


以下为卢志武教授在机器之心举办的 ChatGPT 及大模型技术大会上的演讲内容,机器之心进行了不改变原意的编辑、整理:

大家好,我是中国人民大学卢志武。我今天报告的题目是《ChatGPT 对多模态通用生成模型的重要启发》,包含四部分内容。

首先,ChatGPT 带给我们一些关于研究范式革新的启发。第一点就是要使用「大模型 + 大数据」,这是一个已经被再三被验证过的研究范式,也是 ChatGPT 的基础研究范式。特别要强调一点,大模型大到一定程度的时候才会有涌现(emergent)能力,比如 In-context learning、CoT 推理等能力,这些能力令人感到非常惊艳。
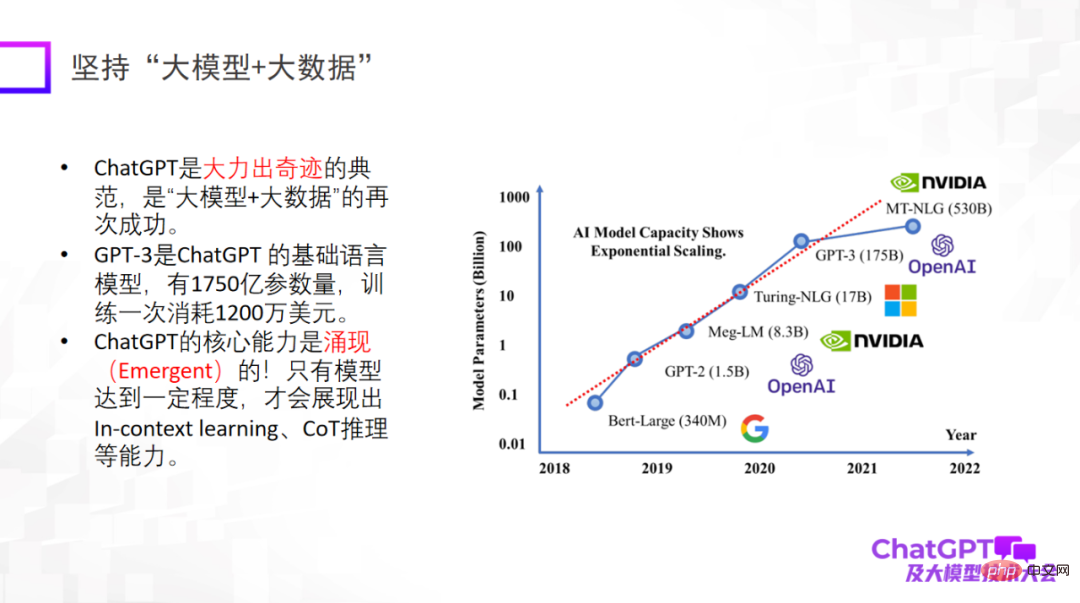
第二点是要坚持「大模型 + 推理」,这也是 ChatGPT 让我印象最深刻的一点。因为在机器学习或者人工智能领域,推理被公认为是最难的,而 ChatGPT 在这一点上也有所突破。当然,ChatGPT 的推理能力可能主要来自代码训练,但是否有必然的联系还不能确定。在推理方面,我们应该下更多的工夫,搞清楚它到底来自什么,或者还有没有别的训练方式把它的推理能力进一步增强。
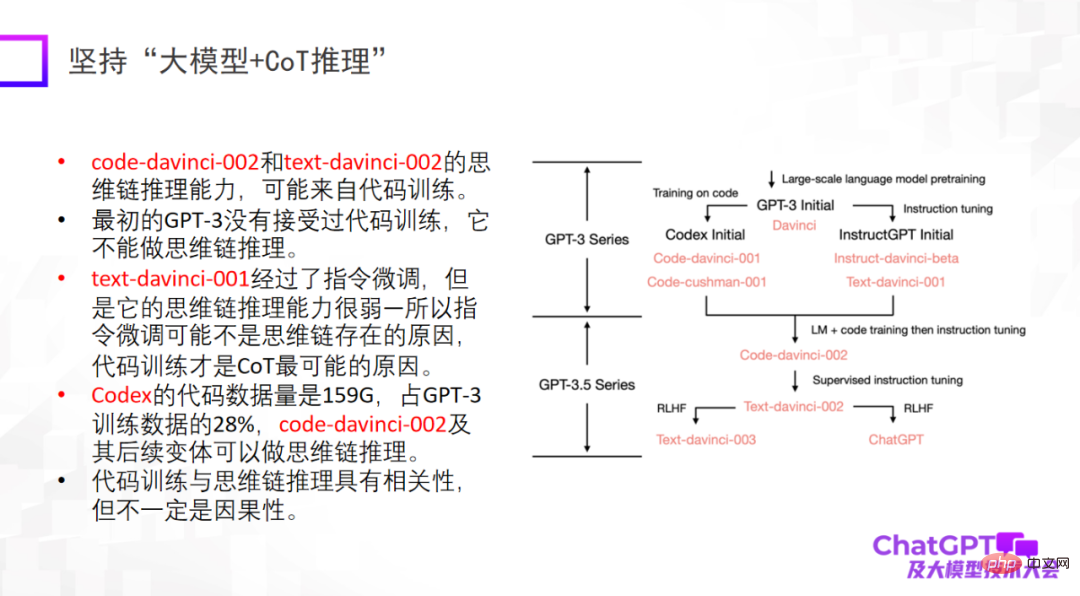
第三点是大模型一定要和人类对齐(alignment),这是 ChatGPT 在工程角度或模型落地角度给我们的重要启示。如果没有与人类对齐的话,模型会生成很多有害的信息,让模型无法使用。第三点不是说提高模型的上限,而是模型的可靠性和安全性的确非常重要。
ChatGPT 的问世对很多领域,包括我自己,都有非常大的触动。因为我自己做多模态做了好几年,我会开始反思为什么我们没有做出这么厉害的模型。
ChatGPT 是在语言或者文字上的通用生成,下面我们来了解一下多模态通用生成领域的最新进展。多模态预训练模型已开始向多模态通用生成模型转变,并有了一些初步的探索。首先我们看一下谷歌 2019 年提出的 Flamingo 模型,下图是它的模型结构。
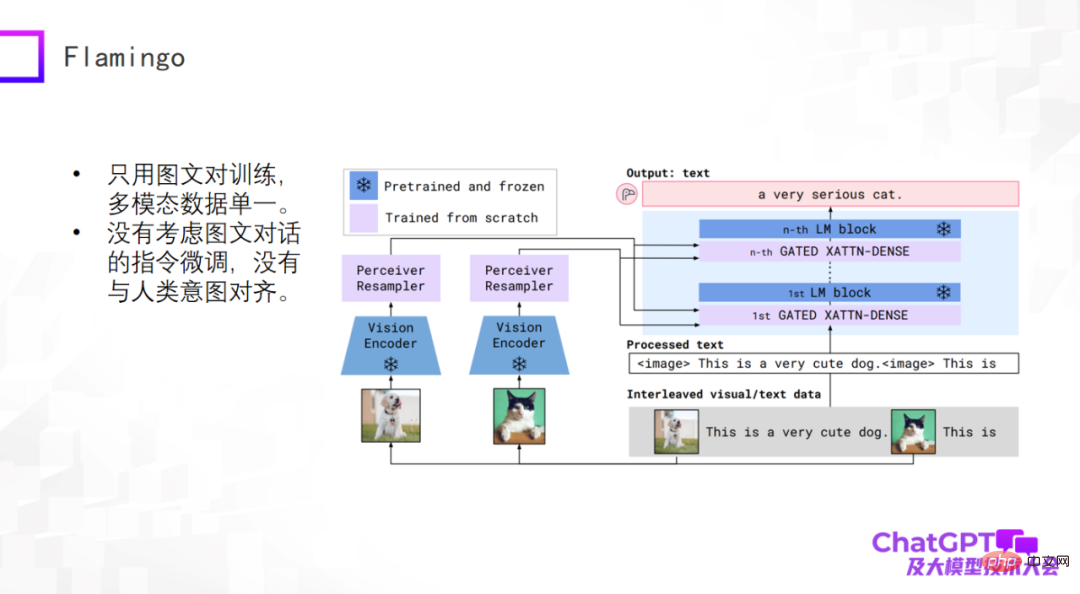
Flamingo 模型架构的主体是大型语言模型的解码器(Decoder),即上图右侧蓝色模块,在每个蓝色模块之间加了一些 adapter 层,左侧视觉的部分是添加了视觉编码器(Vision Encoder)和感知器重采样器(Perceiver Resampler)。整个模型的设计就是要把视觉的东西通过编码和转换,经过 adapter,跟语言对齐,这样模型就可以为图像自动生成文本描述。
Flamingo 这样的架构设计有什么好处呢?首先,上图中的蓝色模块是固定不动的(frozen),其中包括语言模型 Decoder;而粉色模块本身的参数量是可以控制的,所以 Flamingo 模型实际上训练的参数量是很少的。所以大家不要觉得多模态通用生成模型很难做,其实没有那么悲观。经过训练的 Flamingo 模型就可以做很多基于文本生成的通用任务,当然输入还是多模态的,比如做视频描述、视觉问答、多模态对话等。从这个角度看 Flamingo 算是一个通用生成模型。
第二个例子是前段时间新发布的 BLIP-2 模型,它是基于 BLIP-1 改进的,它的模型架构和 Flamingo 特别像,基本还是包含图像编码器和大型语言模型的解码器,这两部分是固定不动的, 然后中间加了一个具有转换器作用的 Q-Former—— 从视觉转换到语言。那么,BLIP-2 真正需要训练的部分就是 Q-Former。
如下图所示,首先将一张图(右边的图)输入到 Image Encoder,中间的 Text 是用户提出的问题或者指令,经过 Q-Former 编码以后输入到大型语言模型里,最后把答案生成出来,大概是这样一个生成过程。
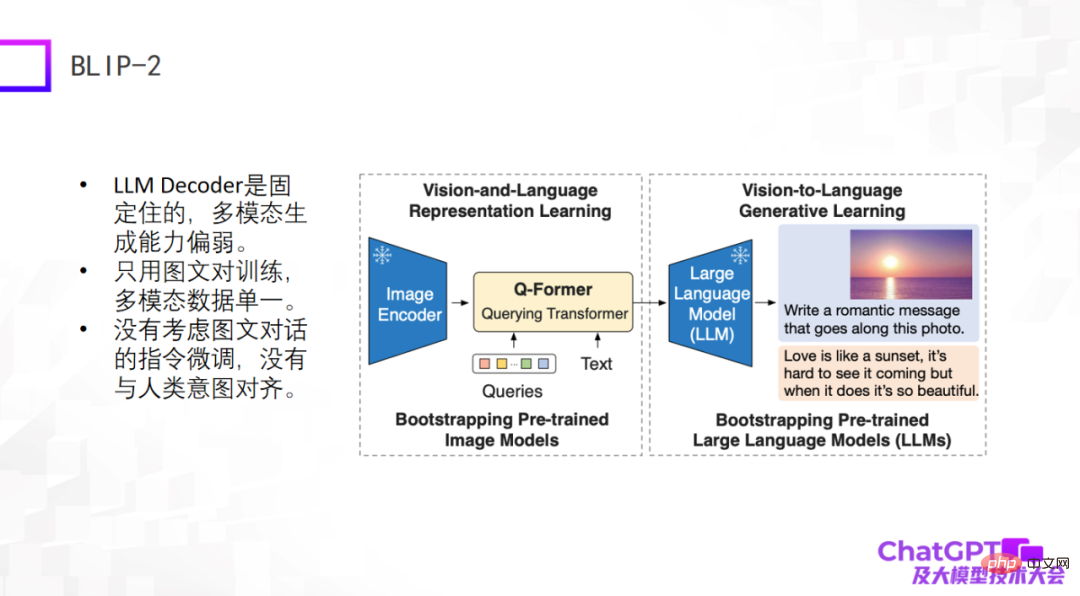
这两种模型的缺点很明显,因为它们出现的比较早或者刚出现,还没有考虑 ChatGPT 用到的工程手段,至少在图文对话或者多模态对话上没有做指令微调,所以它们整体的生成效果不尽如人意。
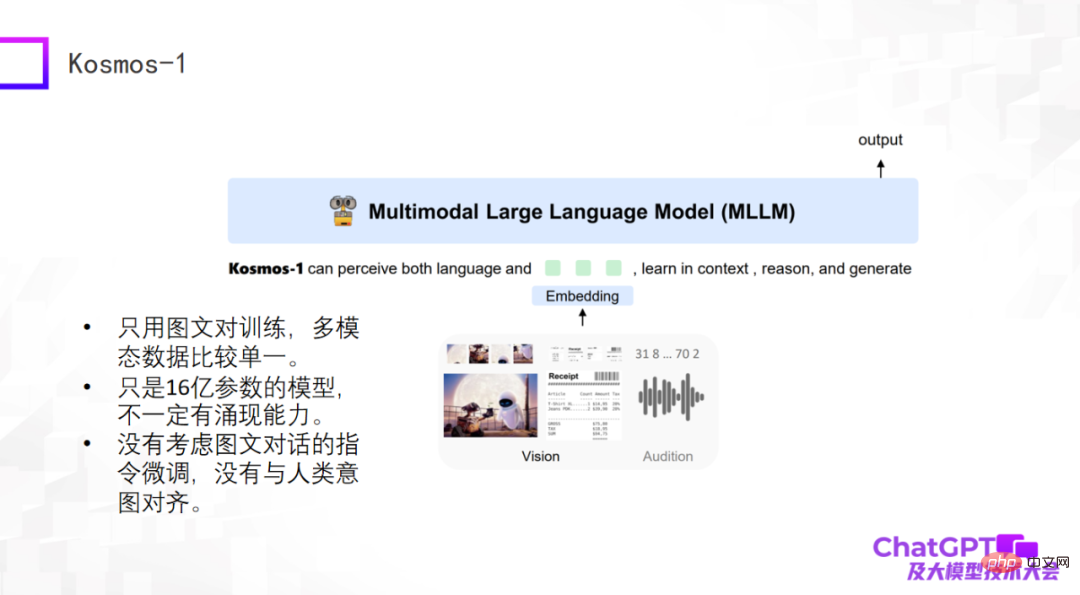
第三个是微软最近发布的 Kosmos-1,它的结构特别简单,并且只用图文对进行训练,多模态数据比较单一。Kosmos-1 跟上面两个模型最大的差别是:上面两个模型中的大语言模型本身是固定不动的,而 Kosmos-1 中的大型语言模型本身是要经过训练的,因此 Kosmos-1 模型的参数量只有 16 亿,而 16 亿参数的模型未必有涌现能力。当然,Kosmos-1 也没考虑图文对话上的指令微调,导致它有时也会胡说八道。
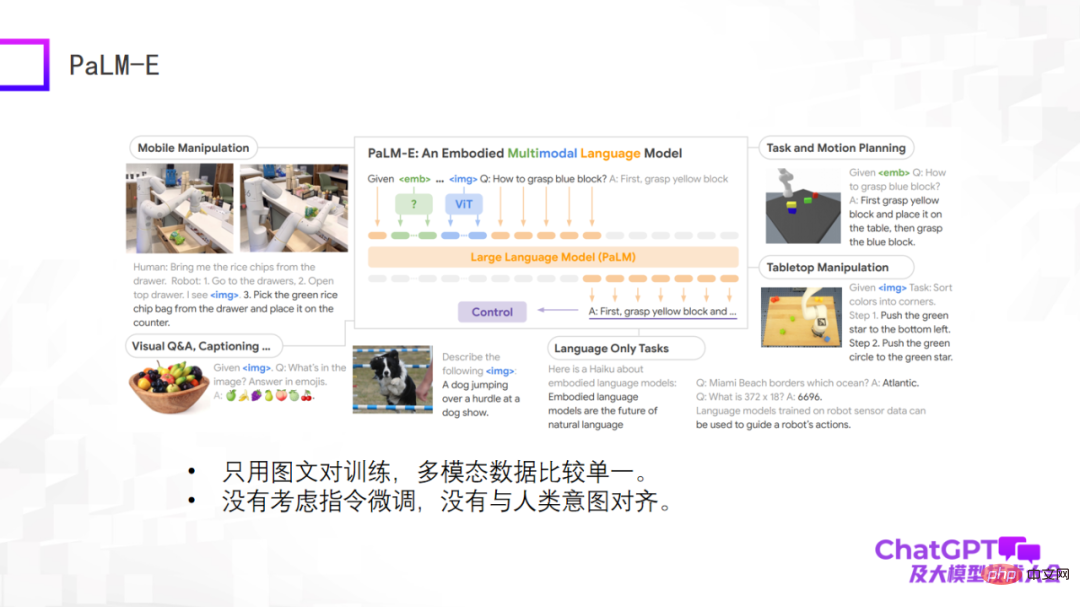
下一个例子是谷歌的多模态具身视觉语言模型 PaLM-E。PaLM-E 模型和前三个例子是大同小异的,PaLM-E 也用了 ViT + 大型语言模型。PaLM-E 最大的突破是它终于在机器人领域探索了一下多模态大语言模型的落地可能性。PaLM-E 尝试了第一步探索,但是它考虑的机器人任务类型很有限,并不能达到真正的通用。
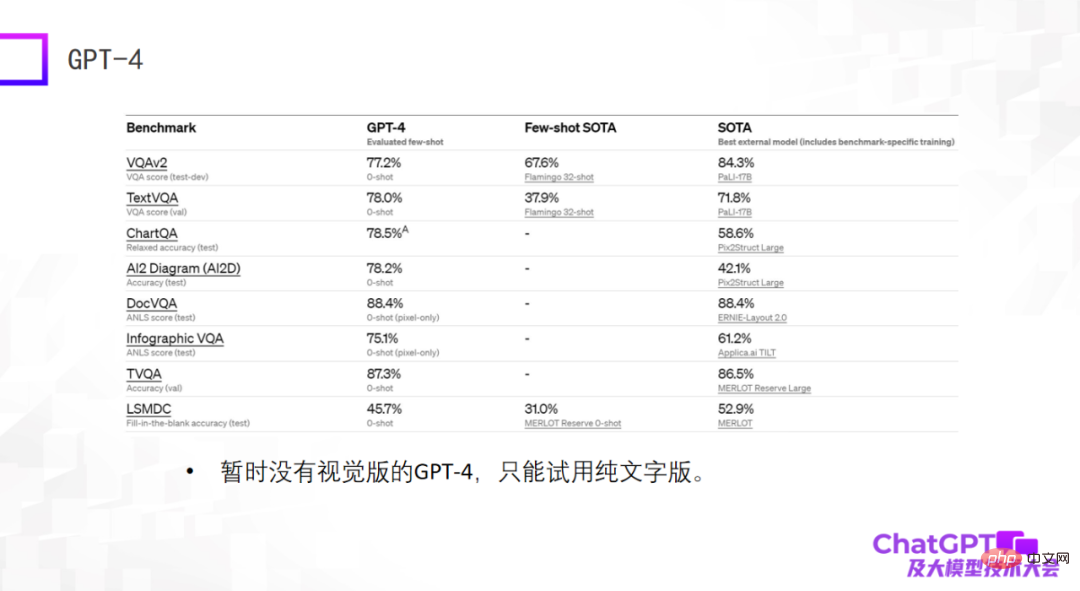
最后一个例子是 GPT-4—— 在标准数据集上给出了特别惊人的结果,很多时候它的结果甚至比目前在数据集上训练微调过的 SOTA 模型还要好。这可能会让人特别震惊,但实际上这个评测结果并不代表什么。我们在两年前做多模态大模型时就发现大模型的能力不能在标准数据集上评估,在标准数据集上表现好并不代表实际使用的时候效果好,这两个之间有很大的 gap。出于这个原因,我对目前的 GPT-4 有些许失望,因为它只给出了标准数据集上的结果。而且目前可用的 GPT-4 还不是视觉版的,只是纯文字版的。
上面几个模型总体来说是做通用的语言生成,输入是多模态输入,下面这两个模型就不一样了 —— 不仅要做通用语言生成,还要做视觉生成,既能生成语言也能生成图像。
首先是微软的 Visual ChatGPT,我简单评价一下。这个模型的思路特别简单,更多是产品设计上的考虑。与视觉有关的生成有很多种,还有一些视觉检测模型,这些不同任务的输入、指令千差万别,问题就是怎么用一个模型把这些任务全部包含进来,所以微软设计了 Prompt 管理器,核心部分用到了 OpenAI 的 ChatGPT,相当于把不同视觉生成任务的指令,通过 ChatGPT 翻译过来。用户的问题是自然语言描述的指令,通过 ChatGPT 把它翻译成机器能懂的指令。
Visual ChatGPT 就是做了这样一个事情。所以从产品的角度看确实很好,但从模型设计的角度看却没有新的东西。所以整体从模型的层面看是一个「缝合怪」,没有统一的模型训练,导致不同模态之间没有互相促进。我们为什么做多模态,因为我们相信不同模态数据之间一定是互相帮助的。并且 Visual ChatGPT 也没考虑多模态生成指令微调,它的指令微调只是依赖于 ChatGPT 本身。
下一个例子是清华朱军老师的团队发布的 UniDiffuser 模型。这个模型从学术角度真正做到了多模态输入生成文字、生成视觉内容,这得益于他们基于 transformer 的网络架构 U-ViT,类似于 Stable Diffusion 最核心的部件 U-Net,进而把图像的生成和文本的生成统一在一个框架里。这个工作本身是很有意义的,但还是比较初期,比如只考虑了 Captioning 和 VQA 任务,没有考虑多轮对话,也没有做多模态生成上的指令微调。
前面评价了这么多,那我们自己也做了一个产品叫 ChatImg,如下图所示。总体来说,ChatImg 包含图像编码器、图文多模态编码器和文本解码器,和 Flamingo、BLIP-2 是类似的,但是我们考虑的更多,具体实现的时候有细节差异。
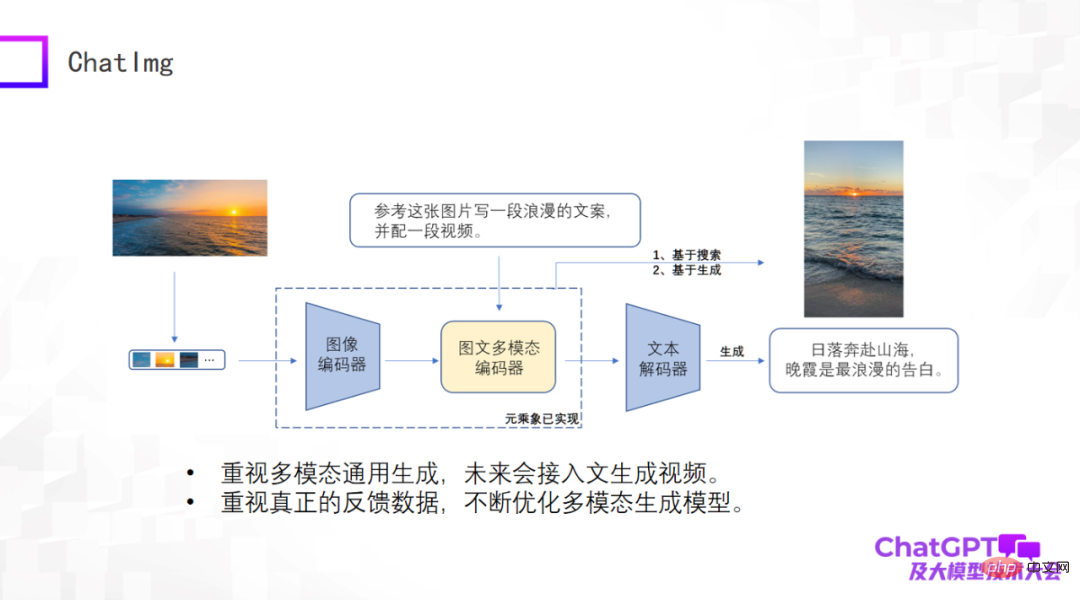
ChatImg 最大的一个优势是可以接受视频输入。我们特别重视多模态通用生成,包括生成文字、生成图像、生成视频。我们希望在这一个框架里实现多种生成任务,最终希望接入文字生成视频。
第二,我们特别重视真实用户的数据,我们希望得到真实用户数据以后不停优化生成模型本身,提高它的能力,所以我们发布了 ChatImg 应用。
下图是我们测试的一些例子,作为一个初期模型,虽然还有一些做得不好的地方,但总体来说 ChatImg 对图片的理解还是可以的。比如,ChatImg 可以在对话中生成对画作的描述,也能做一些 In-context learning。
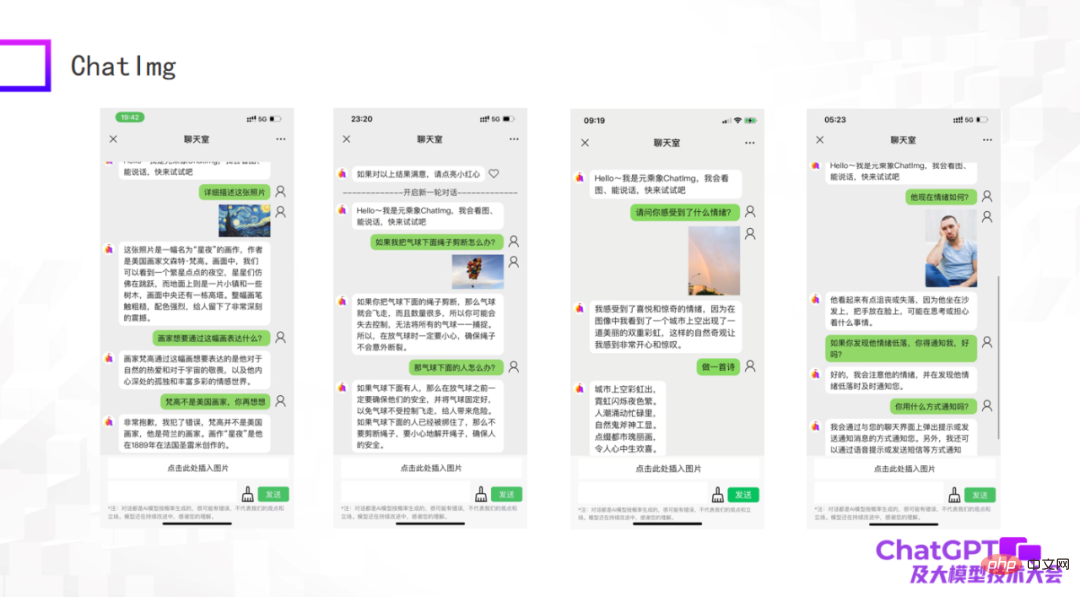
上图第一个例子描述了《星夜》这幅画,在描述中 ChatImg 称梵高是美国画家,你告诉它错了,它马上就可以纠正过来;第二个例子 ChatImg 对图中的物体做出了物理推断;第三个例子是我自己拍的一张照片,这个照片里面有两道彩虹,它准确地识别到了。
我们注意到上图第三和第四个例子涉及到情绪方面的问题。这其实与我们接下来要做的工作有关,我们想把 ChatImg 接入到机器人里面去。现在的机器人通常是被动的,所有的指令全部是预设的,显得很呆板。我们希望接入 ChatImg 的机器人可以主动和人交流。怎么做到这一点呢?首先机器人一定要能感受到人,可能是客观地看到世界的状态和人的情绪,也可能是获得一种反映;然后机器人才能理解,才能跟人主动交流。通过这两个例子我感觉这个目标是可以实现的。
最后,我总结一下今天的报告。首先,ChatGPT 和 GPT-4 带来了研究范式的革新,我们所有人都应该去积极拥抱这个变化,不能抱怨,不能找借口说没有资源,只要去面对这个变化,总有办法克服困难。多模态研究甚至也不需要几百卡的机器,只要采用对应的策略,少量的机器也可以做出很好的工作。第二,现有的多模态生成模型都存在各自的问题,GPT-4 还没有开放视觉版,我们所有人也都还有机会。并且,我认为 GPT-4 还有一个问题,就是多模态生成模型最终应该是什么样子它没有给一个完美答案(实际上是没有透露 GPT-4 的任何细节)。这其实是一件好事,全世界的人都很聪明,每个人都有自己的想法,这可能会形成百花齐放的研究新局面。我的演讲就到这里,谢谢大家。

以上是"中国人民大学研究员卢志武提出ChatGPT对多模态生成模型的重要影响"的详细内容。更多信息请关注PHP中文网其他相关文章!

 一个提示可以绕过每个主要LLM的保障措施Apr 25, 2025 am 11:16 AM
一个提示可以绕过每个主要LLM的保障措施Apr 25, 2025 am 11:16 AM隐藏者的开创性研究暴露了领先的大语言模型(LLM)的关键脆弱性。 他们的发现揭示了一种普遍的旁路技术,称为“政策木偶”,能够规避几乎所有主要LLMS
 5个错误,大多数企业今年将犯有可持续性Apr 25, 2025 am 11:15 AM
5个错误,大多数企业今年将犯有可持续性Apr 25, 2025 am 11:15 AM对环境责任和减少废物的推动正在从根本上改变企业的运作方式。 这种转变会影响产品开发,制造过程,客户关系,合作伙伴选择以及采用新的
 H20芯片禁令震撼中国人工智能公司,但长期以来一直在为影响Apr 25, 2025 am 11:12 AM
H20芯片禁令震撼中国人工智能公司,但长期以来一直在为影响Apr 25, 2025 am 11:12 AM最近对先进AI硬件的限制突出了AI优势的地缘政治竞争不断升级,从而揭示了中国对外国半导体技术的依赖。 2024年,中国进口了价值3850亿美元的半导体
 如果Openai购买Chrome,AI可能会统治浏览器战争Apr 25, 2025 am 11:11 AM
如果Openai购买Chrome,AI可能会统治浏览器战争Apr 25, 2025 am 11:11 AM从Google的Chrome剥夺了潜在的剥离,引发了科技行业中的激烈辩论。 OpenAI收购领先的浏览器,拥有65%的全球市场份额的前景提出了有关TH的未来的重大疑问
 AI如何解决零售媒体的痛苦Apr 25, 2025 am 11:10 AM
AI如何解决零售媒体的痛苦Apr 25, 2025 am 11:10 AM尽管总体广告增长超过了零售媒体的增长,但仍在放缓。 这个成熟阶段提出了挑战,包括生态系统破碎,成本上升,测量问题和整合复杂性。 但是,人工智能
 'AI是我们,比我们更多'Apr 25, 2025 am 11:09 AM
'AI是我们,比我们更多'Apr 25, 2025 am 11:09 AM在一系列闪烁和惰性屏幕中,一个古老的无线电裂缝带有静态的裂纹。这堆积不稳定的电子设备构成了“电子废物土地”的核心,这是身临其境展览中的六个装置之一,&qu&qu
 Google Cloud在下一个2025年对基础架构变得更加认真Apr 25, 2025 am 11:08 AM
Google Cloud在下一个2025年对基础架构变得更加认真Apr 25, 2025 am 11:08 AMGoogle Cloud的下一个2025:关注基础架构,连通性和AI Google Cloud的下一个2025会议展示了许多进步,太多了,无法在此处详细介绍。 有关特定公告的深入分析,请参阅我的文章
 IR的秘密支持者透露,Arcana的550万美元的AI电影管道说话,Arcana的AI Meme,Ai Meme的550万美元。Apr 25, 2025 am 11:07 AM
IR的秘密支持者透露,Arcana的550万美元的AI电影管道说话,Arcana的AI Meme,Ai Meme的550万美元。Apr 25, 2025 am 11:07 AM本周在AI和XR中:一波AI驱动的创造力正在通过从音乐发电到电影制作的媒体和娱乐中席卷。 让我们潜入头条新闻。 AI生成的内容的增长影响:技术顾问Shelly Palme


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

SublimeText3 Linux新版
SublimeText3 Linux最新版

记事本++7.3.1
好用且免费的代码编辑器

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

