



2023年,是AI人工智能技术全面爆红的一年。
以ChatGPT、GPT-4、文心一言为代表的AIGC大模型,集文本撰写、代码开发、诗词创作等功能于一体,展现出了超强的内容生产能力,带给人们极大震撼。
作为一个通信老人,除了AIGC大模型本身之外,小枣君更加关注的,是模型背后的通信技术。到底是一张怎样的强大网络,在支持着AIGC的运转?此外,AI浪潮的全面来袭,将对传统网络带来怎样的变革?
█ AIGC,到底需要多大的算力?
众所周知,数据、算法和算力,是人工智能发展的三大基本要素。
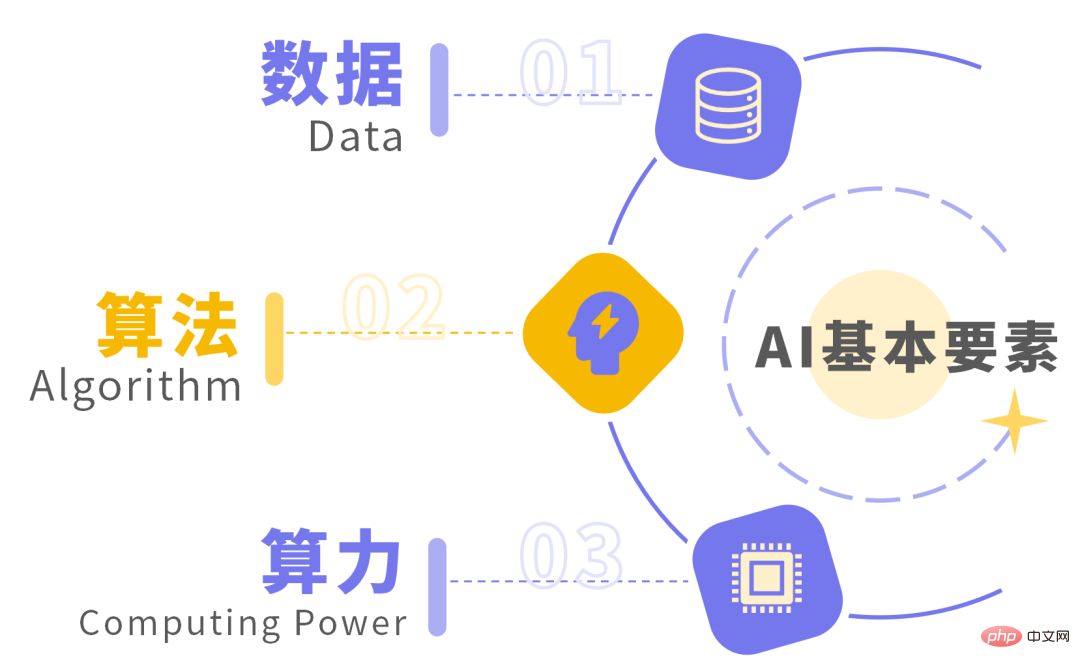
前面提到的几个AIGC大模型,之所以那么厉害,不仅是因为它们背后有海量的数据投喂,也因为算法在不断进化升级。更重要的是,人类的算力规模,已经发展到了一定程度。强大的算力基础设施,完全能够支撑AIGC的计算需求。
AIGC发展到现在,训练模型参数从千亿级飙升到了万亿级。为了完成这么大规模的训练,底层支撑的GPU数量,也达到了万卡级别规模。
以ChatGPT为例,他们使用了微软的超算基础设施进行训练,据说动用了10000块V100 GPU,组成了一个高带宽集群。一次训练,需要消耗算力约3640 PF-days(即每秒1千万亿次计算,运行3640天)。
一块V100的FP32算力,是0.014 PFLOPS(算力单位,等于每秒1千万亿次的浮点运算)。一万块V100,那就是140 PFLOPS。
也就是说,如果GPU的利用率是100%,那么,完成一次训练,就要3640÷140=26(天)。
GPU的利用率是不可能达到100%,如果按33%算(OpenAI提供的假设利用率),那就是26再翻三倍,等于78天。
可以看出,GPU的算力、GPU的利用率,对大模型的训练有很大影响。
那么问题来了,影响GPU利用率的最大因素,是什么呢?
答案是:网络。
一万甚至几万块的GPU,作为计算集群,与存储集群进行数据交互,需要极大的带宽。此外,GPU集群进行训练计算时,都不是独立的,而是混合并行。GPU之间,有大量的数据交换,也需要极大的带宽。
如果网络不给力,数据传输慢,GPU就要等待数据,导致利用率下降。利用率下降,训练时间就会增加,成本也会增加,用户体验会变差。
业界曾经做过一个模型,计算出网络带宽吞吐能力、通信时延与GPU利用率之间的关系,如下图所示:

大家可以看到,网络吞吐能力越强,GPU利用率越高;通信动态时延越大,GPU利用率越低。
一句话,没有好网络,别玩大模型。
█ 怎样的网络,才能支撑AIGC的运行?
为了应对AI集群计算对网络的调整,业界也是想了不少办法的。
传统的应对策略,主要是三种:Infiniband、RDMA、框式交换机。我们分别来简单了解一下。
Infiniband组网
Infiniband(直译为“无限带宽”技术,缩写为IB)组网,搞数据通信的童鞋应该不会陌生。
这是目前组建高性能网络的最佳途径,带宽极高,可以实现无拥塞和低时延。ChatGPT、GPT-4所使用的,据说就是Infiniband组网。
如果说Infiniband组网有什么缺点的话,那就是一个字——贵。相比传统以太网的组网,Infiniband组网的成本会贵好几倍。这项技术比较封闭,业内目前成熟的供应商只有1家,用户没什么选择权。
- RDMA网络
RDMA的全称是Remote Direct Memory Access(远程直接数据存取)。它是一种新型的通信机制。在RDMA方案里,应用程序的数据,不再经过CPU和复杂的操作系统,而是直接和网卡通信,不仅大幅提升了吞吐能力,也降低了时延。
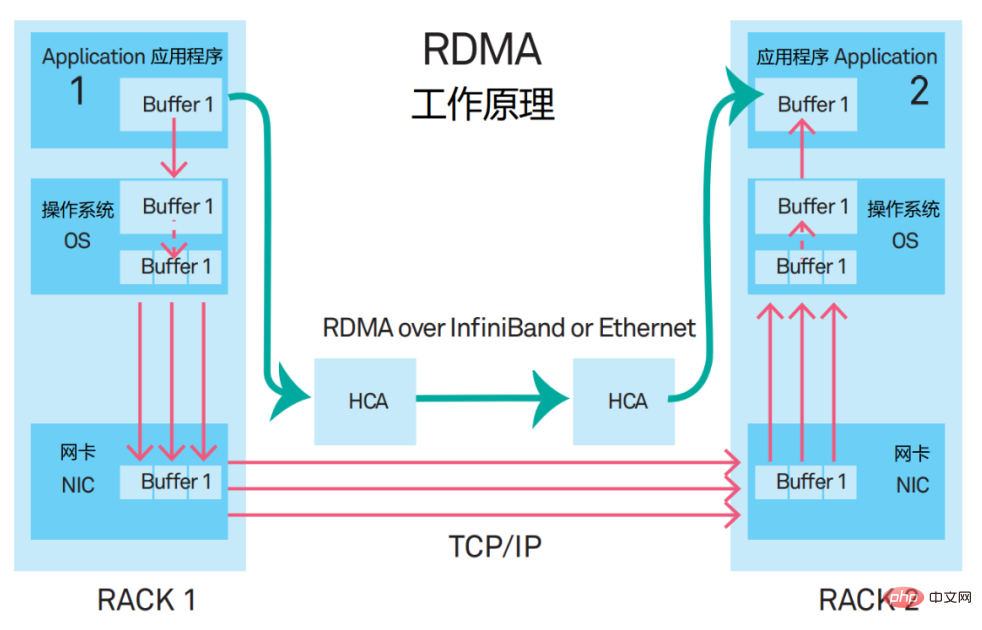
RDMA最早提出时,是承载在InfiniBand网络中的。现在,RDMA逐渐移植到了以太网上。
目前,高性能网络的主流组网方案,是基于RoCE v2(RDMA over Converged Ethernet,基于融合以太网的RDMA)协议来组建支持RDMA的网络。
这种方案有两个重要的搭配技术,分别是PFC(Priority Flow Control,基于优先级的流量控制)和ECN(Explicit Congestion Notification,显式拥塞通知)。它们是为了避免链路中的拥塞而产生的技术,但是,频繁被触发,反而会导致发送端暂停发送,或降速发送,进而拉低通信带宽。(下文还会提到它们)
- 框式交换机
国外有部分互联网公司,寄希望于利用采用框式交换机(DNX芯片+VOQ技术),来满足构建高性能网络的需求。
DNX:broadcom(博通)的一个芯片系列
VOQ:Virtual Output Queue,虚拟输出队列
这种方案看似可行,但也面临以下几个挑战。
首先,框式交换机的扩展能力一般。机框大小限制了最大端口数,如想做更大规模的集群,需要横向扩展多个机框。
其次,框式交换机的设备功耗大。机框内线卡芯片、Fabric芯片、风扇等数量众多,单设备的功耗超过2万瓦,有的甚至3万多瓦,对机柜供电能力要求太高。
第三,框式交换机的单设备端口数量多,故障域大。
基于以上原因,框式交换机设备只适合小规模部署AI计算集群。
█ 到底什么是DDC
前面说的都是传统方案。既然这些传统方案不行,那当然就要想新办法。
于是,一种名叫DDC的全新解决方案,闪亮登场了。
DDC,全名叫做Distributed Disaggregated Chassis(分布式分散式机箱)。
它是前面框式交换机的“分拆版”。框式交换机的扩展能力不足,那么,我们干脆把它给拆开,将一个设备变成多个设备,不就OK了?

框式设备,一般分为交换网板(背板)和业务线卡(板卡)两部分,相互之间用连接器连接。
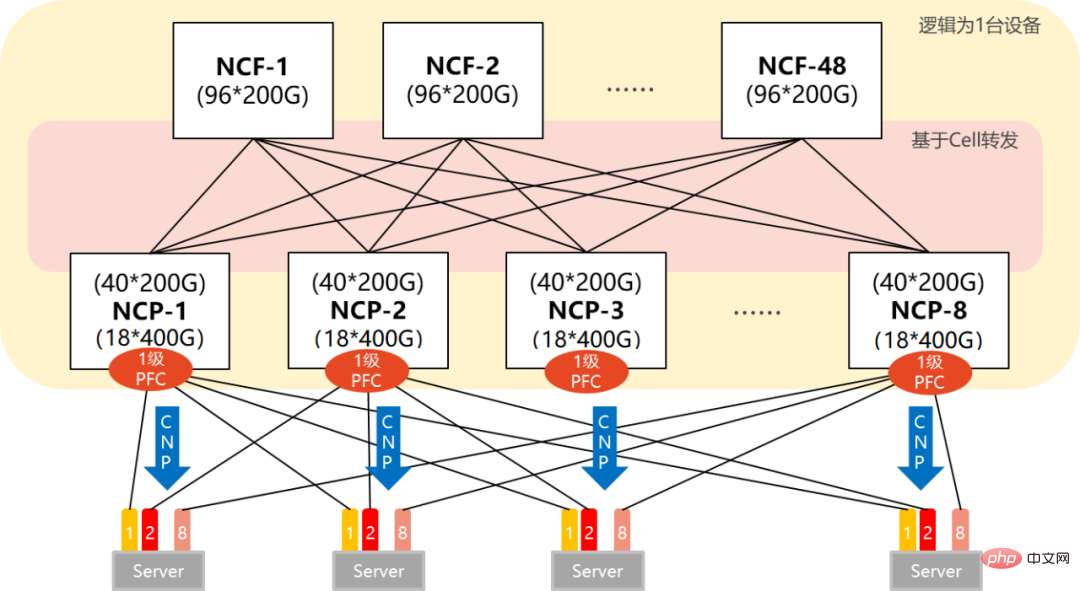
DDC方案,将交换网板变成了NCF设备,将业务线卡变成了NCP设备。连接器,则变成了光纤。框式设备的管理功能,在DDC架构中,也变成了NCC。
NCF:Network Cloud Fabric(网络云管理控制平面)
NCP:Network Cloud Packet Processing(网络云数据包处理)
NCC:Network Cloud Controller(网络云控制器)
DDC从集中式变成分布式之后,扩展能力大大增强了。它可以根据AI集群的大小,灵活设计组网规模。
我们来举两个例子(单POD组网和多POD组网)。
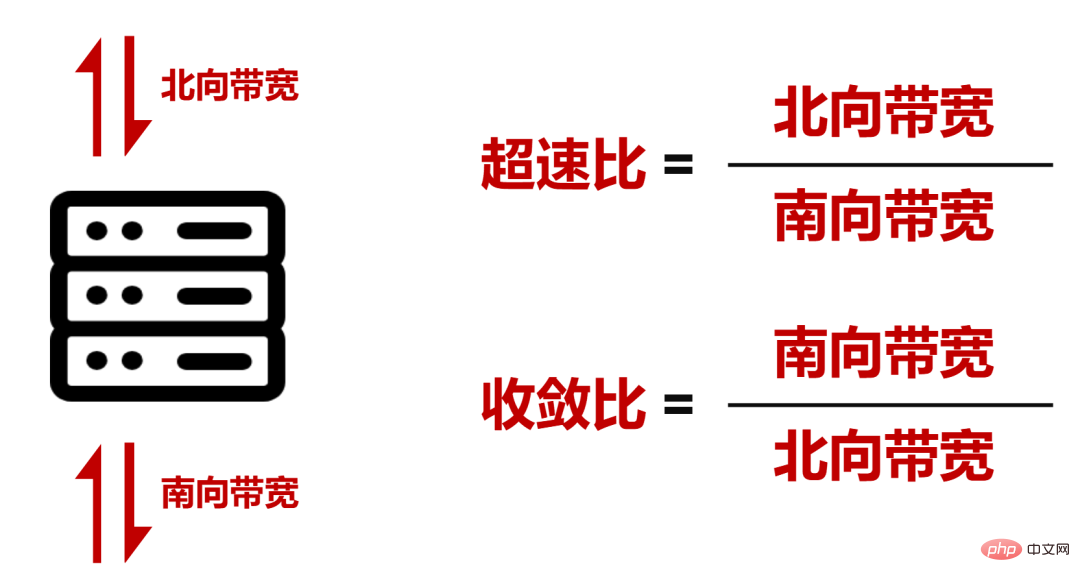
单POD组网中,采用96台NCP作为接入,其中NCP下行共18个400G接口,负责连接AI计算集群的网卡。上行共40个200G接口,最大可以连接40台NCF,NCF提供96个200G接口,该规模上下行带宽为超速比1.1:1。整个POD可支撑1728个400G网络接口,按照一台服务器配8块GPU来计算,可支撑216台AI计算服务器。
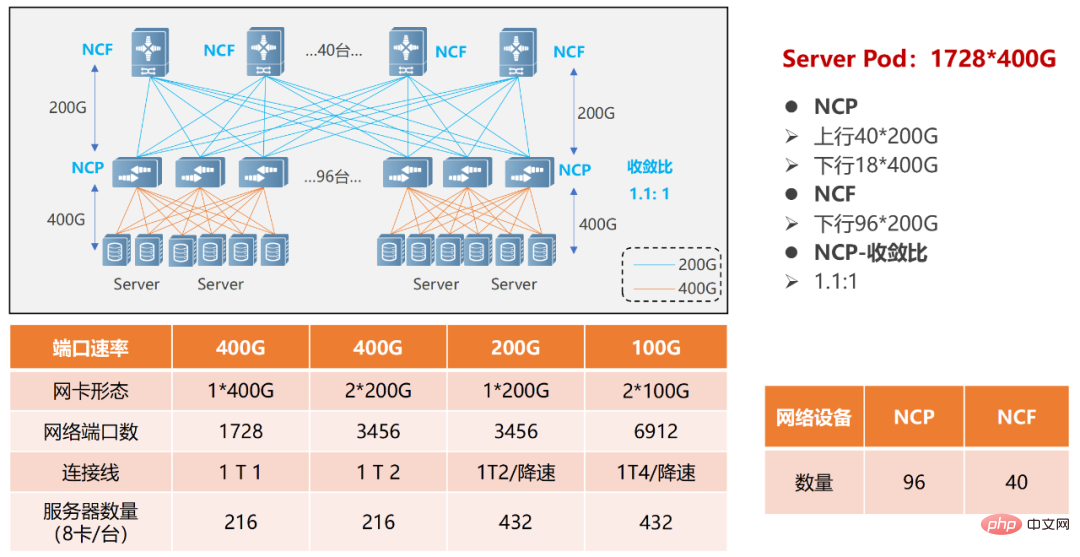
单POD组网
多级POD组网,规模可以变得更大。
在多级POD组网中,NCF设备要牺牲一半的SerDes,用于连接第二级的NCF。所以,此时单POD采用48台NCP作为接入,下行共18个400G接口。
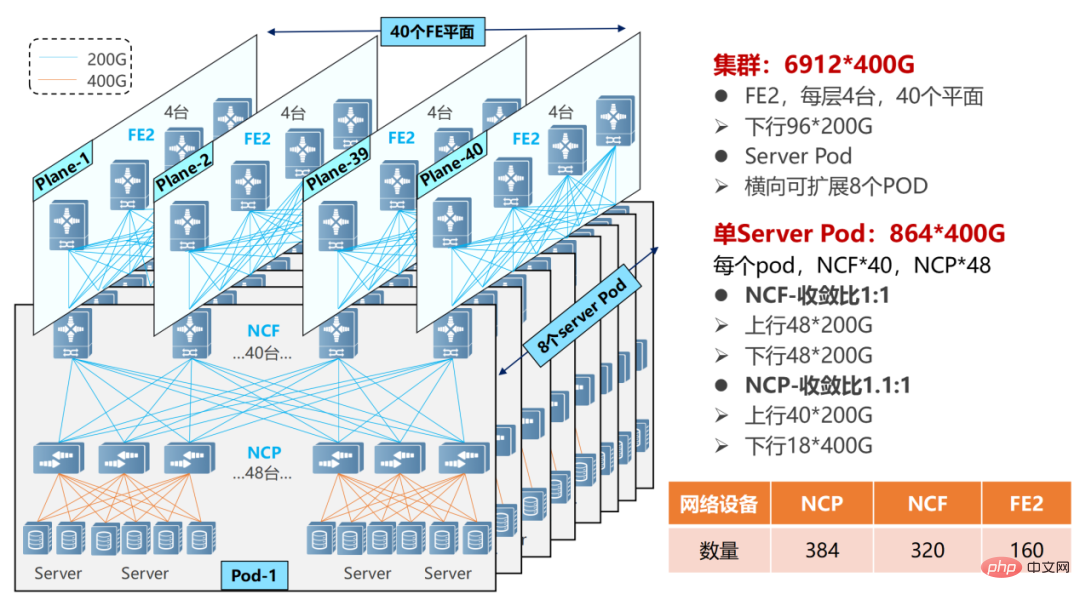
多POD组网
单个POD内,可以支撑864个400G接口(48×18)。通过横向增加POD(8个),实现规模扩容,整体最大可支撑6912个400G网络端口(864×8)。
NCP上行40个200G,接POD内40台NCF。POD内NCF采用48个200G接口,48个200G接口分为12个一组上行到第二级的NCF。第二级NCF采用40个平面(Plane),每个平面4台NCF-P,分别对应在POD内的40台NCF。
整个网络的POD内实现了1.1:1的超速比(北向带宽大于南向带宽),而在POD和二级NCF之间实现了1:1的收敛比(南向带宽/北向带宽)。
█ DDC的技术特点
站在规模和带宽吞吐的角度,DDC已经可以满足AI大模型训练对于网络的需求。
然而,网络的运作过程是复杂的,DDC还需要在时延对抗、负载均衡性、管理效率等方面有所提升。
- 基于VOQ+Cell的转发机制,对抗丢包
网络在工作的过程中,可能会出现突发流量,造成接收端来不及处理,引起拥塞和丢包。
为了应对这种情况,DDC采取了基于VOQ+Cell的转发机制。
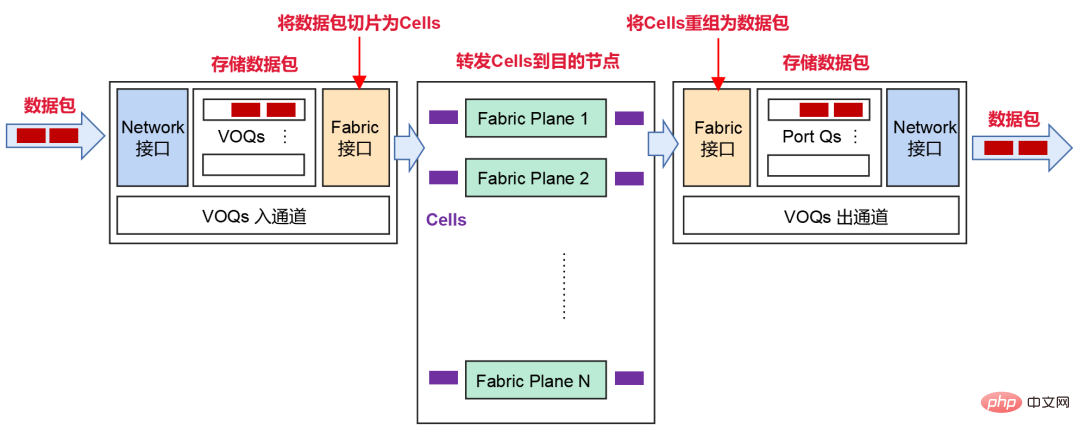
发送端从网络接收到数据包之后,会分类到VOQ(虚拟输出队列)中存储。
在发送数据包前,NCP会先发送Credit报文,确定接收端是否有足够的缓存空间处理这些报文。
如果接收端OK,则将数据包分片成Cells(数据包的小切片),并且动态负载均衡到中间的Fabric节点(NCF)。
如果接收端暂时没能力处理报文,报文会在发送端的VOQ中暂存,并不会直接转发到接收端。
在接收端,这些Cells会进行重组和存储,进而转发到网络中。
切片后的Cells,将采用轮询的机制发送。它能够充分利用到每一条上行链路,确保所有上行链路的传输数据量近似相等。
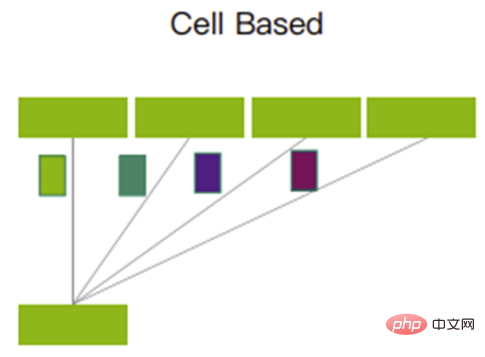
轮询机制
这样的机制,充分利用了缓存,可以大幅度减少丢包,甚至不会产生丢包情况。数据重传减少了,整体通信时延更稳定更低,从而可以提高带宽利用率,进而提升业务吞吐效率。
- PFC单跳部署,避免死锁
前面我们提到,RDMA无损网络中引入了PFC(基于优先级的流量控制)技术,进行流量控制。
简单来说,PFC就是在一条以太网链路上创建 8 个虚拟通道,并为每条虚拟通道指定相应优先级,允许单独暂停和重启其中任意一条虚拟通道,同时允许其它虚拟通道的流量无中断通过。
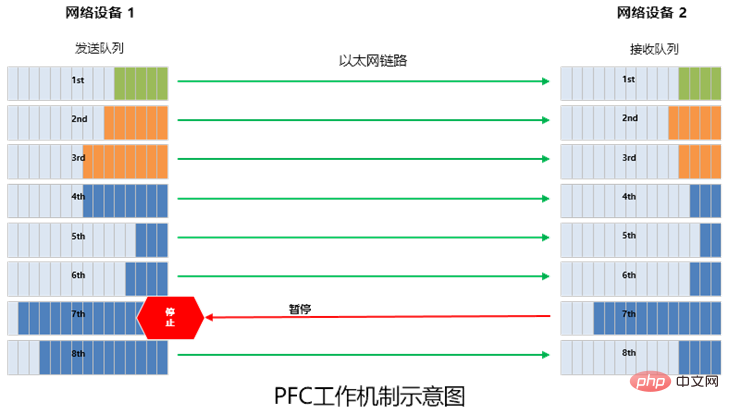
PFC可以实现基于队列的流量控制,但是,它也存在一个问题,那就是死锁。
所谓死锁,就是多个交换机之间,因为环路等原因,同时出现了拥塞(各自端口缓存消耗超过了阈值),又都在等待对方释放资源,从而导致的“僵持状态”(所有交换机的数据流永久堵塞)。
DDC的组网下,就不存在PFC的死锁问题。因为,站在整个网络的角度,所有NCP和NCF可以看成一台设备。对于AI服务器来说,整个DDC,就是一个交换机,不存在多级交换机。所以,就不存在死锁。
另外,根据DDC的数据转发机制,可在接口处部署ECN(显式拥塞通知)。
ECN机制下,网络设备一旦检测到RoCE v2流量出现了拥塞(内部的Credit和缓存机制无法支撑突发流量),就会向服务器端发送CNP(Congestion Notification Packets,拥塞通知报文),要求降速。
- 分布式OS,提升可靠性
最后再看看管理控制平面。
前面我们提到,在DDC架构中,框式设备的管理功能变成了NCC(网络云控制器)。NCC非常重要,如果采用单点式的方式,万一出现问题,就会导致整网故障。
为了避免出现这样的问题,DDC可以取消NCC的集中控制面,构建分布式OS(操作系统)。
基于分布式OS,可以基于SDN运维控制器,通过标准接口(Netconf、GRPC等)配置管理设备。这样的话,每台NCP和NCF独立管理,有独立的控制面和管理面,大大提升了系统的可靠性,也更加便于部署。
█ DDC的商用进展
综上所述,相对传统组网,DDC在组网规模、扩展能力、可靠性、成本、部署速度方面,拥有显著优势。它是网络技术升级的产物,提供了一种颠覆原有网络架构的思路,可以实现网络硬件的解耦、网络架构的统一、转发容量的扩展。
业界曾经使用OpenMPI测试套件进行过框式设备和传统组网设备的对比模拟测试。测试结论是:在All-to-All场景下,相较于传统组网,框式设备的带宽利用率提升了约20%(对应GPU利用率提升8%左右)。
正是因为DDC的显著能力优势,现在这项技术已经成为行业的重点发展方向。例如锐捷网络,他们就率先推出了两款可交付的DDC产品,分别是400G NCP交换机——RG-S6930-18QC40F1,以及200G NCF交换机——RG-X56-96F1。

RG-S6930-18QC40F1交换机的高度为2U,提供18个400G的面板口,40个200G的Fabric内联口,4个风扇和2个电源。
RG-X56-96F1交换机的高度为4U,提供96个200G的Fabric内联口,8个风扇和4个电源。
据悉,锐捷网络还会继续研发、推出400G端口形态的产品。
█ 最后的话
AIGC的崛起,已经掀起了互联网行业的新一轮技术革命。
我们可以看到,越来越多的企业,正在加入这个赛道,参与角逐。这意味着,网络基础设施的升级,迫在眉睫。
DDC的出现,将大幅提升网络基础设施的能力,不仅可以有效应对AI革命对网络基础设施提出的挑战,更将助力整个社会的数字化转型,加速人类数智时代的全面到来。
以上是适合驱动AIGC的网络的特征是什么?的详细内容。更多信息请关注PHP中文网其他相关文章!

![无法使用chatgpt!解释可以立即测试的原因和解决方案[最新2025]](https://img.php.cn/upload/article/001/242/473/174717025174979.jpg?x-oss-process=image/resize,p_40) 无法使用chatgpt!解释可以立即测试的原因和解决方案[最新2025]May 14, 2025 am 05:04 AM
无法使用chatgpt!解释可以立即测试的原因和解决方案[最新2025]May 14, 2025 am 05:04 AMChatGPT无法访问?本文提供多种实用解决方案!许多用户在日常使用ChatGPT时,可能会遇到无法访问或响应缓慢等问题。本文将根据不同情况,逐步指导您解决这些问题。 ChatGPT无法访问的原因及初步排查 首先,我们需要确定问题是出在OpenAI服务器端,还是用户自身网络或设备问题。 请按照以下步骤进行排查: 步骤1:检查OpenAI官方状态 访问OpenAI Status页面 (status.openai.com),查看ChatGPT服务是否正常运行。如果显示红色或黄色警报,则表示Open
 计算ASI的风险始于人类的思想May 14, 2025 am 05:02 AM
计算ASI的风险始于人类的思想May 14, 2025 am 05:02 AM2025年5月10日,麻省理工学院物理学家Max Tegmark告诉《卫报》,AI实验室应在释放人工超级智能之前模仿Oppenheimer的三位一体测试演算。 “我的评估是'康普顿常数',这是一场比赛的可能性
 易于理解的解释如何编写和撰写歌词和推荐工具May 14, 2025 am 05:01 AM
易于理解的解释如何编写和撰写歌词和推荐工具May 14, 2025 am 05:01 AMAI音乐创作技术日新月异,本文将以ChatGPT等AI模型为例,详细讲解如何利用AI辅助音乐创作,并辅以实际案例进行说明。我们将分别介绍如何通过SunoAI、Hugging Face上的AI jukebox以及Python的Music21库进行音乐创作。 通过这些技术,每个人都能轻松创作原创音乐。但需注意,AI生成内容的版权问题不容忽视,使用时务必谨慎。 让我们一起探索AI在音乐领域的无限可能! OpenAI最新AI代理“OpenAI Deep Research”介绍: [ChatGPT]Ope
 什么是chatgpt-4?对您可以做什么,定价以及与GPT-3.5的差异的详尽解释!May 14, 2025 am 05:00 AM
什么是chatgpt-4?对您可以做什么,定价以及与GPT-3.5的差异的详尽解释!May 14, 2025 am 05:00 AMChatGPT-4的出现,极大地拓展了AI应用的可能性。相较于GPT-3.5,ChatGPT-4有了显着提升,它具备强大的语境理解能力,还能识别和生成图像,堪称万能的AI助手。在提高商业效率、辅助创作等诸多领域,它都展现出巨大的潜力。然而,与此同时,我们也必须注意其使用上的注意事项。 本文将详细解读ChatGPT-4的特性,并介绍针对不同场景的有效使用方法。文中包含充分利用最新AI技术的技巧,敬请参考。 OpenAI发布的最新AI代理,“OpenAI Deep Research”详情请点击下方链
 解释如何使用chatgpt应用程序!日本支持和语音对话功能May 14, 2025 am 04:59 AM
解释如何使用chatgpt应用程序!日本支持和语音对话功能May 14, 2025 am 04:59 AMCHATGPT应用程序:与AI助手释放您的创造力!初学者指南 ChatGpt应用程序是一位创新的AI助手,可处理各种任务,包括写作,翻译和答案。它是一种具有无限可能性的工具,可用于创意活动和信息收集。 在本文中,我们将以一种易于理解的方式解释初学者,从如何安装chatgpt智能手机应用程序到语音输入功能和插件等应用程序所独有的功能,以及在使用该应用时要牢记的要点。我们还将仔细研究插件限制和设备对设备配置同步
 如何使用中文版Chatgpt?注册程序和费用的说明May 14, 2025 am 04:56 AM
如何使用中文版Chatgpt?注册程序和费用的说明May 14, 2025 am 04:56 AMChatGPT中文版:解锁中文AI对话新体验 ChatGPT风靡全球,您知道它也提供中文版本吗?这款强大的AI工具不仅支持日常对话,还能处理专业内容,并兼容简体中文和繁体中文。无论是中国地区的使用者,还是正在学习中文的朋友,都能从中受益。 本文将详细介绍ChatGPT中文版的使用方法,包括账户设置、中文提示词输入、过滤器的使用、以及不同套餐的选择,并分析潜在风险及应对策略。此外,我们还将对比ChatGPT中文版和其他中文AI工具,帮助您更好地了解其优势和应用场景。 OpenAI最新发布的AI智能
 5 AI代理神话,您需要停止相信May 14, 2025 am 04:54 AM
5 AI代理神话,您需要停止相信May 14, 2025 am 04:54 AM这些可以将其视为生成AI领域的下一个飞跃,这为我们提供了Chatgpt和其他大型语言模型聊天机器人。他们可以代表我们采取行动,而不是简单地回答问题或产生信息
 易于理解使用Chatgpt创建和管理多个帐户的非法性的解释May 14, 2025 am 04:50 AM
易于理解使用Chatgpt创建和管理多个帐户的非法性的解释May 14, 2025 am 04:50 AM使用chatgpt有效的多个帐户管理技术|关于如何使用商业和私人生活的详尽解释! Chatgpt在各种情况下都使用,但是有些人可能担心管理多个帐户。本文将详细解释如何为ChatGpt创建多个帐户,使用时该怎么做以及如何安全有效地操作它。我们还介绍了重要的一点,例如业务和私人使用差异,并遵守OpenAI的使用条款,并提供指南,以帮助您安全地利用多个帐户。 Openai


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

Dreamweaver Mac版
视觉化网页开发工具

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

