
四款「ChatGPT搜索」全面对比!斯坦福华人博士纯手工标注:新必应流畅度最低,近一半句子都没引用

- 王林转载
- 2023-05-01 23:28:09985浏览
ChatGPT发布后不久,微软成功上车发布「新必应」,不仅股价大涨,甚至还大有取代谷歌,开启搜索引擎新时代的架势。
不过新必应真是大型语言模型的正确玩法吗?生成的答案真的对用户有用吗?句子里标的引文可信度有多少?
最近,斯坦福的研究人员从不同的来源收集了大量的用户查询,对当下四个大火的生成性搜索引擎,新必应(Bing Chat),NeevaAI,perplexity.ai和 YouChat进行了人工评估。

论文链接:https://arxiv.org/pdf/2304.09848.pdf
实验结果发现,来自现有生成搜索引擎的回复流畅且信息量大,但经常包含没有证据的陈述和不准确的引用。
平均来说,只有51.5%的引用可以完全支撑生成的句子,只有74.5% 的引用可以作为相关句子的证据支持。
研究人员认为,对于那些可能成为信息搜寻用户主要工具的系统来说,这个结果实在是过低了,特别是考虑到有些句子只是貌似可信的话,生成式搜索引擎仍然需要进一步优化。

个人主页:https://cs.stanford.edu/~nfliu/
第一作者Nelson Liu是斯坦福大学自然语言处理组的四年级博士生,导师为Percy Liang,本科毕业于华盛顿大学,主要研究方向为构建实用的NLP系统,尤其是用于信息查找的应用程序。
别轻信生成式搜索引擎
2023年3月,微软报告说「大约三分之一的每日预览用户每天都在使用[Bing]聊天」,并且Bing聊天在其公开预览的第一个月提供了4500万次聊天,也就是说,把大型语言模型融合进搜索引擎是非常有市场的,极有可能改变互联网的搜索入口。

但目前来看,现有的基于大型语言模型技术的生成式搜索引擎仍然存在准确率不高的问题,但具体的准确率仍然没有得到全面评估,进而也无法了解到新型搜索引擎的局限之处。
可验证性(verifiability)是提升搜索引擎可信度的关键,即为生成答案中的每一句话都提供引文的外部链接来作为证据支撑,可以使用户更容易验证答案的准确程度。
研究人员通过收集不同类型、来源的问题,在四个商业生成式搜索引擎(Bing Chat, NeevaAI, perplexity.ai, YouChat)上进行人工评估。
评估指标主要包括流畅性,即生成的文本是否连贯;有用性,即搜索引擎的回复对于用户来说是否有帮助,以及答案中的信息是否能够解决问题;引用召回,即生成的关于外部网站的句子中包含引用支持的比例;引用精度,即生成的引用支持其相关句子的比例。
流畅性(fluency)
同时展示用户查询、生成的回复以及声明「该回复是流畅且语义连贯的」,标注人员以五分制Likert量表对数据进行打分。
有用性(perceived utility)
与流畅性类似,标注人员需要评定他们对「该回复是对用户查询来说是有用且有信息量的 」这一说法的同意程度。
引用召回(citation recall)
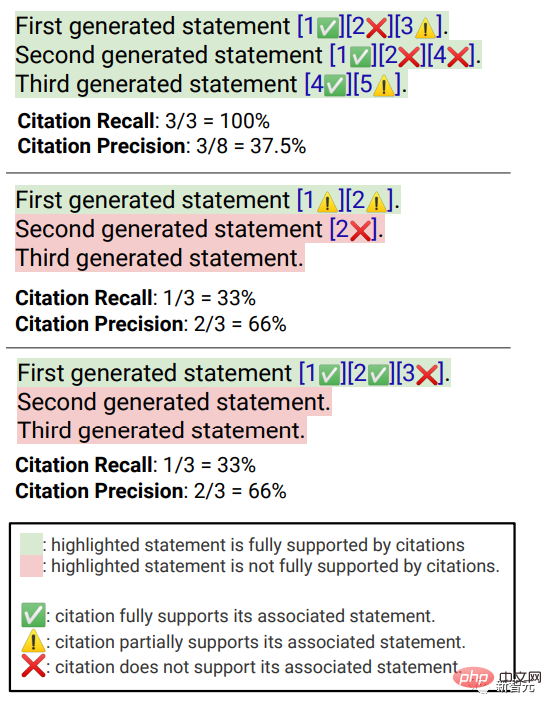
引用召回率是指由其相关引文完全支持的、值得验证的句子的比例,所以该指标的计算需要确定回复中值得验证的句子,以及评估每个值得验证的句子能够被相关引文支持。
在「识别值得验证的句子」过程中,研究人员认为关于外部世界的每一个生成的句子都是值得验证的,即使是那些可能看起来很明显、微不足道的常识,因为对于某些读者来说似乎是明显的「常识」,但其实可能并不正确。
搜索引擎系统的目标应该是为所有生成的关于外部世界的句子提供参考来源,使读者能够轻松地验证生成的回复中的任何叙述,不能为了简单而牺牲可验证性。
所以实际上标注人员对所有生成的句子都进行验证,除了那些以系统为第一人称的回复,如「作为一个语言模型,我没有能力做...」,或是对用户的提问,如「你想了解更多吗?」等。
评估「一个值得验证的陈述是否得到其相关引文的充分支持」可以基于归因已识别来源(AIS, attributable to identified sources)评估框架,标注人员进行二元标注,即如果一个普通的听众认可「基于引用的网页,可以得出...」,那引文即可完全支持该回复。
引用精确率
为了衡量引用的精确率,标注人员需要判断每个引用是否对其相关的句子提供了全部、部分或无关支持。
完全支持(full support):句子中的所有信息都得到了引文的支持。
部分支持(Partial support):句子中的一些信息得到了引文的支持,但其他部分可能存在缺失或矛盾。
无关支持(No support):如引用的网页完全不相关或相互矛盾。
对于有多个相关引文的句子,还会额外要求标注人员使用AIS评估框架判断所有相关引文网页作为一个整体是否为该句子提供了充分的支持(二元判断)。
实验结果
在流畅性和有用性评估中,可以看到各个搜索引擎都能够生成非常流畅且有用的回复。
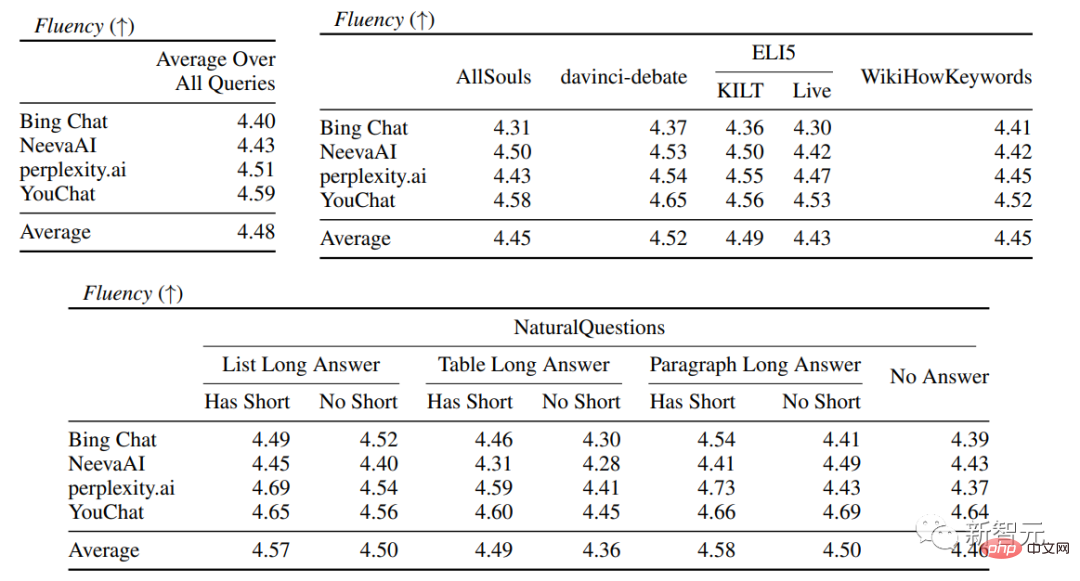
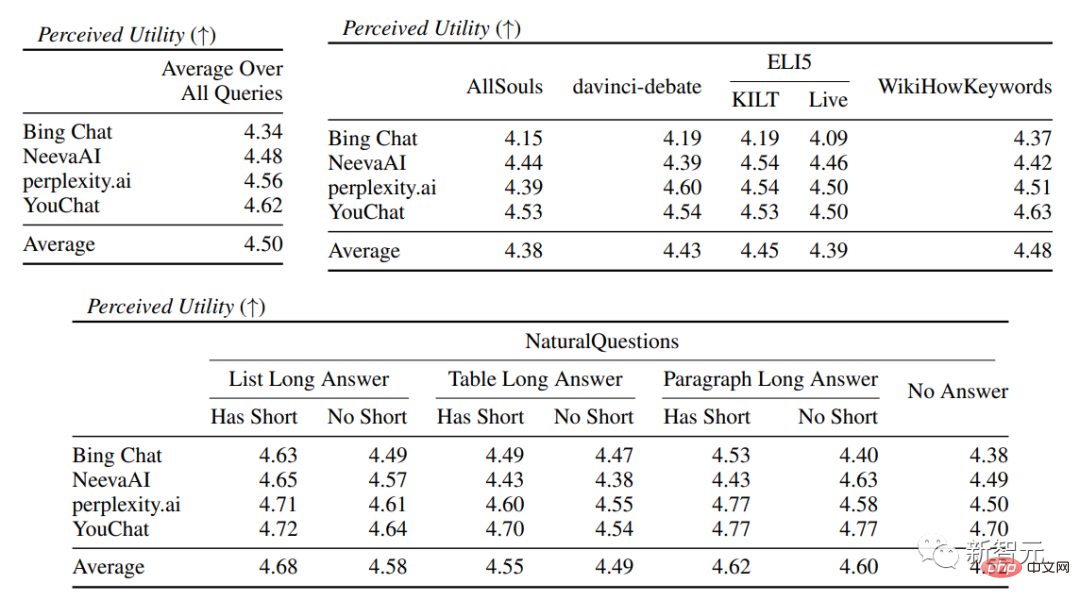
在具体的搜索引擎评估中,可以看到看到Bing Chat的流畅性/有用性评分最低(4.40/4.34),其次是NeevaAI(4.43/4.48),perplexity.ai(4.51/4.56),以及YouChat(4.59/4.62)。
在不同类别的用户查询中,可以看到较短的提取性问题通常比长问题要更流畅,通常只回答事实性知识即可;一些有难度的问题通常需要对不同的表格或网页进行汇总,合成过程会降低整体的流畅性。
在引文评估中,可以看到现有的生成式搜索引擎往往不能全面或正确地引用网页,平均只有51.5%的生成句子得到了引文的完全支持(召回率),只有74.5%的引文完全支持其相关句子(精确度)。
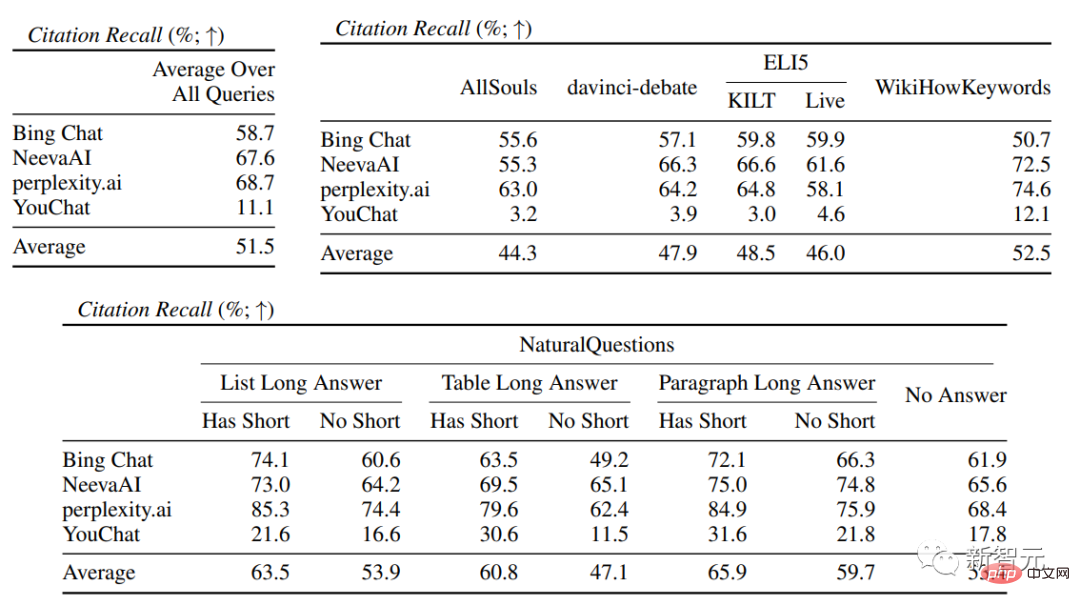
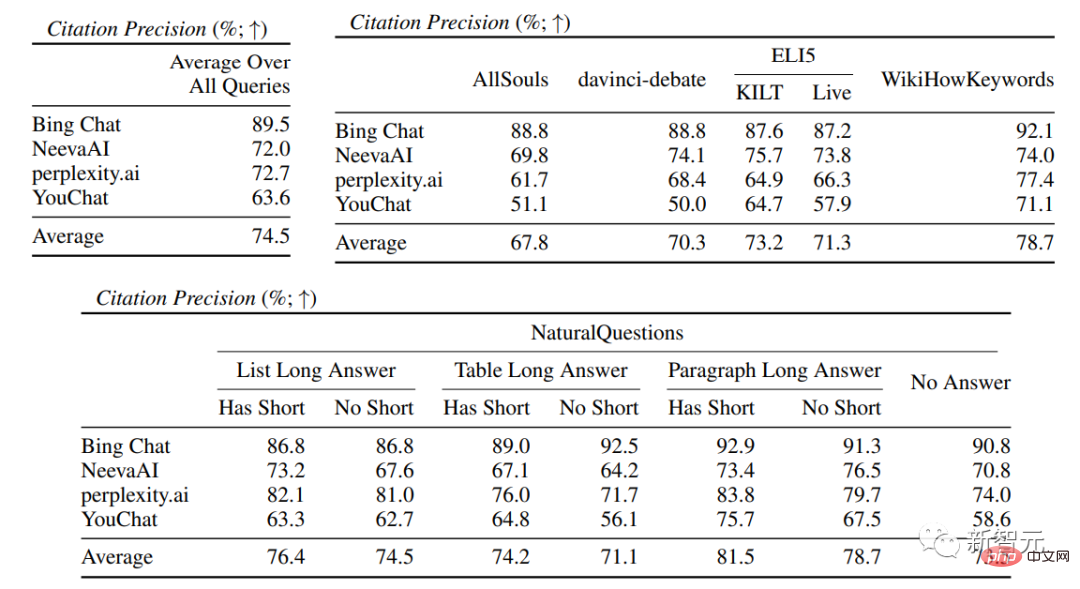
这个数值来说对于已经拥有数百万用户的搜索引擎系统来说是不可接受的,特别是在生成回复往往信息量比较大的情况下。
并且不同的生成式搜索引擎之间的引文召回率和精确度有很大差异,其中perplexity.ai实现了最高的召回率(68.7),而NeevaAI(67.6)、Bing Chat(58.7)和YouChat(11.1)较低。
另一方面,Bing Chat实现了最高的精确度(89.5),其次是perplexity.ai(72.7)、NeevaAI(72.0)和YouChat(63.6)
在不同的用户查询中,有长答案的NaturalQuestions查询和非NaturalQuestions查询之间的引用召回率差距接近11%(分别为58.5和47.8);
同样,有短答案的NaturalQuestions查询和无短答案的NaturalQuestions查询之间的引用召回率差距接近10%(有短答案的查询为63.4,只有长答案的查询为53.6,而无长或短答案的查询为53.4)。
在没有网页支持的问题中,引用率就会较低,例如对开放式的AllSouls论文问题进行评估时,生成式搜索引擎在引文召回率方面只有44.3
以上是四款「ChatGPT搜索」全面对比!斯坦福华人博士纯手工标注:新必应流畅度最低,近一半句子都没引用的详细内容。更多信息请关注PHP中文网其他相关文章!