
Python虚拟机中整型的实现原理是什么

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2023-04-18 09:18:481432浏览
数据结构
在 cpython 内部的 int 类型的实现数据结构如下所示:
typedef struct _longobject PyLongObject;
struct _longobject {
PyObject_VAR_HEAD
digit ob_digit[1];
};
#define PyObject_VAR_HEAD PyVarObject ob_base;
typedef struct {
PyObject ob_base;
Py_ssize_t ob_size; /* Number of items in variable part */
} PyVarObject;
typedef struct _object {
_PyObject_HEAD_EXTRA
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
} PyObject;上面的数据结构用图的方式表示出来如下图所示:
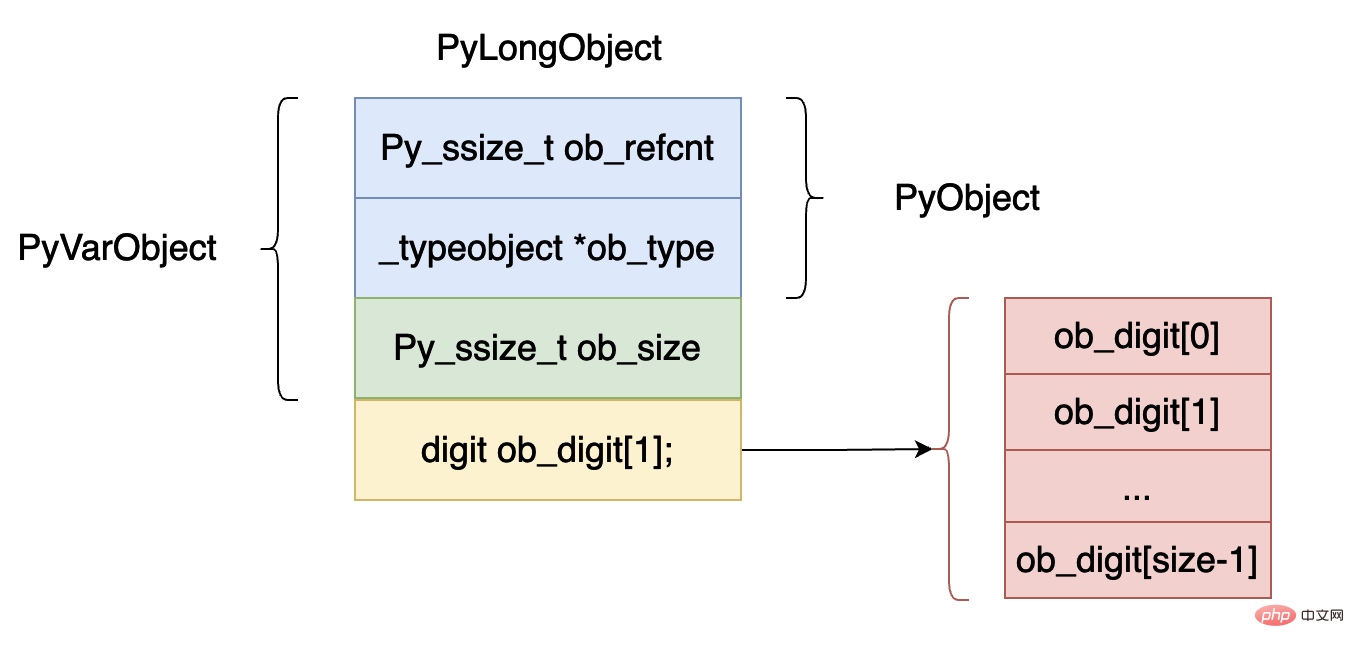
ob_refcnt,表示对象的引用记数的个数,这个对于垃圾回收很有用处,后面我们分析虚拟机中垃圾回收部分在深入分析。
ob_type,表示这个对象的数据类型是什么,在 python 当中有时候需要对数据的数据类型进行判断比如 isinstance, type 这两个关键字就会使用到这个字段。
ob_size,这个字段表示这个整型对象数组 ob_digit 当中一共有多少个元素。
digit 类型其实就是 uint32_t 类型的一个 宏定义,表示 32 位的整型数据。
深入分析 PyLongObject 字段的语意
首先我们知道在 python 当中的整数是不会溢出的,这正是 PyLongObject 使用数组的原因。在 cpython 内部的实现当中,整数有 0 、正数、负数,对于这一点在 cpython 当中有以下几个规定:
ob_size,保存的是数组的长度,ob_size 大于 0 时保存的是正数,当 ob_size 小于 0 时保存的是负数。
ob_digit,保存的是整数的绝对值。在前面我们谈到了,ob_digit 是一个 32 位的数据,但是在 cpython 内部只会使用其中的前 30 位,这只为了避免溢出的问题。
我们下面使用几个例子来深入理解一下上面的规则:
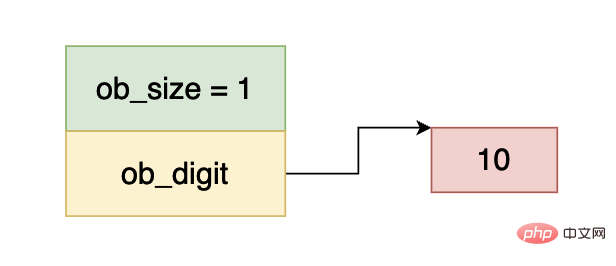
在上图当中 ob_size 大于 0 ,说明这个数是一个正数,而 ob_digit 指向一个 int32 的数据,数的值等于 10,因此上面这个数表示整数 10 。
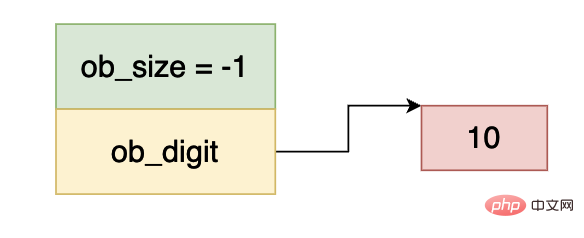
同理 ob_size 小于 0,而 ob_digit 等于 10,因此上图当中的数据表示 -10 。

上面是一个 ob_digit 数组长度为 2 的例子,上面所表示数据如下所示:
1⋅20+1⋅21+1⋅22+...+1⋅229+0⋅230+0⋅231+1⋅232
因为对于每一个数组元素来说我们只使用前 30 位,因此到第二个整型数据的时候正好对应着 230,大家可以对应着上面的结果了解整个计算过程。

上面也就很简单了:
−(1⋅20+1⋅21+1⋅22+...+1⋅229+0⋅230+0⋅231+1⋅232)
小整数池
为了避免频繁的创建一些常用的整数,加快程序执行的速度,我们可以将一些常用的整数先缓存起来,如果需要的话就直接将这个数据返回即可。在 cpython 当中相关的代码如下所示:(小整数池当中缓存数据的区间为[-5, 256])
#define NSMALLPOSINTS 257 #define NSMALLNEGINTS 5 static PyLongObject small_ints[NSMALLNEGINTS + NSMALLPOSINTS];
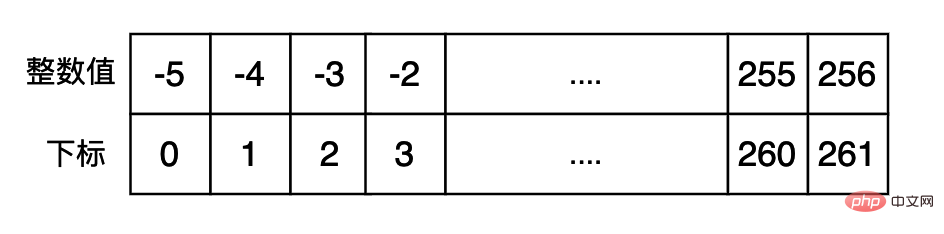
我们使用下面的代码进行测试,看是否使用了小整数池当中的数据,如果使用的话,对于使用小整数池当中的数据,他们的 id() 返回值是一样的,id 这个内嵌函数返回的是 python 对象的内存地址。
>>> a = 1 >>> b = 2 >>> c = 1 >>> id(a), id(c) (4343136496, 4343136496) >>> a = -6 >>> c = -6 >>> id(a), id(c) (4346020624, 4346021072) >>> a = 257 >>> b = 257 >>> id(a), id(c) (4346021104, 4346021072) >>>
从上面的结果我们可以看到的是,对于区间[-5, 256]当中的值,id 的返回值确实是一样的,不在这个区间之内的返回值就是不一样的。
我们还可以这个特性实现一个小的 trick,就是求一个 PyLongObject 对象所占的内存空间大小,因为我们可以使用 -5 和 256 这两个数据的内存首地址,然后将这个地址相减就可以得到 261 个 PyLongObject 所占的内存空间大小(注意虽然小整数池当中一共有 262 个数据,但是最后一个数据是内存首地址,并不是尾地址,因此只有 261 个数据),这样我们就可以求一个 PyLongObject 对象的内存大小。
>>> a = -5 >>> b = 256 >>> (id(b) - id(a)) / 261 32.0 >>>
从上面的输出结果我们可以看到一个 PyLongObject 对象占 32 个字节。我们可以使用下面的 C 程序查看一个 PyLongObject 真实所占的内存空间大小。
#include "Python.h"
#include <stdio.h>
int main()
{
printf("%ld\n", sizeof(PyLongObject));
return 0;
}上面的程序的输出结果如下所示:

上面两个结果是相等的,因此也验证了我们的想法。
从小整数池当中获取数据的核心代码如下所示:
static PyObject *
get_small_int(sdigit ival)
{
PyObject *v;
assert(-NSMALLNEGINTS <= ival && ival < NSMALLPOSINTS);
v = (PyObject *)&small_ints[ival + NSMALLNEGINTS];
Py_INCREF(v);
return v;
}整数的加法实现
如果你了解过大整数加法就能够知道,大整数加法的具体实现过程了,在 cpython 内部的实现方式其实也是一样的,就是不断的进行加法操作然后进行进位操作。
#define Py_ABS(x) ((x) < 0 ? -(x) : (x)) // 返回 x 的绝对值
#define PyLong_BASE ((digit)1 << PyLong_SHIFT)
#define PyLong_MASK ((digit)(PyLong_BASE - 1))
static PyLongObject *
x_add(PyLongObject *a, PyLongObject *b)
{
// 首先获得两个整型数据的 size
Py_ssize_t size_a = Py_ABS(Py_SIZE(a)), size_b = Py_ABS(Py_SIZE(b));
PyLongObject *z;
Py_ssize_t i;
digit carry = 0;
// 确保 a 保存的数据 size 是更大的
/* Ensure a is the larger of the two: */
if (size_a < size_b) {
{ PyLongObject *temp = a; a = b; b = temp; }
{ Py_ssize_t size_temp = size_a;
size_a = size_b;
size_b = size_temp; }
}
// 创建一个新的 PyLongObject 对象,而且数组的长度是 size_a + 1
z = _PyLong_New(size_a+1);
if (z == NULL)
return NULL;
// 下面就是整个加法操作的核心
for (i = 0; i < size_b; ++i) {
carry += a->ob_digit[i] + b->ob_digit[i];
// 将低 30 位的数据保存下来
z->ob_digit[i] = carry & PyLong_MASK;
// 将 carry 右移 30 位,如果上面的加法有进位的话 刚好可以在下一次加法当中使用(注意上面的 carry)
// 使用的是 += 而不是 =
carry >>= PyLong_SHIFT; // PyLong_SHIFT = 30
}
// 将剩下的长度保存 (因为 a 的 size 是比 b 大的)
for (; i < size_a; ++i) {
carry += a->ob_digit[i];
z->ob_digit[i] = carry & PyLong_MASK;
carry >>= PyLong_SHIFT;
}
// 最后保存高位的进位
z->ob_digit[i] = carry;
return long_normalize(z); // long_normalize 这个函数的主要功能是保证 ob_size 保存的是真正的数据的长度 因为可以是一个正数加上一个负数 size 还变小了
}
PyLongObject *
_PyLong_New(Py_ssize_t size)
{
PyLongObject *result;
/* Number of bytes needed is: offsetof(PyLongObject, ob_digit) +
sizeof(digit)*size. Previous incarnations of this code used
sizeof(PyVarObject) instead of the offsetof, but this risks being
incorrect in the presence of padding between the PyVarObject header
and the digits. */
if (size > (Py_ssize_t)MAX_LONG_DIGITS) {
PyErr_SetString(PyExc_OverflowError,
"too many digits in integer");
return NULL;
}
// offsetof 会调用 gcc 的一个内嵌函数 __builtin_offsetof
// offsetof(PyLongObject, ob_digit) 这个功能是得到 PyLongObject 对象 字段 ob_digit 之前的所有字段所占的内存空间的大小
result = PyObject_MALLOC(offsetof(PyLongObject, ob_digit) +
size*sizeof(digit));
if (!result) {
PyErr_NoMemory();
return NULL;
}
// 将对象的 result 的引用计数设置成 1
return (PyLongObject*)PyObject_INIT_VAR(result, &PyLong_Type, size);
}
static PyLongObject *
long_normalize(PyLongObject *v)
{
Py_ssize_t j = Py_ABS(Py_SIZE(v));
Py_ssize_t i = j;
while (i > 0 && v->ob_digit[i-1] == 0)
--i;
if (i != j)
Py_SIZE(v) = (Py_SIZE(v) < 0) ? -(i) : i;
return v;
}以上是Python虚拟机中整型的实现原理是什么的详细内容。更多信息请关注PHP中文网其他相关文章!