



这篇文章初版2018年5月就写好了,最近2022年12月才中。四年中得到了老板们的很多支持和理解。
(这段经历也希望给在投稿的同学们一点鼓舞,paper写好肯定能中的,不要轻易放弃!)
arXiv早期版本为:Query Attack via Opposite-Direction Feature:Towards Robust Image Retrieval

论文链接:https://link.springer.com/article/10.1007/s11263-022-01737-y
论文备份链接:https://zdzheng.xyz/files/IJCV_Retrieval_Robustness_CameraReady.pdf
代码:https://github.com/layumi/U_turn
作者:Zhedong Zheng, Liang Zheng, Yi Yang and Fei Wu
与早期版本相比,
- 我们在公式上做了一些调整;
- 加入了很多新的related works讨论;
- 加入了多尺度Query攻击 / 黑盒攻击 / 防御三个不同角度的实验;
- 加入Food256,Market-1501,CUB,Oxford,Paris等数据集上的新方法和 较新的可视化方式。
- 攻击了reid中的PCB结构,攻击了Cifar10中的WiderResNet。
实际案例
实际使用的话。举个例子,比如我们要攻击google或者百度的图像检索系统,搞大新闻(大雾)。我们可以下载一张狗的图像,通过imagenet模型(也可以是其他模型,最好是接近检索系统的模型)计算特征,通过把特征调头(本文的方法),来计算对抗噪声(adversarial noise)加回到狗上。再把攻击过后的狗使用以图搜图,可以看到百度谷歌的系统就不能返回狗相关的内容了。虽然我们人还能识别出这是狗的图像。
P.S. 我当时也试过攻击谷歌以图搜图,人还能识别出这是狗的图像,但谷歌往往会返回「马赛克」相关图像。我估计谷歌也不全是用深度特征,或者和imagenet模型有较大差异,导致攻击后,往往趋向于「马赛克」,而不是其他实体类别(飞机啊之类的)。当然马赛克也算某种程度的成功!
What
1.本文的初衷其实特别简单,现有reid模型,或者风景检索模型已经达到了95%以上的Recall-1召回率,那么我们是不是可以设计一种方式来攻击检索模型?一方面探探reid模型的老底,一方面攻击是为了更好的防御,研究一下防御异常case。
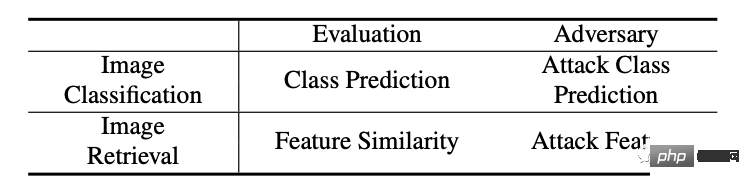
2.检索模型与传统的分类模型的差异在于检索模型是用提取出来的特征来比较结果(排序),这与传统的分类模型有较大的差异,如下表。
3. 检索问题还有一个特点就是open set也就是说测试的时候类别往往是训练时没见过的。如果大家熟悉cub数据集,在检索设置下,训练的时候训练集合100多种鸟,和测试时测试100多种鸟,这两个100种是没有overlapp种类的。纯靠提取的视觉特征来匹配和排序。所以一些分类攻击方法不适合攻击检索模型,因为攻击时基于类别预测的graident往往是不准的。
4. 检索模型在测试时,有两部分数据一部分是查询图像query,一部分是图像库 gallery(数据量较大,而且一般不能access)。考虑到实际可行性,我们方法将主要瞄准攻击query的图像来导致错误的检索结果。
How
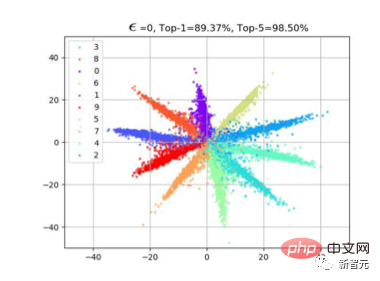
1. 很自然的一个想法就是攻击特征。那么怎么攻击特征?基于我们之前对于cross entropy loss的观察,(可以参考large-margin softmax loss这篇文章)。往往我们使用分类loss的时候,特征f会存在一个放射形的分布。这是由于特征在学习的时候与最后一层分类层权重W计算的是cos similarity。如下图,导致我们学完模型,同一类的样本会分布在该类W附近,这样f*W才能到达最大值。
2. 所以我们提出了一个特别简单的方法,就是让特征调头。如下图,其实有两种常见的分类攻击方法也可以一起可视化出来。如(a)这种就是把分类概率最大的类别给压下去(如Fast Gradient),通过给-Wmax,所以有红色的梯度传播方向沿着反Wmax;如(b)还有一种就是把最不可能的类别的特征给拉上来(如Least-likely),所以红色的梯度沿着Wmin。
3. 这两种分类攻击方法在传统分类问题上当然是很直接有效的。但由于检索问题中测试集都是没见过的类别(没见过的鸟种),所以自然f的分布没有那么紧密贴合Wmax或者Wmin,因此我们的策略很简单,既然有了f,那我们直接把f往-f去移动就好了,如图(c)。
这样在特征匹配阶段,原来排名高的结果,理想情况下,与-f算cos similarity,从接近1变到接近-1,反而会排到最低。
达成了我们攻击检索排序的效果。
4. 一个小extension。在检索问题中,我们还常用multi-scale来做query augmentation,所以我们也研究了一下怎么在这种情况下维持攻击效果。(主要难点在于resize操作可能把一些小却关键的抖动给smooth了。)
其实我们应对的方法也很简单,就如model ensemble一样,我们把多个尺度的adversarial gradient做个ensemble平均就好。
实验
1. 在三个数据集三个指标下,我们固定了抖动幅度也就是横坐标的epsilon,比较在同样抖动幅度下哪一种方法能使检索模型犯更多错。我们的方法是黄色线 都处在最下面,也就是攻击效果更好。
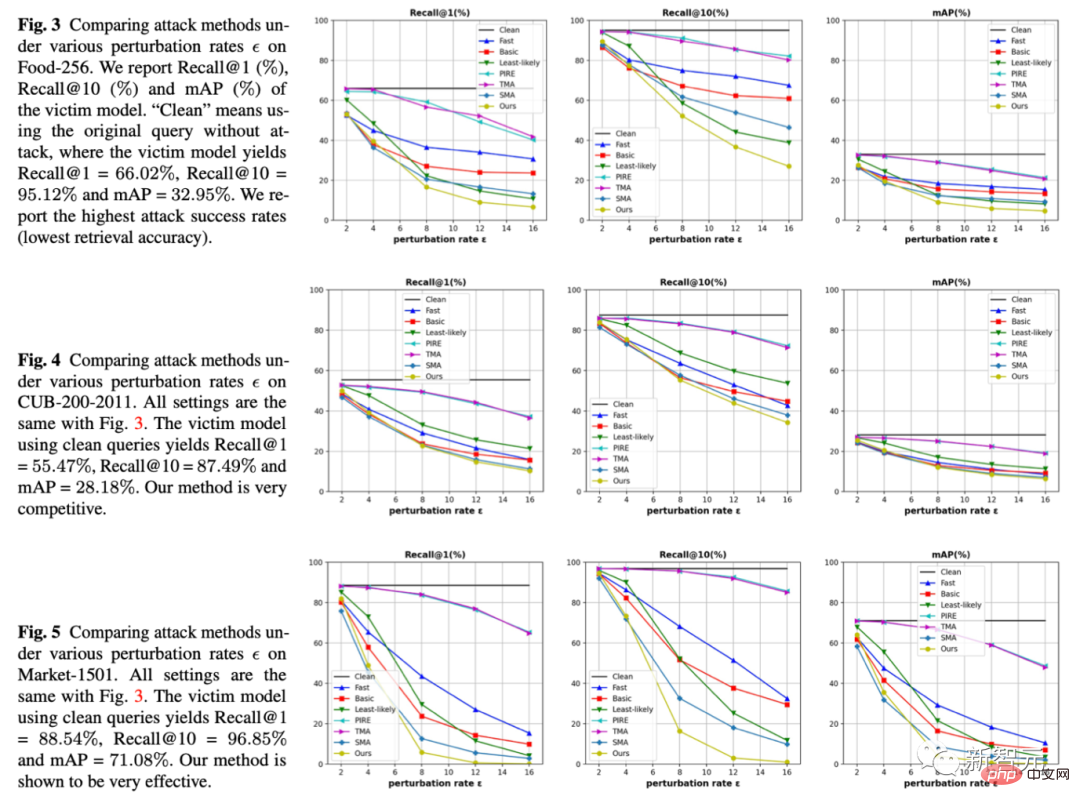
2. 同时我们也提供了在5个数据集上(Food,CUB,Market,Oxford,Paris)的定量实验结果
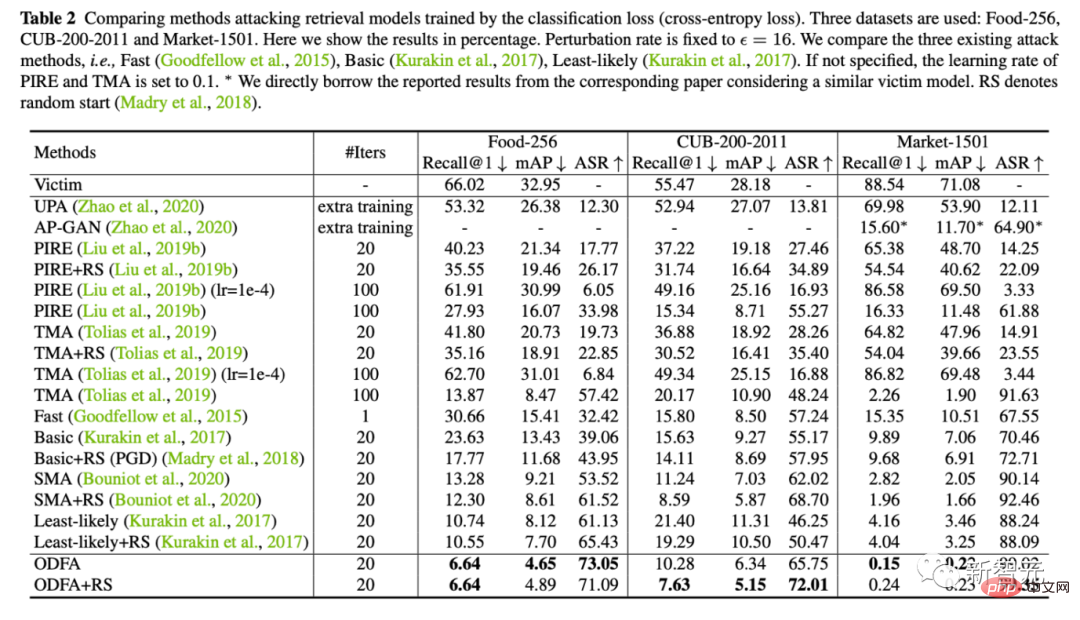
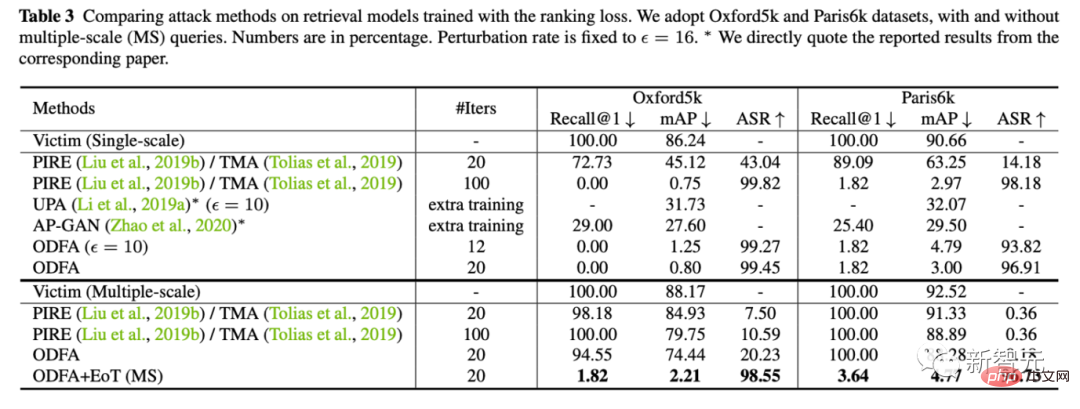
3. 为了展示模型的机制,我们也尝试攻击了Cifar10上的分类模型。
可以看到我们改变最后一层特征的策略,对于top-5也有很强的压制力。对于top-1,由于没有拉一个候选类别上来,所以会比least-likely略低一些,但也差不多。
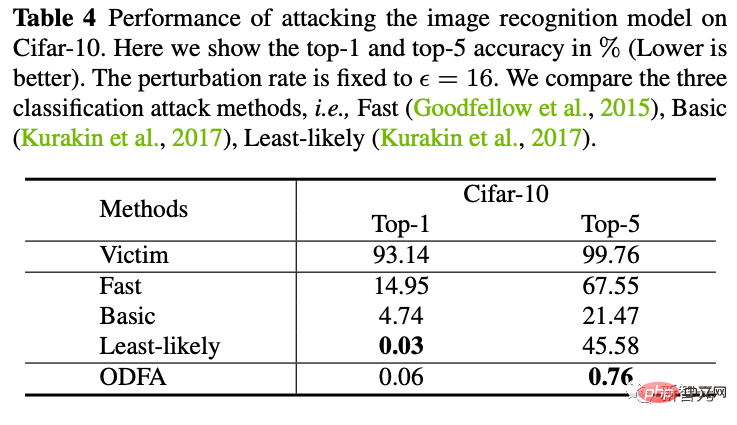
4. 黑盒攻击
我们也尝试了使用ResNet50生成的攻击样本去攻击一个黑盒的DenseNet模型(这个模型的参数我们是不可获取的)。发现也能取得比较好的迁移攻击能力。
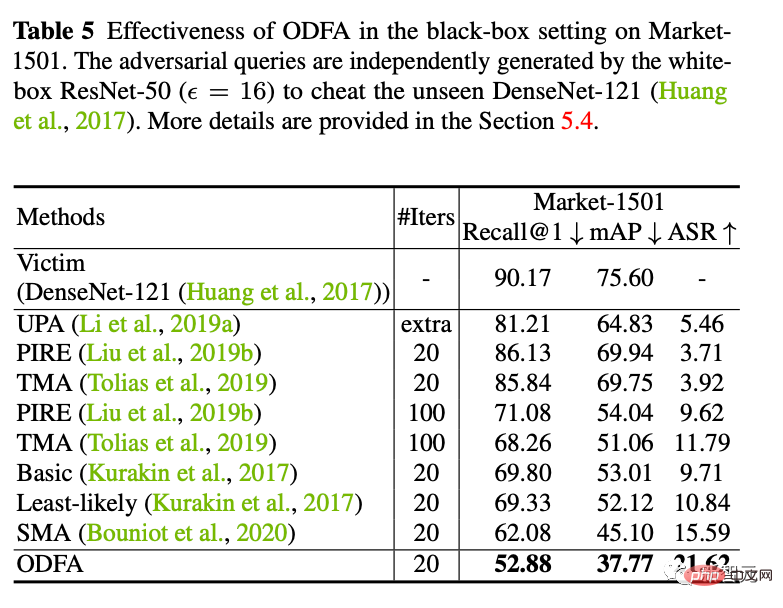
5. 对抗防御
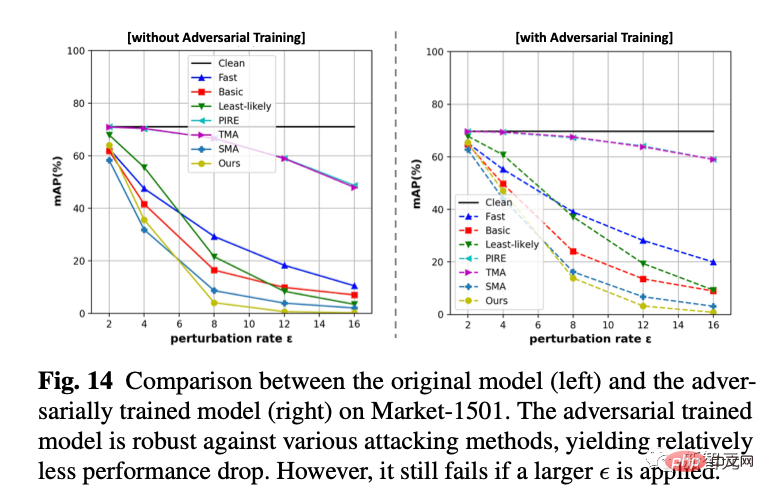
我们采用online adversarial training的方式来训练一个防御模型。我们发现他在接受新的白盒攻击的时候依然是不行的,但是比完全没有防御的模型在小抖动上会更稳定一些(掉点少一些)。
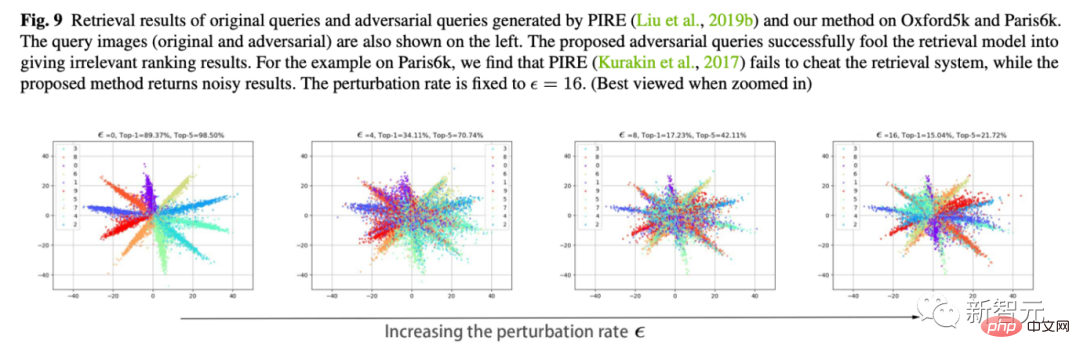
6. 特征移动的可视化
这也是我觉得最喜欢的一个实验。我们利用Cifar10,把最后分类层的维度改为2,来plot分类层的feature的变化。
如下图,随着抖动幅度epsilon的变大,我们可以看到样本的特征慢慢「调头」了。比如大部分橙色的特征就移动到对面去了。
以上是逆转特征让re-id模型从88.54%到0.15%的详细内容。更多信息请关注PHP中文网其他相关文章!

 一个提示可以绕过每个主要LLM的保障措施Apr 25, 2025 am 11:16 AM
一个提示可以绕过每个主要LLM的保障措施Apr 25, 2025 am 11:16 AM隐藏者的开创性研究暴露了领先的大语言模型(LLM)的关键脆弱性。 他们的发现揭示了一种普遍的旁路技术,称为“政策木偶”,能够规避几乎所有主要LLMS
 5个错误,大多数企业今年将犯有可持续性Apr 25, 2025 am 11:15 AM
5个错误,大多数企业今年将犯有可持续性Apr 25, 2025 am 11:15 AM对环境责任和减少废物的推动正在从根本上改变企业的运作方式。 这种转变会影响产品开发,制造过程,客户关系,合作伙伴选择以及采用新的
 H20芯片禁令震撼中国人工智能公司,但长期以来一直在为影响Apr 25, 2025 am 11:12 AM
H20芯片禁令震撼中国人工智能公司,但长期以来一直在为影响Apr 25, 2025 am 11:12 AM最近对先进AI硬件的限制突出了AI优势的地缘政治竞争不断升级,从而揭示了中国对外国半导体技术的依赖。 2024年,中国进口了价值3850亿美元的半导体
 如果Openai购买Chrome,AI可能会统治浏览器战争Apr 25, 2025 am 11:11 AM
如果Openai购买Chrome,AI可能会统治浏览器战争Apr 25, 2025 am 11:11 AM从Google的Chrome剥夺了潜在的剥离,引发了科技行业中的激烈辩论。 OpenAI收购领先的浏览器,拥有65%的全球市场份额的前景提出了有关TH的未来的重大疑问
 AI如何解决零售媒体的痛苦Apr 25, 2025 am 11:10 AM
AI如何解决零售媒体的痛苦Apr 25, 2025 am 11:10 AM尽管总体广告增长超过了零售媒体的增长,但仍在放缓。 这个成熟阶段提出了挑战,包括生态系统破碎,成本上升,测量问题和整合复杂性。 但是,人工智能
 'AI是我们,比我们更多'Apr 25, 2025 am 11:09 AM
'AI是我们,比我们更多'Apr 25, 2025 am 11:09 AM在一系列闪烁和惰性屏幕中,一个古老的无线电裂缝带有静态的裂纹。这堆积不稳定的电子设备构成了“电子废物土地”的核心,这是身临其境展览中的六个装置之一,&qu&qu
 Google Cloud在下一个2025年对基础架构变得更加认真Apr 25, 2025 am 11:08 AM
Google Cloud在下一个2025年对基础架构变得更加认真Apr 25, 2025 am 11:08 AMGoogle Cloud的下一个2025:关注基础架构,连通性和AI Google Cloud的下一个2025会议展示了许多进步,太多了,无法在此处详细介绍。 有关特定公告的深入分析,请参阅我的文章
 IR的秘密支持者透露,Arcana的550万美元的AI电影管道说话,Arcana的AI Meme,Ai Meme的550万美元。Apr 25, 2025 am 11:07 AM
IR的秘密支持者透露,Arcana的550万美元的AI电影管道说话,Arcana的AI Meme,Ai Meme的550万美元。Apr 25, 2025 am 11:07 AM本周在AI和XR中:一波AI驱动的创造力正在通过从音乐发电到电影制作的媒体和娱乐中席卷。 让我们潜入头条新闻。 AI生成的内容的增长影响:技术顾问Shelly Palme


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

