


移植sql server 的存储过程到mysql中,遇到了sql server中的:
IF @@ROWCOUNT
对应到mysql中可以使用 FOUND_ROWS() 函数来替换。
1. found_rows() 函数
文档地址:http://dev.mysql.com/doc/refman/5.6/en/information-functions.html#function_found-rows
1)found_rows() 的第一种使用情况(带有SQL_CALC_FOUND_ROWS,也带有 limit):
A SELECT statement may include a LIMIT clause to restrict the number of rows the server returns to the client. In some cases, it is desirable to know how many rows the statement would have returned without the LIMIT, but without running the statement again. To obtain this row count, include a SQL_CALC_FOUND_ROWS option in the SELECT statement, and then invoke FOUND_ROWS() afterward:
mysql> SELECT SQL_CALC_FOUND_ROWS * FROM tbl_name
-> WHERE id > 100 LIMIT 10;
mysql> SELECT FOUND_ROWS();
The second SELECT returns a number indicating how many rows the first SELECT would have returned had it been written without the LIMIT clause.
前面的带有limit的select语句如果加上了 SQL_CALC_FOUND_ROWS,那么接下来执行的 SELECT FOUND_ROWS(); 将返回前面语句不带limit语句返回的行数。

此种情况下,select found_rows() 和 select count(*) 有一个很小的区别:如果userId允许为null,那么select found_rows() 的结果可能要比select count(*) 要小一些。因为前者等价于:select count(userId) from Users; 而该语句不会计算userId 为null的行在内。而count(*)会计算在内。
2)found_rows() 的第二种/第三中使用情况(不带有SQL_CALC_FOUND_ROWS):
In the absence of the SQL_CALC_FOUND_ROWS option in the most recent successful SELECT statement, FOUND_ROWS() returns the number of rows in the result set returned by that statement. If the statement includes a LIMIT clause, FOUND_ROWS() returns the number of rows up to the limit. For example, FOUND_ROWS() returns 10 or 60, respectively, if the statement includes LIMIT 10 or LIMIT 50, 10.
The row count available through FOUND_ROWS() is transient and not intended to be available past the statement following the SELECT SQL_CALC_FOUND_ROWS statement. If you need to refer to the value later, save it:
mysql> SELECT SQL_CALC_FOUND_ROWS * FROM ... ;
mysql> SET @rows = FOUND_ROWS();
If you are using SELECT SQL_CALC_FOUND_ROWS, MySQL must calculate how many rows are in the full result set. However, this is faster than running the query again without LIMIT, because the result set need not be sent to the client.
1> 第二种使用情况(不带有SQL_CALC_FOUND_ROWS,也没有带 limit ):

如果前面的select语句没有带 SQL_CALC_FOUND_ROWS,也没有带 limit ,那么后面的 SELECT FOUND_ROWS(); 返回的结果就是前面的select返回的行数;
2> 第三中使用情况(不带有SQL_CALC_FOUND_ROWS,但是有带 limit ):
如果前面的select语句没有带 SQL_CALC_FOUND_ROWS,但是带有 limit,那么后面的 SELECT FOUND_ROWS(); 返回的结果就是limit语句到达的最大的行数,比如:select * from xxx limit 10; 到达的最大的行数为10,所以 found_rows() 返回10;比如 select * from xxx limit 50,10; 它要从第50行开始,再扫描10行,所以到达的最大的行数为60,所以found_rows() 返回60。

这里第一个select found_rows() 返回105,因为他是从偏移100的地方,再扫描5行,所以返回105;但是第二个扫描的结果为空,select found_rows()返回了0!而不是105,因为 where userId=999999的结果为空,所以后面的 limit 100,5根本就没有执行。所以select found_rows()返回了0。
再看一个例子,更深入的理解其中情况下的 found_rows():

上面sql中 user_Pwd=xx 的值都是一样的。可以看到这种情况下的found_rows() 是对的select语句的中间结果,再 limit 时,此时的limit的扫描到的最大的行数。和原始表中的数据的行数,是没有关系的。他是对select的中间结果的limit,然后才得到最后的结果集,再返回。
3)SQL_CALC_FOUND_ROWS and FOUND_ROWS() 适合使用的场景
SQL_CALC_FOUND_ROWS and FOUND_ROWS() can be useful in situations when you want to restrict the number of rows that a query returns, but also determine the number of rows in the full result set without running the query again. An example is a Web script that presents a paged display containing links to the pages that show other sections of a search result. Using FOUND_ROWS() enables you to determine how many other pages are needed for the rest of the result.
1> SQL_CALC_FOUND_ROW + limit + found_rows() 可以使用在分页的场合。
2> 不带SQL_CALC_FOUND_ROW 的 found_rows() 可以使用在存储过程中判断前面的select是否为空:
DELIMITER //
DROP PROCEDURE IF EXISTS loginandreg //
CREATE PROCEDURE loginandreg(
OUT userId BIGINT,
IN user_Pwd VARCHAR(32),
IN user_MobileCode VARCHAR(16),
IN user_RegIP VARCHAR(16)
)
BEGIN
IF EXISTS(SELECT * FROM Users u WHERE u.user_MobileCode=user_MobileCode) THEN
SELECT u.userId INTO userId FROM Users u WHERE u.user_MobileCode=user_MobileCode AND u.user_Pwd=user_Pwd;
IF FOUND_ROWS() < 1 THEN
SELECT -1 INTO userId;
END IF;
ELSE
INSERT INTO Users(user_Pwd,user_MobileCode,user_Visibility,user_Level,user_RegTime,user_RegIP,user_Collecter,user_Collected)
VALUES (user_Pwd,user_MobileCode,6,6,NOW(),user_RegIP,0,0);
SELECT LAST_INSERT_ID() INTO userId;
END IF;
END //
DELIMITER ;
上面存储过程中的:
SELECT u.userId INTO userId FROM Users u WHERE u.user_MobileCode=user_MobileCode AND u.user_Pwd=user_Pwd;
IF FOUND_ROWS()
SELECT -1 INTO userId;
END IF;
就是一个很好的使用的例子。
这种存储过程的场景中就可以使用 mysql 的 FOUND_ROWS() 替换 sql server 存储过程中的 IF @@ROWCOUNT
--------------------------------------------------------------------------------------------------------------------------
2. row-count() 函数
文档地址:http://dev.mysql.com/doc/refman/5.6/en/information-functions.html#function_row-count
一句话,row_count() 函数一般用于返回被 update, insert, delete 实际修改的行数。
In MySQL 5.6, ROW_COUNT() returns a value as follows:
DDL statements: 0. This applies to statements such as CREATE TABLE or DROP TABLE.
DML statements other than SELECT: The number of affected rows. This applies to statements such as UPDATE, INSERT, or DELETE (as before), but now also to statements such as ALTER TABLE and LOAD DATA INFILE.
SELECT: -1 if the statement returns a result set, or the number of rows “affected” if it does not. For example, for SELECT * FROM t1, ROW_COUNT() returns -1. For SELECT * FROM t1 INTO OUTFILE 'file_name', ROW_COUNT() returns the number of rows written to the file.
SIGNAL statements: 0.
For UPDATE statements, the affected-rows value by default is the number of rows actually changed. If you specify the CLIENT_FOUND_ROWS flag to mysql_real_connect() when connecting to mysqld, the affected-rows value is the number of rows “found”; that is, matched by the WHERE clause.
也就是说对于update语句,row_count() 默认返回的是实际被修改的行数;但是通过参数设置,也可以返回找到的行数(或者说匹配的行数,受影响的行数),这样设置就能兼容于Oracle ps/sql中 sql%rowcount 和 sql server 中的 @@RowCount。
但是 row_count() 的结果和 mysql 的JDBC driver的默认行为却是不一致的,mysql jdbc中的 Connection.getUpdateCount() 函数返回的是被找到的行数,而不是实际被修改的行数,如果要返回被实际修改的行,要使用存储过程,相关链接说明:
http://stackoverflow.com/questions/17544782/how-to-tell-number-of-rows-changed-from-jdbc-execution
http://mybatis-user.963551.n3.nabble.com/Return-number-of-changed-rows-td3888464.html#a3903155
http://dev.mysql.com/doc/connector-j/en/connector-j-reference-configuration-properties.html (这里包含了所有mysql jdbc 链接可设置的参数)
useAffectedRows
Don't set the CLIENT_FOUND_ROWS flag when connecting to the server (not JDBC-compliant, will break most applications that rely on "found" rows vs. "affected rows" for DML statements), but does cause "correct" update counts from "INSERT ... ON DUPLICATE KEY UPDATE" statements to be returned by the server.
Default: false
Since version: 5.1.7
关于对mysql复制的影响:
Important
FOUND_ROWS() is not replicated reliably using statement-based replication. This function is automatically replicated using row-based replication.
Important
ROW_COUNT() is not replicated reliably using statement-based replication. This function is automatically replicated using row-based replication.
注意:found_rows() 和 row_count() 在基于 语句的复制 环境中是不可靠的,它们自动使用 基于行的复制行为。

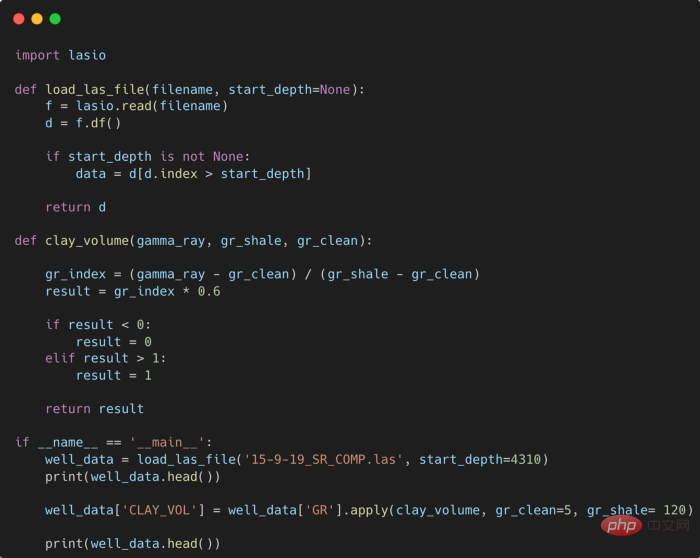 提高 Python 代码可读性的五个基本技巧Apr 12, 2023 pm 08:58 PM
提高 Python 代码可读性的五个基本技巧Apr 12, 2023 pm 08:58 PMPython 中有许多方法可以帮助我们理解代码的内部工作原理,良好的编程习惯,可以使我们的工作事半功倍!例如,我们最终可能会得到看起来很像下图中的代码。虽然不是最糟糕的,但是,我们需要扩展一些事情,例如:load_las_file 函数中的 f 和 d 代表什么?为什么我们要在 clay 函数中检查结果?这些函数需要什么类型?Floats? DataFrames?在本文中,我们将着重讨论如何通过文档、提示输入和正确的变量名称来提高应用程序/脚本的可读性的五个基本技巧。1. Comments我们可
 CRPS:贝叶斯机器学习模型的评分函数Apr 12, 2023 am 11:07 AM
CRPS:贝叶斯机器学习模型的评分函数Apr 12, 2023 am 11:07 AM连续分级概率评分(Continuous Ranked Probability Score, CRPS)或“连续概率排位分数”是一个函数或统计量,可以将分布预测与真实值进行比较。机器学习工作流程的一个重要部分是模型评估。这个过程本身可以被认为是常识:将数据分成训练集和测试集,在训练集上训练模型,并使用评分函数评估其在测试集上的性能。评分函数(或度量)是将真实值及其预测映射到一个单一且可比较的值 [1]。例如,对于连续预测可以使用 RMSE、MAE、MAPE 或 R 平方等评分函数。如果预测不是逐点
 详解JavaScript函数如何实现可变参数?(总结分享)Aug 04, 2022 pm 02:35 PM
详解JavaScript函数如何实现可变参数?(总结分享)Aug 04, 2022 pm 02:35 PMjs是弱类型语言,不能像C#那样使用param关键字来声明形参是一个可变参数。那么js中,如何实现这种可变参数呢?下面本篇文章就来聊聊JavaScript函数可变参数的实现方法,希望对大家有所帮助!
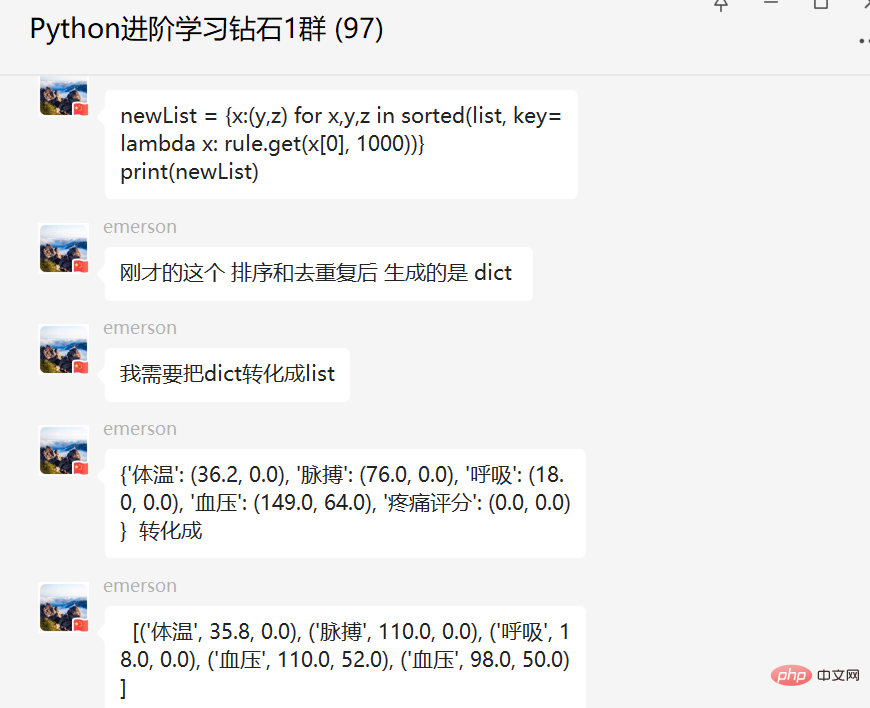 盘点Python内置函数sorted()高级用法实战May 13, 2023 am 10:34 AM
盘点Python内置函数sorted()高级用法实战May 13, 2023 am 10:34 AM一、前言前几天在Python钻石交流群有个叫【emerson】的粉丝问了一个Python排序的问题,这里拿出来给大家分享下,一起学习下。其实这里【瑜亮老师】、【布达佩斯的永恒】等人讲了很多,只不过对于基础不太好的小伙伴们来说,还是有点难的。不过在实际应用中内置函数sorted()用的还是蛮多的,这里也单独拿出来讲一下,希望下次再有小伙伴遇到的时候,可以不慌。二、基础用法内置函数sorted()可以用来做排序,基础的用法很简单,看个例子,如下所示。lst=[3,28,18,29,2,5,88
 学Python,还不知道main函数吗Apr 12, 2023 pm 02:58 PM
学Python,还不知道main函数吗Apr 12, 2023 pm 02:58 PMPython 中的 main 函数充当程序的执行点,在 Python 编程中定义 main 函数是启动程序执行的必要条件,不过它仅在程序直接运行时才执行,而在作为模块导入时不会执行。要了解有关 Python main 函数的更多信息,我们将从如下几点逐步学习:什么是 Python 函数Python 中 main 函数的功能是什么一个基本的 Python main() 是怎样的Python 执行模式Let’s get started什么是 Python 函数相信很多小伙伴对函数都不陌生了,函数是可
 Python面向对象里常见的内置成员介绍Apr 12, 2023 am 09:10 AM
Python面向对象里常见的内置成员介绍Apr 12, 2023 am 09:10 AM好嘞,今天我们继续剖析下Python里的类。[[441842]]先前我们定义类的时候,使用到了构造函数,在Python里的构造函数书写比较特殊,他是一个特殊的函数__init__,其实在类里,除了构造函数还有很多其他格式为__XXX__的函数,另外也有一些__xx__的属性。下面我们一一说下:构造函数Python里所有类的构造函数都是__init__,其中根据我们的需求,构造函数又分为有参构造函数和无惨构造函数。如果当前没有定义构造函数,那么系统会自动生成一个无参空的构造函数。例如:在有继承关系
 go语言的形参占用内存吗Dec 28, 2022 pm 05:19 PM
go语言的形参占用内存吗Dec 28, 2022 pm 05:19 PM形参变量在未出现函数调用时并不占用内存,只在调用时才占用,调用结束后将释放内存。形参全称“形式参数”,是函数定义时使用的参数;但函数定义时参数是没有任实际何数据的,因而在函数被调用前没有为形参分配内存,其作用是说明自变量的类型和形态以及在过程中的作用。
 Golang函数的类型断言用法介绍May 16, 2023 am 08:02 AM
Golang函数的类型断言用法介绍May 16, 2023 am 08:02 AMGolang的函数类型断言是一个非常重要的特性,它可以让我们在函数中精细地控制变量的类型,从而更加方便地进行数据处理和转换。本文将介绍Golang函数的类型断言用法,希望能够对大家的学习有所帮助。一、什么是Golang函数的类型断言?Golang函数的类型断言可以理解为函数参数中所声明变量的类型具有多态性,这使得一个函数在不同的参数传递下可以灵活


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

SublimeText3汉化版
中文版,非常好用

记事本++7.3.1
好用且免费的代码编辑器

Dreamweaver Mac版
视觉化网页开发工具

