然而更重要的是,与指令缓存相比,gist 缓存有着除延迟之外的关键优势:将 26 个 token 压缩为 1 个可以在输入上下文窗口中腾出更多空间,这受到绝对位置嵌入或者 GPU VRAM 的限制。特别是对于 LLaMA-7B,KV 缓存中的每个 token 需要 1.05MB 的存储空间。尽管在测试的 prompt 长度下,KV 缓存相对于 LLaMA-7B 推断所需的内存总贡献微不足道,但一个越来越常见的场景是开发人员在大量用户之间缓存许多 prompt,存储成本很快就会增加。在存储空间相同的情况下,gist 缓存能比完整指令缓存多 26 倍的 prompt。
以上是将26个token压缩成1个新方法,极致节省ChatGPT输入框空间的详细内容。更多信息请关注PHP中文网其他相关文章!


 优化您的组织与Genai代理商的电子邮件营销Apr 13, 2025 am 11:44 AM
优化您的组织与Genai代理商的电子邮件营销Apr 13, 2025 am 11:44 AM介绍 恭喜!您经营一家成功的业务。通过您的网页,社交媒体活动,网络研讨会,会议,免费资源和其他来源,您每天收集5000个电子邮件ID。下一个明显的步骤是
 Apache Pinot实时应用程序性能监视Apr 13, 2025 am 11:40 AM
Apache Pinot实时应用程序性能监视Apr 13, 2025 am 11:40 AM介绍 在当今快节奏的软件开发环境中,确保最佳应用程序性能至关重要。监视实时指标,例如响应时间,错误率和资源利用率可以帮助MAIN
 Chatgpt击中了10亿用户? Openai首席执行官说:'短短几周内翻了一番Apr 13, 2025 am 11:23 AM
Chatgpt击中了10亿用户? Openai首席执行官说:'短短几周内翻了一番Apr 13, 2025 am 11:23 AM“您有几个用户?”他扮演。 阿尔特曼回答说:“我认为我们上次说的是每周5亿个活跃者,而且它正在迅速增长。” “你告诉我,就像在短短几周内翻了一番,”安德森继续说道。 “我说那个私人
 pixtral -12b:Mistral AI'第一个多模型模型 - 分析VidhyaApr 13, 2025 am 11:20 AM
pixtral -12b:Mistral AI'第一个多模型模型 - 分析VidhyaApr 13, 2025 am 11:20 AM介绍 Mistral发布了其第一个多模式模型,即Pixtral-12b-2409。该模型建立在Mistral的120亿参数Nemo 12B之上。是什么设置了该模型?现在可以拍摄图像和Tex
 生成AI应用的代理框架 - 分析VidhyaApr 13, 2025 am 11:13 AM
生成AI应用的代理框架 - 分析VidhyaApr 13, 2025 am 11:13 AM想象一下,拥有一个由AI驱动的助手,不仅可以响应您的查询,还可以自主收集信息,执行任务甚至处理多种类型的数据(TEXT,图像和代码)。听起来有未来派?在这个a




热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

Atom编辑器mac版下载
最流行的的开源编辑器

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

SublimeText3汉化版
中文版,非常好用

WebStorm Mac版
好用的JavaScript开发工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

