
DeepMind为何缺席GPT盛宴?原来在教小机器人踢足球

- 王林转载
- 2023-05-04 22:31:051289浏览
在很多学者看来,具身智能是通往 AGI 的一个非常有前途的方向,而 ChatGPT 的成功也离不开以强化学习为基础的 RLHF 技术。DeepMind vs. OpenAI,究竟谁能率先实现 AGI,答案似乎还未揭晓。
我们知道,创建通用的具身智能(即以敏捷、灵巧的方式在物理世界采取行动并像动物或人类一样进行理解的智能体)是 AI 研究者和机器人专家的长期目标之一。从时间上来看,创建具有复杂运动能力的智能具身智能体可以追溯到很多年前,无论是在模拟还是真实世界中。
近年来进展速度大大加快,其中基于学习的方法发挥了重大作用。例如深度强化学习已被证明能够解决模拟角色的复杂运动控制问题,包括复杂、感知驱动的全身控制或多智能体行为。同时,深度强化学习越来越多地应用于物理机器人。尤其是广泛使用的高质量四足机器人,它们已经成为了通过学习生成一系列稳健运动行为的演示目标。
不过,静态环境中的运动只是动物与人类部署其身体与世界交互的众多方式的一部分,这种运动形态已在很多研究全身控制和运动操纵的工作中得到验证,尤其是四足机器人。相关运动示例包括攀爬、运球或接球等足球技巧,以及使用腿进行简单操作。
其中对于足球运动来说,它展示了人类感觉运动智能的很多特征。足球的复杂性要求各种高敏捷和动态动作,包括跑动、转身、回避、踢球、传球、跌倒爬起等。这些动作需要以多种方式进行组合。球员则需要对球、队友和对方球员做出预测,并根据比赛环境调整动作。这种挑战的多样性已在机器人和 AI 社区中得到认可,并诞生了机器人世界杯 RoboCup。
不过应看到,踢好足球所需要的敏捷、灵活和迅速反应以及这些要素之间的平滑过渡对于手动设计机器人来说挑战很大且耗费时间。近日,DeepMind(现已与谷歌大脑团队合并为 Google DeepMind)的新论文探讨了利用深度强化学习为双足机器人学习敏捷的足球技巧。

论文地址:https://arxiv.org/pdf/2304.13653.pdf
项目主页:https://sites.google.com/view/op3-soccer
在这篇论文中,研究者研究了动态多智能体环境中小型类人机器人的全身控制和对象交互。他们考虑了整个足球问题的一个子集,训练了一个具有 20 个可控关节的低成本微型类人机器人来玩 1 v1 足球比赛,并观察本体感觉和比赛状态特征。通过内置的控制器,机器人缓慢笨拙地移动。不过,研究者使用深度强化学习将智能体以自然流畅方式组合起来的动态敏捷的上下文自适应运动技巧(如走、跑、转身以及踢球和跌倒爬起)合成为了复杂的长期行为。
在实验中,智能体学会了预测球的运动、定位、阻攻以及利用反弹球等。智能体在多智能体环境中出现这些行为得益于技能复用、端到端训练和简单奖励的组合。研究者在模拟中训练智能体并将它们迁移到物理机器人中,证明了即使对于低成本机器人而言,模拟到真实的迁移也是可能的。
用数据说话,机器人的行走速度提升了 156%,起身的时间减少了 63%,踢球的速度也比基线提升了 24%。
在进入技术解读之前,我们先看一些机器人在 1v1 足球比赛中的精彩瞬间。比如射门:


罚点球:

转向、盘带和踢球,一气呵成

阻攻:

实验设置
想要让机器人学会踢足球,首先需要一些基本设置。
环境方面,DeepMind 首先在自定义的足球环境中模拟训练智能体,然后将策略迁移到相应的真实环境中,如图 1 所示。环境包括一个长 5 米、宽 4 米的足球场,以及两个球门,每个球门的开口宽度均为 0.8 米。在模拟和真实环境中,球场都以坡道为界,从而确保球在界内。真正的球场上铺有橡胶地砖,以减少摔倒损坏机器人的风险并增加地面摩擦力。
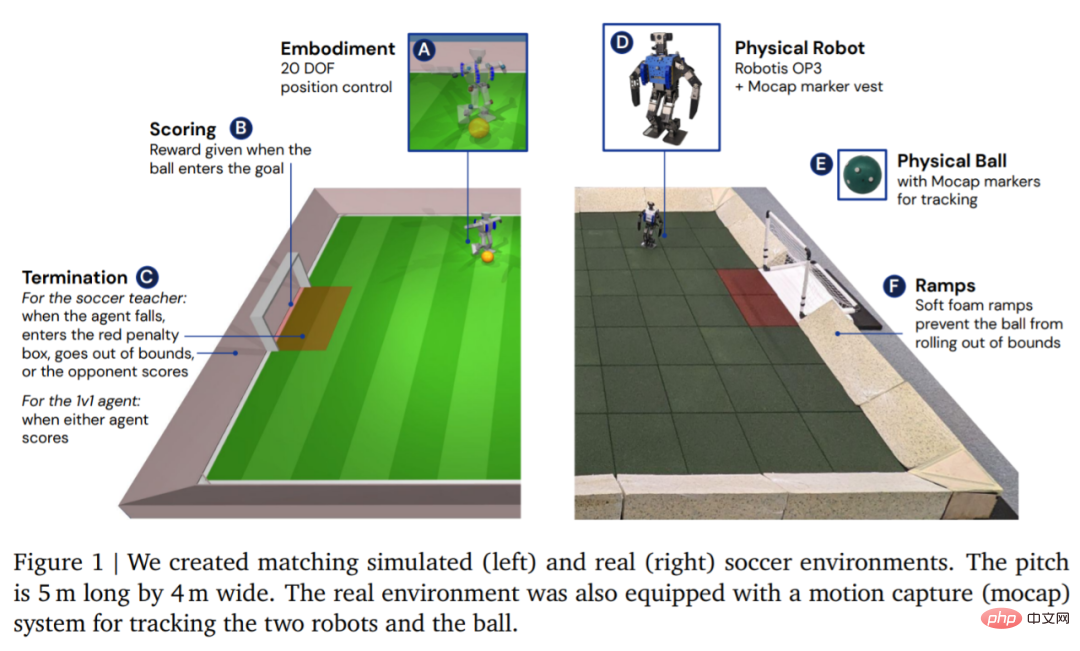
环境设置好后,接着就是硬件和动作捕捉的设置。DeepMind 采用 Robotis OP3 机器人,它身高 51 厘米,重 3.5 kg,由 20 个伺服电机驱动。该机器人没有 GPU 或其他专用加速器,因此所有神经网络计算都在 CPU 上运行。机器人的头部是罗技 C920 网络摄像头,它可以选择以每秒 30 帧的速度提供 RGB 视频流。

方法
DeepMind 的目标是训练可以行走、踢球、起身、防守、懂得如何得分的智能体,然后再将这些功能迁移到真正的机器人身上。DeepMind 将训练分成两个阶段来进行,如图 3 所示。
- 在第一阶段,DeepMind 针对两种特定技能训练教师策略,这两种技能包括智能体从地面上站起来和进球得分。
- 在第二阶段,第一阶段的教师策略被用来规范智能体,同时智能体学会有效地对抗越来越强大的对手。
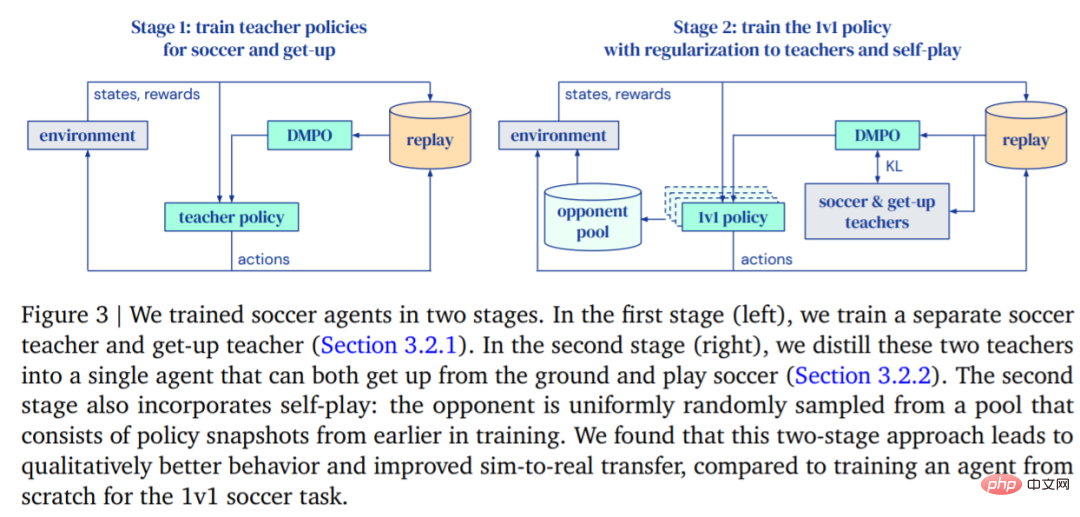
训练
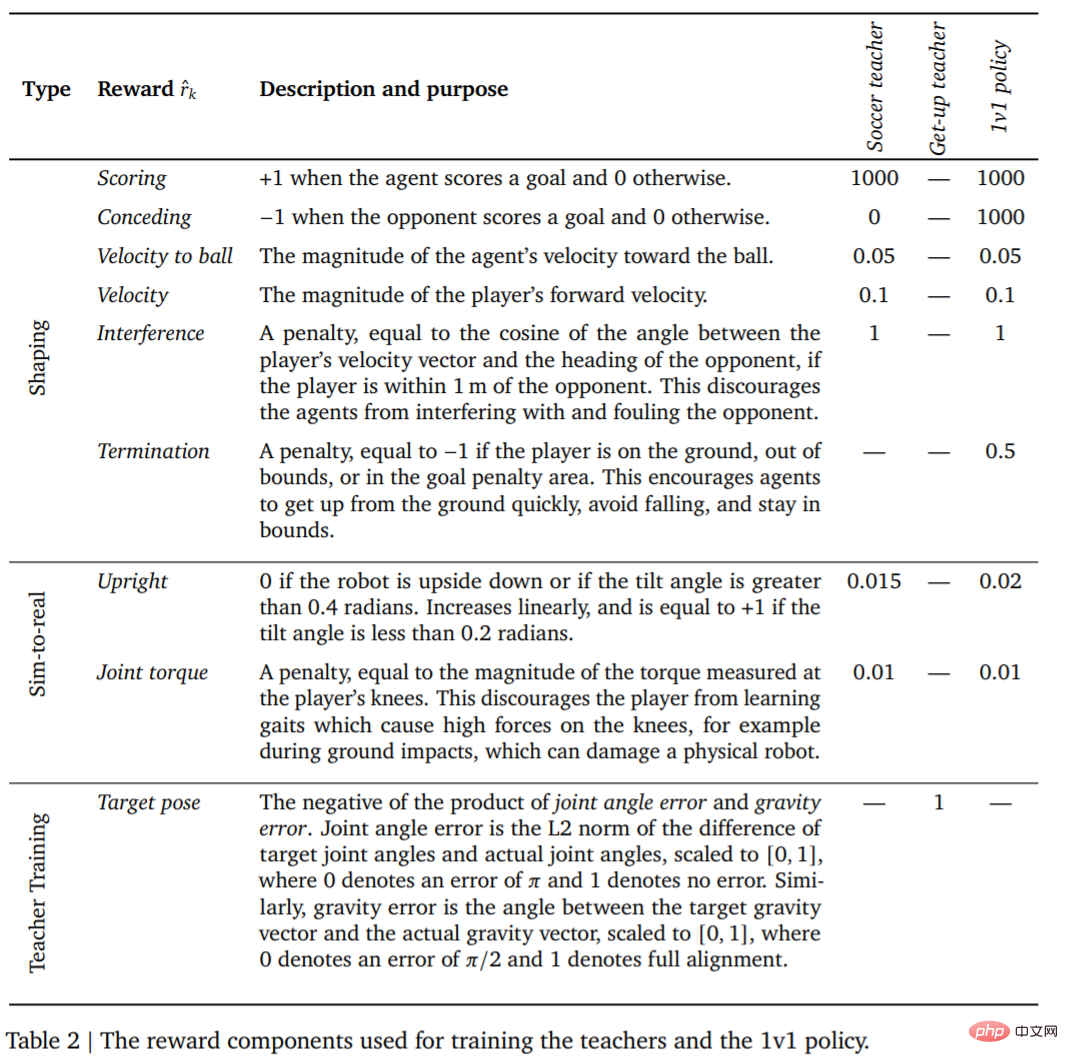
首先是教师训练。教师需要接受尽可能多的进球训练。当智能体摔倒、出界、进入禁区 (图 1 中用红色标记) 或对手得分时,这一回合(Episodes)终止。在每一回合的开始,对智能体、另一方和球在球场上的随机位置和方向进行初始化。双方都初始化为默认站姿。对手使用未经训练的策略进行初始化,因此,智能体在这个阶段学会避开对手,但不会发生进一步复杂的互动。此外,每个训练阶段的奖励及其权重如表 2 所示。
接着智能体与越来越强大的对手竞争,同时将其行为规范到教师策略。这样一来智能体能够掌握一系列足球技能:行走、踢球、起身、得分和防守。当智能体出界或在球门禁区内时,它会在每个时间步受到固定的惩罚。
智能体训练好后,接下来就是将训练好的踢球策略零样本迁移到真实机器人。为了提高零样本迁移成功率,DeepMind 通过简单的系统识别减少了模拟智能体与真实机器人的差距,通过训练期间的领域随机化和扰动提高了策略的鲁棒性,以及包括塑造奖励策略以获得不太可能损害机器人的行为。
实验
1v1 比赛:足球智能体可以处理多种紧急行为,包括灵活的运动技能,例如从地面起身、快速从跌倒中恢复、奔跑和转身。游戏过程中,智能体以流畅的方式在所有这些技能之间转换。

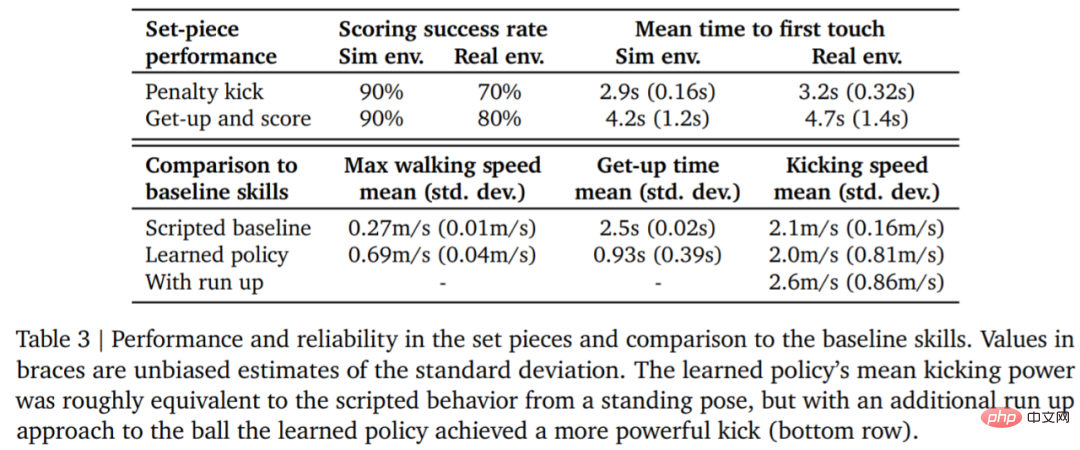
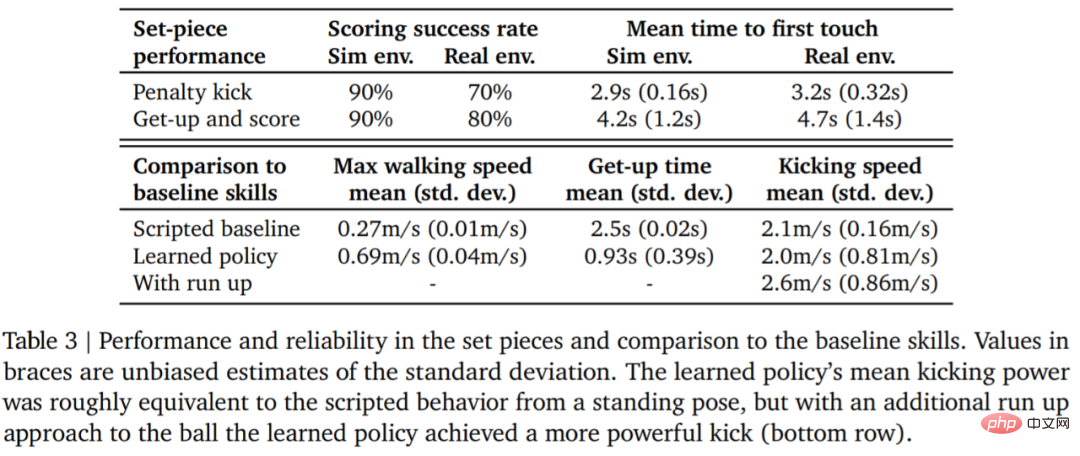
下表 3 为定量分析结果。从结果可以看出强化学习策略比专门的人工设计的技能表现更好,智能体的行走速度快了 156%,起身时间少了 63%。
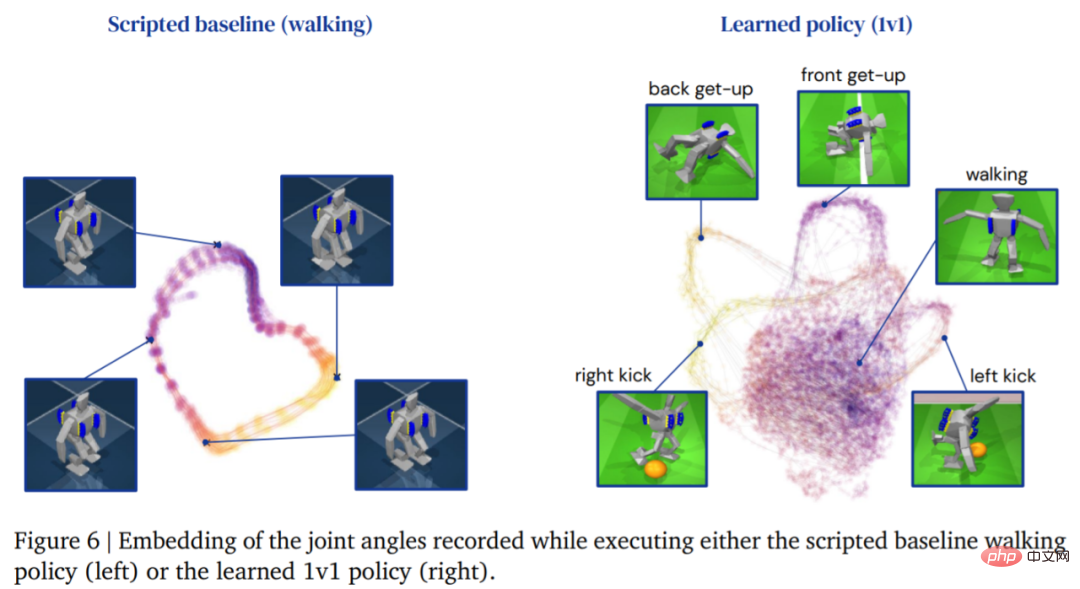
下图为智能体的行走轨迹,相比之下,由学习策略产生的智能体轨迹结构更加丰富:
为了评估学习策略的可靠性,DeepMind 设计了点球和起跳射门定位球,并在模拟环境和真实环境中实现。初始配置如图 7 所示。
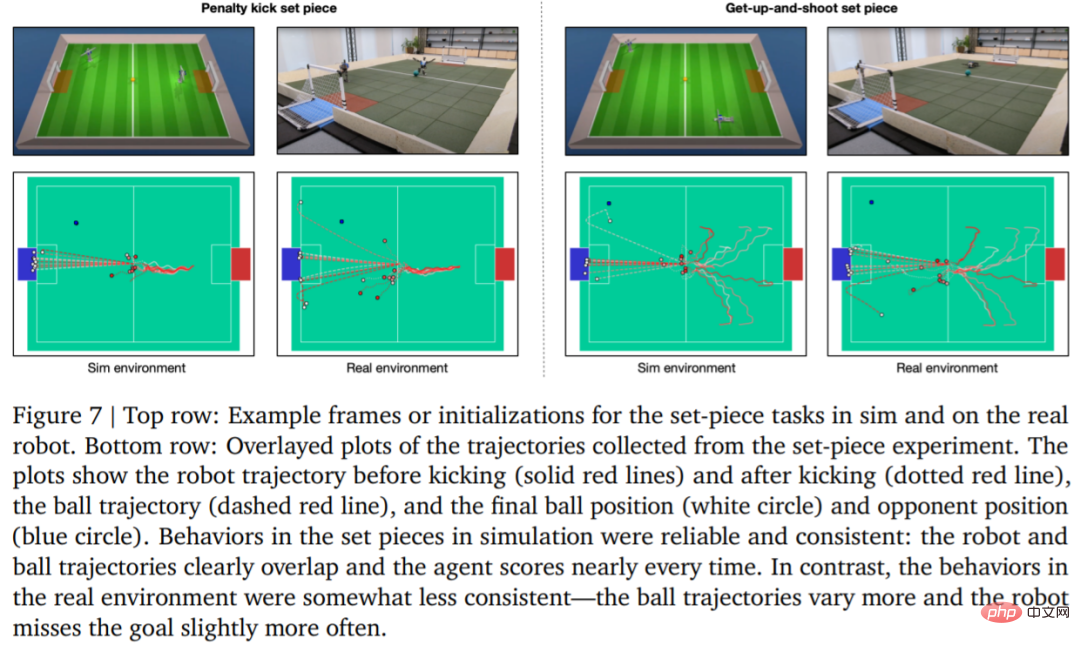
在真实环境中,机器人在罚点球任务中 10 次中了 7 次 (70%),在起射任务中 10 次中了 8 次 (80%)。而在模拟实验中,智能体在这两项任务中的得分更加一致,这表明智能体的训练策略迁移到真实环境(包括真实机器人、球、地板表面等),性能略有下降,行为差异有所增加,但机器人仍然能够可靠地起身、踢球和得分。结果如图 7 和表 3 所示。
以上是DeepMind为何缺席GPT盛宴?原来在教小机器人踢足球的详细内容。更多信息请关注PHP中文网其他相关文章!