
揭秘数据竞赛胜利秘诀:探析A100在200场比赛中的优势

- PHPz转载
- 2023-04-21 19:55:071393浏览
2022 年是 AI 领域发展的重要一年,在数据竞赛领域也同样如此,所有平台的总奖金超过了 500 万美元。
近日,机器学习竞赛分析平台 ML Contests 对 2022 年的数据竞赛进行了一次大规模统计。新报告回顾了 2022 年发生的所有值得关注的事。以下是对原文的编译整理。
重点内容:
- 成功参赛者的工具选择:Python、Pydata、Pytorch 和梯度提高的决策树。
- 深度学习仍未取代梯度增强的决策树,尽管在结识增强方法时,前者通常价值会有所提升。
- Transformer 继续在 NLP 中占主导地位,并开始在计算机视觉中和卷积神经网络开始竞争。
- 当今数据竞赛涵盖了广泛的研究领域,包括计算机视觉、NLP、数据分析、机器人、时间序列分析等。
- 大集合模型在获胜方案中仍然很普遍,一些单模型解决方案也能赢。
- 有多个活跃的数据竞赛平台存在。
- 数据竞赛社区持续增长,在学界也是一样。
- 大约有 50%获奖者是一人团队,50%的获奖者是首次得奖。
- 有人使用了高端硬件,但 Google Colab 这样的免费资源也能赢得比赛。
比赛和趋势
奖金数额最大的比赛是由美国复垦局赞助 Drivendata 的 Snow Cast Showdown 竞赛。参与者可获得 50 万美元的奖金,旨在通过为西部的不同地区提供准确的雪水流量估算,以帮助改善供水管理。与往常一样,Drivendata 详细撰写了比赛情况的文章并有详细的解决方案报告,非常值得一读。
2022 年最受欢迎的比赛是 Kaggle 的 American Express 默认预测竞赛,旨在预测客户是否会偿还贷款。有超过 4000 支队伍参赛,共 10 万美元奖金分发至前四名的队伍。今年第一次有首次参赛且单人队伍获得冠军,其使用了神经网络和 LightGBM 模型的集合。
最大的独立竞赛是斯坦福大学的 AI 审计挑战,该挑战为最佳的「模型、解决方案、数据集和工具」提供了 7.1 万美元的奖励池,以寻求方法解决「非法歧视的 AI 审核系统」的问题。
基于金融预测的三场比赛全部在 Kaggle 上:分别是 JPX 的东京证券交易所预测,Ubiquant 的市场预测以及 G-Research 的加密预测。
在不同方向的对比中,计算机视觉占比最高,NLP 位居第二,顺序决策问题(强化学习)正在兴起。Kaggle 通过在 2020 年引入模拟竞赛来回应这种流行的增长。Aicrowd 还举办了许多强化学习类竞赛。在 2022 年,其中有 25 个互动赛的比赛总额超过 30 万美元。
在 NeurIPS 2022 官方竞赛 Real Robot Challenge 中,参与者必须学会控制三指机器人,以将立方体移动到目标位置或将其定位在空间的特定点上,且要面朝正确的方向。参与者的策略每周在物理机器人上运行,结果更新到排行榜上。奖励为 5000 美元的奖品,以及在 NeurIPS 研讨会上演讲的学术荣誉。
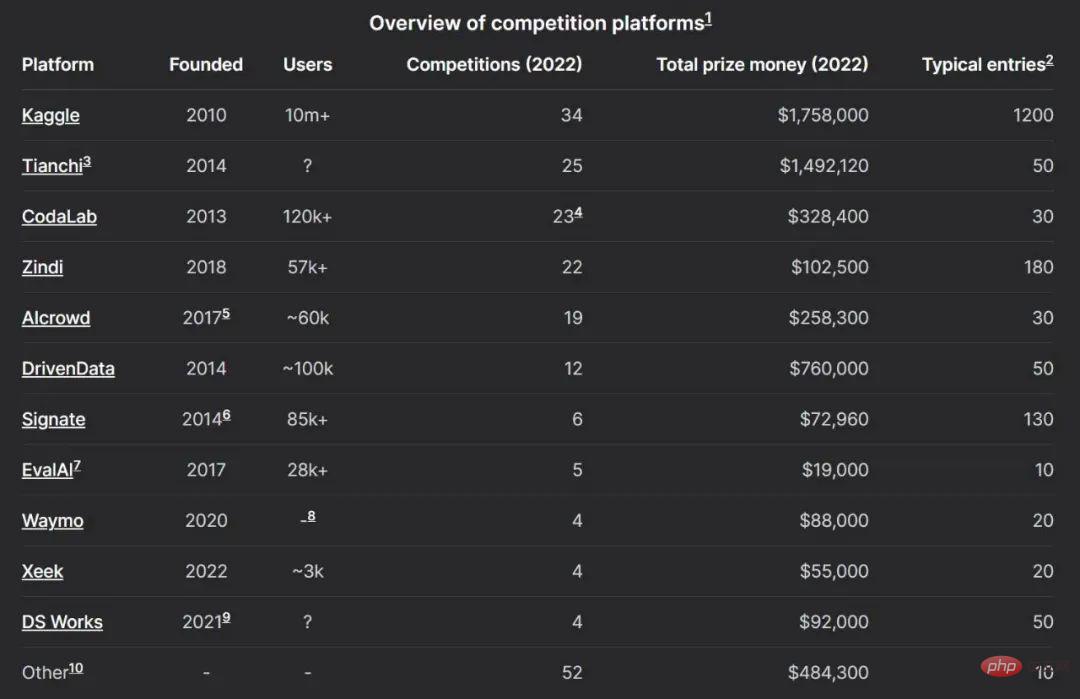
平台
虽然人们都知道 Kaggle 和天池,但目前也有很多机器学习竞赛平台组成了活跃的生态系统。
下图为 2022 平台比较:
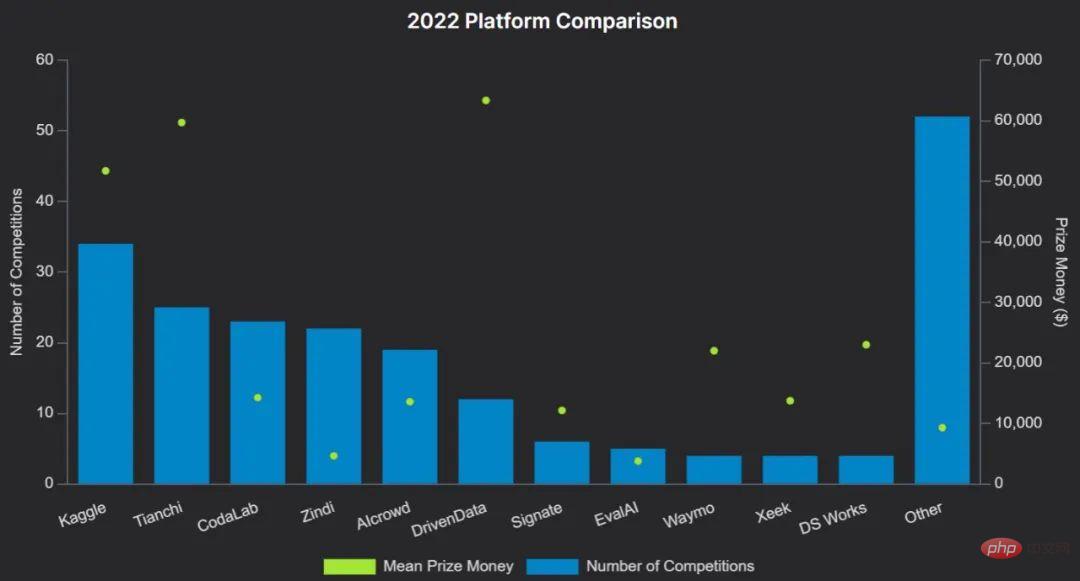
举一些例子:
- Kaggle 是最成熟的平台之一,它在 2017 年被谷歌收购,并拥有最大的社区,最近吸引了 1000 万用户。在 Kaggle 上进行带奖金的比赛可能非常昂贵。除了举办比赛外,Kaggle 还允许用户托管数据集,笔记和模型。
- Codalab 是一个开源竞赛平台,由巴黎大学 - 萨克莱大学维护。任何人都可以注册,主持或参加比赛。其提供免费的 CPU 资源可用于推理,比赛组织者可以用自己的硬件进行补充。
- Zindi 是一个较小的平台,具有非常活跃的社区,专注于将机构与非洲的数据科学家联系起来。Drivendata 专注于具有社会影响的竞赛,并为 NASA 和其他组织开展了比赛。竞赛总是在深入的研究报告后跟进。
- Aicrowd 最初是瑞士联邦理工学院(EPFL)的研究项目,现在是前五名竞赛平台之一。它举办了几次 NeurIPS 官方比赛。
学术界
在大型平台上运行的比赛的大部分奖金都来自工业界,但是机器学习竞赛显然在学术界拥有更加丰富的历史,正如 Isabelle Guyon 今年在 NeurIPS 邀请演讲中所讨论的那样。
NeurIPS 是全球最负盛名的学术机器学习会议之一,过去十年中最重要的机器学习论文经常会在大会上呈现,包括 AlexNet,GAN,Transformer 和 GPT-3。
NeurIPS 在 2014 年首次在机器学习(CIML)研讨会方面举办了数据挑战赛,自 2017 年以来一直有竞赛环节。从那时起,竞赛和总奖金不断增长,在 2022 年 12 月达到了接近 40 万美元。
其他机器学习会议也举办了比赛,包括 CVPR、ICPR、IJCAI、ICRA、ECCV、PCIC 和 AutoML。
奖金
大约一半的机器学习比赛有超过 1 万美元的奖池。毫无疑问,许多有趣的比赛奖金不多,本报告仅考虑那些有货币奖品或学术荣誉的部分。通常,与享有声望的学术会议相关的数据比赛为获奖者提供了旅行赠款,以便他们参加会议。
虽然平均而言,一些比赛平台确实倾向于拥有比其他平台更大的奖池(见平台比较图表),但许多平台在 2022 年至少举办过一场奖池非常大的比赛 —— 总奖金排名前十的比赛包括在 DrivenData、Kaggle、CodaLab 和 AIcrowd 上运行的。
夺冠方法
该调查通过问卷和观察代码的方式分析获胜算法使用的技术。
相当一致的是,Python 是竞赛获胜者的首选语言,这对于人们来说可能不是个预料之外的结果。在使用 Python 的人中,大约一半主要使用 Jupyter Notebook,另一半使用标准 Python 脚本。
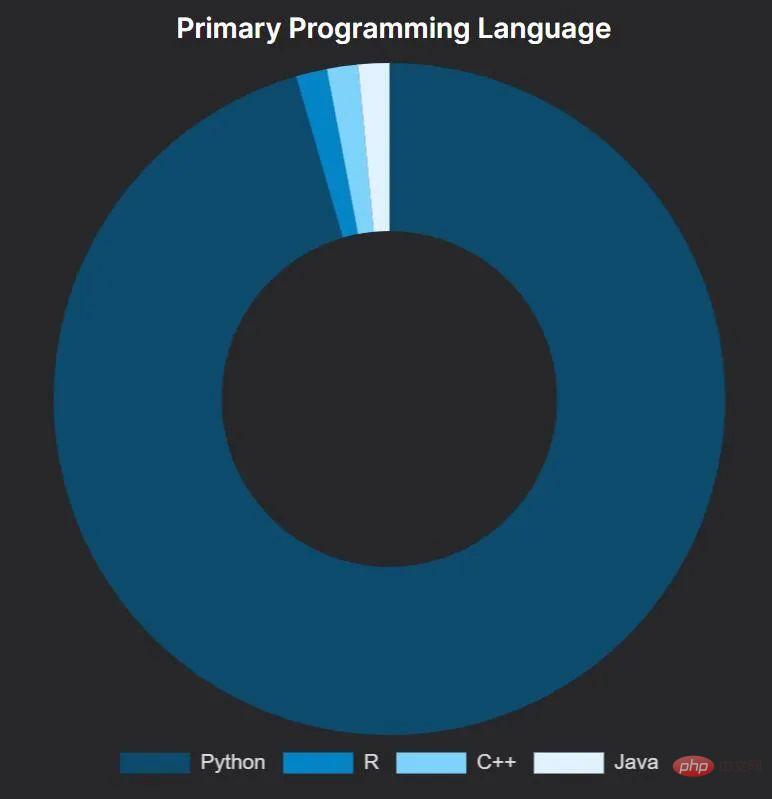
一个主要使用 R 语言的获胜解决方案是:Amir Ghazi 赢得了 Kaggle 上预测 2022 年美国男子大学篮球锦标赛获胜者的比赛。他通过使用 —— 显然是逐字复制 ——2018 年同类竞赛获胜解决方案的代码来做到这一点,该方法由 Kaggle Grandmaster Darius Barušauskas 撰写。让人难以想象的是,Darius 也参加了 2022 年的这场比赛,他使用新的方法,并获得了第 593 名。
获奖者使用的 Python 包
在观察获胜解决方案中使用的软件包时,结果显示所有使用 Python 的获奖者都在一定程度上使用了 PyData 堆栈。
将最流行的软件包分为三类 —— 核心工具包、NLP 类和计算机视觉类。

其中,深度学习框架 PyTorch 的增长一直稳定,其从 2021 年到 2022 年的跃升非常明显:PyTorch 从获胜解决方案的 77% 增加到了 96%。
在 46 个使用深度学习的获奖解决方案中,44 个使用 PyTorch 作为他们的主要框架,只有两个使用 TensorFlow。更明显的是,使用 TensorFlow 赢得的两项比赛之一,Kaggle 的大堡礁竞赛,提供额外的 5 万美元奖金给使用 TensorFlow 的获胜团队。另一个使用 TensorFlow 获胜的比赛使用了高级的 Keras API。
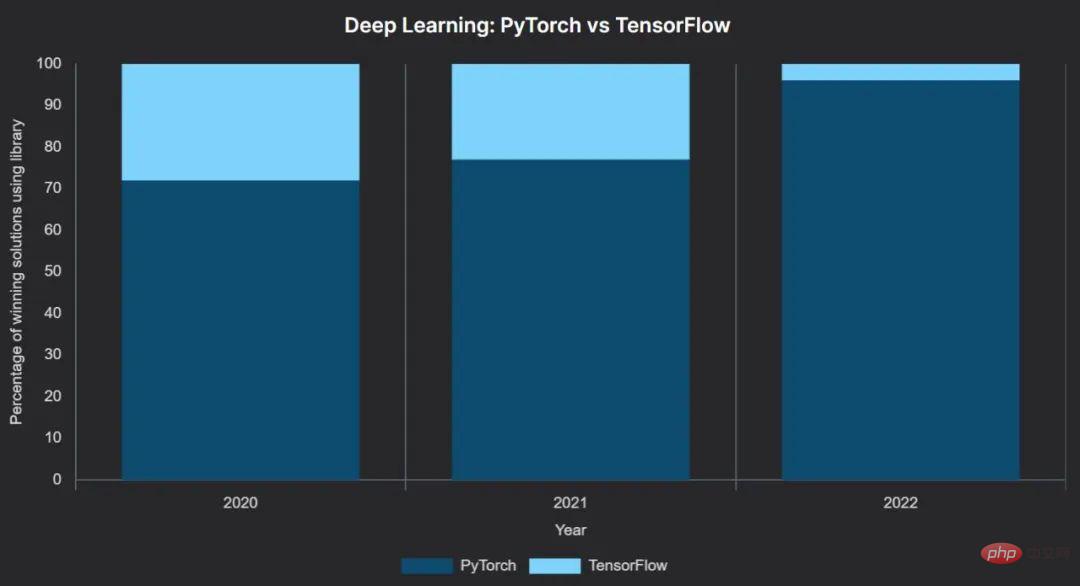
虽然有 3 名获胜者使用 pytorch-lightning 和 1 名使用 fastai—— 两者都建立在 PyTorch 之上 —— 但绝大多数人直接使用 PyTorch。
现在或许可以说至少在数据竞赛上,PyTorch 赢得了机器学习框架之争。这与更广泛的机器学习研究趋势一致。
值得注意的是,我们没有发现任何获胜团队使用其他神经网络库的实例,例如 JAX(由 Google 构建,由 DeepMind 使用)、PaddlePaddle(由百度开发)或 MindSpore(由华为开发)。
计算机视觉
工具有一统江湖的趋势,技术却不是。在 CVPR 2022 上,ConvNext 架构被介绍为「2020 年代的 ConvNet」,并证明其性能优于最近的基于 Transformer 的模型。它被用于至少两个赢得比赛的计算机视觉解决方案,而 CNN 总体上仍是迄今为止计算机视觉竞赛获奖者中最爱用的神经网络架构。
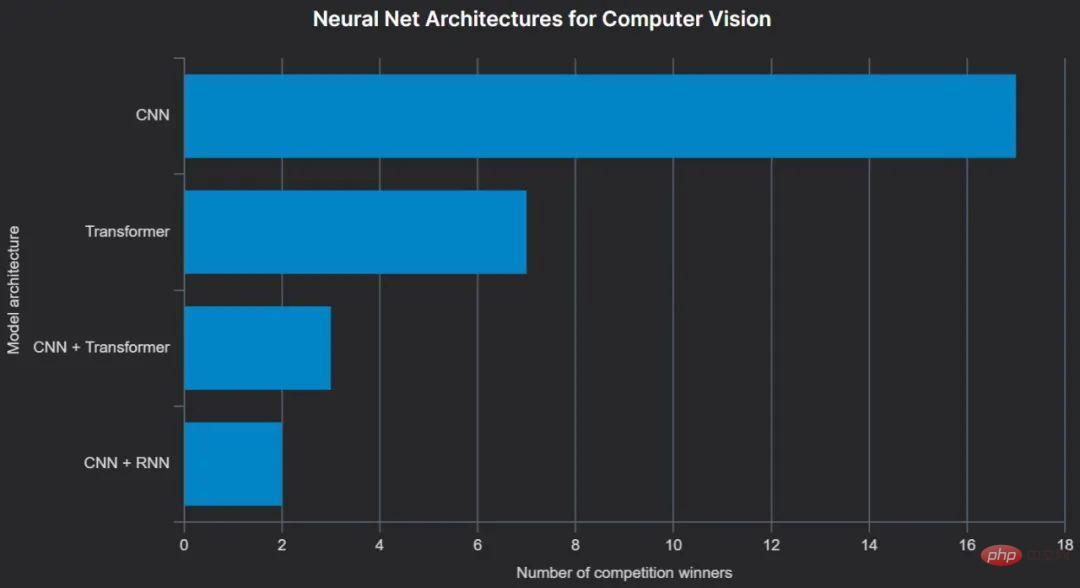
计算机视觉与语言建模非常相似的地方在于使用预训练模型:在公共数据集(例如 ImageNet)上训练的易于理解的架构。最受欢迎的存储库是 Hugging Face Hub,可通过 timm 访问,这使得加载数十种不同计算机视觉模型的预训练版本变得极其方便。
使用预训练模型的优势是显而易见的:真实世界的图像和人类生成的文本都有一些共同的特征,使用预训练模型可以带来常识的知识,类似于使用了更大、更通用的训练数据集。
通常,预先训练好的模型会根据特定任务的数据(例如比赛组织者提供的数据)进行微调 —— 进一步训练,但并非总是如此。Image Matching Challenge 的获胜者使用了预训练模型,完全没有任何微调 ——「由于本次比赛中训练和测试数据的质量(不同),我们没有使用提供的训练进行 fine-tuning,因为我们认为它会不太有效。」这个决定得到了回报。
到目前为止,2022 年获奖者中最受欢迎的预训练计算机视觉模型类型是 EfficientNet,顾名思义,它的优势在于比许多其他模型占用资源更少。
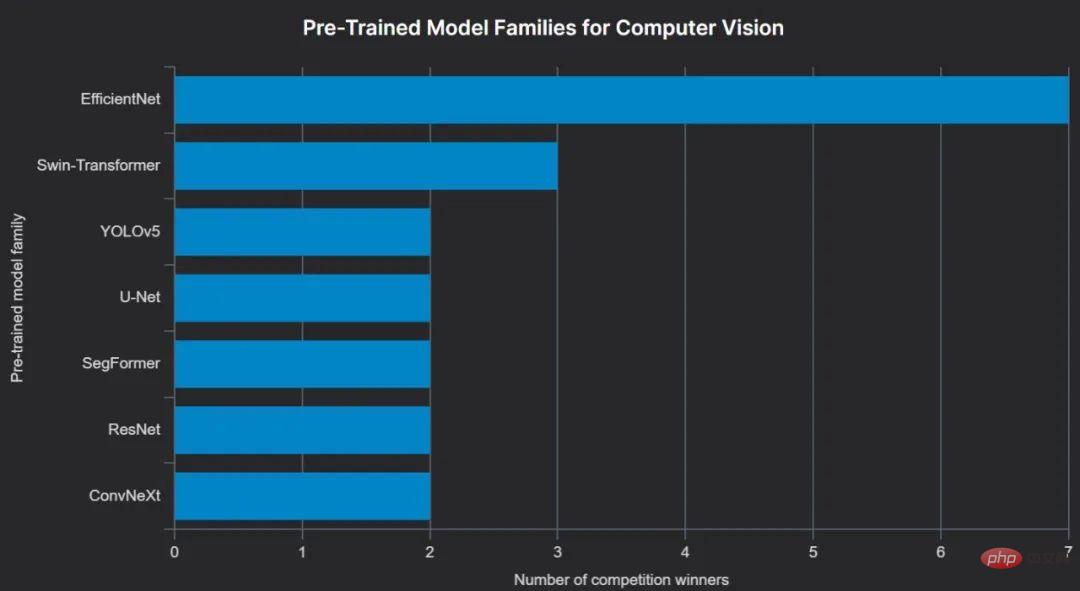
自然语言处理
自 2017 年问世以来,基于 Transformer 的模型一直主导着自然语言处理(NLP)领域。Transformer 是 BERT 和 GPT 中的「T」,也是 ChatGPT 中的核心。
因此,自然语言处理竞赛中所有获胜的解决方案都是基于 Transformer 的模型为核心也就不足为奇了。它们都是在 PyTorch 中实现的,这并不奇怪。他们都使用了预训练模型,使用 Hugging Face 的 Transformers 库加载,几乎所有模型都使用了 Microsoft Research 的 DeBERTa 模型版本 —— 通常是 deberta-v3-large。
它们其中的许多都需要大量的计算资源。例如,谷歌 AI4Code 获胜者运行 A100(80GB)大约 10 天,以训练单个 deberta-v3-large 用于他们的最终解决方案。这种方法是个例外(使用单个主模型和固定的训练 / 评估拆分)—— 所有其他解决方案都大量使用集成模型,并且几乎都使用各种形式的 k-fold 交叉验证。例如,Jigsaw Toxic Comments 比赛的获胜者使用了 15 个模型输出的加权平均值。
基于 Transformer 的集成有时会与 LSTM 或 LightGBM 结合使用,也有至少两个伪标签实例被有效地用于获胜的解决方案。
XGBoost 曾经是 Kaggle 的代名词。然而,LightGBM 显然是 2022 年获奖者最喜欢的 GBDT 库 —— 获奖者在他们的解决方案报告或问卷中提到 LightGBM 的次数与 CatBoost 和 XGBoost 的总和相同,CatBoost 位居第二,XGBoost 出人意料地排名第三。
计算和硬件
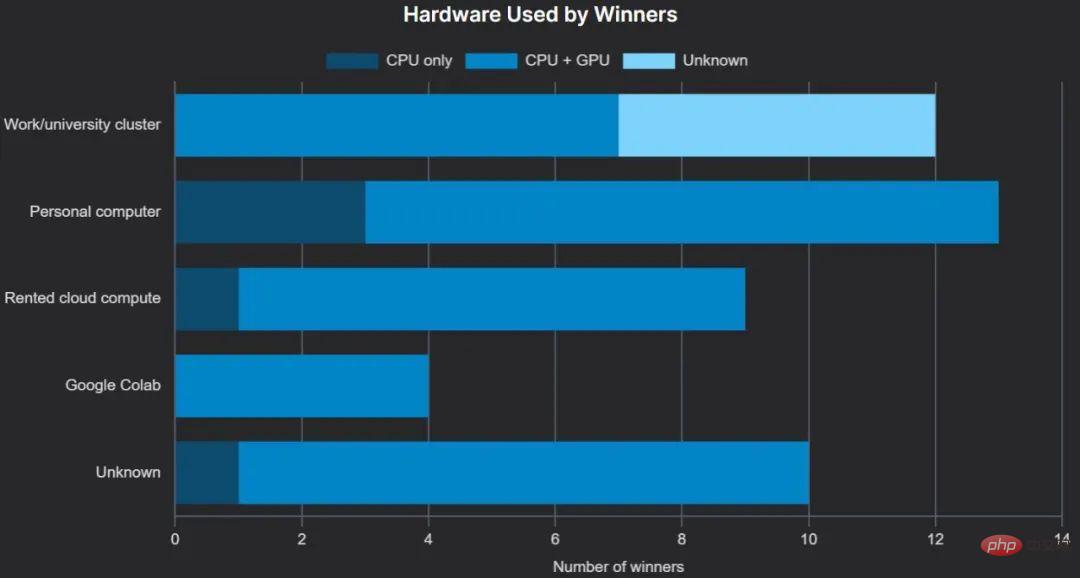
正如大致预期的,大多数获胜者使用 GPU 进行训练 —— 这可以极大地提高梯度提升树的训练性能,并且实际上是深度神经网络所必需的。相当多的获奖者可以访问其雇主或大学提供的集群,通常包括 GPU。
有点令人惊讶的是,我们没有发现任何使用 Google 的张量处理单元 TPU 来训练获胜模型的实例。我们也没有看到任何关于苹果 M 系列芯片上训练的获胜模型,苹果芯片自 2022 年 5 月以来一直得到 PyTorch 的支持。
谷歌的云笔记本解决方案 Colab 很受欢迎,有一位获胜者使用免费套餐,一位使用 Pro 套餐,另一位使用 Pro+(我们无法确定第四位获胜者使用 Colab 所使用的套餐)。
本地个人硬件比云硬件更受欢迎,尽管九名获奖者提到了他们用于训练的 GPU,但没有具体说明他们使用的是本地 GPU 还是云 GPU。
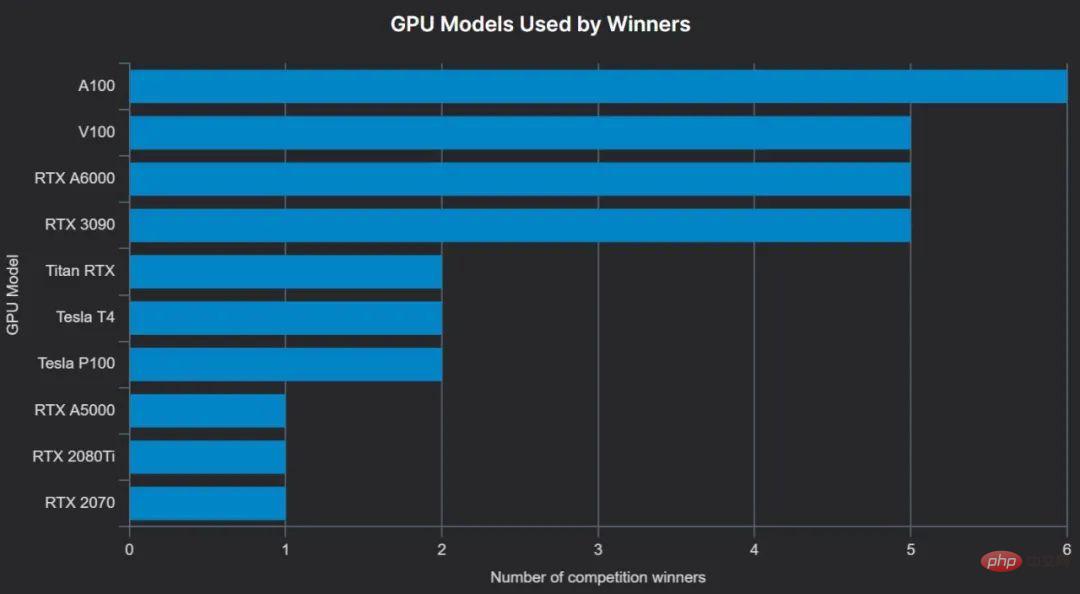
最受欢迎的 GPU 是最新的高端 AI 加速卡 NVIDIA A100(这里将 A100 40GB 和 A100 80GB 放在一起,因为获胜者并不总能区分两者),而且通常使用多块 A100—— 例如,Zindi 的 Turtle Recall 竞赛的获胜者使用 8 块 A100(40GB)GPU,另外两个获胜者使用 4 块 A100。
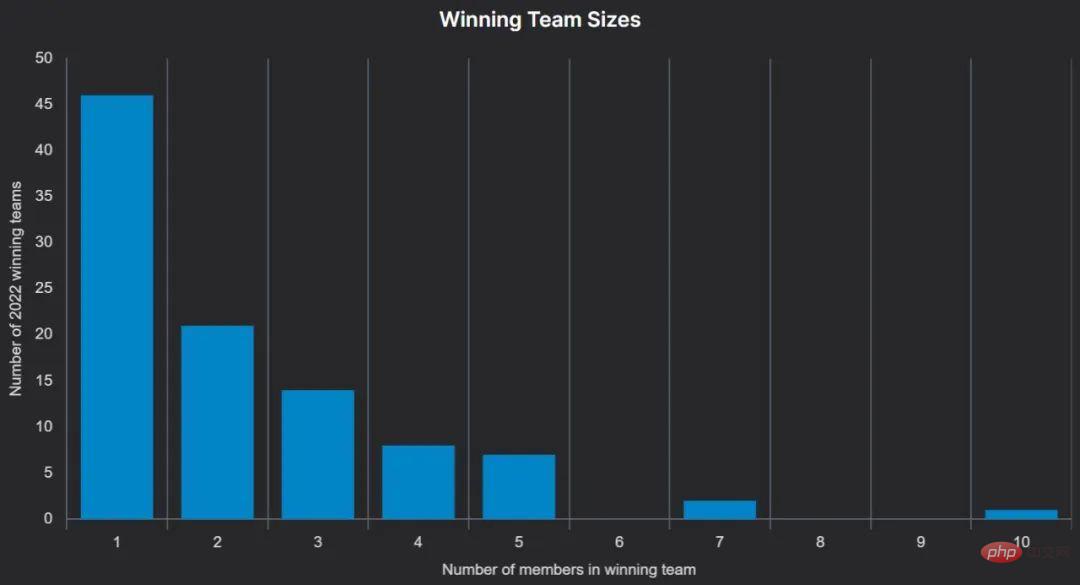
团队构成
许多比赛允许每个团队最多 5 名参赛者,团队可以由个人或较小的团队在成绩提交截止日期前的某个 deadline 前「合并」在一起组成。
一些比赛允许更大的团队,例如,Waymo 的开放数据挑战允许每个团队最多 10 个人。
结论
这是对 2022 年机器学习竞赛的大致观察。希望你可以从中找到一些有用信息。
2023 年有许多激动人心的新比赛,我们期待在这些比赛结束时发布更多见解。
以上是揭秘数据竞赛胜利秘诀:探析A100在200场比赛中的优势的详细内容。更多信息请关注PHP中文网其他相关文章!