



概念
Python中已经有了threading模块,为什么还需要线程池呢,线程池又是什么东西呢?
以爬虫为例,需要控制同时爬取的线程数,例子中创建了20个线程,而同时只允许3个线程在运行,但是20个线程都需要创建和销毁,线程的创建是需要消耗系统资源的,有没有更好的方案呢?
其实只需要三个线程就行了,每个线程各分配一个任务,剩下的任务排队等待,当某个线程完成了任务的时候,排队任务就可以安排给这个线程继续执行。
这就是线程池的思想(当然没这么简单),但是自己编写线程池很难写的比较完美,还需要考虑复杂情况下的线程同步,很容易发生死锁。
从Python3.2开始,标准库为我们提供了concurrent.futures模块,它提供了ThreadPoolExecutor和ProcessPoolExecutor两个类,实现了对threading和multiprocessing的进一步抽象(这里主要关注线程池),不仅可以帮我们自动调度线程,还可以做到:
主线程可以获取某一个线程(或者任务的)的状态,以及返回值。
当一个线程完成的时候,主线程能够立即知道。
让多线程和多进程的编码接口一致。
实例
简单使用
from concurrent.futures import ThreadPoolExecutor
import time
# 参数times用来模拟网络请求的时间
def get_html(times):
time.sleep(times)
print("get page {}s finished".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
# 通过submit函数提交执行的函数到线程池中,submit函数立即返回,不阻塞
task1 = executor.submit(get_html, (3))
task2 = executor.submit(get_html, (2))
# done方法用于判定某个任务是否完成
print(task1.done())
# cancel方法用于取消某个任务,该任务没有放入线程池中才能取消成功
print(task2.cancel())
time.sleep(4)
print(task1.done())
# result方法可以获取task的执行结果
print(task1.result())
# 执行结果
# False # 表明task1未执行完成
# False # 表明task2取消失败,因为已经放入了线程池中
# get page 2s finished
# get page 3s finished
# True # 由于在get page 3s finished之后才打印,所以此时task1必然完成了
# 3 # 得到task1的任务返回值ThreadPoolExecutor构造实例的时候,传入max_workers参数来设置线程池中最多能同时运行的线程数目。
使用submit函数来提交线程需要执行的任务(函数名和参数)到线程池中,并返回该任务的句柄(类似于文件、画图),注意submit()不是阻塞的,而是立即返回。
通过submit函数返回的任务句柄,能够使用done()方法判断该任务是否结束。上面的例子可以看出,由于任务有2s的延时,在task1提交后立刻判断,task1还未完成,而在延时4s之后判断,task1就完成了。
使用cancel()方法可以取消提交的任务,如果任务已经在线程池中运行了,就取消不了。这个例子中,线程池的大小设置为2,任务已经在运行了,所以取消失败。如果改变线程池的大小为1,那么先提交的是task1,task2还在排队等候,这是时候就可以成功取消。
使用result()方法可以获取任务的返回值。查看内部代码,发现这个方法是阻塞的。
as_completed
上面虽然提供了判断任务是否结束的方法,但是不能在主线程中一直判断啊。
有时候我们是得知某个任务结束了,就去获取结果,而不是一直判断每个任务有没有结束。
这是就可以使用as_completed方法一次取出所有任务的结果。
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
# 参数times用来模拟网络请求的时间
def get_html(times):
time.sleep(times)
print("get page {}s finished".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
urls = [3, 2, 4] # 并不是真的url
all_task = [executor.submit(get_html, (url)) for url in urls]
for future in as_completed(all_task):
data = future.result()
print("in main: get page {}s success".format(data))
# 执行结果
# get page 2s finished
# in main: get page 2s success
# get page 3s finished
# in main: get page 3s success
# get page 4s finished
# in main: get page 4s successas_completed()方法是一个生成器,在没有任务完成的时候,会阻塞,在有某个任务完成的时候,会yield这个任务,就能执行for循环下面的语句,然后继续阻塞住,循环到所有的任务结束。
从结果也可以看出,先完成的任务会先通知主线程。
map
除了上面的as_completed方法,还可以使用executor.map方法,但是有一点不同。
from concurrent.futures import ThreadPoolExecutor
import time
# 参数times用来模拟网络请求的时间
def get_html(times):
time.sleep(times)
print("get page {}s finished".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
urls = [3, 2, 4] # 并不是真的url
for data in executor.map(get_html, urls):
print("in main: get page {}s success".format(data))
# 执行结果
# get page 2s finished
# get page 3s finished
# in main: get page 3s success
# in main: get page 2s success
# get page 4s finished
# in main: get page 4s success使用map方法,无需提前使用submit方法,map方法与python标准库中的map含义相同,都是将序列中的每个元素都执行同一个函数。
上面的代码就是对urls的每个元素都执行get_html函数,并分配各线程池。可以看到执行结果与上面的as_completed方法的结果不同,输出顺序和urls列表的顺序相同,就算2s的任务先执行完成,也会先打印出3s的任务先完成,再打印2s的任务完成。
wait
wait方法可以让主线程阻塞,直到满足设定的要求。
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED, FIRST_COMPLETED
import time
# 参数times用来模拟网络请求的时间
def get_html(times):
time.sleep(times)
print("get page {}s finished".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
urls = [3, 2, 4] # 并不是真的url
all_task = [executor.submit(get_html, (url)) for url in urls]
wait(all_task, return_when=ALL_COMPLETED)
print("main")
# 执行结果
# get page 2s finished
# get page 3s finished
# get page 4s finished
# mainwait方法接收3个参数,等待的任务序列、超时时间以及等待条件。
等待条件return_when默认为ALL_COMPLETED,表明要等待所有的任务都结束。
可以看到运行结果中,确实是所有任务都完成了,主线程才打印出main。
等待条件还可以设置为FIRST_COMPLETED,表示第一个任务完成就停止等待。
源码分析
cocurrent.future模块中的future的意思是未来对象,可以把它理解为一个在未来完成的操作,这是异步编程的基础 。
在线程池submit()之后,返回的就是这个future对象,返回的时候任务并没有完成,但会在将来完成。
也可以称之为task的返回容器,这个里面会存储task的结果和状态。
那ThreadPoolExecutor内部是如何操作这个对象的呢?
下面简单介绍ThreadPoolExecutor的部分代码:
1.init方法
init方法中主要重要的就是任务队列和线程集合,在其他方法中需要使用到。

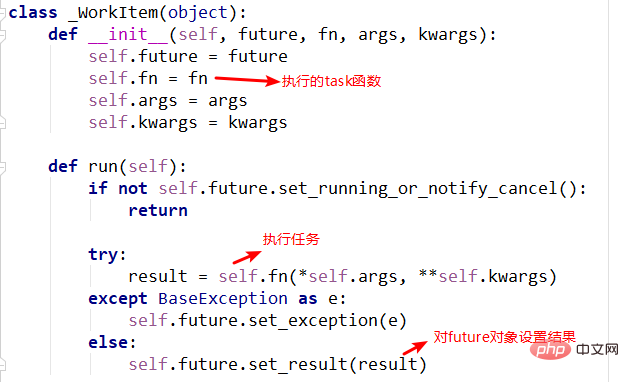
2.submit方法
submit中有两个重要的对象,_base.Future()和_WorkItem()对象,_WorkItem()对象负责运行任务和对future对象进行设置,最后会将future对象返回,可以看到整个过程是立即返回的,没有阻塞。
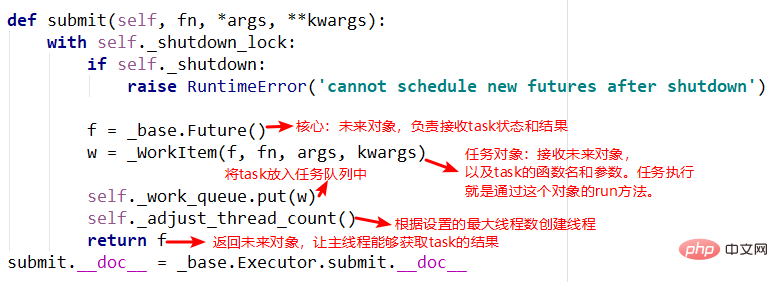
3.adjust_thread_count方法
这个方法的含义很好理解,主要是创建指定的线程数。但是实现上有点难以理解,比如线程执行函数中的weakref.ref,涉及到了弱引用等概念,留待以后理解。
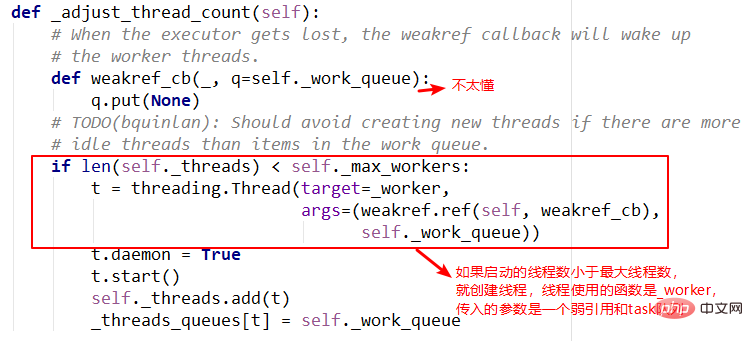
4._WorkItem对象
_WorkItem对象的职责就是执行任务和设置结果。这里面主要复杂的还是self.future.set_result(result)。
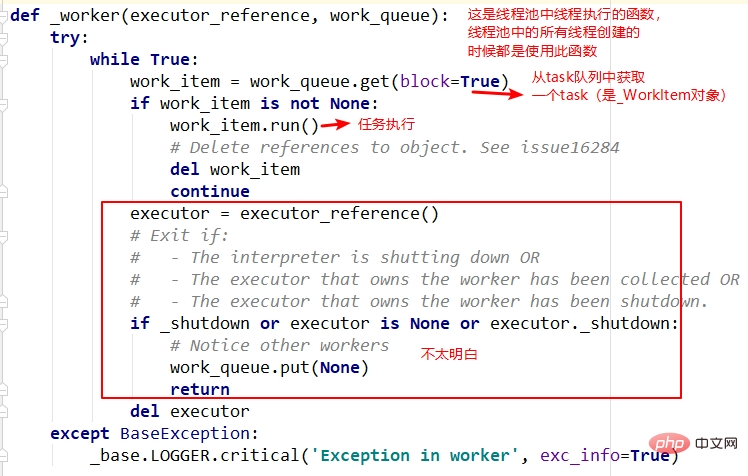
5.线程执行函数--_worker
这是线程池创建线程时指定的函数入口,主要是从队列中依次取出task执行,但是函数的第一个参数还不是很明白。留待以后。
以上是Python之ThreadPoolExecutor线程池问题怎么解决的详细内容。更多信息请关注PHP中文网其他相关文章!

 Python的主要目的:灵活性和易用性Apr 17, 2025 am 12:14 AM
Python的主要目的:灵活性和易用性Apr 17, 2025 am 12:14 AMPython的灵活性体现在多范式支持和动态类型系统,易用性则源于语法简洁和丰富的标准库。1.灵活性:支持面向对象、函数式和过程式编程,动态类型系统提高开发效率。2.易用性:语法接近自然语言,标准库涵盖广泛功能,简化开发过程。
 Python:多功能编程的力量Apr 17, 2025 am 12:09 AM
Python:多功能编程的力量Apr 17, 2025 am 12:09 AMPython因其简洁与强大而备受青睐,适用于从初学者到高级开发者的各种需求。其多功能性体现在:1)易学易用,语法简单;2)丰富的库和框架,如NumPy、Pandas等;3)跨平台支持,可在多种操作系统上运行;4)适合脚本和自动化任务,提升工作效率。
 每天2小时学习Python:实用指南Apr 17, 2025 am 12:05 AM
每天2小时学习Python:实用指南Apr 17, 2025 am 12:05 AM可以,在每天花费两个小时的时间内学会Python。1.制定合理的学习计划,2.选择合适的学习资源,3.通过实践巩固所学知识,这些步骤能帮助你在短时间内掌握Python。
 Python与C:开发人员的利弊Apr 17, 2025 am 12:04 AM
Python与C:开发人员的利弊Apr 17, 2025 am 12:04 AMPython适合快速开发和数据处理,而C 适合高性能和底层控制。1)Python易用,语法简洁,适用于数据科学和Web开发。2)C 性能高,控制精确,常用于游戏和系统编程。
 Python:时间投入和学习步伐Apr 17, 2025 am 12:03 AM
Python:时间投入和学习步伐Apr 17, 2025 am 12:03 AM学习Python所需时间因人而异,主要受之前的编程经验、学习动机、学习资源和方法及学习节奏的影响。设定现实的学习目标并通过实践项目学习效果最佳。
 Python:自动化,脚本和任务管理Apr 16, 2025 am 12:14 AM
Python:自动化,脚本和任务管理Apr 16, 2025 am 12:14 AMPython在自动化、脚本编写和任务管理中表现出色。1)自动化:通过标准库如os、shutil实现文件备份。2)脚本编写:使用psutil库监控系统资源。3)任务管理:利用schedule库调度任务。Python的易用性和丰富库支持使其在这些领域中成为首选工具。
 Python和时间:充分利用您的学习时间Apr 14, 2025 am 12:02 AM
Python和时间:充分利用您的学习时间Apr 14, 2025 am 12:02 AM要在有限的时间内最大化学习Python的效率,可以使用Python的datetime、time和schedule模块。1.datetime模块用于记录和规划学习时间。2.time模块帮助设置学习和休息时间。3.schedule模块自动化安排每周学习任务。
 Python:游戏,Guis等Apr 13, 2025 am 12:14 AM
Python:游戏,Guis等Apr 13, 2025 am 12:14 AMPython在游戏和GUI开发中表现出色。1)游戏开发使用Pygame,提供绘图、音频等功能,适合创建2D游戏。2)GUI开发可选择Tkinter或PyQt,Tkinter简单易用,PyQt功能丰富,适合专业开发。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

SublimeText3 Linux新版
SublimeText3 Linux最新版

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

