



一、安装依赖包
pip install --index https://pypi.mirrors.ustc.edu.cn/simple/ python-office
二、pdf转word
2.1 代码实现
import office office.pdf.pdf2docx(file_path = 'test.pdf')
运行过程如下:
[1/4] Opening document...
[INFO] [2/4] Analyzing document...
[WARNING] 'created' timestamp seems very low; regarding as unix timestamp
[WARNING] 'modified' timestamp seems very low; regarding as unix timestamp
[WARNING] 'created' timestamp seems very low; regarding as unix timestamp
[WARNING] 'modified' timestamp seems very low; regarding as unix timestamp
[INFO] [3/4] Parsing pages...
[INFO] (1/9) Page 1
[INFO] (2/9) Page 2
[INFO] (3/9) Page 3
[INFO] (4/9) Page 4
[INFO] (5/9) Page 5
[INFO] (6/9) Page 6
[INFO] (7/9) Page 7
[INFO] (8/9) Page 8
[INFO] (9/9) Page 9
[INFO] [4/4] Creating pages...
[INFO] (1/9) Page 1
[INFO] (2/9) Page 2
[INFO] (3/9) Page 3
[INFO] (4/9) Page 4
[INFO] (5/9) Page 5
[INFO] (6/9) Page 6
[INFO] (7/9) Page 7
[INFO] (8/9) Page 8
[INFO] (9/9) Page 9
[INFO] Terminated in 1.30s.
Process finished with exit code 0
2.2 pdf内容
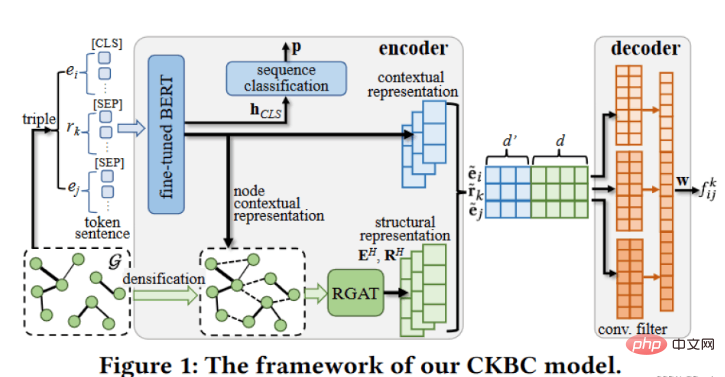
2.3 转换后的word
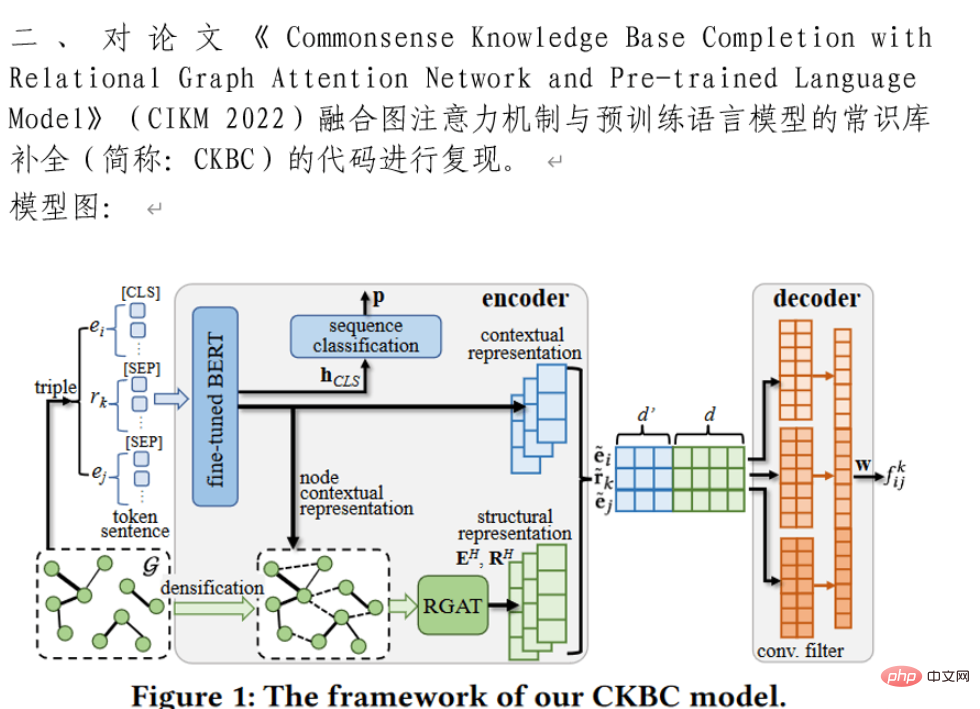
由上可见,效果还不错。
补充
除了上文的办法,小编还为大家整理了更多Python实现的PDF转Word方法,需要的可以参考一下
方法一:
import os
from configparser import ConfigParser
from io import StringIO
from io import open
from concurrent.futures import ProcessPoolExecutor
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import process_pdf
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from docx import Document
def read_from_pdf(file_path):
with open(file_path, 'rb') as file:
resource_manager = PDFResourceManager()
return_str = StringIO()
lap_params = LAParams()
device = TextConverter(
resource_manager, return_str, laparams=lap_params)
process_pdf(resource_manager, device, file)
device.close()
content = return_str.getvalue()
return_str.close()
return content
def save_text_to_word(content, file_path):
doc = Document()
for line in content.split('\n'):
paragraph = doc.add_paragraph()
paragraph.add_run(remove_control_characters(line))
doc.save(file_path)
def remove_control_characters(content):
mpa = dict.fromkeys(range(32))
return content.translate(mpa)
def pdf_to_word(pdf_file_path, word_file_path):
content = read_from_pdf(pdf_file_path)
save_text_to_word(content, word_file_path)
def main():
config_parser = ConfigParser()
config_parser.read('config.cfg')
config = config_parser['default']
tasks = []
with ProcessPoolExecutor(max_workers=int(config['max_worker'])) as executor:
for file in os.listdir(config['pdf_folder']):
extension_name = os.path.splitext(file)[1]
if extension_name != '.pdf':
continue
file_name = os.path.splitext(file)[0]
pdf_file = config['pdf_folder'] + '/' + file
word_file = config['word_folder'] + '/' + file_name + '.docx'
print('正在处理: ', file)
result = executor.submit(pdf_to_word, pdf_file, word_file)
tasks.append(result)
while True:
exit_flag = True
for task in tasks:
if not task.done():
exit_flag = False
if exit_flag:
print('完成')
exit(0)
if __name__ == '__main__':
main()方法二:
加密过的PDF转word
#-*- coding: UTF-8 -*-
#!/usr/bin/python
#-*- coding: utf-8 -*-
import sys
import importlib
importlib.reload(sys)
from pdfminer.pdfparser import PDFParser,PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import *
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
import os
#设置工作目录文件夹
os.chdir(r'c:/users/dicey/desktop/codes/pdf-docx')
#解析pdf文件函数
def parse(pdf_path):
fp = open('diya.pdf', 'rb') # 以二进制读模式打开
# 用文件对象来创建一个pdf文档分析器
parser = PDFParser(fp)
# 创建一个PDF文档
doc = PDFDocument()
# 连接分析器 与文档对象
parser.set_document(doc)
doc.set_parser(parser)
# 提供初始化密码
# 如果没有密码 就创建一个空的字符串
doc.initialize()
# 检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# 创建PDf 资源管理器 来管理共享资源
rsrcmgr = PDFResourceManager()
# 创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
# 用来计数页面,图片,曲线,figure,水平文本框等对象的数量
num_page, num_image, num_curve, num_figure, num_TextBoxHorizontal = 0, 0, 0, 0, 0
# 循环遍历列表,每次处理一个page的内容
for page in doc.get_pages(): # doc.get_pages() 获取page列表
num_page += 1 # 页面增一
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
for x in layout:
if isinstance(x,LTImage): # 图片对象
num_image += 1
if isinstance(x,LTCurve): # 曲线对象
num_curve += 1
if isinstance(x,LTFigure): # figure对象
num_figure += 1
if isinstance(x, LTTextBoxHorizontal): # 获取文本内容
num_TextBoxHorizontal += 1 # 水平文本框对象增一
# 保存文本内容
with open(r'test2.doc', 'a',encoding='utf-8') as f: #生成doc文件的文件名及路径
results = x.get_text()
f.write(results)
f.write('\n')
print('对象数量:\n','页面数:%s\n'%num_page,'图片数:%s\n'%num_image,'曲线数:%s\n'%num_curve,'水平文本框:%s\n'
%num_TextBoxHorizontal)
if __name__ == '__main__':
pdf_path = r'diya.pdf' #pdf文件路径及文件名
parse(pdf_path)以上是怎么用两行Python代码实现pdf转word功能的详细内容。更多信息请关注PHP中文网其他相关文章!

 您如何将元素附加到Python数组?Apr 30, 2025 am 12:19 AM
您如何将元素附加到Python数组?Apr 30, 2025 am 12:19 AMInpython,YouAppendElementStoAlistusingTheAppend()方法。1)useappend()forsingleelements:my_list.append(4).2)useextend()orextend()或= formultiplelements:my_list.extend.extend(emote_list)ormy_list = [4,5,6] .3)useInsert()forspefificpositions:my_list.insert(1,5).beaware
 您如何调试与Shebang有关的问题?Apr 30, 2025 am 12:17 AM
您如何调试与Shebang有关的问题?Apr 30, 2025 am 12:17 AM调试shebang问题的方法包括:1.检查shebang行确保是脚本首行且无前置空格;2.验证解释器路径是否正确;3.直接调用解释器运行脚本以隔离shebang问题;4.使用strace或truss跟踪系统调用;5.检查环境变量对shebang的影响。
 如何从python数组中删除元素?Apr 30, 2025 am 12:16 AM
如何从python数组中删除元素?Apr 30, 2025 am 12:16 AMpythonlistscanbemanipulationusesseveralmethodstoremovelements:1)theremove()MethodRemovestHefirStocCurrenceOfAstePecifiedValue.2)thepop()thepop()methodremovesandremovesandurturnturnsananelementatagivenIndex.3)

 在Python列表上可以执行哪些常见操作?Apr 30, 2025 am 12:01 AM
在Python列表上可以执行哪些常见操作?Apr 30, 2025 am 12:01 AMpythristssupportnumereperations:1)addingElementSwithAppend(),Extend(),andInsert()。2)emovingItemSusingRemove(),pop(),andclear(),and clear()。3)访问andmodifyingandmodifyingwithIndexingAndexingAndSlicing.4)
 如何使用numpy创建多维数组?Apr 29, 2025 am 12:27 AM
如何使用numpy创建多维数组?Apr 29, 2025 am 12:27 AM使用NumPy创建多维数组可以通过以下步骤实现:1)使用numpy.array()函数创建数组,例如np.array([[1,2,3],[4,5,6]])创建2D数组;2)使用np.zeros(),np.ones(),np.random.random()等函数创建特定值填充的数组;3)理解数组的shape和size属性,确保子数组长度一致,避免错误;4)使用np.reshape()函数改变数组形状;5)注意内存使用,确保代码清晰高效。
 说明Numpy阵列中'广播”的概念。Apr 29, 2025 am 12:23 AM
说明Numpy阵列中'广播”的概念。Apr 29, 2025 am 12:23 AM播放innumpyisamethodtoperformoperationsonArraySofDifferentsHapesbyAutapityallate AligningThem.itSimplifififiesCode,增强可读性,和Boostsperformance.Shere'shore'showitworks:1)较小的ArraySaraySaraysAraySaraySaraySaraySarePaddedDedWiteWithOnestOmatchDimentions.2)
 说明如何在列表,Array.Array和用于数据存储的Numpy数组之间进行选择。Apr 29, 2025 am 12:20 AM
说明如何在列表,Array.Array和用于数据存储的Numpy数组之间进行选择。Apr 29, 2025 am 12:20 AMforpythondataTastorage,choselistsforflexibilityWithMixedDatatypes,array.ArrayFormeMory-effficityHomogeneousnumericalData,andnumpyArraysForAdvancedNumericalComputing.listsareversareversareversareversArversatilebutlessEbutlesseftlesseftlesseftlessforefforefforefforefforefforefforefforefforefforlargenumerdataSets; arrayoffray.array.array.array.array.array.ersersamiddreddregro


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

Atom编辑器mac版下载
最流行的的开源编辑器

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

禅工作室 13.0.1
功能强大的PHP集成开发环境

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

