



译者 | 朱先忠
审校 | 重楼
图像来自文章https://www.php.cn/link/f74412c3c1c8899f3c130bb30ed0e363,由作者本人制作
人工智能在改变我们的生活、工作和与技术互动的方式方面取得了令人难以置信的进步。最近,一个取得重大进展的领域是大型语言模型(LLM)的开发,如GPT-3、ChatGPT和GPT-4。这些模型能够以令人印象深刻的准确性执行语言完成翻译、文本摘要和问答等任务。
虽然很难忽视大型语言模型不断增加的模型规模,但同样重要的是要认识到,它们的成功很大程度上归功于用于训练它们的大量高质量数据。
在本文中,我们将从以数据为中心的人工智能角度概述大型语言模型的最新进展,参考我们最近的调查论文(末尾文献1与2)中的观点以及GitHub上的相应技术资源。特别是,我们将通过以数据为中心的人工智能的视角仔细研究GPT模型,这是数据科学界日益增长的一种观点。我们将通过讨论三个以数据为中心的人工智能目标——训练数据开发、推理数据开发和数据维护,来揭示GPT模型背后以数据为核心的人工智能概念。
大型语言模型与GPT模型
LLM(大型语言模型)是一种自然语言处理模型,经过训练可以在上下文中推断单词。例如,LLM最基本的功能是在给定上下文的情况下预测丢失的令牌。为了做到这一点,LLM被训练来从海量数据中预测每个候选令牌的概率。

使用具有上下文的大型语言模型预测丢失令牌的概率的说明性示例(作者本人提供的图片)
GPT模型是指OpenAI创建的一系列大型语言模型,如GPT-1、GPT-2、GPT-3、InstructGPT和ChatGPT/GPT-4。与其他大型语言模型一样,GPT模型的架构在很大程度上基于转换器(Transformer),它使用文本和位置嵌入作为输入,并使用注意力层来建模令牌间的关系。
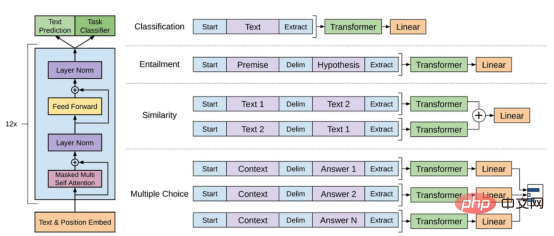
GPT-1模型体系架构示意图,本图像来自论文https://www.php.cn/link/c3bfbc2fc89bd1dd71ad5fc5ac96ae69
后来的GPT模型使用了与GPT-1类似的架构,只是使用了更多的模型参数,具有更多的层、更大的上下文长度、隐藏层大小等。

GPT模型的各种模型大小比较(作者提供图片)
什么是以数据为中心的人工智能?
以数据为中心的人工智能是一种新兴的思考如何构建人工智能系统的新方式。人工智能先驱吴恩达(Andrew Ng)一直在倡导这一理念。
以数据为中心的人工智能是对用于构建人工智能系统的数据进行系统化工程的学科。
——吴恩达
过去,我们主要专注于在数据基本不变的情况下创建更好的模型(以模型为中心的人工智能)。然而,这种方法可能会在现实世界中导致问题,因为它没有考虑数据中可能出现的不同问题,例如不准确的标签、重复和偏置。因此,“过度拟合”一个数据集可能不一定会导致更好的模型行为。
相比之下,以数据为中心的人工智能专注于提高用于构建人工智能系统的数据的质量和数量。这意味着,注意力将集中在数据本身,而模型相对来说更固定。以数据为中心的方法开发人工智能系统在现实世界中具有更大的潜力,因为用于训练的数据最终决定了模型的最大能力。
值得注意的是,“以数据为中心”与“数据驱动”有根本不同,因为后者只强调使用数据来指导人工智能开发,而人工智能开发通常仍以开发模型而非工程数据为中心。
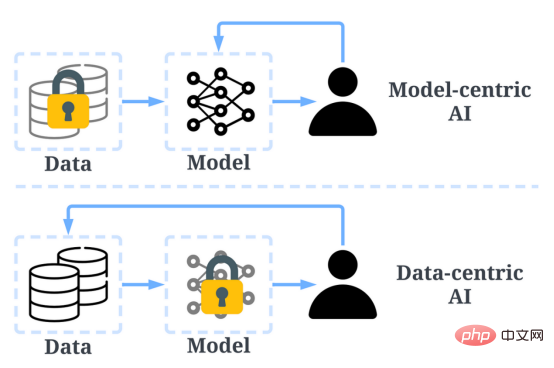
以数据为中心的人工智能与以模型为中心的AI的比较(图片来自https://www.php.cn/link/f9afa97535cf7c8789a1c50a2cd83787论文作者)
总体来看,以数据为中心的人工智能框架由三个目标组成:
- 训练数据开发是收集和产生丰富、高质量的数据,以支持机器学习模型的训练。
- 推理数据开发是为了创建新的评估集,这些评估集可以为模型提供更精细的见解,或者通过工程数据输入触发模型的特定能力。
- 数据维护是为了确保数据在动态环境中的质量和可靠性。数据维护至关重要,因为现实世界中的数据不是一次性创建的,而是需要持续维护的。
以数据为中心的人工智能框架(图像来自论文https://www.php.cn/link/f74412c3c1c8899f3c130bb30ed0e363的作者)
为什么以数据为中心的人工智能使GPT模型如此成功?
几个月前,人工智能界大佬Yann LeCun在其推特上表示,ChatGPT并不是什么新鲜事。事实上,在ChatGPT和GPT-4中使用的所有技术(Transformer和从人类反馈中强化学习等)都不是新技术。然而,他们确实取得了以前的模型无法取得的令人难以置信的成绩。那么,他们成功的动力是什么呢?
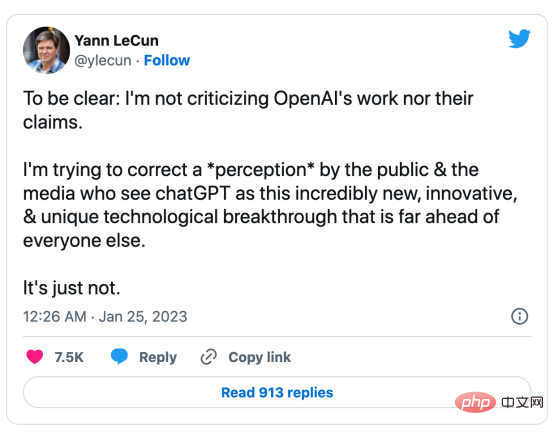
首先,加强训练数据开发。通过更好的数据收集、数据标记和数据准备策略,用于训练GPT模型的数据的数量和质量显著提高。
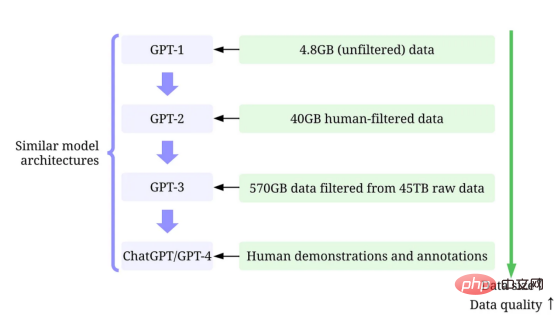
- GPT-1:BooksCorpus数据集用于训练。该数据集包含4629MB的原始文本,涵盖了冒险、幻想和浪漫等一系列流派的书籍。
- 没有使用以数据为中心的人工智能策略。
- 训练结果:在该数据集上应用GPT-1可以通过微调来提高下游任务的性能。
- 采用了以数据为中心的人工智能策略:(1)仅使用Reddit的出站链接来控制/过滤数据,该链接至少收到3个结果;(2)使用工具Dragnet和Newspaper提取“干净”的内容;(3)采用重复数据消除和其他一些基于启发式的净化方法(论文中没有提到细节)。
- 训练结果:净化后得到40GB的文本。GPT-2无需微调即可实现强大的零样本结果。
- 使用了以数据为中心的人工智能策略:(1)训练分类器,根据每个文档与WebText的相似性筛选出低质量文档,WebText是高质量文档的代理。(2)使用Spark的MinHashLSH对文档进行模糊的重复数据消除。(3)使用WebText、图书语料库和维基百科来增强数据。
- 训练结果:从45TB的明文中过滤得到570GB的文本(在本次质量过滤中仅选择1.27%的数据)。在零样本设置中,GPT-3显著优于GPT-2。
- 使用了以数据为中心的人工智能策略:(1)使用人工提供的提示答案,通过监督训练调整模型。(2)收集比较数据以训练奖励模型,然后使用该奖励模型通过来自人类反馈的强化学习(RLHF)来调整GPT-3。
- 训练结果:InstructGPT显示出更好的真实性和更少的偏差,即更好的一致性。
- GPT-2:使用WebText来进行训练。这是OpenAI中的一个内部数据集,通过从Reddit中抓取出站链接创建。
- GPT-3:GPT-3的训练主要基于Common Crawl工具。
- InstructGPT:让人类评估调整GPT-3的答案,使其能够更好地符合人类的期望。他们为注释器设计了测试,只有那些能够通过测试的人才有资格进行注释。此外,他们甚至还设计了一项调查,以确保注释者喜欢注释过程。
- ChatGPT/GPT-4:OpenAI未披露详细信息。但众所周知,ChatGPT/GPT-4在很大程度上遵循了以前GPT模型的设计,它们仍然使用RLHF来调整模型(可能有更多、更高质量的数据/标签)。人们普遍认为,随着模型权重的增加,GPT-4使用了更大的数据集。
其次,进行推理数据开发。由于最近的GPT模型已经足够强大,我们可以通过在固定模型的情况下调整提示(或调整推理数据)来实现各种目标。例如,我们可以通过提供摘要的文本以及“summarize it”或“TL;DR”等指令来进行文本摘要,以指导推理过程。

提示符微调,图片由作者提供
设计正确的推理提示是一项具有挑战性的任务。它在很大程度上依赖于启发式技术。一项很好的调查总结了目前为止人们使用的不同的提示方法。有时,即使在语义上相似的提示也可能具有非常不同的输出。在这种情况下,可能需要基于软提示的校准来减少差异。
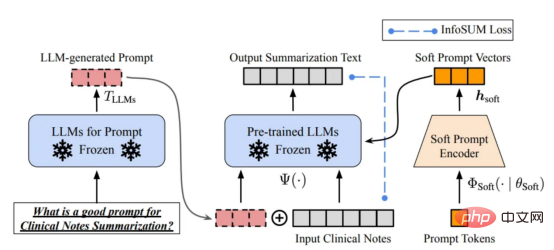
基于软提示符的校准。本图像来自于论文https://arxiv.org/abs/2303.13035v1,经原作者许可
大型语言模型推理数据开发的研究仍处于早期阶段。在不久的将来,已经在其他任务中使用的更多推理数据开发技术可能会应用于大型语言模型领域。
就数据维护方面来说,ChatGPT/GPT-4作为一种商业产品,并不仅仅是训练一次成功的,而是需要不断更新和维护。显然,我们不知道数据维护是如何在OpenAI之外执行的。因此,我们讨论了一些以数据为中心的通用人工智能策略,这些策略很可能已用于或将用于GPT模型:
- 持续数据收集:当我们使用ChatGPT/GPT-4时,我们的提示/反馈反过来可以被OpenAI用来进一步推进他们的模型。可能已经设计和实施了质量指标和保证策略,以便在此过程中收集高质量的数据。
- 数据理解工具:有可能已经开发出各种工具来可视化和理解用户数据,促进更好地理解用户的需求,并指导未来的改进方向。
- 高效的数据处理:随着ChatGPT/GPT-4用户数量的快速增长,需要一个高效的数据管理系统来实现快速的数据采集。
ChatGPT/GPT-4系统能够通过如图所示的“拇指向上”和“拇指向下”两个图标按钮收集用户反馈,以进一步促进他们的系统发展。此处屏幕截图来自于https://chat.openai.com/chat。
数据科学界能从这一波大型语言模型中学到什么?
大型语言模型的成功彻底改变了人工智能。展望未来,大型语言模型可能会进一步彻底改变数据科学的生命周期。为此,我们做出两个预测:
- 以数据为中心的人工智能变得更加重要。经过多年的研究,模型设计已经非常成熟,尤其是在Transformer之后。工程数据成为未来改进人工智能系统的关键(或可能是唯一)方法。此外,当模型变得足够强大时,我们不需要在日常工作中训练模型。相反,我们只需要设计适当的推理数据(即时工程)来从模型中探索知识。因此,以数据为中心的人工智能的研发将推动未来的进步。
- 大型语言模型将实现更好的以数据为中心的人工智能解决方案。在大型语言模型的帮助下,许多乏味的数据科学工作可以更有效地进行。例如,ChaGPT/GPT-4已经可以编写可操作的代码来处理和清理数据。此外,大型语言模型甚至可以用于创建用于训练的数据。例如,最近的工作表明,使用大型语言模型生成合成数据可以提高临床文本挖掘中的模型性能。
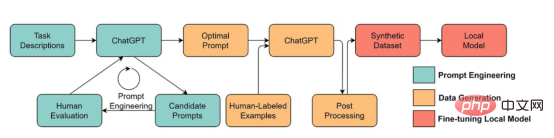
使用大型语言模型生成合成数据以训练模型,此处图像来自论文https://arxiv.org/abs/2303.04360,经原作者许可
参考资料
我希望这篇文章能在你自己的工作中给你带来启发。您可以在以下论文中了解更多关于以数据为中心的人工智能框架及其如何为大型语言模型带来好处:
[1]以数据为中心的人工智能综述。
[2]以数据为中心的人工智能前景与挑战。
注意,我们还维护了一个GitHub代码仓库,它将定期更新相关的以数据为中心的人工智能资源。
在以后的文章中,我将深入研究以数据为中心的人工智能的三个目标(训练数据开发、推理数据开发和数据维护),并介绍具有代表性的方法。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:What Are the Data-Centric AI Concepts behind GPT Models?,作者:Henry Lai
以上是GPT模型中的数据中心型AI揭秘的详细内容。更多信息请关注PHP中文网其他相关文章!

 AI内部部署的隐藏危险:治理差距和灾难性风险Apr 28, 2025 am 11:12 AM
AI内部部署的隐藏危险:治理差距和灾难性风险Apr 28, 2025 am 11:12 AMApollo Research的一份新报告显示,先进的AI系统的不受检查的内部部署构成了重大风险。 在大型人工智能公司中缺乏监督,普遍存在,允许潜在的灾难性结果
 构建AI测谎仪Apr 28, 2025 am 11:11 AM
构建AI测谎仪Apr 28, 2025 am 11:11 AM传统测谎仪已经过时了。依靠腕带连接的指针,打印出受试者生命体征和身体反应的测谎仪,在识破谎言方面并不精确。这就是为什么测谎结果通常不被法庭采纳的原因,尽管它曾导致许多无辜者入狱。 相比之下,人工智能是一个强大的数据引擎,其工作原理是全方位观察。这意味着科学家可以通过多种途径将人工智能应用于寻求真相的应用中。 一种方法是像测谎仪一样分析被审问者的生命体征反应,但采用更详细、更精确的比较分析。 另一种方法是利用语言标记来分析人们实际所说的话,并运用逻辑和推理。 俗话说,一个谎言会滋生另一个谎言,最终
 AI是否已清除航空航天行业的起飞?Apr 28, 2025 am 11:10 AM
AI是否已清除航空航天行业的起飞?Apr 28, 2025 am 11:10 AM航空航天业是创新的先驱,它利用AI应对其最复杂的挑战。 现代航空的越来越复杂性需要AI的自动化和实时智能功能,以提高安全性,降低操作
 观看北京的春季机器人比赛Apr 28, 2025 am 11:09 AM
观看北京的春季机器人比赛Apr 28, 2025 am 11:09 AM机器人技术的飞速发展为我们带来了一个引人入胜的案例研究。 来自Noetix的N2机器人重达40多磅,身高3英尺,据说可以后空翻。Unitree公司推出的G1机器人重量约为N2的两倍,身高约4英尺。比赛中还有许多体型更小的类人机器人参赛,甚至还有一款由风扇驱动前进的机器人。 数据解读 这场半程马拉松吸引了超过12,000名观众,但只有21台类人机器人参赛。尽管政府指出参赛机器人赛前进行了“强化训练”,但并非所有机器人均完成了全程比赛。 冠军——由北京类人机器人创新中心研发的Tiangong Ult
 镜子陷阱:人工智能伦理和人类想象力的崩溃Apr 28, 2025 am 11:08 AM
镜子陷阱:人工智能伦理和人类想象力的崩溃Apr 28, 2025 am 11:08 AM人工智能以目前的形式并不是真正智能的。它擅长模仿和完善现有数据。 我们不是在创造人工智能,而是人工推断 - 处理信息的机器,而人类则
 新的Google泄漏揭示了方便的Google照片功能更新Apr 28, 2025 am 11:07 AM
新的Google泄漏揭示了方便的Google照片功能更新Apr 28, 2025 am 11:07 AM一份报告发现,在谷歌相册Android版7.26版本的代码中隐藏了一个更新的界面,每次查看照片时,都会在屏幕底部显示一行新检测到的面孔缩略图。 新的面部缩略图缺少姓名标签,所以我怀疑您需要单独点击它们才能查看有关每个检测到的人员的更多信息。就目前而言,此功能除了谷歌相册已在您的图像中找到这些人之外,不提供任何其他信息。 此功能尚未上线,因此我们不知道谷歌将如何准确地使用它。谷歌可以使用缩略图来加快查找所选人员的更多照片的速度,或者可能用于其他目的,例如选择要编辑的个人。我们拭目以待。 就目前而言
 加固芬特的指南 - 分析VidhyaApr 28, 2025 am 09:30 AM
加固芬特的指南 - 分析VidhyaApr 28, 2025 am 09:30 AM增强者通过教授模型根据人类反馈进行调整来震撼AI的开发。它将监督的学习基金会与基于奖励的更新融合在一起,使其更安全,更准确,真正地帮助
 让我们跳舞:结构化运动以微调我们的人类神经网Apr 27, 2025 am 11:09 AM
让我们跳舞:结构化运动以微调我们的人类神经网Apr 27, 2025 am 11:09 AM科学家已经广泛研究了人类和更简单的神经网络(如秀丽隐杆线虫中的神经网络),以了解其功能。 但是,出现了一个关键问题:我们如何使自己的神经网络与新颖的AI一起有效地工作


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

SublimeText3汉化版
中文版,非常好用

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

