



在开源了「分割一切」的 SAM 模型后,Meta 在「视觉基础模型」的路上越走越远。
这次,他们开源的是一组名叫 DINOv2 的模型。这些模型能产生高性能的视觉表征,无需微调就能用于分类、分割、图像检索、深度估计等下游任务。
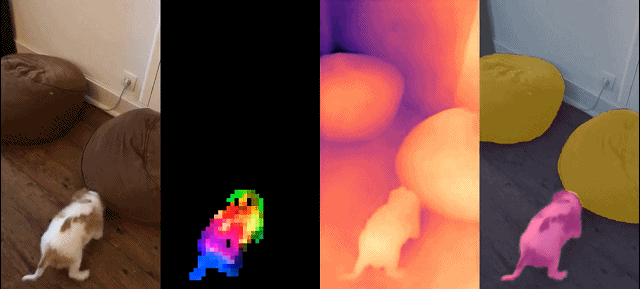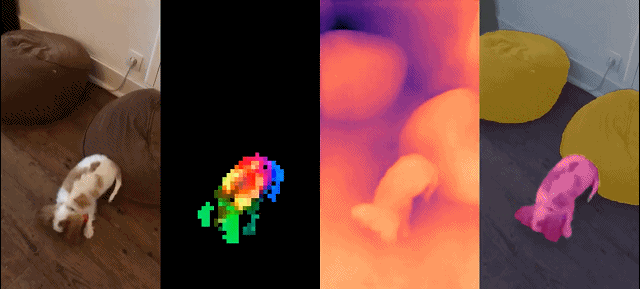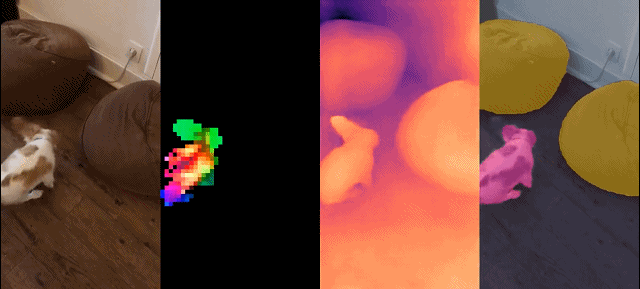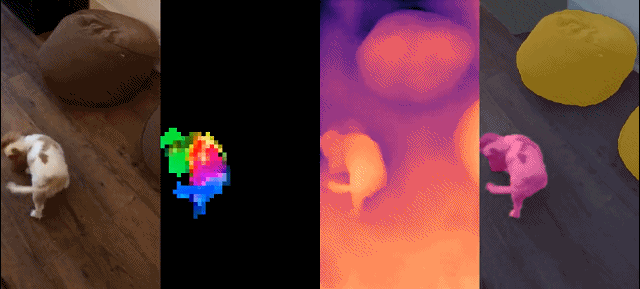
这组模型具有如下特征:
- 使用自监督的方式进行训练,而不需要大量的标记数据;
- 可以用作几乎所有 CV 任务的骨干,不需要微调,如图像分类、分割、图像检索和深度估计;
- 直接从图像中学习特征,而不依赖文本描述,这可以使模型更好地理解局部信息;
- 可以从任何图像集合中学习;
- DINOv2 的预训练版本已经可用,并可以在一系列任务上媲美 CLIP 和 OpenCLIP。

- 论文链接:https://arxiv.org/pdf/2304.07193.pdf
- 项目链接:https://dinov2.metademolab.com/
论文概览
学习非特定任务的预训练表示已成为自然语言处理的标准。大家可以「按原样」使用这些功能(无需微调),并且它们在下游任务上的表现明显优于特定任务模型的性能。这一成功得益于使用辅助目标对大量原始文本进行预训练,例如语言建模或词向量,这些不需要监督。
随着 NLP 领域发生这种范式转变,预计类似的「基础」模型将出现在计算机视觉中。这些模型应该生成在任何任务上「开箱即用」的视觉特征,无论是在图像级别(例如图像分类)还是像素级别(例如分割)。
这些基础模型有很大希望可以集中在文本引导(text-guided)的预训练上,即使用一种文本监督的形式来指导特征的训练。这种形式的文本引导预训练限制了可以保留的有关图像的信息,因为标题仅近似于图像中的丰富信息,并且更精细、复杂的像素级信息可能无法通过此监督被发现。此外,这些图像编码器需要已经对齐好的文本 - 图像语料库,不能提供其文本对应物的灵活性,也就是说不能仅从原始数据中学习。
文本引导预训练的替代方法是自监督学习,其中特征仅从图像中学习。这些方法在概念上更接近语言建模等前置任务,并且可以在图像和像素级别捕获信息。然而,尽管它们有可能去学习通用特征,但自监督学习的大部分效果提升都是在小型精编数据集 ImageNet1k 的预训练背景下取得的。一些研究人员已经尝试将这些方法扩展到 ImageNet-1k 之外的一些努力,但他们专注于未经筛选的数据集,这通常会导致性能质量显着下降。这是由于缺乏对数据质量和多样性的控制,而数据质量和多样性对于产生良好的结果至关重要。
在这项工作中,研究者探讨了如果在大量精编数据上进行预训练,自监督学习是否有可能去学习通用的视觉特征。它们重新审视了现有的在图像和 patch 级别学习特征的判别性自监督方法,例如 iBOT,并在更大数据集下重新考虑他们的一些设计选择。研究者的大多数技术贡献都是为了在扩展模型和数据大小时稳定和加速判别性自监督学习而量身定制的。这些改进使他们方法的速度提升到了类似的判别性自监督方法的 2 倍左右,需要的内存减少到了后者的 1/3,使他们能够利用更长的训练和更大的 batch size。
关于预训练数据,他们构建了一个自动 pipeline ,用于从大量未经筛选的图像集合中过滤和重新平衡数据集。这个灵感来自 NLP 中使用的 pipeline ,其中使用数据相似性而不是外部元数据,并且不需要手动注释。在处理图像时的一个主要困难是重新平衡概念并且要避免在一些主导模式下出现过拟合。在这项工作中,朴素聚类方法可以很好地解决此问题,研究人员们收集了一个由 142M 图像组成的小而多样化的语料库来验证他们的方法。
最后,研究者们提供了各种预训练的视觉模型,称为 DINOv2,在他们的数据上使用不同的视觉 Transformer(ViT)架构进行训练。他们发布了所有模型和代码,以在任何数据上重新训练 DINOv2。在扩展时,他们在图像和像素级别的各种计算机视觉基准测试上验证了 DINOv2 的质量,如图 2 所示。最后研究者们得出结论,单独的自监督预训练是学习可迁移冻结特征的良好候选者,可媲美最好的公开可用的弱监督模型。
数据处理
研究者通过从大量未筛选的数据中检索与多个精编数据集中的图像接近的图像来组装他们的精编 LVD-142M 数据集。他们在论文中介绍了数据管道中的主要组成部分,包括精选 / 未筛选的数据源、图像重复数据删除步骤和检索系统。整条 pipeline 不需要任何元数据或文本,直接处理图像,如图 3 所示。请读者参阅附录 A,了解有关模型方法的更多详细信息。
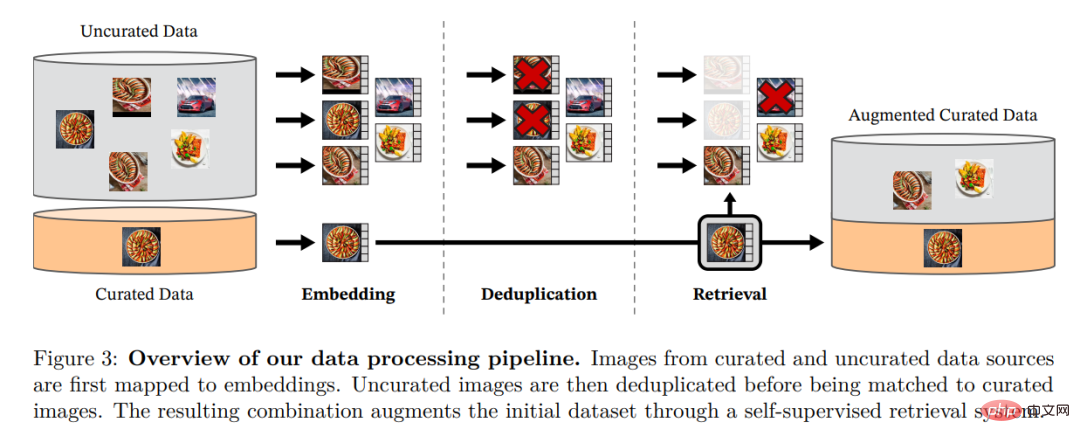
图 3:数据处理的 pipeline 概述。来自精编和非精编的数据源的图像首先被映射到嵌入。然后,非精编的图像在与标准图像匹配之前对重复数据删除。由此产生的组合通过自监督检索系统进一步丰富扩充了初始数据集。
判别性自监督预训练
研究人员通过一种判别性的自监督方法学习他们的特征,该方法可以看作是 DINO 和 iBOT 损失的结合,并以 SwAV 为中心。他们还添加了一个正则化器来传播特征和一个简短的高分辨率训练阶段。
高效实现
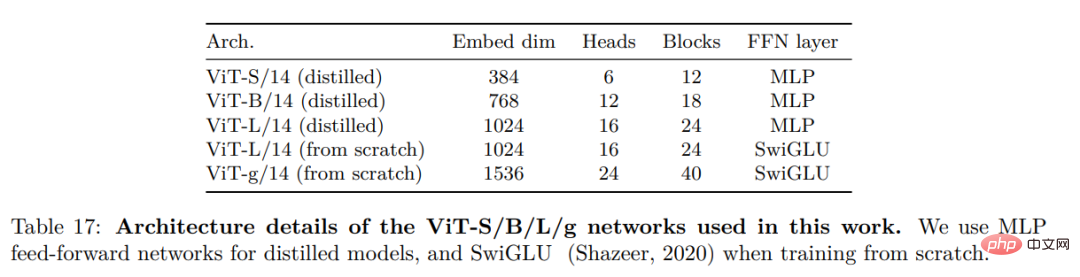
他们考虑了几项改进,以在更大范围内训练模型。使用 PyTorch 2.0 在 A100 GPU 上训练模型,该代码也可与用于特征提取的预训练模型一起使用。模型的详细信息在附录表 17 中。在相同的硬件下,与 iBOT 实现相比,DINOv2 代码仅使用 1/3 的内存,运行速度提高到了前者的 2 倍。
实验结果
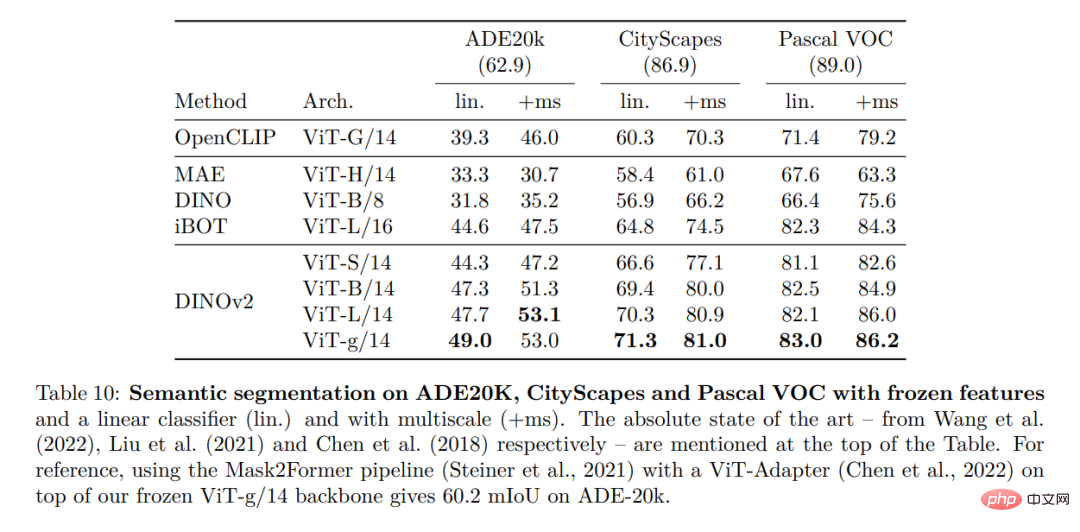
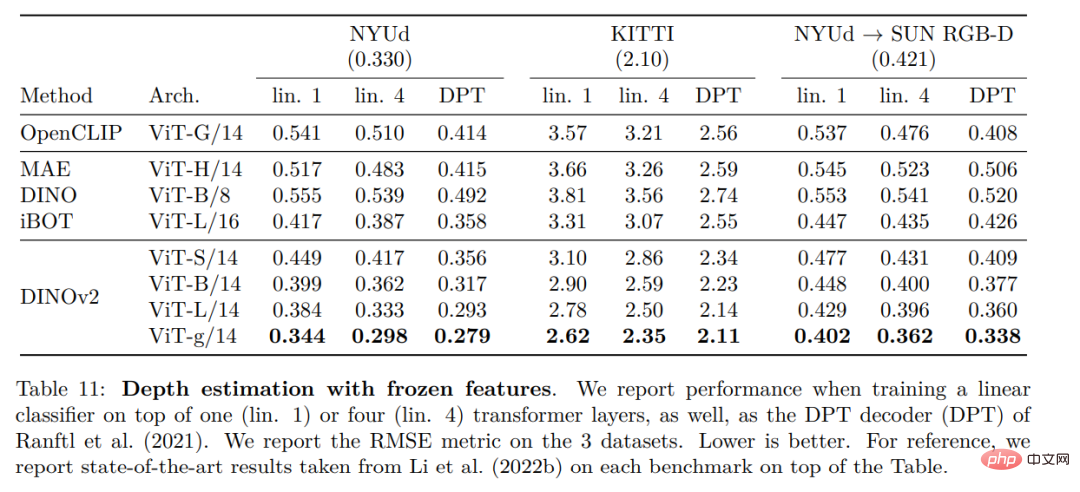
在本节中,研究者将介绍新模型在许多图像理解任务上的实证评估。他们评估了全局和局部图像表示,包括类别和实例级识别、语义分割、单目深度预测和动作识别。
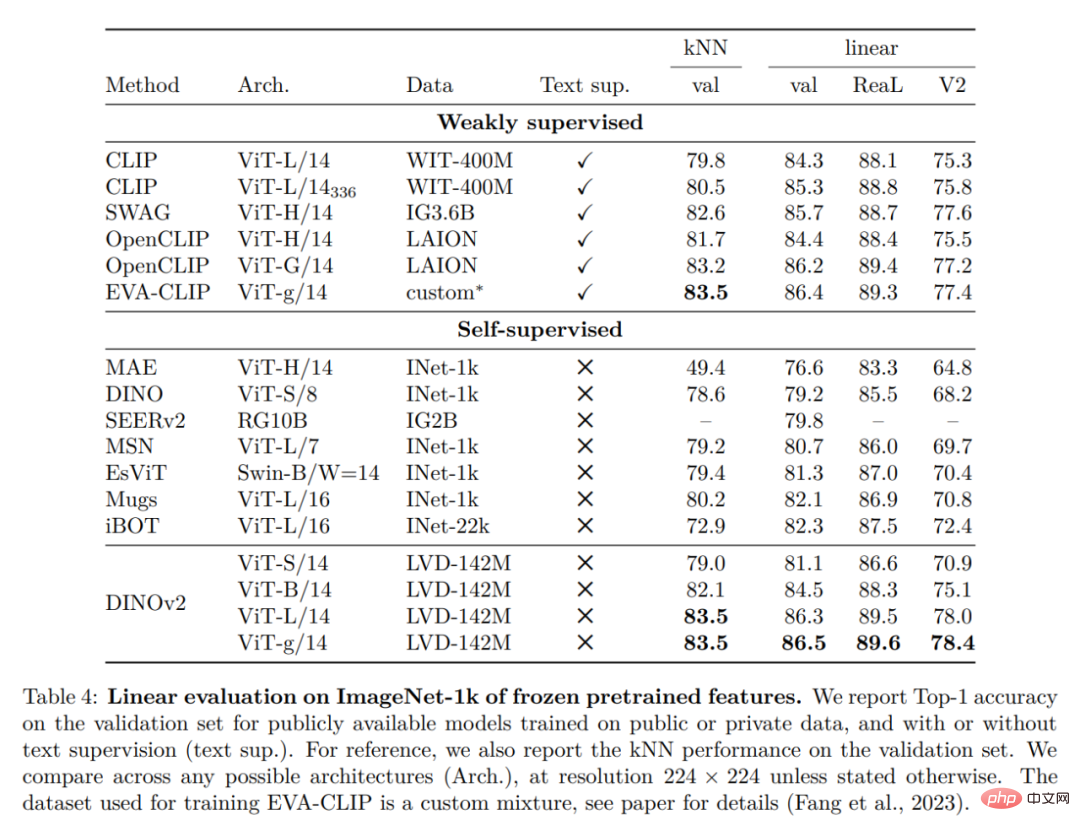
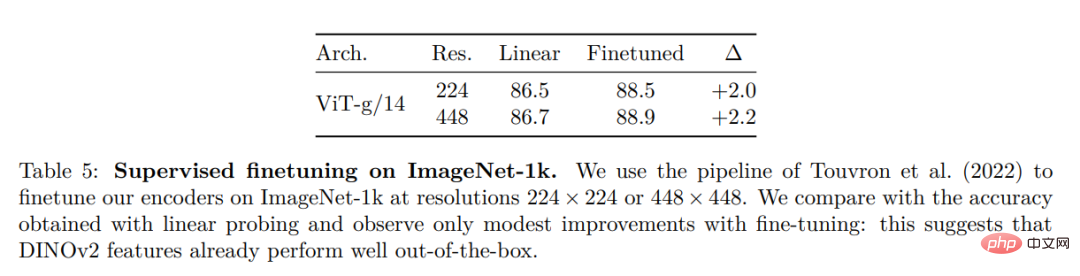
ImageNet 分类
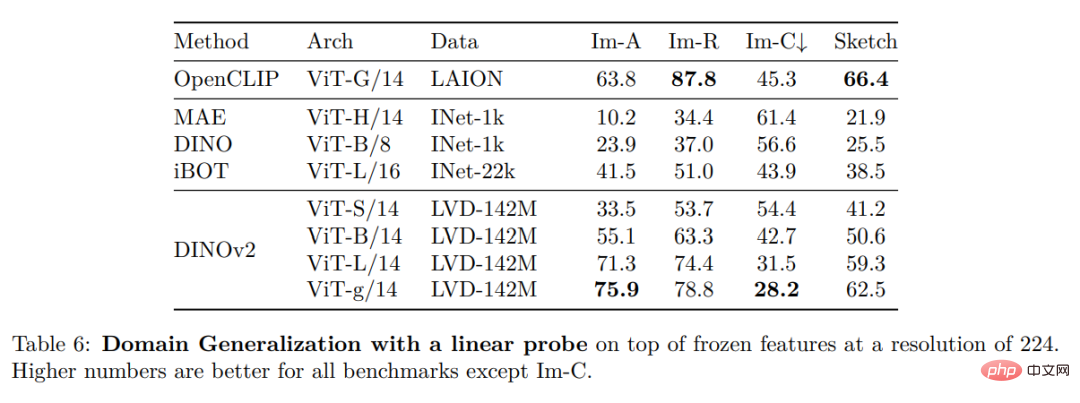
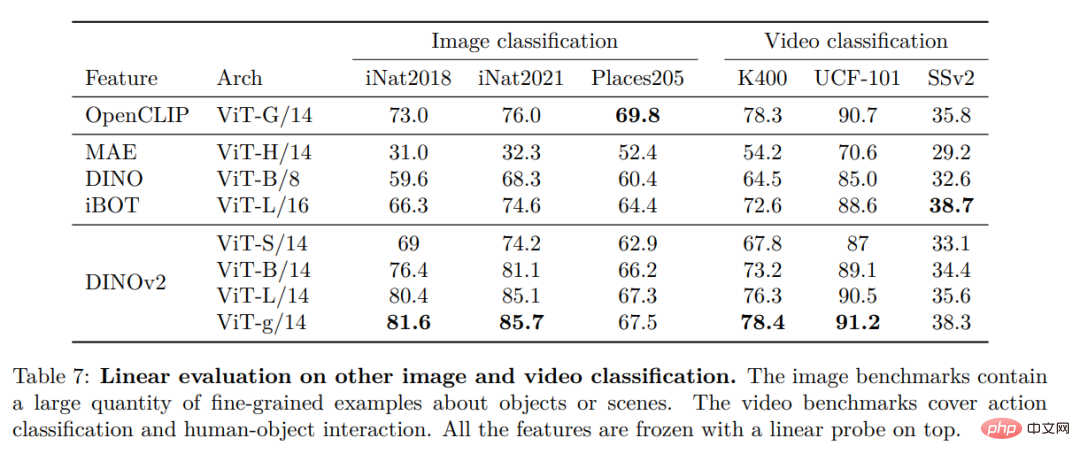
其他图像和视频分类基准
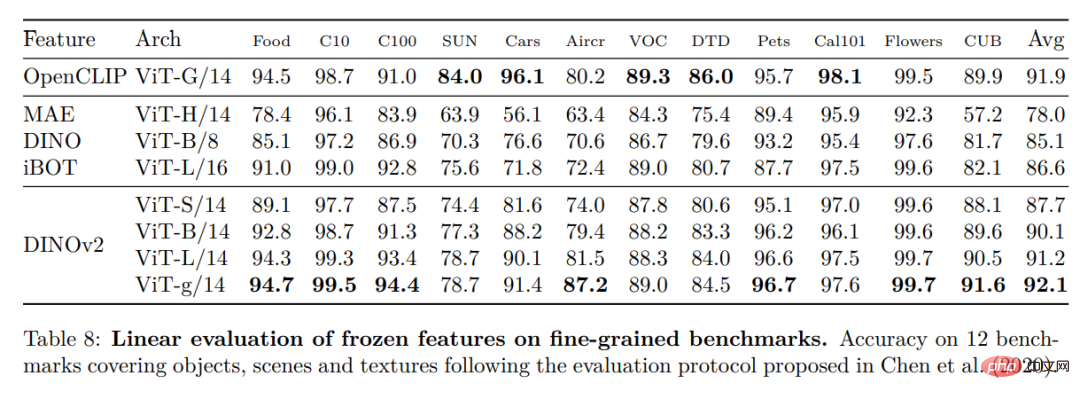
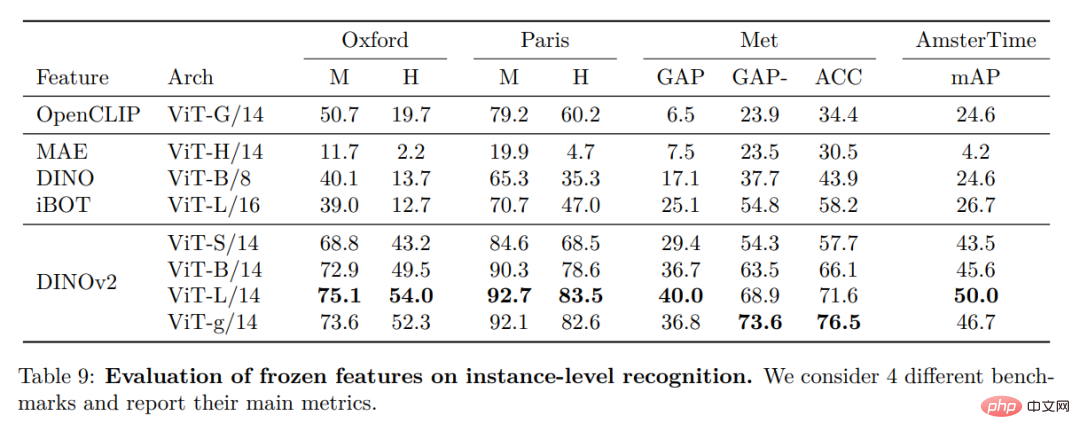
实例识别
密集识别任务
定性结果



以上是Meta发布多用途大模型开源,助力离视觉大一统更进一步的详细内容。更多信息请关注PHP中文网其他相关文章!

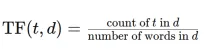 将文本文档转换为带有TFIDFECTORIZER的TF-IDF矩阵Apr 18, 2025 am 10:26 AM
将文本文档转换为带有TFIDFECTORIZER的TF-IDF矩阵Apr 18, 2025 am 10:26 AM本文解释了术语“频率分析”频率(TF-IDF)技术,这是一种自然语言处理(NLP)的关键工具(NLP),用于分析文本数据。 TF-IDF通过加权TE超过基本词袋方法的局限性
 使用Langchain建立智能AI代理:实用指南Apr 18, 2025 am 10:18 AM
使用Langchain建立智能AI代理:实用指南Apr 18, 2025 am 10:18 AM使用兰班释放AI特工的力量:初学者指南 想象一下,通过让她与Chatgpt聊天来向您的祖母展示人工智能的奇观 - 当AI毫不费力地进行对话时,她的脸上的兴奋! Th
 MISTRAL大2:足够强大,可以挑战Llama 3.1 405b?Apr 18, 2025 am 10:16 AM
MISTRAL大2:足够强大,可以挑战Llama 3.1 405b?Apr 18, 2025 am 10:16 AMMISTRAL大2:深入了解Mistral AI强大的开源LLM Meta AI最近发布的Llama 3.1模型系列很快被Mistral AI揭幕了其迄今为止最大的模型:Mistral flow 2。这个1230亿参数
 稳定扩散中的噪声时间表是什么? - 分析VidhyaApr 18, 2025 am 10:15 AM
稳定扩散中的噪声时间表是什么? - 分析VidhyaApr 18, 2025 am 10:15 AM了解扩散模型中的噪声时间表:综合指南 您是否曾经被AI产生的令人惊叹的数字艺术视觉效果所吸引,并想知道基础机制? 关键要素是“噪声时间表,&quo
 如何使用GPT-4O构建对话聊天机器人? - 分析VidhyaApr 18, 2025 am 10:06 AM
如何使用GPT-4O构建对话聊天机器人? - 分析VidhyaApr 18, 2025 am 10:06 AM使用GPT-4O构建上下文聊天机器人:综合指南 在AI和NLP迅速发展的景观中,聊天机器人已成为开发人员和组织必不可少的工具。 创建真正引人入胜且聪明的聊天的关键方面
 2025年建造AI代理的前7个框架Apr 18, 2025 am 10:00 AM
2025年建造AI代理的前7个框架Apr 18, 2025 am 10:00 AM本文探讨了建立AI代理的七个领先框架 - 自主软件实体,这些软件实体可以感知,决定和采取行动实现目标。 这些代理人超越了传统的强化学习,利用高级计划和推理
 I型和II型错误有什么区别? - 分析VidhyaApr 18, 2025 am 09:48 AM
I型和II型错误有什么区别? - 分析VidhyaApr 18, 2025 am 09:48 AM了解统计假设检验中的I型和II型错误 想象一下一项临床试验测试一种新的血压药物。 该试验的结论大大降低了血压,但实际上并非如此。这是一种类型
 使用Sumy库的自动文本摘要Apr 18, 2025 am 09:37 AM
使用Sumy库的自动文本摘要Apr 18, 2025 am 09:37 AMSumy:您的AI驱动摘要助理 厌倦了筛选无尽的文件? 强大的Python库Sumy提供了一种简化的解决方案,用于自动文本摘要。 本文探讨了Sumy的功能,指导您通过


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

SublimeText3汉化版
中文版,非常好用

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

