
Stable Diffusion-XL开启公测,让你摆脱繁琐的长prompt!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2023-04-23 10:16:071816浏览
自从Midjourney发布v5之后,在生成图像的人物真实程度、手指细节等方面都有了显着改善,并且在prompt理解的准确性、审美多样性和语言理解方面也都取得了进步。
相比之下,Stable Diffusion虽然免费、开源,但每次都要写一大长串的prompt,想生成高质量的图像全靠多次抽卡。

最近Stability AI的官宣,正在研发的Stable Diffusion XL开始面向公众测试,目前可以在Clipdrop平台免费试用。

试用链接:https://clipdrop.co/stable-diffusion
Stability AI的创始人兼首席执行官Emad Mostaque表示,目前该模型仍然处于训练阶段,等参数稳定后将会开源;SD-XL在「握手」等图像细节方面会表现更好,几乎完全可控。
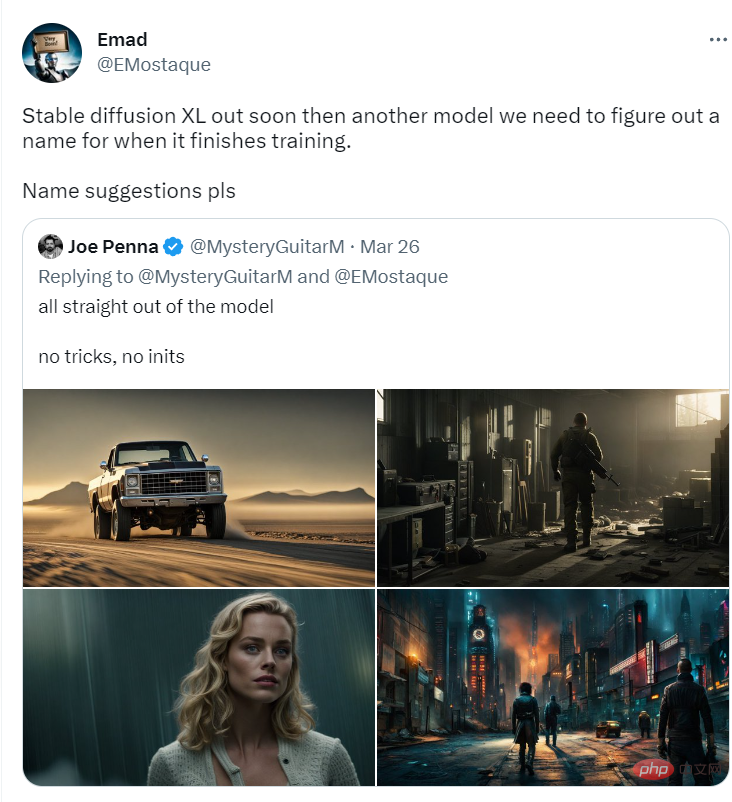
Stable Diffusion XL也并不是最终发布版的名字,并且也并非是v3,因为SD-XL的架构和SD-v2系列的模型架构非常相似。

Minimalistic home gym with rubber flooring, wall-mounted TV, weight bench, medicine ball, dumbbells, yoga mats, high-tech equipment, high detail, organized and efficient.
简约的家庭健身房,橡胶地板,壁挂式电视,举重凳,药球,哑铃,瑜伽垫,高科技设备,高细节,组织和效率
下面几张SD-XL官方发布的例图,可以看出图像的质量已经非常能打了。



不过有时候less并不代表more,有网友认为SD-XL为了摆脱「糟糕的品味」,设定了太多的规则,定制化空间越来越小,不符合大多数人的喜好。目前v1.5的Stable Diffusion仍然是社区内最流行的基座模型。

网友表示希望新版SD能够和SD 2.1版本的嵌入、hypernetworkds和Lora模型保持兼容,再从零开始重训的话就太难受了。

也有网友认为,SD-XL的表现和civit网站上网友分享的模型差不多,新模型的效果也并不是特别惊艳,也就是平均水平。

SD-XL:开源版Midjourney
关于Stable Diffusion XL模型的具体信息,官方并没有透露太多,目前只知道是一个与v2模型架构相似、但规模和参数量更大的模型。
SD-v2.1包括9亿参数,SD-XL大约有23亿参数,Emad表示正式版可能会额外发布一个更小的蒸馏版本。
SD-XL相比之前版本的改进如下:
- 使用较短的描述性prompt即可生成高质量图像
- 可以生成更贴合prompt的图像
- 图像中的人体结构更合理
- 与 v2.1和 v1.5版本(程度较轻)相比,SD-XL生成的图片更符合大众审美
- 负面提示词(negative prompt)是可选项
- 生成的肖像图更逼真
- 图像中的文本更清晰
需要注意的是,SD-XL可能与之前版本的插件不兼容。
清晰可读的文字
在v1系列和v2.1版本的Stable Diffusion模型中,并不具备在图片中生成可读文本的能力。
虽然SD-XL生成的文本信息并不总是准确,但确实得到了巨大的提升。

Photo of a woman sitting in a restaurant holding a menu that says “Menu”
一个女人坐在餐馆里拿着写着「Menu」的菜单

Photo of a man holding a sign that says “Stable Diffusion”
一个男人举着写着「Stable Diffusion」的牌子
a young female holding a sign that says “Stable Diffusion”, highlights in hair, sitting outside restaurant, brown eyes, wearing a dress, side light
一个年轻的女性举着一个牌子,上面写着「Stable Diffusion」,头发高亮,坐在餐厅外面,棕色的眼睛,穿着裙子,侧灯
更好的人体结构
Stable Diffusion在生成人体解剖结构方面一直存在诸多问题,多几条腿、少个胳膊实在是太常见不过的问题,通常需要使用inpaint功能进一步对图像细节进行修正;或者是使用ControlNet的Open Pose功能从参考图像中复制人体的姿态。
比如说SD-v1.5生成瑜伽的图像,经常会出现扭曲的人体。

Photo of a woman in yoga outfit, triangle pose, beach in evening, rim lighting
一个女人的照片在瑜伽服装,三角形的姿势,海滩在晚上,边缘照明
SD-XL虽然生成的图像并不完美,不过在人体姿态方面已经有了显着的进步。

更有美感(more aesthetic)
比如同样以屋子为主题,SD-XL可以生成更对称、视觉效果更好的照片。

SD-XL在肖像照片上也有显着改进。
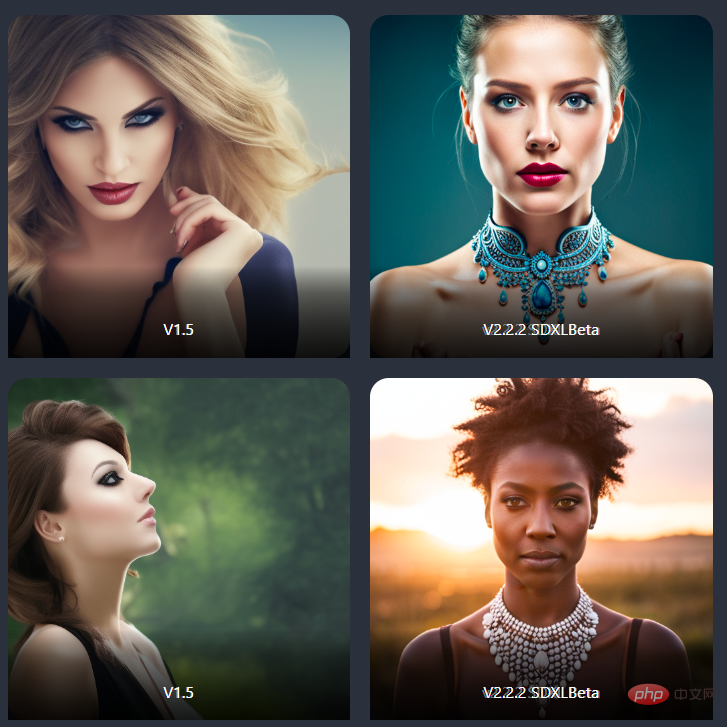
photo shot of a woman
一个女人的照片
更贴合prompt的图像
SD-XL可以更好地理解输入的prompt,并生成更精确的图像。
比如以duotone(双色)为例,SD-v1.5只会生成黑白图像,而SD-XL则可以生成具有多种颜色的双色调图像。
与 v1模型相比,理解提示符的能力有所提高。

duotone portrait of a woman
一个女人的双色调肖像
因为SD-XL同属v2系列模型,所以文本模型尺寸更大,可以比v1模型更好地理解提示词。

比如下面的例子中,v1.5模型始终无法理解图像中的两个主题(机器人和人类),但SD-XL模型可以生成正常的图像(虽然机器人还是不够big)。
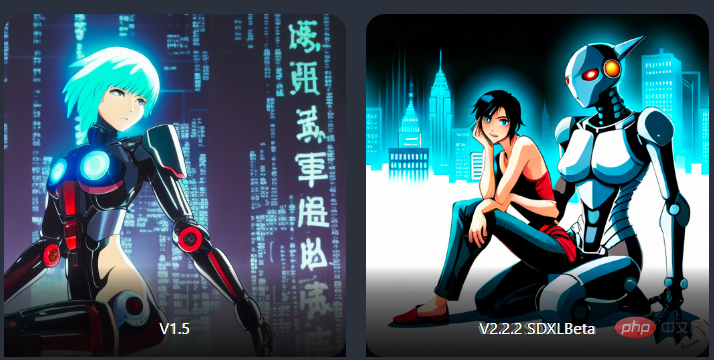
big robot friend sitting next to a human, ghost in the shell style, anime wallpaper
大机器人朋友坐在人类旁边攻壳机动队风格的动漫壁纸

a young man, highlights in hair, brown eyes, in white shirt and blue jean on a beach with a volcano in background
一个年轻人,头发染得很亮,棕色眼睛,穿着白衬衫和蓝色牛仔裤,站在海滩上,背景是一座火山
艺术风格
在艺术风格上,SD-XL并没有显着改进,和之前的版本各有千秋。
比如两个模型以不同的角度生成了Edward Hopper风格的图像。

New York city by Edward Hopper
Edward Hopper绘制的纽约
Leonid Afmov 的风格中,SD-v1.5更准确,SD-XL缺少了不同颜色的笔刷(unmistakable colorful board brushstrokes)。

New York city by Leonid Afremov
Leonid Afemov绘制的纽约
William-Adolphe Bouguereau风格中,V1.5和SDXL都可以生成一些类似的内容,其中SD-XL更接近Bouguereau创作的经典学院派绘画,并且面部细节更多。

Portrait of beautiful woman by William-Adolphe Bouguereau
William-Adolphe Bouguereau绘制的美女肖像
风格转变问题
在添加一些无关紧要的关键字后,模型的风格可能会突然转变。
比如先生成一张照片风格的图像。

a young man, highlights in hair, brown eyes, in white shirt and blue jean on a beach with a volcano in background
一个年轻人,头发染得很亮,棕色眼睛,穿着白衬衫和蓝色牛仔裤,站在海滩上,背景是一座火山
再添加一条黄色的围巾后,图像风格就变成了卡通风格。

a young man, highlights in hair, brown eyes, wearing a yellow scarf, in white shirt and blue jean on a beach with a volcano in background
一个年轻人,头发染得很亮,棕色的眼睛,围着黄色的围巾,穿着白衬衫和蓝色牛仔裤,站在一个火山为背景的海滩上
问题的故障可能源于预览问题,在正式发布后该问题不知能否得到解决。
以上是Stable Diffusion-XL开启公测,让你摆脱繁琐的长prompt!的详细内容。更多信息请关注PHP中文网其他相关文章!