
对Copilot进行逆向工程之后,我发现它可能只用了参数量12B的小模型

- 王林转载
- 2023-04-18 17:37:032018浏览
2021 年,微软、OpenAI、Github 三家联合打造了一个好用的代码补全与建议工具 ——Copilot。
它会在开发者的代码编辑器内推荐代码行,比如当开发者在 Visual Studio Code、Neovim 和 JetBrains IDE 等集成开发环境中输入代码时,它就能够推荐下一行的代码。此外,Copilot 甚至可以提供关于完整的方法和复杂的算法等建议,以及模板代码和单元测试的协助。
一年多过去,这一工具已经成为不少程序员离不开的「编程伙伴」。前特斯拉人工智能总监 Andrej Karpathy 表示,「Copilot 大大加快了我的编程速度,很难想象如何回到『手动编程』。目前,我仍在学习如何使用它,它已经编写了我将近 80% 的代码,准确率也接近 80%。」
习惯之余,我们对于 Copilot 也有一些疑问,比如 Copilot 的 prompt 长什么样?它是如何调用模型的?它的推荐成功率是怎么测出来的?它会收集用户的代码片段发送到自己的服务器吗?Copilot 背后的模型是大模型还是小模型?
为了解答这些疑问,来自伊利诺伊大学香槟分校的一位研究者对 Copilot 进行了粗略的逆向工程,并将观察结果写成了博客。
Andrej Karpathy 在自己的推特中推荐了这篇博客。
以下是博客原文。
对 Copilot 进行逆向工程
Github Copilot 对我来说非常有用。它经常能神奇地读懂我的心思,并提出有用的建议。最让我惊讶的是它能够从周围的代码(包括其他文件中的代码)中正确地「猜测」函数 / 变量。只有当 Copilot 扩展从周围的代码发送有价值的信息到 Codex 模型时,这一切才会发生。我很好奇它是如何工作的,所以我决定看一看源代码。
在这篇文章中,我试图回答有关 Copilot 内部结构的具体问题,同时也描述了我在梳理代码时所得到的一些有趣的观察结果。
这个项目的代码可以在这里找到:
代码地址:https://github.com/thakkarparth007/copilot-explorer
整篇文章结构如下:

逆向工程概述
几个月前,我对 Copilot 扩展进行了非常浅显的「逆向工程」,从那时起我就一直想要进行更深入的研究。在过去的近几周时间终于得以抽空来做这件事。大体来讲,通过使用 Copilot 中包含的 extension.js 文件,我进行了一些微小的手动更改以简化模块的自动提取,并编写了一堆 AST 转换来「美化」每个模块,将模块进行命名,同时分类并手动注释出其中一些最为有趣的部分。
你可以通过我构建的工具探索逆向工程的 copilot 代码库。它可能不够全面和精致,但你仍可以使用它来探索 Copilot 的代码。
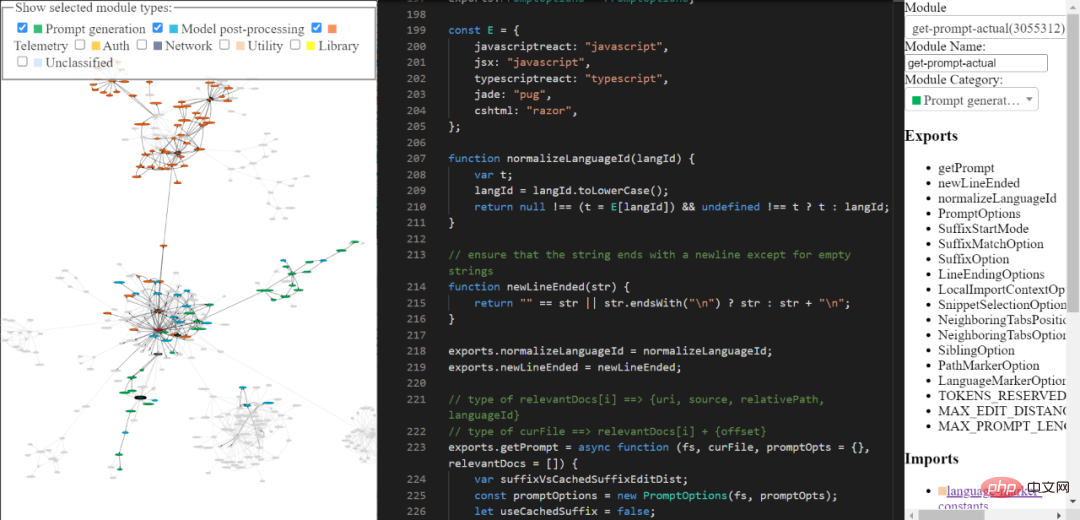
工具链接:https://thakkarparth007.github.io/copilot-explorer/
Copilot:概述
Github Copilot 由如下两个主要部分组成:
- 客户端:VSCode 扩展收集你输入的任何内容(称为 prompt),并将其发送到类似 Codex 的模型。 无论模型返回什么,它都会显示在你的编辑器中。
- 模型:类似 Codex 的模型接受 prompt 并返回完成 prompt 的建议。
秘诀 1:prompt 工程
现在,Codex 已经在大量公共 Github 代码上得到了训练,因此它能提出有用的建议是合理的。但是 Codex 不可能知道你当前项目中存在哪些功能,即便如此,它还是能提出涉及项目功能的建议,它是如何做到的?
让我们分两个部分来对此进行解答:首先让我们来看一下由 copilot 生成的一个真实 prompt 例子,而后我们再来看它是如何生成的。
prompt 长啥样
Copilot 扩展在 prompt 中编码了大量与你项目相关的信息。Copilot 有一个相当复杂的 prompt 工程 pipeline。如下是一个 prompt 的示例:
{"prefix": "# Path: codeviz\app.pyn# Compare this snippet from codeviz\predictions.py:n# import jsonn# import sysn# import timen# from manifest import Manifestn# n# sys.path.append(__file__ + "/..")n# from common import module_codes, module_deps, module_categories, data_dir, cur_dirn# n# gold_annots = json.loads(open(data_dir / "gold_annotations.js").read().replace("let gold_annotations = ", ""))n# n# M = Manifest(n# client_name = "openai",n# client_connection = open(cur_dir / ".openai-api-key").read().strip(),n# cache_name = "sqlite",n# cache_connection = "codeviz_openai_cache.db",n# engine = "code-davinci-002",n# )n# n# def predict_with_retries(*args, **kwargs):n# for _ in range(5):n# try:n# return M.run(*args, **kwargs)n# except Exception as e:n# if "too many requests" in str(e).lower():n# print("Too many requests, waiting 30 seconds...")n# time.sleep(30)n# continuen# else:n# raise en# raise Exception("Too many retries")n# n# def collect_module_prediction_context(module_id):n# module_exports = module_deps[module_id]["exports"]n# module_exports = [m for m in module_exports if m != "default" and "complex-export" not in m]n# if len(module_exports) == 0:n# module_exports = ""n# else:n# module_exports = "It exports the following symbols: " + ", ".join(module_exports)n# n# # get module snippetn# module_code_snippet = module_codes[module_id]n# # snip to first 50 lines:n# module_code_snippet = module_code_snippet.split("\n")n# if len(module_code_snippet) > 50:n# module_code_snippet = "\n".join(module_code_snippet[:50]) + "\n..."n# else:n# module_code_snippet = "\n".join(module_code_snippet)n# n# return {"exports": module_exports, "snippet": module_code_snippet}n# n# #### Name prediction ####n# n# def _get_prompt_for_module_name_prediction(module_id):n# context = collect_module_prediction_context(module_id)n# module_exports = context["exports"]n# module_code_snippet = context["snippet"]n# n# prompt = f"""\n# Consider the code snippet of an unmodule named.n# nimport jsonnfrom flask import Flask, render_template, request, send_from_directorynfrom common import *nfrom predictions import predict_snippet_description, predict_module_namennapp = Flask(__name__)nn@app.route('/')ndef home():nreturn render_template('code-viz.html')nn@app.route('/data/<path:filename>')ndef get_data_files(filename):nreturn send_from_directory(data_dir, filename)nn@app.route('/api/describe_snippet', methods=['POST'])ndef describe_snippet():nmodule_id = request.json['module_id']nmodule_name = request.json['module_name']nsnippet = request.json['snippet']ndescription = predict_snippet_description(nmodule_id,nmodule_name,nsnippet,n)nreturn json.dumps({'description': description})nn# predict name of a module given its idn@app.route('/api/predict_module_name', methods=['POST'])ndef suggest_module_name():nmodule_id = request.json['module_id']nmodule_name = predict_module_name(module_id)n","suffix": "if __name__ == '__main__':rnapp.run(debug=True)","isFimEnabled": true,"promptElementRanges": [{ "kind": "PathMarker", "start": 0, "end": 23 },{ "kind": "SimilarFile", "start": 23, "end": 2219 },{ "kind": "BeforeCursor", "start": 2219, "end": 3142 }]}
正如你所见,上述 prompt 包括一个前缀和一个后缀。Copilot 随后会将此 prompt(在经过一些格式化后)发送给模型。在这种情况下,因为后缀是非空的,Copilot 将以 “插入模式”,也就是 fill-in-middle (FIM) 模式来调用 Codex。
如果你查看前缀,将会看到它包含项目中另一个文件的一些代码。参见 # Compare this snippet from codeviz\predictions.py: 代码行及其之后的数行
prompt 是如何准备的?
Roughly, the following sequence of steps are executed to generate the prompt:
一般来讲,prompt 通过以下一系列步骤逐步生成:
1. 入口点:prompt 提取发生在给定的文档和光标位置。其生成的主要入口点是 extractPrompt (ctx, doc, insertPos)
2. 从 VSCode 中查询文档的相对路径和语言 ID。参见:getPromptForRegularDoc (ctx, doc, insertPos)
3. 相关文档:而后,从 VSCode 中查询最近访问的 20 个相同语言的文件。请参阅 getPromptHelper (ctx, docText, insertOffset, docRelPath, docUri, docLangId) 。这些文件后续会用于提取将要包含在 prompt 中的类似片段。我个人认为用同一种语言作为过滤器很奇怪,因为多语言开发是相当常见的。不过我猜想这仍然能涵盖大多数情况。
4. 配置:接下来,设定一些选项。具体包括:
- suffixPercent(多少 prompt tokens 应该专用于后缀?默认好像为 15%)
- fimSuffixLengthThreshold(可实现 Fill-in-middle 的后缀最小长度?默认为 -1,因此只要后缀非空,FIM 将始终启用,不过这最终会受 AB 实验框架控制)
- includeSiblingFunctions 似乎已被硬编码为 false,只要 suffixPercent 大于 0(默认情况下为 true)。
5. 前缀计算:现在,创建一个「Prompt Wishlist」用于计算 prompt 的前缀部分。这里,我们添加了不同的「元素」及其优先级。例如,一个元素可以类似于「比较这个来自 中的片段」,或本地导入的上下文,或每个文件的语言 ID 及和 / 或路径。这都发生在 getPrompt (fs, curFile, promptOpts = {}, relevantDocs = []) 中。
- 这里有 6 种不同类型的「元素」 – BeforeCursor, AfterCursor, SimilarFile, ImportedFile ,LanguageMarker,PathMarker。
- 由于 prompt 大小有限,wishlist 将按优先级和插入顺序排序,其后将由元素填充到该 prompt 中,直至达到大小限制。这种「填充」逻辑在 PromptWishlist.fulfill (tokenBudget) 中得以实现。
- LanguageMarkerOption、NeighboringTabsPositionOption、SuffixStartMode 等一些选项控制这些元素的插入顺序和优先级。一些选项控制如何提取某些信息,例如,NeighboringTabsOption 控制从其他文件中提取片段的积极程度。某些选项仅为特定语言定义,例如,LocalImportContextOption 仅支持为 Typescript 定义。
- 有趣的是,有很多代码会参与处理这些元素的排序。但我不确定是否使用了所有这些代码,有些于我而言看起来像是死代码。例如,neighborTabsPosition 似乎从未被设置为 DirectlyAboveCursor…… 但我可能是错的。同样地,SiblingOption 似乎被硬编码为 NoSiblings,这意味着没有实际的同级(sibling)函数提取发生。总之,也许它们是为未来设计的,或者可能只是死代码。
6. 后缀计算:上一步是针对前缀的,但后缀的逻辑相对简单 —— 只需用来自于光标的任意可用后缀填充 token budget 即可。这是默认设置,但后缀的起始位置会根据 SuffixStartMode 选项略有不同, 这也是由 AB 实验框架控制的。例如,如果 SuffixStartMode 是 SiblingBlock,则 Copilot 将首先找到与正在编辑的函数同级的功能最相近的函数,并从那里开始编写后缀。
- 后缀缓存:有件事情十分奇怪,只要新后缀与缓存的后缀相差「不太远」,Copilot 就会跨调用缓存后缀, 我不清楚它为何如此。这或许是由于我难以理解代码混淆(obfuscated code)(尽管我找不到该代码的替代解释)。
仔细观察一下片段提取
对我来说,prompt 生成最完整的部分似乎是从其他文件中提取片段。它在此处被调用并被 neighbor-snippet-selector.getNeighbourSnippets 所定义。根据选项,这将会使用「Fixed window Jaccard matcher」或「Indentation based Jaccard Matcher」。我难以百分百确定,但看起来实际上并没有使用 Indentation based Jaccard Matcher。
默认情况下,我们使用 fixed window Jaccard Matcher。这种情况下,将给定文件(会从中提取片段的文件)分割成固定大小的滑动窗口。然后计算每个窗口和参考文件(你正在录入的文件)之间的 Jaccard 相似度。每个「相关文件」仅返回最优窗口(尽管存在需返回前 K 个片段的规定,但从未遵守过)。默认情况下,FixedWindowJaccardMatcher 会被用于「Eager 模式」(即窗口大小为 60 行)。但是,该模式由 AB Experimentation framework 控制,因此我们可能会使用其他模式。
秘诀 2:模型调用
Copilot 通过两个 UI 提供补全:Inline/GhostText 和 Copilot Panel。在这两种情况下,模型的调用方式存在一些差异。
Inline/GhostText
主要模块:https://thakkarparth007.github.io/copilot-explorer/codeviz/templates/code-viz.html#m9334&pos=301:14
在其中,Copilot 扩展要求模型提供非常少的建议 (1-3 条) 以提速。它还积极缓存模型的结果。此外,如果用户继续输入,它会负责调整建议。如果用户打字速度很快,它还会请求模型开启函数防抖动功能(debouncing)。
这个 UI 也设定了一些逻辑来防止在某些情况下发送请求。例如,若用户光标在一行的中间,那么仅当其右侧的字符是空格、右大括号等时才会发送请求。
1、通过上下文过滤器(Contextual Filter)阻止不良请求
更有趣的是,在生成 prompt 后,该模块会检查 prompt 是否「足够好」,以便调用模型, 这是通过计算「上下文过滤分数」来实现的。这个分数似乎是基于一个简单的 logistic 回归模型,它包含 11 个特征,例如语言、之前的建议是否被接受 / 拒绝、之前接受 / 拒绝之间的持续时间、prompt 中最后一行的长度、光标前的最后一个字符等。此模型权重包含在扩展代码自身。
如果分数低于阈值(默认 15% ),则不会发出请求。探索这个模型会很有趣,我观察到一些语言比其他语言具有更高的权重(例如 php > js > python > rust > dart…php)。另一个直观的观察是,如果 prompt 以 ) 或 ] 结尾,则分数低于以 ( 或 [ 结尾的情况 。这是有道理的,因为前者更可能表明早已「完成」,而后者清楚地表明用户将从自动补全中受益。
Copilot Panel
主要模块:https://thakkarparth007.github.io/copilot-explorer/codeviz/templates/code-viz.html#m2990&pos=12:1
Core logic 1:https://thakkarparth007.github.io/copilot-explorer/codeviz/templates/code-viz.html#m893&pos=9:1
Core logic 2:https://thakkarparth007.github.io/copilot-explorer/codeviz/templates/code-viz.html#m2388&pos=67:1
与 Inline UI 相比,此 UI 会从模型中请求更多样本(默认情况下为 10 个)。这个 UI 似乎没有上下文过滤逻辑(有道理,如果用户明确调用它,你不会想不 prompt 该模型)。
这里主要有两件有趣的事情:
- 根据调用它的模式(OPEN_COPILOT/TODO_QUICK_FIX/UNKNOWN_FUNCTION_QUICK_FIX),它会略微修改 prompt。不要问我这些模式是如何激活的。
- 它从模型中请求 logprobs,解决方案列表按 mean logprobs 分类排序。
不显示无用的补全建议:
在(通过任一 UI)显示建议之前,Copilot 执行两个检查:
如果输出是重复的(如:foo = foo = foo = foo...),这是语言模型的常见失败模式,那么这个建议会被丢弃。这在 Copilot proxy server 或客户端都有可能发生。
如果用户已经打出了该建议,该建议也会被丢弃。
秘诀 3:telemetry
Github 在之前的一篇博客中声称,程序员编写的代码中有 40% 是由 Copilot 编写的(适用于 Python 等流行语言)。我很好奇他们是如何测出这个数字的,所以想在 telemetry 代码中插入一些内容。
我还想知道它收集了哪些 telemetry 数据,尤其是是否收集了代码片段。我想知道这一点,因为虽然我们可以轻松地将 Copilot 扩展指向开源 FauxPilot 后端而不是 Github 后端,该扩展可能仍然会通过 telemetry 发送代码片段到 Github,让一些对代码隐私有疑虑的人放弃使用 Copilot。我想知道情况是不是这样。
问题一:40% 的数字是如何测量的?
衡量 Copilot 的成功率不仅仅是简单地计算接受数 / 拒绝数的问题,因为人们通常都会接受推荐并进行一些修改。因此,Github 的工作人员会检查被接受的建议是否仍然存在于代码中。具体来说,他们会在建议代码被插入之后的 15 秒、30 秒、2 分钟、5 分钟、10 分钟进行检查。
现在,对已接受的建议进行精确搜索过于严格,因此他们会测量建议的文本和插入点周围的窗口之间的编辑距离(在字符级别和单词级别)。如果插入和窗口之间的「单词」级编辑距离小于 50%(归一化为建议大小),则该建议被视为「仍在代码中」。
当然,这一切只针对已接受代码。
问题二:telemetry 数据包含代码片段吗?
是的,包含。
在接受或拒绝建议 30 秒后,copilot 会在插入点附近「捕获」一份快照。具体来说,该扩展会调用 prompt extraction 机制来收集一份「假设 prompt」,该 prompt 可以用于在该插入点提出建议。copilot 还通过捕获插入点和所「猜测」的终结点之间的代码来捕获「假设 completion」。我不太明白它是怎么猜测这个端点的。如前所述,这发生在接受或拒绝之后。
我怀疑这些快照可能会被用作进一步改进模型的训练数据。然而,对于假设代码是否「稳定下来」,30 秒似乎太短了。但我猜,考虑到 telemetry 包含与用户项目对应的 github repo,即使 30 秒的时间内会产生嘈杂的数据点,GitHub 的工作人员也可以离线清理这些相对嘈杂的数据。当然,所有这些都只是我的猜测。
注意,GitHub 会让你选择是否同意用你的代码片段「改进产品」,如果你不同意,包含这些片段的 telemetry 就不会被发送到服务器上(至少在我检查的 v1.57 中是这样,但我也验证了 v1.65)。在它们通过网络发送之前,我通过查看代码和记录 telemetry 数据点来检查这一点。
其他观察结果
我稍微修改了扩展代码以启用 verbose logging(找不到可配置的参数)。我发现这个模型叫做「cushman-ml」,这强烈地暗示了 Copilot 使用的可能是 12B 参数模型而不是 175B 参数模型。对于开源工作者来说,这是非常令人鼓舞的,这意味着一个中等大小的模型就可以提供如此优秀的建议。当然,Github 所拥有的巨量数据对于开源工作者来说仍然难以获得。
在本文中,我没有介绍随扩展一起发布的 worker.js 文件。乍一看,它似乎基本上只提供了 prompt-extraction logic 的并行版本,但它可能还有更多的功能。
文件地址:https://thakkarparth007.github.io/copilot-explorer/muse/github.copilot-1.57.7193/dist/worker_expanded.js
启用 verbose logging
如果你想启用 verbose logging,你可以通过修改扩展代码来实现:
- 搜索扩展文件。它通常在~/.vscode/extensions/github.copilot-
/dist/extension.js 下。 - 搜索字符串 shouldLog (e,t,n){ ,如果找不到,也可以尝试 shouldLog ( 。在几个搜索匹配中,其中一个将是非空函数定义。
- 在函数体的开头,添加 return true。
如果你想要一个现成的 patch,只需复制扩展代码:https://thakkarparth007.github.io/copilot-explorer/muse/github.copilot-1.57.7193/dist/extension.js
注意,这是针对 1.57.7193 版本的。
原文中有更多细节链接,感兴趣的读者可以查看原文。
以上是对Copilot进行逆向工程之后,我发现它可能只用了参数量12B的小模型的详细内容。更多信息请关注PHP中文网其他相关文章!