



apscheduler 模块
安装apscheduler 模块
pip install apscheduler
apscheduler 模块介绍
APScheduler(Advanced Python Scheduler)是一个轻量级的Python定时任务调度框架(Python库)。
APScheduler有三个内置的调度系统,其中包括:
cron式调度(可选开始/结束时间)
基于间隔的执行(以偶数间隔运行作业,也可以选择开始/结束时间)
一次性延迟执行任务(在指定的日期/时间内运行作业一次)
支持的后端存储作业
APScheduler可以任意混合和匹配调度系统和作业存储的后端,其中支持后端存储作业包括:
Memory
SQLAlchemy
MongoDB
Redis
RethinkDB
ZooKeeper
APScheduler有四种组成部分
triggers(触发器)中包含调度逻辑,每个作业都由自己的触发器来决定下次运行时间。除了他们自己初始配置意外,触发器完全是无状态的。
job stores(作业存储器)存储被调度的作业,默认的作业存储器只是简单地把作业保存在内存中,其他的作业存储器则是将作业保存在数据库中。当作业被保存到一个持久化的作业存储器中的时候,该作业的数据会被序列化,并在加载时被反序列化。作业存储器不能共享调度器。
executors(执行器)处理作业的运行,他们通常通过在作业中提交指定的可调用对象到一个线程或者进程池来进行。当作业完成时,执行器将会通知调度器。
schedulers(调度器)配置作业存储器和执行器可以在调度器中完成,例如添加、修改和移除作业。根据不同的应用场景可以选用不同的调度器,可选的有BlockingScheduler,BackgroundScheduler,AsyncIOScheduler,GeventScheduler,TornadoScheduler,TwistedScheduler,QtScheduler 7种。
各组件简介
触发器
当你调度作业的时候,你需要为这个作业选择一个触发器,用来描述这个作业何时被触发,APScheduler有三种内置的触发器类型:
date: 一次性指定日期;
interval: 在某个时间范围内间隔多长时间执行一次;
cron :Linux crontab格式兼容,最为强大。
date 最基本的一种调度,作业只会执行一次。它的参数如下:
1.run_date
(datetime|str) – 作业的运行日期或时间
2.timezone
(datetime.tzinfo|str) – 指定时区
作业存储器
如果你的应用在每次启动的时候都会重新创建作业,那么使用默认的作业存储器(MemoryJobStore)即可,但是如果你需要在调度器重启或者应用程序奔溃的情况下任然保留作业,你应该根据你的应用环境来选择具体的作业存储器。例如:使用Mongo或者SQLAlchemy JobStore (用于支持大多数RDBMS)
执行器
对执行器的选择取决于你使用上面哪些框架,大多数情况下,使用默认的ThreadPoolExecutor已经能够满足需求。如果你的应用涉及到CPU密集型操作,你可以考虑使用ProcessPoolExecutor来使用更多的CPU核心。你也可以同时使用两者,将ProcessPoolExecutor作为第二执行器。
选择合适的调度器
BlockingScheduler : 当调度器是你应用中唯一要运行的东西时
BackgroundScheduler : 当你没有运行任何其他框架并希望调度器在你应用的后台执行时使用。
AsyncIOScheduler : 当你的程序使用了asyncio(一个异步框架)的时候使用。
GeventScheduler : 当你的程序使用了gevent(高性能的Python并发框架)的时候使用。
TornadoScheduler : 当你的程序基于Tornado(一个web框架)的时候使用。
TwistedScheduler : 当你的程序使用了Twisted(一个异步框架)的时候使用
QtScheduler : 如果你的应用是一个Qt应用的时候可以使用。
apscheduler 模块使用
添加作业
有两种方式可以添加一个新的作业:
add_job来添加作业;
# -*- coding:utf-8 -*-
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
def my_job1():
print('my_job1 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
def my_job2():
print('my_job2 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
sched = BlockingScheduler()
# 每隔5秒运行一次my_job1
sched.add_job(my_job1, 'interval', seconds=5, id='my_job1')
# 每隔5秒运行一次my_job2
sched.add_job(my_job2, 'cron', second='*/5', id='my_job2')
sched.start()装饰器模式添加作业。
# -*- coding:utf-8 -*-
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
sched = BlockingScheduler()
# 每隔5秒运行一次my_job1
@sched.scheduled_job('interval', seconds=5, id='my_job1')
def my_job1():
print('my_job1 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
# 每隔5秒运行一次my_job2
@sched.scheduled_job('cron', second='*/5', id='my_job2')
def my_job2():
print('my_job2 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
sched.start()移除作业
没有移除作业
# -*- coding:utf-8 -*-
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
def my_job(text=""):
print(text, 'my_job1 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
sched = BlockingScheduler()
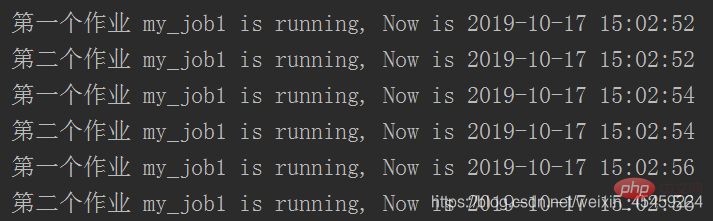
job = sched.add_job(my_job, 'interval', seconds=2, args=['第一个作业'])
# #如果有多个任务序列的话可以给每个任务设置ID号,可以根据ID号选择清除对象,且remove放到start前才有效
sched.add_job(my_job, 'interval', seconds=2, id='my_job_id', args=['第二个作业'])
sched.start()代码执行结果:
使用remove() 移除作业
# -*- coding:utf-8 -*-
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
def my_job(text=""):
print(text, 'my_job1 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
sched = BlockingScheduler()
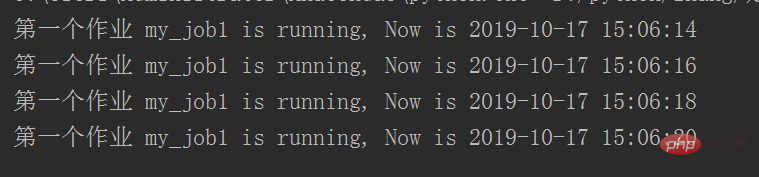
job = sched.add_job(my_job, 'interval', seconds=2, args=['第一个作业'])
job.remove()
# #如果有多个任务序列的话可以给每个任务设置ID号,可以根据ID号选择清除对象,且remove放到start前才有效
sched.add_job(my_job, 'interval', seconds=2, id='my_job_id', args=['第二个作业'])
sched.start()代码执行结果:

使用remove_job()移除作业
# -*- coding:utf-8 -*-
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
def my_job(text=""):
print(text, 'my_job1 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
sched = BlockingScheduler()
job = sched.add_job(my_job, 'interval', seconds=2, args=['第一个作业'])
# #如果有多个任务序列的话可以给每个任务设置ID号,可以根据ID号选择清除对象,且remove放到start前才有效
sched.add_job(my_job, 'interval', seconds=2, id='my_job_id', args=['第二个作业'])
sched.remove_job('my_job_id')
sched.start()代码执行结果:
触发器类型
APScheduler有3中内置的触发器类型:
新建一个调度器(scheduler);
添加一个调度任务(job store);
运行调度任务。
代码实现
# -*- coding:utf-8 -*-
import time
import datetime
from apscheduler.schedulers.blocking import BlockingScheduler
def my_job(text="默认值"):
print(text, time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())))
sched = BlockingScheduler()
sched.add_job(my_job, 'interval', seconds=3, args=['3秒定时'])
# 2018-3-17 00:00:00 执行一次,args传递一个text参数
sched.add_job(my_job, 'date', run_date=datetime.date(2019, 10, 17), args=['根据年月日定时执行'])
# 2018-3-17 13:46:00 执行一次,args传递一个text参数
sched.add_job(my_job, 'date', run_date=datetime.datetime(2019, 10, 17, 14, 10, 0), args=['根据年月日时分秒定时执行'])
# sched.start()
"""
interval 间隔调度,参数如下:
weeks (int) – 间隔几周
days (int) – 间隔几天
hours (int) – 间隔几小时
minutes (int) – 间隔几分钟
seconds (int) – 间隔多少秒
start_date (datetime|str) – 开始日期
end_date (datetime|str) – 结束日期
timezone (datetime.tzinfo|str) – 时区
"""
"""
cron参数如下:
year (int|str) – 年,4位数字
month (int|str) – 月 (范围1-12)
day (int|str) – 日 (范围1-31)
week (int|str) – 周 (范围1-53)
day_of_week (int|str) – 周内第几天或者星期几 (范围0-6 或者 mon,tue,wed,thu,fri,sat,sun)
hour (int|str) – 时 (范围0-23)
minute (int|str) – 分 (范围0-59)
second (int|str) – 秒 (范围0-59)
start_date (datetime|str) – 最早开始日期(包含)
end_date (datetime|str) – 最晚结束时间(包含)
timezone (datetime.tzinfo|str) – 指定时区
"""
# my_job将会在6,7,8,11,12月的第3个周五的1,2,3点运行
sched.add_job(my_job, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3')
# 截止到2018-12-30 00:00:00,每周一到周五早上五点半运行job_function
sched.add_job(my_job, 'cron', day_of_week='mon-fri', hour=5, minute=30, end_date='2018-12-31')
# 表示2017年3月22日17时19分07秒执行该程序
sched.add_job(my_job, 'cron', year=2017, month=3, day=22, hour=17, minute=19, second=7)
# 表示任务在6,7,8,11,12月份的第三个星期五的00:00,01:00,02:00,03:00 执行该程序
sched.add_job(my_job, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3')
# 表示从星期一到星期五5:30(AM)直到2014-05-30 00:00:00
sched.add_job(my_job, 'cron', day_of_week='mon-fri', hour=5, minute=30, end_date='2014-05-30')
# 表示每5秒执行该程序一次,相当于interval 间隔调度中seconds = 5
sched.add_job(my_job, 'cron', second='*/5', args=['5秒定时'])
sched.start()| cron表达式 | 参数 | 描述 |
|---|---|---|
| * | any | Fire on every value |
| */a | any | Fire every a values, starting from the minimum |
| a-b | any | Fire on any value within the a-b range (a must be smaller than b) |
| a-b/c | any | Fire every c values within the a-b range |
| xth y | day | Fire on the x -th occurrence of weekday y within the month |
| last x | day | Fire on the last occurrence of weekday x within the month |
| last | day | Fire on the last day within the month |
| x,y,z | any | Fire on any matching expression; can combine any number of any of the above expressions |
使用SQLAlchemy作业存储器存放作业
# -*- coding:utf-8 -*-
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
import logging
sched = BlockingScheduler()
def my_job():
print('my_job is running, Now is %s' % datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
# 使用sqlalchemy作业存储器
# 根据自己电脑安装的库选择用什么连接 ,如pymysql 其中:scrapy表示数据库的名称,操作数据库之前应创建对应的数据库
url = 'mysql+pymysql://root:123456@localhost:3306/scrapy?charset=utf8'
sched.add_jobstore('sqlalchemy', url=url)
# 添加作业
sched.add_job(my_job, 'interval', id='myjob', seconds=5)
log = logging.getLogger('apscheduler.executors.default')
log.setLevel(logging.INFO) # DEBUG
# 设定日志格式
fmt = logging.Formatter('%(levelname)s:%(name)s:%(message)s')
h = logging.StreamHandler()
h.setFormatter(fmt)
log.addHandler(h)
sched.start()暂停和恢复作业
# 暂停作业: apsched.job.Job.pause() apsched.schedulers.base.BaseScheduler.pause_job() # 恢复作业: apsched.job.Job.resume() apsched.schedulers.base.BaseScheduler.resume_job()
获得job列表
get_jobs(),它会返回所有的job实例;
使用print_jobs()来输出所有格式化的作业列表;
get_job(job_id=“任务ID”)获取指定任务的作业列表。
代码实现:
# -*- coding:utf-8 -*-
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
def my_job(text=""):
print(text, 'my_job1 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
sched = BlockingScheduler()
job = sched.add_job(my_job, 'interval', seconds=2, args=['第一个作业'])
sched.add_job(my_job, 'interval', seconds=2, id='my_job_id', args=['第二个作业'])
print(sched.get_jobs())
print(sched.get_job(job_id="my_job_id"))
sched.print_jobs()
sched.start()关闭调度器
默认情况下调度器会等待所有正在运行的作业完成后,关闭所有的调度器和作业存储。如果你不想等待,可以将wait选项设置为False。
sched.shutdown() sched.shutdown(wait=False)
以上是如何安装和使用Python中的第三方模块apscheduler?的详细内容。更多信息请关注PHP中文网其他相关文章!

 Python与C:学习曲线和易用性Apr 19, 2025 am 12:20 AM
Python与C:学习曲线和易用性Apr 19, 2025 am 12:20 AMPython更易学且易用,C 则更强大但复杂。1.Python语法简洁,适合初学者,动态类型和自动内存管理使其易用,但可能导致运行时错误。2.C 提供低级控制和高级特性,适合高性能应用,但学习门槛高,需手动管理内存和类型安全。
 Python vs. C:内存管理和控制Apr 19, 2025 am 12:17 AM
Python vs. C:内存管理和控制Apr 19, 2025 am 12:17 AMPython和C 在内存管理和控制方面的差异显着。 1.Python使用自动内存管理,基于引用计数和垃圾回收,简化了程序员的工作。 2.C 则要求手动管理内存,提供更多控制权但增加了复杂性和出错风险。选择哪种语言应基于项目需求和团队技术栈。
 科学计算的Python:详细的外观Apr 19, 2025 am 12:15 AM
科学计算的Python:详细的外观Apr 19, 2025 am 12:15 AMPython在科学计算中的应用包括数据分析、机器学习、数值模拟和可视化。1.Numpy提供高效的多维数组和数学函数。2.SciPy扩展Numpy功能,提供优化和线性代数工具。3.Pandas用于数据处理和分析。4.Matplotlib用于生成各种图表和可视化结果。
 Python和C:找到合适的工具Apr 19, 2025 am 12:04 AM
Python和C:找到合适的工具Apr 19, 2025 am 12:04 AM选择Python还是C 取决于项目需求:1)Python适合快速开发、数据科学和脚本编写,因其简洁语法和丰富库;2)C 适用于需要高性能和底层控制的场景,如系统编程和游戏开发,因其编译型和手动内存管理。
 数据科学和机器学习的PythonApr 19, 2025 am 12:02 AM
数据科学和机器学习的PythonApr 19, 2025 am 12:02 AMPython在数据科学和机器学习中的应用广泛,主要依赖于其简洁性和强大的库生态系统。1)Pandas用于数据处理和分析,2)Numpy提供高效的数值计算,3)Scikit-learn用于机器学习模型构建和优化,这些库让Python成为数据科学和机器学习的理想工具。
 学习Python:2小时的每日学习是否足够?Apr 18, 2025 am 12:22 AM
学习Python:2小时的每日学习是否足够?Apr 18, 2025 am 12:22 AM每天学习Python两个小时是否足够?这取决于你的目标和学习方法。1)制定清晰的学习计划,2)选择合适的学习资源和方法,3)动手实践和复习巩固,可以在这段时间内逐步掌握Python的基本知识和高级功能。
 Web开发的Python:关键应用程序Apr 18, 2025 am 12:20 AM
Web开发的Python:关键应用程序Apr 18, 2025 am 12:20 AMPython在Web开发中的关键应用包括使用Django和Flask框架、API开发、数据分析与可视化、机器学习与AI、以及性能优化。1.Django和Flask框架:Django适合快速开发复杂应用,Flask适用于小型或高度自定义项目。2.API开发:使用Flask或DjangoRESTFramework构建RESTfulAPI。3.数据分析与可视化:利用Python处理数据并通过Web界面展示。4.机器学习与AI:Python用于构建智能Web应用。5.性能优化:通过异步编程、缓存和代码优
 Python vs.C:探索性能和效率Apr 18, 2025 am 12:20 AM
Python vs.C:探索性能和效率Apr 18, 2025 am 12:20 AMPython在开发效率上优于C ,但C 在执行性能上更高。1.Python的简洁语法和丰富库提高开发效率。2.C 的编译型特性和硬件控制提升执行性能。选择时需根据项目需求权衡开发速度与执行效率。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

SublimeText3汉化版
中文版,非常好用

Dreamweaver Mac版
视觉化网页开发工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

