



我们知道,基于分数的模型和去噪扩散概率模型(DDPM)是两类强大的生成模型,它们通过反转扩散过程来产生样本。这两类模型已经在 Yang Song 等研究者的论文《Score-based generative modeling through stochastic differential equations》中统一到了单一的框架下,并被广泛地称为扩散模型。
目前,扩散模型在包括图像、音频、视频生成以及解决逆问题等一系列应用中取得了巨大的成功。Tero Karras 等研究者在论文《Elucidating the design space of diffusionbased generative models》中对扩散模型的设计空间进行了分析,并确定了 3 个阶段,分别为 i) 选择噪声水平的调度,ii) 选择网络参数化(每个参数化生成一个不同的损失函数),iii) 设计采样算法。
近日,在谷歌研究院和 UT-Austin 合作的一篇 arXiv 论文《Soft Diffusion: Score Matching for General Corruptions》中,几位研究者认为扩散模型仍有一个重要的步骤:损坏(corrupt)。一般来说,损坏是一个添加不同幅度噪声的过程,对于 DDMP 还需要重缩放。虽然有人尝试使用不同的分布来进行扩散,但仍缺乏一个通用的框架。因此,研究者提出了一个用于更通用损坏过程的扩散模型设计框架。
具体地,他们提出了一个名为 Soft Score Matching 的新训练目标和一种新颖的采样方法 Momentum Sampler。理论结果表明,对于满足正则条件的损坏过程,Soft Score MatchIng 能够学习它们的分数(即似然梯度),扩散必须将任何图像转换为具有非零似然的任何图像。
在实验部分,研究者在 CelebA 以及 CIFAR-10 上训练模型,其中在 CelebA 上训练的模型实现了线性扩散模型的 SOTA FID 分数——1.85。同时与使用原版高斯去噪扩散训练的模型相比,研究者训练的模型速度显著更快。

论文地址:https://arxiv.org/pdf/2209.05442.pdf
方法概览
通常来说,扩散模型通过反转逐渐增加噪声的损坏过程来生成图像。研究者展示了如何学习对涉及线性确定性退化和随机加性噪声的扩散进行反转。

具体地,研究者展示了使用更通用损坏模型训练扩散模型的框架,包含有三个部分,分别为新的训练目标 Soft Score Matching、新颖采样方法 Momentum Sampler 和损坏机制的调度。
首先来看训练目标 Soft Score Matching,这个名字的灵感来自于软过滤,是一种摄影术语,指的是去除精细细节的过滤器。它以一种可证明的方式学习常规线性损坏过程的分数,还在网络中合并入了过滤过程,并训练模型来预测损坏后与扩散观察相匹配的图像。
只要扩散将非零概率指定为任何干净、损坏的图像对,则该训练目标可以证明学习到了分数。另外,当损坏中存在加性噪声时,这一条件总是可以得到满足。
具体地,研究者探究了如下形式的损坏过程。

在过程中,研究者发现噪声在实证(即更好的结果)和理论(即为了学习分数)这两方面都很重要。这也成为了其与反转确定性损坏的并发工作 Cold Diffusion 的关键区别。
其次是采样方法 Momentum Sampling。研究者证明,采样器的选择对生成样本质量具有显著影响。他们提出了 Momentum Sampler,用于反转通用线性损坏过程。该采样器使用了不同扩散水平的损坏的凸组合,并受到了优化中动量方法的启发。
这一采样方法受到了上文 Yang Song 等人论文提出的扩散模型连续公式化的启发。Momentum Sampler 的算法如下所示。

下图直观展示了不同采样方法对生成样本质量的影响。图左使用 Naive Sampler 采样的图像似乎有重复且缺少细节,而图右 Momentum Sampler 显著提升了采样质量和 FID 分数。

最后是调度。即使退化的类型是预定义的(如模糊),决定在每个扩散步骤中损坏多少并非易事。研究者提出一个原则性工具来指导损坏过程的设计。为了找到调度,他们将沿路径分布之间的 Wasserstein 距离最小化。直观地讲,研究者希望从完全损坏的分布平稳过渡到干净的分布。
实验结果
研究者在 CelebA-64 和 CIFAR-10 上评估了提出的方法,这两个数据集都是图像生成的标准基线。实验的主要目的是了解损坏类型的作用。
研究者首先尝试使用模糊和低幅噪声进行损坏。结果表明,他们提出的模型在 CelebA 上实现了 SOTA 结果,即 FID 分数为 1.85,超越了所有其他仅添加噪声以及可能重缩放图像的方法。此外在 CIFAR-10 上获得的 FID 分数为 4.64,虽未达到 SOTA 但也具有竞争力。

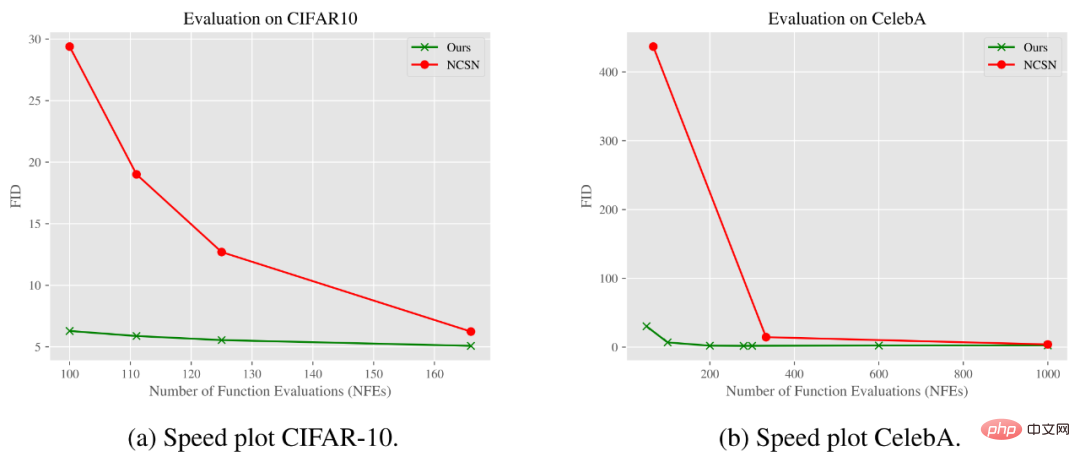
此外,在 CIFAR-10 和 CelebA 数据集上,研究者的方法在另一项指标采样时间上也表现更好。另一个额外的好处是具有显著的计算优势。与图像生成去噪方法相比,去模糊(几乎没有噪声)似乎是一种更有效的操纵。
下图展示了 FID 分数如何随着函数评估数量(Number of Function Evaluations, NFE)而变。从结果可以看到,在 CIFAR-10 和 CelebA 数据集上,研究者的模型可以使用明显更少的步骤来获得与标准高斯去噪扩散模型相同或更好的质量。
以上是Soft Diffusion:谷歌新框架从通用扩散过程中正确调度、学习和采样的详细内容。更多信息请关注PHP中文网其他相关文章!

 Gemma范围:Google'用于凝视AI的显微镜Apr 17, 2025 am 11:55 AM
Gemma范围:Google'用于凝视AI的显微镜Apr 17, 2025 am 11:55 AM使用Gemma范围探索语言模型的内部工作 了解AI语言模型的复杂性是一个重大挑战。 Google发布的Gemma Scope是一种综合工具包,为研究人员提供了一种强大的探索方式
 谁是商业智能分析师以及如何成为一位?Apr 17, 2025 am 11:44 AM
谁是商业智能分析师以及如何成为一位?Apr 17, 2025 am 11:44 AM解锁业务成功:成为商业智能分析师的指南 想象一下,将原始数据转换为驱动组织增长的可行见解。 这是商业智能(BI)分析师的力量 - 在GU中的关键作用
 如何在SQL中添加列? - 分析VidhyaApr 17, 2025 am 11:43 AM
如何在SQL中添加列? - 分析VidhyaApr 17, 2025 am 11:43 AMSQL的Alter表语句:动态地将列添加到数据库 在数据管理中,SQL的适应性至关重要。 需要即时调整数据库结构吗? Alter表语句是您的解决方案。本指南的详细信息添加了Colu
 业务分析师与数据分析师Apr 17, 2025 am 11:38 AM
业务分析师与数据分析师Apr 17, 2025 am 11:38 AM介绍 想象一个繁华的办公室,两名专业人员在一个关键项目中合作。 业务分析师专注于公司的目标,确定改进领域,并确保与市场趋势保持战略一致。 simu
 什么是Excel中的Count和Counta? - 分析VidhyaApr 17, 2025 am 11:34 AM
什么是Excel中的Count和Counta? - 分析VidhyaApr 17, 2025 am 11:34 AMExcel 数据计数与分析:COUNT 和 COUNTA 函数详解 精确的数据计数和分析在 Excel 中至关重要,尤其是在处理大型数据集时。Excel 提供了多种函数来实现此目的,其中 COUNT 和 COUNTA 函数是用于在不同条件下统计单元格数量的关键工具。虽然这两个函数都用于计数单元格,但它们的设计目标却针对不同的数据类型。让我们深入了解 COUNT 和 COUNTA 函数的具体细节,突出它们独特的特性和区别,并学习如何在数据分析中应用它们。 要点概述 理解 COUNT 和 COU
 Chrome在这里与AI:每天都有新事物!Apr 17, 2025 am 11:29 AM
Chrome在这里与AI:每天都有新事物!Apr 17, 2025 am 11:29 AMGoogle Chrome的AI Revolution:个性化和高效的浏览体验 人工智能(AI)正在迅速改变我们的日常生活,而Google Chrome正在领导网络浏览领域的负责人。 本文探讨了兴奋
 AI的人类方面:福祉和四人底线Apr 17, 2025 am 11:28 AM
AI的人类方面:福祉和四人底线Apr 17, 2025 am 11:28 AM重新构想影响:四倍的底线 长期以来,对话一直以狭义的AI影响来控制,主要集中在利润的最低点上。但是,更全面的方法认识到BU的相互联系
 您应该知道的5个改变游戏规则的量子计算用例Apr 17, 2025 am 11:24 AM
您应该知道的5个改变游戏规则的量子计算用例Apr 17, 2025 am 11:24 AM事情正稳步发展。投资投入量子服务提供商和初创企业表明,行业了解其意义。而且,越来越多的现实用例正在出现以证明其价值超出


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

Dreamweaver Mac版
视觉化网页开发工具

