



基于 pywinauto 的自动化采集任务
实现技术
这个程序使用了一个 Python 的自动化库 ---- pywinauto, 因为官方已经很久没更新了, 所以 python 的版本最高只能是 Python 3.7 左右, 我用的是 Python 3.7.1. 我使用它模拟了输入单词, 复制例句, 获取例句, 清空剪切板, 然后重复这个操作, 总体上实现比较简陋. 而且, 为了简单, 我是之间手动切换到例句页, 这样就不用使用程序来切换到例句页了.
代码
requirements.txt
pyperclip==1.8.2 pywin32==304 pywinauto==0.6.8
代码
import os
import random
import time
import re
from typing import Dict, List
from pywinauto.application import Application
from pywinauto import mouse
from pywinauto import keyboard
import pyperclip
import json
# 程序处理中的各种路径
dir_path = r"C:/Users/Dick/Desktop/work/DragonEnglish/tools"
input_path = os.path.join(dir_path, r"input.txt")
output_path = os.path.join(dir_path, r"output.json")
error_path = os.path.join(dir_path, r"error.txt")
# 顺序错误的单词
error_words = []
# 有道词典的进程id
processId = 13840
def line_process(content: str) -> str:
"""
去除所有空行, 再去除前面四行无关内容
"""
lines = content.split("\r\n")
# 因为例句开头是 数字. 开头的, 所以先以这个为特点来进行过滤掉多复制的开头
count = 0
for i in range(len(lines)):
if re.match(r"\d+\.", lines[i]):
count = i
break
lines = lines[count:]
filter_lines = []
for line in lines:
if line.strip() != "": # 过滤空行
if not line.startswith("youdao") and not \
(line.startswith("《") and line.endswith("》")): # 过滤来源
filter_lines.append(line)
if len(filter_lines) % 3 != 0:
raise Exception("抓取数据错误")
content = "\n".join(filter_lines) + "\n" # 补上一个 \n, 不然正则会漏掉一个结果
return content
def to_list(line: str) -> List[Dict[str, str]]:
"""
直接生成列表字典对象
[{
"no": 1,
"original": "",
"translate"
}]
"""
sentences = []
# 正则表达式
REGEXP = r'(?P<no>\d+?)\.\n(?P<original>.+?)\n(?P<translate>.+?)\n'
# 编译
pattern = re.compile(REGEXP)
# 匹配
rs = pattern.finditer(line)
# 组装结果
for r in rs:
print(r.groupdict())
sentences.append(r.groupdict())
return sentences
if __name__ == "__main__":
# 连接网易有道词典
app = Application(backend="uia").connect(process=processId)
# 获取需要的窗口
win = app.window(class_name="RICHEDIT50W")
# 输入词汇列表
input_words = []
# 输出词汇对象列表
output_words = []
# 打开输入文件,初始化输入词汇列表
with open(input_path, "r", encoding="utf-8") as input_file:
input_words = input_file.read().split("\n")
for word in input_words:
print("正在抓取单词: %s" % word)
# 清空剪切板,这步很重要,防止重复复制
pyperclip.copy("")
# 将输入数据复制到剪切板
pyperclip.copy(word)
# 定位到输入框(采用坐标定位,定位到大致位置即可)
mouse.click(coords=(2400, 80))
# 模拟按键操作:全选 删除 粘贴 回车(触发查询)
keyboard.send_keys("^a{DELETE}^v{ENTER}")
# 清空剪切板,这步很重要,防止重复复制
pyperclip.copy("")
# 鼠标左键点击,这个操作只是为了把鼠标移动到这里
mouse.click(button="left", coords=(2200, 330))
# 模拟键盘 CTRL+A CTRL+C,直接全选所有的例句(这里会多选一部分内容,待会再处理)
keyboard.send_keys("^a^c")
# 暂停一会儿,不做操作的太快
time.sleep(random.random() * 2 + 1)
# pywinauto 复制的内容是在系统的剪切板里面的,所以需要其它库读取
content = pyperclip.paste()
# 对内容进行简单的预处理后,加入output_words
try:
lines = line_process(content)
except BaseException as exp:
print(exp)
# 如果抓取出现问题,说明被网易抓了现行,直接退出即可。
break
sentences = to_list(lines)
if not sentences:
print("获取例句为空, 可能是数据格式错误.")
break
output_words.append({
"word": word,
"example": sentences,
})
# 模拟暂停一个较长的随机时间,没有必要追求速度,平稳运行即可。
time.sleep(random.random() * 3 + 3)
# 清空剪切板,这步很重要,防止重复复制
pyperclip.copy("")
# 抓取完毕一个文件的内容后,然后一次性写入即可。
# 之前的写法是一个单词写入一次,会造成太多的IO次数,浪费性能!
with open(output_path, "a+", encoding="utf-8") as output_file:
output_file.write(json.dumps(
output_words, ensure_ascii=False, indent=4))
# 错误单词记录
with open(error_path, "w", encoding="utf-8") as err_file:
err_file.writelines("\n".join(error_words))演示 如果想要启动这个代码, 还是蛮复杂的. 我这里直接把需要的步骤罗列一下, 希望能帮助感兴趣的同学.
修改dir_path, 并且在下面准备一个 input.txt 文件.
获取有道词典进程的 id.
获取单词输入框的坐标, 获取复制粘贴处的坐标.
将有道词典界面调整到例句处.
启动项目, 需要一个 input.txt 文件, 这里是我测试的文件.
sophisticated
centralization
phenomenon
internationalization
radioactive
我是通过任务管理器获取的进程 pid, 你也可以通过其它访问. 或者最简单的是使用 Inspect 和 Spy++, 我这里就偷懒了, 直接怎么省事怎么来了.
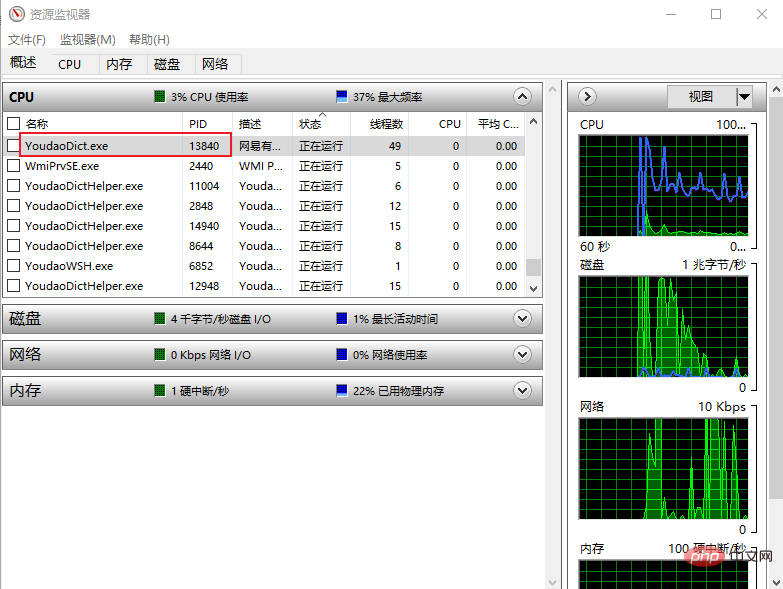
单词输入框的坐标, 复制粘贴处的坐标. 第一个坐标是为了定位输入框的, 然后程序会把单词复制进去, 并执行一下回车键, 然后内容被查询出来. 再将鼠标移动到第二个坐标处, 这里只是移动到下面的空白处就行了, 然后会执行一个全选 CTRL+A 操作. 这样一个单词的内容就全部获取到了.
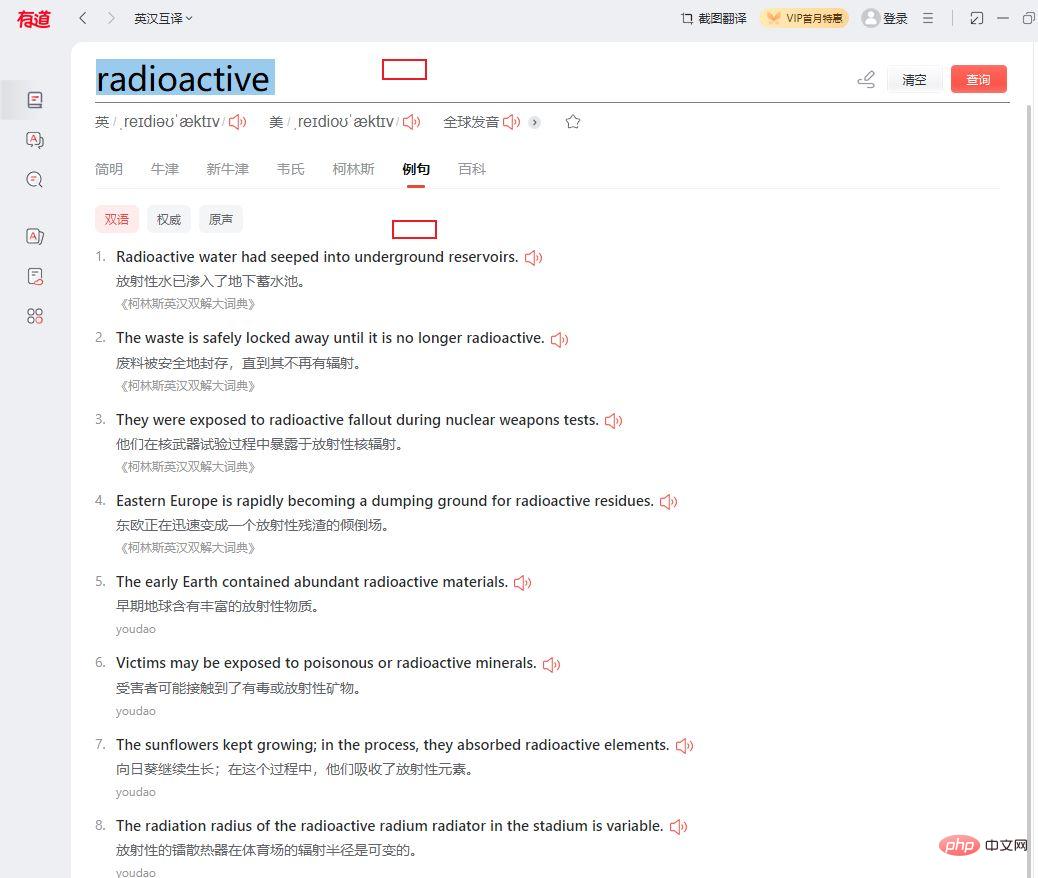
将有道调整到这个位置, 首选查询一个单词, 选择例句, 然后保持这个界面不要动即可.
最后就是程序的执行了, 录制的 GIF 做了加速处理, 实际上执行的时候, 是特意加了延时的, 防止被过早的发现了.
控制台输出
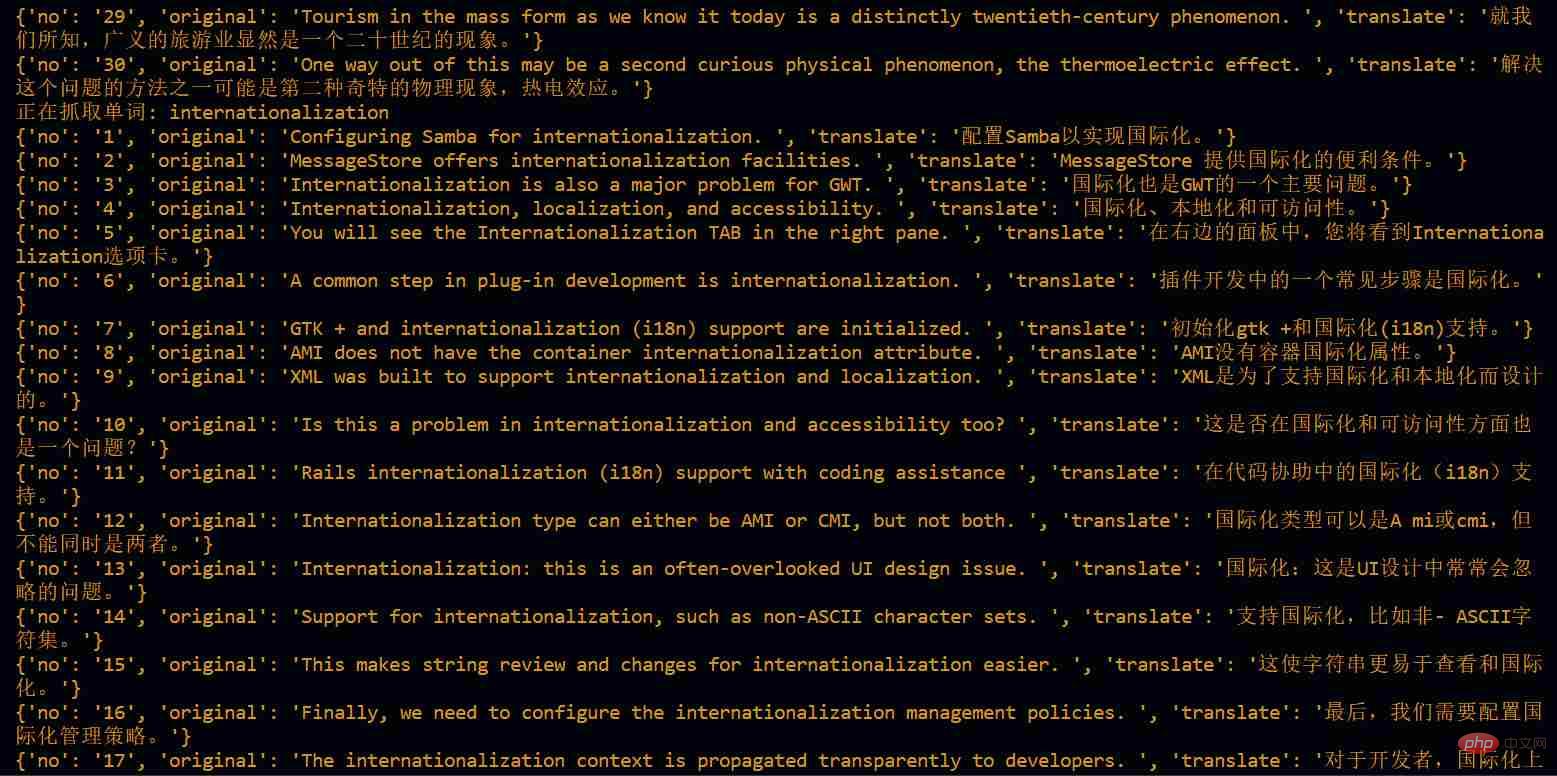
output.json 文件
以上是使用Python和pywinauto实现自动化采集任务的步骤和方法的详细内容。更多信息请关注PHP中文网其他相关文章!

 Python vs. C:了解关键差异Apr 21, 2025 am 12:18 AM
Python vs. C:了解关键差异Apr 21, 2025 am 12:18 AMPython和C 各有优势,选择应基于项目需求。1)Python适合快速开发和数据处理,因其简洁语法和动态类型。2)C 适用于高性能和系统编程,因其静态类型和手动内存管理。
 Python vs.C:您的项目选择哪种语言?Apr 21, 2025 am 12:17 AM
Python vs.C:您的项目选择哪种语言?Apr 21, 2025 am 12:17 AM选择Python还是C 取决于项目需求:1)如果需要快速开发、数据处理和原型设计,选择Python;2)如果需要高性能、低延迟和接近硬件的控制,选择C 。
 达到python目标:每天2小时的力量Apr 20, 2025 am 12:21 AM
达到python目标:每天2小时的力量Apr 20, 2025 am 12:21 AM通过每天投入2小时的Python学习,可以有效提升编程技能。1.学习新知识:阅读文档或观看教程。2.实践:编写代码和完成练习。3.复习:巩固所学内容。4.项目实践:应用所学于实际项目中。这样的结构化学习计划能帮助你系统掌握Python并实现职业目标。
 最大化2小时:有效的Python学习策略Apr 20, 2025 am 12:20 AM
最大化2小时:有效的Python学习策略Apr 20, 2025 am 12:20 AM在两小时内高效学习Python的方法包括:1.回顾基础知识,确保熟悉Python的安装和基本语法;2.理解Python的核心概念,如变量、列表、函数等;3.通过使用示例掌握基本和高级用法;4.学习常见错误与调试技巧;5.应用性能优化与最佳实践,如使用列表推导式和遵循PEP8风格指南。
 在Python和C之间进行选择:适合您的语言Apr 20, 2025 am 12:20 AM
在Python和C之间进行选择:适合您的语言Apr 20, 2025 am 12:20 AMPython适合初学者和数据科学,C 适用于系统编程和游戏开发。1.Python简洁易用,适用于数据科学和Web开发。2.C 提供高性能和控制力,适用于游戏开发和系统编程。选择应基于项目需求和个人兴趣。
 Python与C:编程语言的比较分析Apr 20, 2025 am 12:14 AM
Python与C:编程语言的比较分析Apr 20, 2025 am 12:14 AMPython更适合数据科学和快速开发,C 更适合高性能和系统编程。1.Python语法简洁,易于学习,适用于数据处理和科学计算。2.C 语法复杂,但性能优越,常用于游戏开发和系统编程。
 每天2小时:Python学习的潜力Apr 20, 2025 am 12:14 AM
每天2小时:Python学习的潜力Apr 20, 2025 am 12:14 AM每天投入两小时学习Python是可行的。1.学习新知识:用一小时学习新概念,如列表和字典。2.实践和练习:用一小时进行编程练习,如编写小程序。通过合理规划和坚持不懈,你可以在短时间内掌握Python的核心概念。
 Python与C:学习曲线和易用性Apr 19, 2025 am 12:20 AM
Python与C:学习曲线和易用性Apr 19, 2025 am 12:20 AMPython更易学且易用,C 则更强大但复杂。1.Python语法简洁,适合初学者,动态类型和自动内存管理使其易用,但可能导致运行时错误。2.C 提供低级控制和高级特性,适合高性能应用,但学习门槛高,需手动管理内存和类型安全。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

Dreamweaver CS6
视觉化网页开发工具

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

SublimeText3汉化版
中文版,非常好用

