



一、生成式模型商业化
现如今,生成式AI赛道火热。根据PitchBook统计数据,2022年生成式AI赛道总共获得约14亿美元的融资,几乎达到了过去5年的总和。OpenAI、Stability AI等明星公司,其他初创企业如Jasper、Regie.AI、Replika等均获得资本青睐。
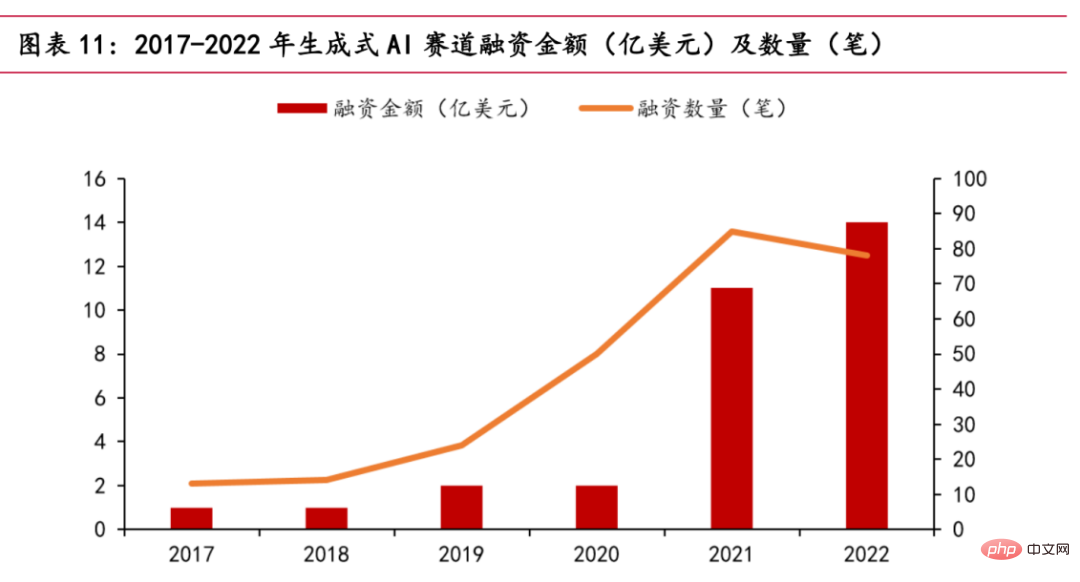
融资金额与时间关系图
2022年10月,Stability AI获得约1亿美元融资,发布的开源模型Stable Diffusion,可以根据用户输入的文字描述生成图片,引爆AI作画领域。2022年11月30日,ChatGPT在宣布公测之后,上线5天,全球用户数量已突破百万。上线不到40天,日活用户已突破千万。2023年3月15日凌晨,OpenAI发布目前最强的GPT系列模型——GPT-4,提供大规模的多模态模型,可以接受图像和文本输入,产生文本输出,在业内产生颠覆性的影响。2023年3月17日,微软举办了Microsoft 365 Copilot发布会,正式把OpenAI的GPT-4 模型装进了Office套件,推出了全新的AI功能Copilot。它不仅会做PPT,写文案,还会做分析,生成视频。此外,国内各个大厂也宣布陆续推出类ChatGPT的产品。2月8日,阿里巴巴专家爆料,达摩院正在研发类ChatGPT对话机器人,已开放给公司内员工测试。可能将AI大模型技术与钉钉生产力工具深度结合。2月8日,京东集团副总裁何晓冬坦言:京东在ChatGPT领域拥有丰富的场景和高质量的数据。2月9日,腾讯相关人士称:腾讯目前也有ChatGPT相似产品和AI生成内容的计划,专项研究也在有序推进。网易表示,教育业务将整合AI生成的内容,包括但不限于AI口语老师、作文打分和评价等。3月16日,百度百度正式发布大语言模型、生成式AI产品“文心一言”,发布两天,已有12家企业完成首批签约合作,申请百度智能云文心一言API调用服务测试的企业达9万。
目前,大模型已经逐渐渗透我们的生活。未来,各行各业都有可能出现翻天覆地的变化。以ChatGPT为例,包括以下几个方面:
- ChatGPT+传媒:可以实现新闻智能写作,提升新闻实效性;
- ChatGPT+影视:根据大众兴趣定制影视内容,获得更高收视率,票房和口碑降低影视制作团队在内容创作的成本,提高创作效率。
- ChatGPT+营销:充当虚拟客服,助力产品营销。例如24小时的产品介绍和在线服务,降低营销成本;可以快速了解客户需求,紧跟科技潮流;提供稳定可靠的咨询服务,可控性和安全性强。
- ChatGPT+娱乐:实时的聊天对象,增强陪伴性和趣味性。
- ChatGPT+教育:提供全新的教育工具,通过自助提问来快速查缺补漏。
- ChatGPT+金融:实现金融资讯,金融产品的自动化生产,塑造虚拟理财顾问。
- ChatGPT+医疗:快速了解患者病情且及时反馈,第一时间情感支持。
需要说明的是,这里虽然主要讨论的是大语言模型的落地,但是实际上其他多模态(音频、视频、图片)的大模型一样存在广阔的应用场景。
二、生成式模型介绍
1、主流的大语言模型:LaMDA
由google公司发布。LaMDA模型基于transformer框架,拥有1370亿模型参数,具备文本中长距离依赖的建模能力。该模型是通过对话来训练的。主要包括预训练和微调两个过程:在预训练阶段,他们使用了多达1.56T的公共对话数据集和网页文本,以语言模型(LM)作为训练的目标函数,即目标是预测下一个字符(token)。在微调阶段,他们设计来多个任务,例如给回复进行属性打分(敏感度、安全性等等),使语言模型对其人类的偏好。下图展示了其中一类的微调任务。

LaMDA模型预训练阶段

LaMDA模型微调阶段任务之一
LaMDA模型专注于对话生成任务,但常犯事实性的错误。谷歌今年发布了Bard(一项试验性的对话式AI服务)便是由LaMDA模型来提供支持。然而Bard在发布会上,Bard犯下事实性错误,这令谷歌周三股价大跌,盘中跌超8%,刷新日低至约98美元,市值蒸发1100亿美元,让人唏嘘。
2、主流的大语言模型:InstructGPT
InstructGPT模型基于GPT架构,主要由有监督的微调(Supervise Fune-Tuning, SFT)和人类反馈的强化学习(Reinforce Learning Human Fune-tuning, RLHF)训练得到。以InstructGPT为技术支持的对话产品——ChatGPT专注于生成语言文本,也可以生成代码和进行简单数学运算。具体的技术细节已经在上两期进行过详细探讨,读者可前往阅读,此处不再赘述。
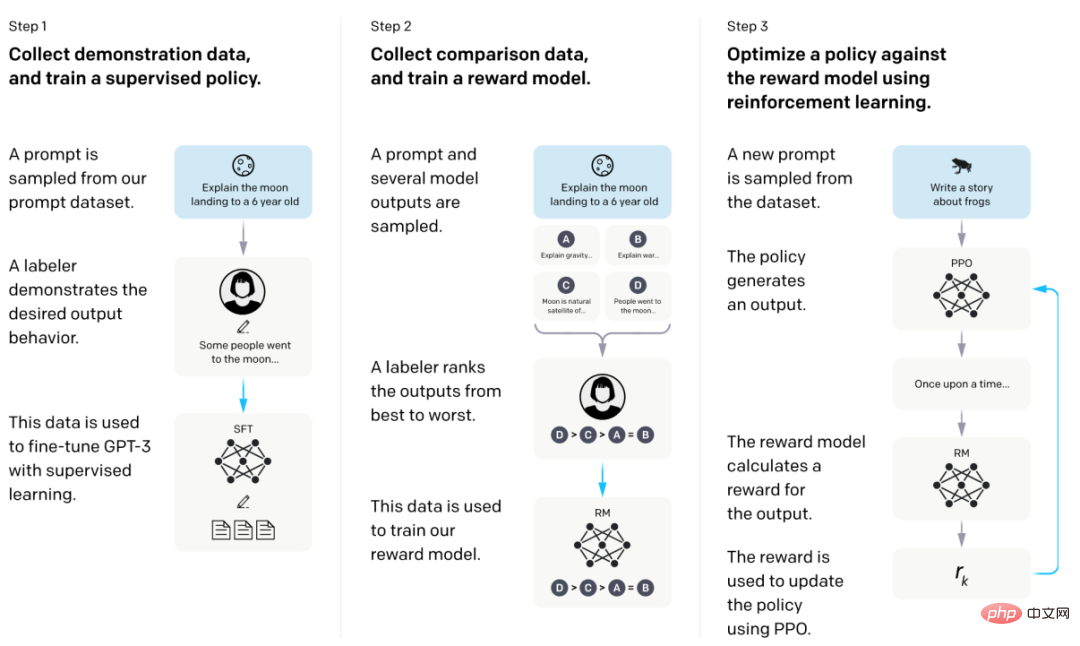
InstructGPT模型训练流程图
3、主流的大语言模型:Cluade
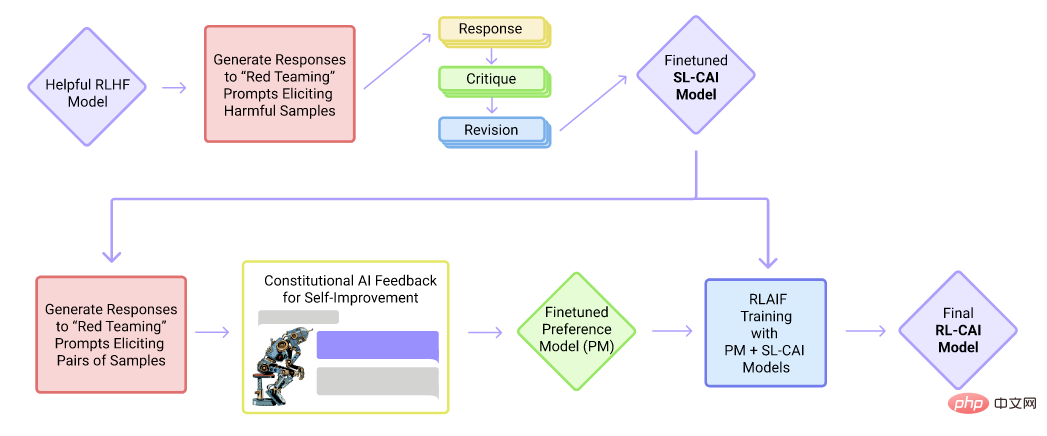
Cluade模型训练流程图
Cluade是Anthropic公司的对话型产品。Cluade与ChatGPT一样,都是基于GPT框架,是单向的语言模型。然而,不同于ChatGPT,它主要由有监督的微调和AI反馈的强化学习训练得到。在有监督的微调阶段,它先制定了一系列规则(Constitution),例如不能生成有害信息,不能生成种族偏见等等,然后根据这些规则获得有监督数据。随后,让AI来判断分辨回复的优劣,自动训练用于强化学习的数据集。
相比于ChatGPT而言,Claude 能更清晰地拒绝不恰当请求,句子之间衔接的也更自然。当遇到超出能力范围的问题时,Claude 会主动坦白。目前,Cluade当前还处于内测阶段。不过根据 Scale Sepllbook 团队成员内部测试结果显示,相比 ChatGPT,Claude在测试的12 项任务中有 8 项更强。
三、大语言模型的能力
我们统计了国内外的大语言模型以及模型能力、开源情况等。
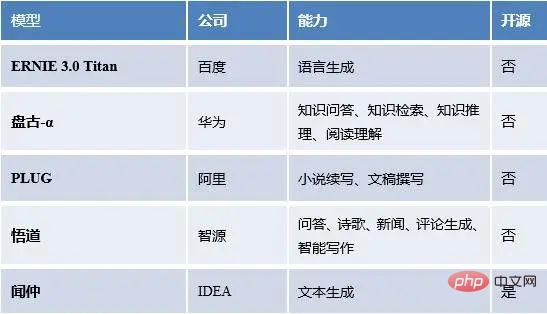
国内流行的大语言模型
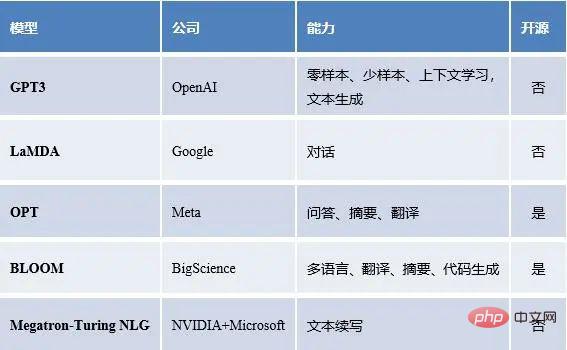
国外流行的大语言模型
可以看出,大语言模型表现的能力多种多样,包括但不限于少样本学习、零样本迁移等等。那么有个很自然但问题产生了,这些能力都是怎么样产生的呢?大语言模型的能力究竟来自于哪里?接下来,我们试图解答上述的疑惑。
下图展示了一些成熟大语言模型和进化过程。归纳出来,大多数模型会经历三个阶段:预训练,指令微调和对齐。代表模型有Deepmind的Sparrow和OpenAI的ChatGPT。
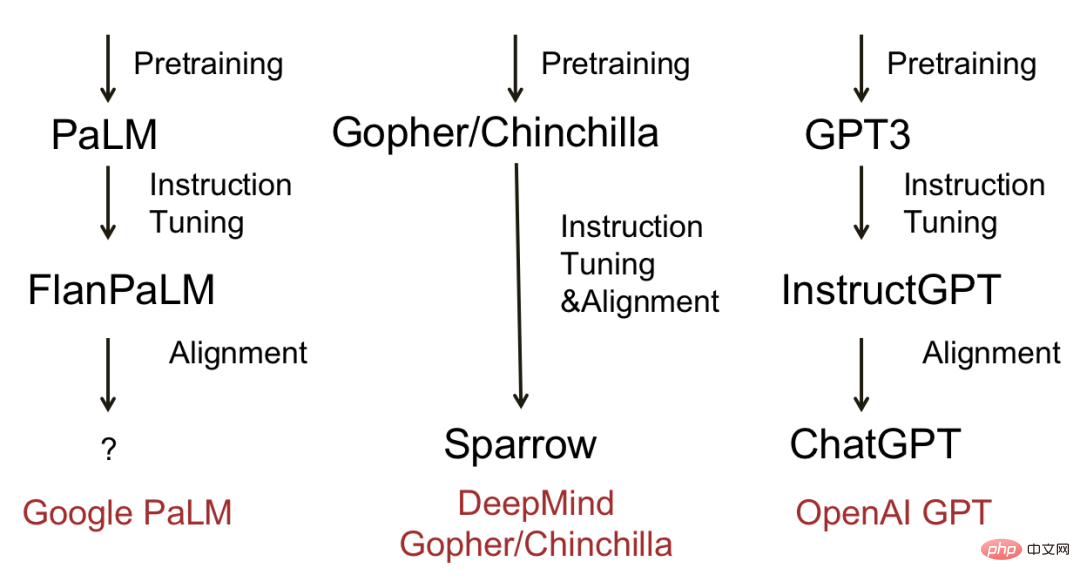
流行大语言模型的进化图
那么,在这每一步的背后,模型究竟可以获得什么样的能力呢?爱丁堡大学的符尧博士总结了他认为的步骤和能力的对应关系,给我们一些启发。
1. 预训练阶段,该阶段的目标是获得一个强大的基础模型。相应地,在此阶段模型展现出来的能力有:语言生成,上下文学习能力,具备世界的知识,推理能力等等。此阶段的代表性模型有GPT-3,PaLM等。
2. 指令微调阶段。该阶段的目标是解锁一些涌现能力(emergent ability)。这里的涌现能力是特指小模型没有,大模型才有的能力。经历过指令微调后的模型,出现了基础模型所没有的能力。例如,通过构造新的指令,模型能够解决新任务;再比如,思维链的能力,即通过展示给模型推理过程,模型也能仿照进行正确推理等,代表模型有InstructGPT,Flan等。
对齐阶段。该阶段的目标是使模型具备人类的价值观,比如要产生有信息量的回复,不能产生歧视类的发言等等。可以认为,对齐阶段赋予了模型们“个性化”。这类的代表模型有ChatGPT。
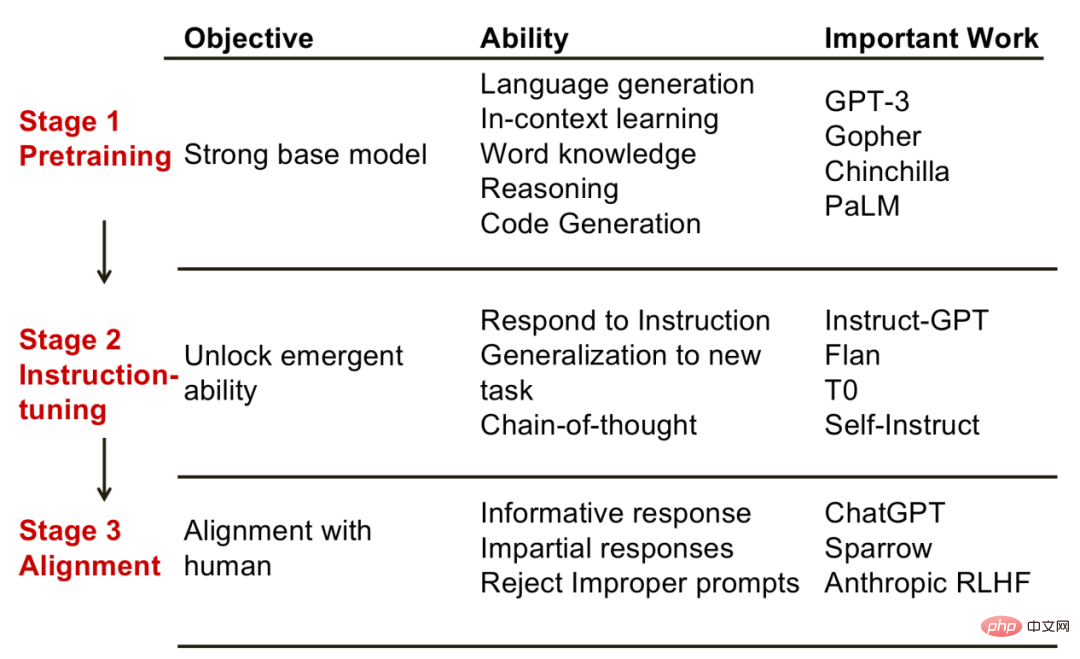
大语言模型三阶段。图片来自《符尧:论大语言模型能力的来源》
总地来说,上述三个阶段相辅相成,缺一不可。只有预训练阶段得到了一个足够强大的基础模型,才有可能通过指令微调激发(或者增强)语言模型的其他能力。对齐阶段赋予模型一定“性格”,更好地符合人类社会的一些要求。
四、生成式模型鉴别
大语言模型技术在带来便利的同时,也包含着风险和挑战。在技术层面,GPT生成的内容不能保证真实性,如会产生有害言论等。在使用层面,用户可能在教育、科研等领域滥用 AI产生的文本。目前,多家公司和机构开始对ChatGPT的使用施加限制。微软和亚马逊因担心泄露机密信息,禁止公司员工向ChatGPT分享敏感数据;香港大学禁止在港大所有课堂、作业和评估中使用ChatGPT或其他人工智能工具。我们主要介绍工业界的相关工作。
GPTZero:GPTZero是最早出现的文本生成鉴别工具。它是由Edward Tian(美国普林斯顿CS专业本科生)发布的在线网站(https://gptzero.me/)。它的原理靠文本困惑度(perplexity,PPL)作为指标来判断所给内容到底是谁写的。其中,困惑度用以评价语言模型的好坏指标,本质上是计算句子出现的概率。
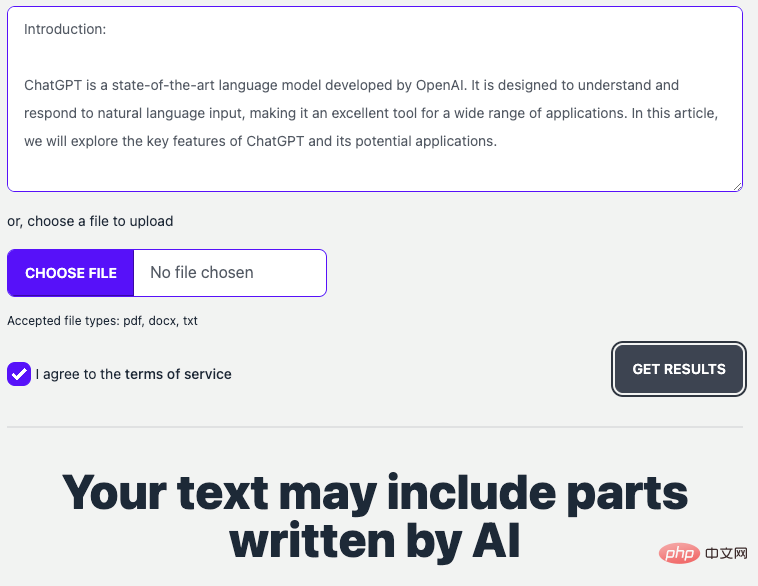
GPTZero网站界面
(这里我们使用ChatGPT产生一段新闻报道,让GPTZero判断是否是生成的文本。)
GPT2 Output Detector:该工具由OpenAI发布。它利用“GPT2-生成内容”和Reddit数据集,在RoBerta上进行微调,学习一个检测分类器。即“用魔法打败魔法”。官网也提示说,只有当文本超过50个字符(token)时,预测结果才更加可信。

GPT2 Output Detector网站界面
AI Text Classifier: 该工具由OpenAI发布。原理是收集在同一个话题下人类写作文本和AI写作文本。将每一个文本都划分成提示和回复对,让GPT微调后产生答案(例如,让GPT产生Yes/No)的概率作为结果阈值。该工具的划分非常细致,结果包括5类:非常不可能是AI生成的(阈值<0.1),不太可能是AI生成的(阈值0.1~0.45),不清楚是否是AI写的(阈值0.45~0.9),可能是AI生成的(阈值0.9-0.98),很可能是AI生成的(阈值>0.98)。
AI Text Classifier网站界面
五、总结&展望
大语言模型拥有小模型没有的涌现能力,例如优秀的零样本学习、领域迁移、思维链能力。大模型的能力实际上来自于预训练、指令微调和对齐,这三个过程密切相关,成就了现在超强的大语言模型。
大语言模型(GPT系列)目前还不具备置信更新、形式推理、互联网检索等能力,有专家认为,如果可以将知识卸载到模型之外,参数量会大大减少,大语言模型才能真正的更进一步。
只有在合理的监管和治理之下,人工智能技术才能更好地为人服务。国内发展大模型任重而道远!
参考文献
[1] https://stablediffusionweb.com
[2] https://openai.com/product/gpt-4
[3] LaMDA: Language Models for Dialog Applications, Arxiv 2022.10
[4] Constitutional AI: Harmlessness from AI Feedback,Arxiv 2022.12
[5] https://scale.com/blog/chatgpt-vs-claude#Calculation
[6] 国联证劵:《ChatGPT 风口已至,商业化落地加速》
[7] 国泰君安证券:《ChatGPT研究框架2023》
[8] 符尧:预训练、指令微调、对齐、专业化:论大语言模型能力的来源https://www.bilibili.com/video/BV1Qs4y1h7pn/?spm_id_from=333.880.my_history.page.click&vd_source=da8bf0b993cab65c4de0f26405823475
[9] 万字长文解析!复现和使用GPT-3/ChatGPT,你所应该知道的https://mp.weixin.qq.com/s/ILpbRRNP10Ef1z3lb2CqmA
以上是ChatGPT专题:大语言模型的能力和未来的详细内容。更多信息请关注PHP中文网其他相关文章!


 优化您的组织与Genai代理商的电子邮件营销Apr 13, 2025 am 11:44 AM
优化您的组织与Genai代理商的电子邮件营销Apr 13, 2025 am 11:44 AM介绍 恭喜!您经营一家成功的业务。通过您的网页,社交媒体活动,网络研讨会,会议,免费资源和其他来源,您每天收集5000个电子邮件ID。下一个明显的步骤是
 Apache Pinot实时应用程序性能监视Apr 13, 2025 am 11:40 AM
Apache Pinot实时应用程序性能监视Apr 13, 2025 am 11:40 AM介绍 在当今快节奏的软件开发环境中,确保最佳应用程序性能至关重要。监视实时指标,例如响应时间,错误率和资源利用率可以帮助MAIN
 Chatgpt击中了10亿用户? Openai首席执行官说:'短短几周内翻了一番Apr 13, 2025 am 11:23 AM
Chatgpt击中了10亿用户? Openai首席执行官说:'短短几周内翻了一番Apr 13, 2025 am 11:23 AM“您有几个用户?”他扮演。 阿尔特曼回答说:“我认为我们上次说的是每周5亿个活跃者,而且它正在迅速增长。” “你告诉我,就像在短短几周内翻了一番,”安德森继续说道。 “我说那个私人
 pixtral -12b:Mistral AI&#039;第一个多模型模型 - 分析VidhyaApr 13, 2025 am 11:20 AM
pixtral -12b:Mistral AI&#039;第一个多模型模型 - 分析VidhyaApr 13, 2025 am 11:20 AM介绍 Mistral发布了其第一个多模式模型,即Pixtral-12b-2409。该模型建立在Mistral的120亿参数Nemo 12B之上。是什么设置了该模型?现在可以拍摄图像和Tex
 生成AI应用的代理框架 - 分析VidhyaApr 13, 2025 am 11:13 AM
生成AI应用的代理框架 - 分析VidhyaApr 13, 2025 am 11:13 AM想象一下,拥有一个由AI驱动的助手,不仅可以响应您的查询,还可以自主收集信息,执行任务甚至处理多种类型的数据(TEXT,图像和代码)。听起来有未来派?在这个a




热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

禅工作室 13.0.1
功能强大的PHP集成开发环境

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

