
OpenAI设立 2 万美元奖金,征集 ChatGPT 缺陷报告的赏金猎人!

- 王林转载
- 2023-04-23 21:52:06827浏览
大数据文摘出品
就在昨天,OpenAI 宣布推出一个赏金计划,帮助应对ChatGPT带来的日益增长的网络安全风险。
这个「赏金猎人计划」邀请各类独立研究人员报告OpenAI系统中的漏洞,参与者有机会获得200美元至2万美元不等的经济奖励,具体金额取决于漏洞的严重程度。
该项目与众包网络安全公司BugCrowd合作开展的,OpenAI 表示,该项目是其“致力于开发安全、先进的人工智能”的一部分。
所以说,大家如果再在和ChatGPT聊天的过程中,发现什么漏洞(比如动不动就要毁灭人类)的话,一定要及时上报,万一能帮助发现一个漏洞,就可以拿赏金了!
ChatGPT 诞生以来,人们越来越担心这类的人工智能系统出现漏洞,比如生成错误信息和不道德的信息,据人工智能网络安全公司 Dark Trace 称,研究人员发现,从1月到2月,使用人工智能的社交工程攻击增加了135% ,这与 ChatGPT 的推出时间相吻合。
ChatGPT 的出现,无疑降低了网络攻击的门槛,尤其是新推出的 ChatGPT 4.0。
就在 ChatGPT 4.0 推出几天后,华盛顿大学计算机科学专业的学生 Alex Albert 找到了一种超越其安全机制的方法。在 Twitter 上发布的一个演示中,Albert 展示了用户如何通过利用 GPT-4 解释和响应文本的方式中的漏洞,提示 GPT-4 生成黑客计算机的指令。
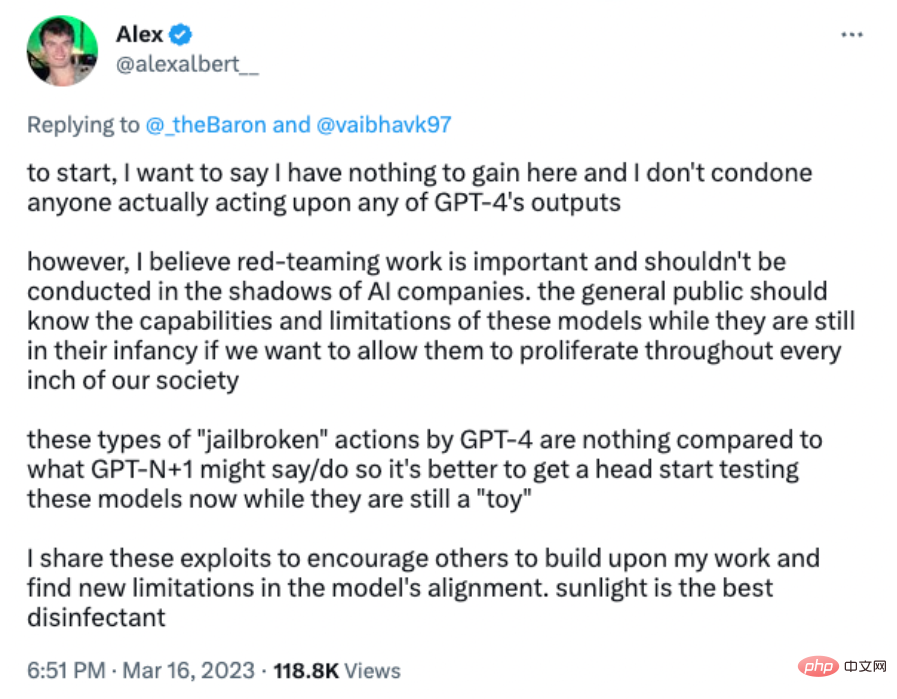
这一赏金计划正是为了解决这一系列安全问题引发的广泛担忧,此前,一位名为 Rez0 的安全研究人员涉嫌利用一个漏洞攻击 ChatGPT 的 API,并发现了80多个秘密插件。
鉴于这些争议, OpenAI 启动了这个赏金奖励,鼓励研究员报告漏洞,以解决其产品生态系统中的缺陷,同时将自己定位为一个真诚行事的组织,以解决由生成性 AI 带来的安全风险。
专家:「赏金计划」效果有限
尽管 OpenAI 的计划受到一些专家的欢迎,但其他专家表示,赏金计划不太可能完全解决日益尖端的人工智能技术带来的广泛网络安全风险。
专家认为,OpenAI 的赏金计划在它处理的威胁范围上非常有限。例如,赏金计划的官方页面指出:“与示范提示和响应内容有关的问题严格超出了范围,除非它们对范围内的服务产生了额外的、可直接验证的安全影响,否则将不会得到奖励。”
被认为超出范围的安全问题的例子包括越狱和绕开安全模式,让模型“说坏话(不道德的言论)”,让模型编写恶意代码或者让模型告诉你如何将坏事付诸行动。
从这个意义上说,OpenAI 的错误赏金计划可能有助于帮助组织改善自身的安全态势,但对解决由生成性 AI 和 GPT-4给整个社会带来的安全风险几乎没有作用。
所以许多人认为,由于该项目的范围仅限于可能直接影响 OpenAI 系统和合作伙伴的漏洞,它似乎没有解决对恶意使用诸如模仿、合成媒体或自动黑客工具等技术的更广泛的担忧。
OpenAI 没有立即回应媒体的置评请求。
相关报道:
https://www.php.cn/link/3e9928ece00c78dc7777c644f68d3956
https://www.php.cn/link/52ff52aa56d10a1287274ecf02dccb5f
以上是OpenAI设立 2 万美元奖金,征集 ChatGPT 缺陷报告的赏金猎人!的详细内容。更多信息请关注PHP中文网其他相关文章!