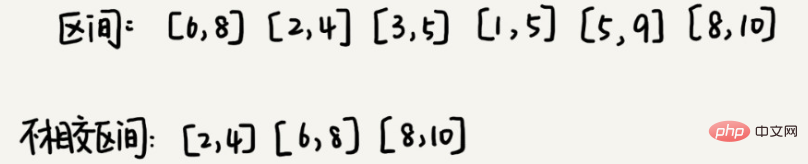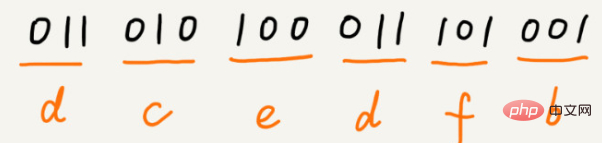有哪些常见的算法是Java开发中常用的呢?

- 王林转载
- 2023-05-09 10:04:151698浏览
贪心算法(greedy algorithm)
经典的应用:比如霍夫曼编码(Huffman Coding)、Prim 和 Kruskal 最小生成树算法、还有 Dijkstra 单源最短路径算法。
贪心算法解决问题的步骤
第一步,当我们看到这类问题的时候,首先要联想到贪心算法:针对一组数据,我们定义了限制值和期望值,希望从中选出几个数据,在满足限制值的情况下,期望值最大。
类比到刚刚的例子,限制值就是重量不能超过 100kg,期望值就是物品的总价值。这组数据就是 5 种豆子。我们从中选出一部分,满足重量不超过 100kg,并且总价值最大。
第二步,我们尝试看下这个问题是否可以用贪心算法解决:每次选择当前情况下,在对限制值同等贡献量的情况下,对期望值贡献最大的数据。
类比到刚刚的例子,我们每次都从剩下的豆子里面,选择单价最高的,也就是重量相同的情况下,对价值贡献最大的豆子。
第三步,我们举几个例子看下贪心算法产生的结果是否是最优的。大部分情况下,举几个例子验证一下就可以了。严格地证明贪心算法的正确性,是非常复杂的,需要涉及比较多的数学推理。
贪心算法不工作的主要原因是,前面的选择,会影响后面的选择。
贪心算法实战分析
1. 分糖果
我们有 m 个糖果和 n 个孩子。我们现在要把糖果分给这些孩子吃,但是糖果少,孩子多(m 我们可以把这个问题抽象成,从 n 个孩子中,抽取一部分孩子分配糖果,让满足的孩子的个数(期望值)是最大的。这个问题的限制值就是糖果个数 m。
我们每次从剩下的孩子中,找出对糖果大小需求最小的,然后发给他剩下的糖果中能满足他的最小的糖果,这样得到的分配方案,也就是满足的孩子个数最多的方案。
2. 钱币找零
这个问题在我们的日常生活中更加普遍。假设我们有 1 元、2 元、5 元、10 元、20 元、50 元、100 元这些面额的纸币,它们的张数分别是 c1、c2、c5、c10、c20、c50、c100。我们现在要用这些钱来支付 K 元,最少要用多少张纸币呢?
生活中,我们肯定是先用面值最大的来支付,如果不够,就继续用更小一点面值的,以此类推,最后剩下的用 1 元来补齐。在贡献相同期望值(纸币数目)的情况下,我们希望多贡献点金额,这样就可以让纸币数更少,这就是一种贪心算法的解决思路。
3. 区间覆盖
假设我们有 n 个区间,区间的起始端点和结束端点分别是 [l1, r1],[l2, r2],[l3, r3],……,[ln, rn]。我们从这 n 个区间中选出一部分区间,这部分区间满足两两不相交(端点相交的情况不算相交),最多能选出多少个区间呢?
这个处理思想在很多贪心算法问题中都有用到,比如任务调度、教师排课等等问题。
这个问题的解决思路是这样的:我们假设这 n 个区间中最左端点是 lmin,最右端点是 rmax。这个问题就相当于,我们选择几个不相交的区间,从左到右将 [lmin, rmax] 覆盖上。我们按照起始端点从小到大的顺序对这 n 个区间排序。
我们每次选择的时候,左端点跟前面的已经覆盖的区间不重合的,右端点又尽量小的,这样可以让剩下的未覆盖区间尽可能的大,就可以放置更多的区间。这实际上就是一种贪心的选择方法。
如何用贪心算法实现霍夫曼编码?
霍夫曼编码用这种不等长的编码方法,编码字符。要求各个字符的编码之间,不会出现某个编码是另一个编码前缀的情况。把出现频率比较多的字符,用稍微短一些的编码;出现频率比较少的字符,用稍微长一些的编码。
假设我有一个包含 1000 个字符的文件,每个字符占 1 个 byte(1byte=8bits),存储这 1000 个字符就一共需要 8000bits,那有没有更加节省空间的存储方式呢?
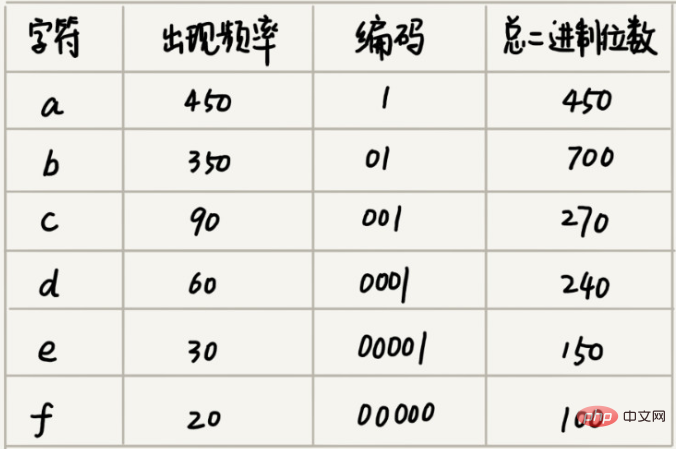
假设我们通过统计分析发现,这 1000 个字符中只包含 6 种不同字符,假设它们分别是 a、b、c、d、e、f。而 3 个二进制位(bit)就可以表示 8 个不同的字符,所以,为了尽量减少存储空间,每个字符我们用 3 个二进制位来表示。那存储这 1000 个字符只需要 3000bits 就可以了,比原来的存储方式节省了很多空间。不过,还有没有更加节省空间的存储方式呢?
a(000)、b(001)、c(010)、d(011)、e(100)、f(101)
霍夫曼编码是一种十分有效的编码方法,广泛用于数据压缩中,其压缩率通常在 20%~90% 之间。
霍夫曼编码不仅会考察文本中有多少个不同字符,还会考察每个字符出现的频率,根据频率的不同,选择不同长度的编码。霍夫曼编码试图用这种不等长的编码方法,来进一步增加压缩的效率。如何给不同频率的字符选择不同长度的编码呢?根据贪心的思想,我们可以把出现频率比较多的字符,用稍微短一些的编码;出现频率比较少的字符,用稍微长一些的编码。
编码不等长,如何读出来解析?
对于等长的编码来说,我们解压缩起来很简单。比如刚才那个例子中,我们用 3 个 bit 表示一个字符。在解压缩的时候,我们每次从文本中读取 3 位二进制码,然后翻译成对应的字符。但是,霍夫曼编码是不等长的,每次应该读取 1 位还是 2 位、3 位等等来解压缩呢?这个问题就导致霍夫曼编码解压缩起来比较复杂。为了避免解压缩过程中的歧义,霍夫曼编码要求各个字符的编码之间,不会出现某个编码是另一个编码前缀的情况。
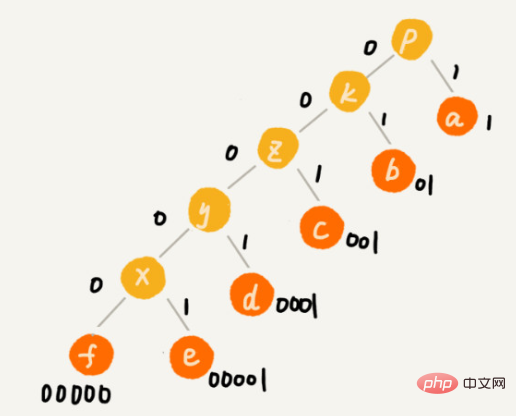
假设这 6 个字符出现的频率从高到低依次是 a、b、c、d、e、f。我们把它们编码下面这个样子,任何一个字符的编码都不是另一个的前缀,在解压缩的时候,我们每次会读取尽可能长的可解压的二进制串,所以在解压缩的时候也不会歧义。经过这种编码压缩之后,这 1000 个字符只需要 2100bits 就可以了。
尽管霍夫曼编码的思想并不难理解,但是如何根据字符出现频率的不同,给不同的字符进行不同长度的编码呢?
利用大顶堆,根据频率放字符。
分治算法
分治算法(divide and conquer)的核心思想其实就是四个字,分而治之 ,也就是将原问题划分成 n 个规模较小,并且结构与原问题相似的子问题,递归地解决这些子问题,然后再合并其结果,就得到原问题的解。
分治算法是一种处理问题的思想,递归是一种编程技巧。实际上,分治算法一般都比较适合用递归来实现。分治算法的递归实现中,每一层递归都会涉及这样三个操作:
分解:将原问题分解成一系列子问题; 解决:递归地求解各个子问题,若子问题足够小,则直接求解; 合并:将子问题的结果合并成原问题。 分治算法能解决的问题,一般需要满足下面这几个条件:
原问题与分解成的小问题具有相同的模式; 原问题分解成的子问题可以独立求解,子问题之间没有相关性 具有分解终止条件,也就是说,当问题足够小时,可以直接求解; 可以将子问题合并成原问题,而这个合并操作的复杂度不能太高,否则就起不到减小算法总体复杂度的效果了。 分治算法应用举例分析
如何编程求出一组数据的有序对个数或者逆序对个数呢?
拿每个数字跟它后面的数字比较,看有几个比它小的。我们把比它小的数字个数记作 k,通过这样的方式,把每个数字都考察一遍之后,然后对每个数字对应的 k 值求和,最后得到的总和就是逆序对个数。不过,这样操作的时间复杂度是 O(n^2)。
我们可以将数组分成前后两半 A1 和 A2,分别计算 A1 和 A2 的逆序对个数 K1 和 K2,然后再计算 A1 与 A2 之间的逆序对个数 K3。那数组 A 的逆序对个数就等于 K1+K2+K3。借助归并排序算法
给 10GB 的订单文件按照金额排序这样一个需求?
我们就可以先扫描一遍订单,根据订单的金额,将 10GB 的文件划分为几个金额区间。比如订单金额为 1 到 100 元的放到一个小文件,101 到 200 之间的放到另一个文件,以此类推。这样每个小文件都可以单独加载到内存排序,最后将这些有序的小文件合并,就是最终有序的 10GB 订单数据了。
回溯算法
应用场景:深度优先搜索,正则表达式匹配、编译原理中的语法分析。很多经典的数学问题都可以用回溯算法解决,比如数独、八皇后、0-1 背包、图的着色、旅行商问题、全排列等等
回溯的处理思想,有点类似枚举搜索。我们枚举所有的解,找到满足期望的解。为了有规律地枚举所有可能的解,避免遗漏和重复,我们把问题求解的过程分为多个阶段。每个阶段,我们都会面对一个岔路口,我们先随意选一条路走,当发现这条路走不通的时候(不符合期望的解),就回退到上一个岔路口,另选一种走法继续走。
八皇后问题
我们有一个 8x8 的棋盘,希望往里放 8 个棋子(皇后),每个棋子所在的行、列、对角线都不能有另一个棋子。
1.0-1 背包
很多场景都可以抽象成这个问题模型。这个问题的经典解法是动态规划,不过还有一种简单但没有那么高效的解法,那就是今天讲的回溯算法。
我们有一个背包,背包总的承载重量是 Wkg。现在我们有 n 个物品,每个物品的重量不等,并且不可分割。我们现在期望选择几件物品,装载到背包中。在不超过背包所能装载重量的前提下,如何让背包中物品的总重量最大?
对于每个物品来说,都有两种选择,装进背包或者不装进背包。对于 n 个物品来说,总的装法就有 2^n 种,去掉总重量超过 Wkg 的,从剩下的装法中选择总重量最接近 Wkg 的。不过,我们如何才能不重复地穷举出这 2^n 种装法呢?
回溯方法:我们可以把物品依次排列,整个问题就分解为了 n 个阶段,每个阶段对应一个物品怎么选择。先对第一个物品进行处理,选择装进去或者不装进去,然后再递归地处理剩下的物品。
动态规划
动态规划比较适合用来求解最优问题,比如求最大值、最小值等等。它可以非常显著地降低时间复杂度,提高代码的执行效率。
0-1 背包问题
对于一组不同重量、不可分割的物品,我们需要选择一些装入背包,在满足背包最大重量限制的前提下,背包中物品总重量的最大值是多少呢?
思路:
(1)把整个求解过程分为 n 个阶段,每个阶段会决策一个物品是否放到背包中。每个物品决策(放入或者不放入背包)完之后,背包中的物品的重量会有多种情况,也就是说,会达到多种不同的状态,对应到递归树中,就是有很多不同的节点。
(2)我们把每一层重复的状态(节点)合并,只记录不同的状态,然后基于上一层的状态集合,来推导下一层的状态集合。我们可以通过合并每一层重复的状态,这样就保证每一层不同状态的个数都不会超过 w 个(w 表示背包的承载重量),也就是例子中的 9。
划分n个阶段,每一个阶段基于上一个阶段推导,动态地往前推进,就避免了重复计算。
用回溯算法解决这个问题的时间复杂度 O(2^n),是指数级的。那动态规划解决方案的时间复杂度是多少呢?
耗时最多的部分就是代码中的两层 for 循环,所以时间复杂度是 O(n*w)。n 表示物品个数,w 表示背包可以承载的总重量。我们需要额外申请一个 n 乘以 w+1 的二维数组,对空间的消耗比较多。所以,有时候,我们会说,动态规划是一种空间换时间的解决思路。
0-1 背包问题升级版
对于一组不同重量、不同价值、不可分割的物品,我们选择将某些物品装入背包,在满足背包最大重量限制的前提下,背包中可装入物品的总价值最大是多少呢?
什么样的问题适合用动态规划来解决呢?
一个模型三个特征
一个模型:多阶段决策最优解模型
三个特征:
最优子结构,问题的最优解包含子问题的最优解 无后效性,第一层含义是,在推导后面阶段的状态的时候,我们只关心前面阶段的状态值,不关心这个状态是怎么一步一步推导出来的。第二层含义是,某阶段状态一旦确定,就不受之后阶段的决策影响。(后面的不影响前面的。) 重复子问题,不同的决策序列,到达某个相同的阶段时,可能会产生重复的状态。 两种动态规划解题思路总结
1. 状态转移表法
一般能用动态规划解决的问题,都可以使用回溯算法的暴力搜索解决。画出递归树。从递归树中,我们很容易可以看出来,是否存在重复子问题,以及重复子问题是如何产生的
找到重复子问题之后,接下来,我们有两种处理思路,第一种是直接用回溯加“备忘录”的方法,来避免重复子问题。从执行效率上来讲,这跟动态规划的解决思路没有差别。第二种是使用动态规划的解决方法,状态转移表法。
我们先画出一个状态表。状态表一般都是二维的,所以你可以把它想象成二维数组。其中,每个状态包含三个变量,行、列、数组值。我们根据决策的先后过程,从前往后,根据递推关系,分阶段填充状态表中的每个状态。最后,我们将这个递推填表的过程,翻译成代码,就是动态规划代码了。
需要很多变量来表示,那对应的状态表可能就是高维的,比如三维、四维。那这个时候,我们就不适合用状态转移表法来解决了。一方面是因为高维状态转移表不好画图表示,另一方面是因为人脑确实很不擅长思考高维的东西。
2. 状态转移方程法
我们需要分析,某个问题如何通过子问题来递归求解,也就是所谓的最优子结构。根据最优子结构,写出递归公式,也就是所谓的状态转移方程。有了状态转移方程,代码实现就非常简单了。一般情况下,我们有两种代码实现方法,一种是递归加“备忘录”,另一种是迭代递推。
min_dist(i, j) = w[i][j] + min(min_dist(i, j-1), min_dist(i-1, j))
我要强调一点,不是每个问题都同时适合这两种解题思路。有的问题可能用第一种思路更清晰,而有的问题可能用第二种思路更清晰,所以,你要结合具体的题目来看,到底选择用哪种解题思路。 状态转移表法解题思路大致可以概括为,回溯算法实现 - 定义状态 - 画递归树 - 找重复子问题 - 画状态转移表 - 根据递推关系填表 - 将填表过程翻译成代码。状态转移方程法的大致思路可以概括为,找最优子结构 - 写状态转移方程 - 将状态转移方程翻译成代码。
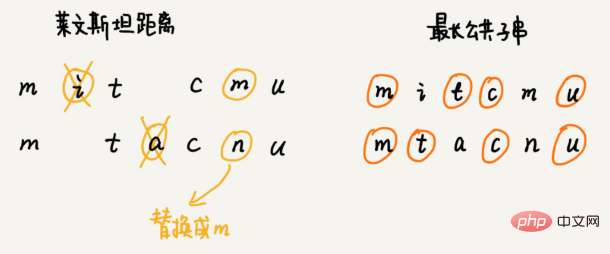
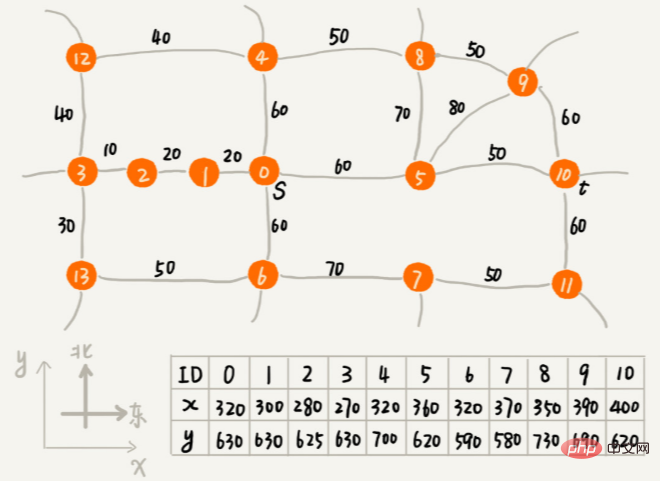
如何量化两个字符串的相似度? 编辑距离指的就是,将一个字符串转化成另一个字符串,需要的最少编辑操作次数(比如增加一个字符、删除一个字符、替换一个字符)。编辑距离越大,说明两个字符串的相似程度越小;相反,编辑距离就越小,说明两个字符串的相似程度越大。对于两个完全相同的字符串来说,编辑距离就是 0。 编辑距离有多种不同的计算方式,比较著名的有莱文斯坦距离(Levenshtein distance)和最长公共子串长度(Longest common substring length)。其中,莱文斯坦距离允许增加、删除、替换字符这三个编辑操作,最长公共子串长度只允许增加、删除字符这两个编辑操作。 莱文斯坦距离和最长公共子串长度,从两个截然相反的角度,分析字符串的相似程度。莱文斯坦距离的大小,表示两个字符串差异的大小;而最长公共子串的大小,表示两个字符串相似程度的大小。 两个字符串 mitcmu 和 mtacnu 的莱文斯坦距离是 3,最长公共子串长度是 4。 如何编程计算莱文斯坦距离? 这个问题是求把一个字符串变成另一个字符串,需要的最少编辑次数。整个求解过程,涉及多个决策阶段,我们需要依次考察一个字符串中的每个字符,跟另一个字符串中的字符是否匹配,匹配的话如何处理,不匹配的话又如何处理。所以,这个问题符合多阶段决策最优解模型。 推荐算法 利用向量的距离,求相似成度。 搜索:如何用A*搜索算法实现游戏中的寻路功能? 那如何快速找出一条接近于最短路线的次优路线呢? 这个快速的路径规划算法,就是我们今天要学习的A* 算法。实际上,A* 算法是对 Dijkstra 算法的优化和改造。 通过这个顶点跟终点之间的直线距离,也就是欧几里得距离来近似地估计这个顶点跟终点的路径长度(注意:路径长度跟直线距离是两个概念) 这个距离记作 h(i)(i 表示这个顶点的编号),专业的叫法是启发函数(heuristic function) 因为欧几里得距离的计算公式,会涉及比较耗时的开根号计算,所以,我们一般通过另外一个更加简单的距离计算公式,那就是曼哈顿距离(Manhattan distance) 曼哈顿距离是两点之间横纵坐标的距离之和。计算的过程只涉及加减法、符号位反转,所以比欧几里得距离更加高效。 int hManhattan(Vertex v1, Vertex v2) { // Vertex 表示顶点,后面有定义
return Math.abs(v1.x - v2.x) + Math.abs(v1.y - v2.y);
}
f(i)=g(i)+h(i),顶点与起点之间的路径长度 g(i),顶点到终点的路径长度估计值h(i). f(i) 的专业叫法是估价函数(evaluation function)。 A* 算法就是对 Dijkstra 算法的简单改造, f(i) 最小的先出列。 它跟 Dijkstra 算法的代码实现,主要有 3 点区别: 优先级队列构建的方式不同。A* 算法是根据 f 值(也就是刚刚讲到的 f(i)=g(i)+h(i))来构建优先级队列,而 Dijkstra 算法是根据 dist 值(也就是刚刚讲到的 g(i))来构建优先级队列; A* 算法在更新顶点 dist 值的时候,会同步更新 f 值; 循环结束的条件也不一样。Dijkstra 算法是在终点出队列的时候才结束,A* 算法是一旦遍历到终点就结束。 以上是有哪些常见的算法是Java开发中常用的呢?的详细内容。更多信息请关注PHP中文网其他相关文章!