



如今,转换器(Transformers)成为大多数先进的自然语言处理(NLP)和计算机视觉(CV)体系结构中的关键模块。然而,表格式数据领域仍然主要以梯度提升决策树(GBDT)算法为主导。于是,有人试图弥合这一差距。其中,第一篇基于转换器的表格数据建模论文是由Huang等人于2020年发表的论文《TabTransformer:使用上下文嵌入的表格数据建模》。
本文旨在提供该论文内容的基本展示,同时将深入探讨TabTransformer模型的实现细节,并向您展示如何针对我们自己的数据来具体使用TabTransformer。
一、论文概述
上述论文的主要思想是,如果使用转换器将常规的分类嵌入转换为上下文嵌入,那么,常规的多层感知器(MLP)的性能将会得到显著提高。接下来,让我们更为深入地理解这一描述。
1.分类嵌入(Categorical Embeddings)
在深度学习模型中,使用分类特征的经典方法是训练其嵌入性。这意味着,每个类别值都有一个唯一的密集型向量表示,并且可以传递给下一层。例如,由下图您可以看到,每个分类特征都使用一个四维数组表示。然后,这些嵌入与数字特征串联,并用作MLP的输入。
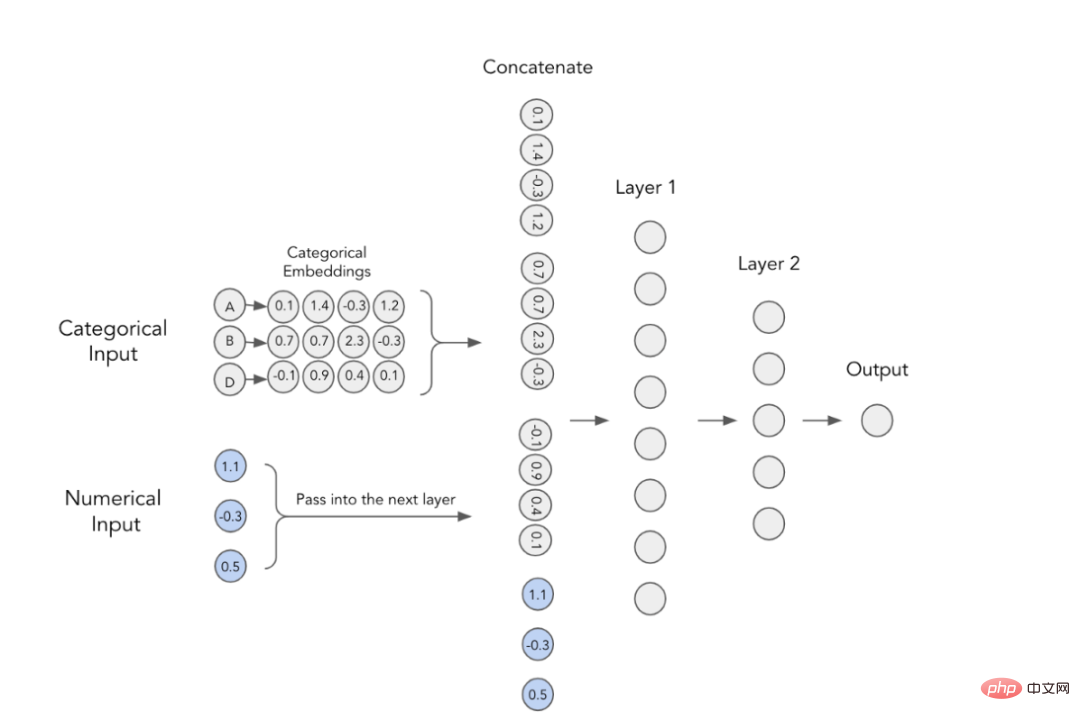
带有分类嵌入的MLP
2.上下文嵌入(Contextual Embeddings)
论文作者认为,分类嵌入缺乏上下文含义,即它们并没有对分类变量之间的任何交互和关系信息进行编码。为了将嵌入内容更加具体化,有人建议使用NLP领域当前所使用的转换器来实现这一目的。
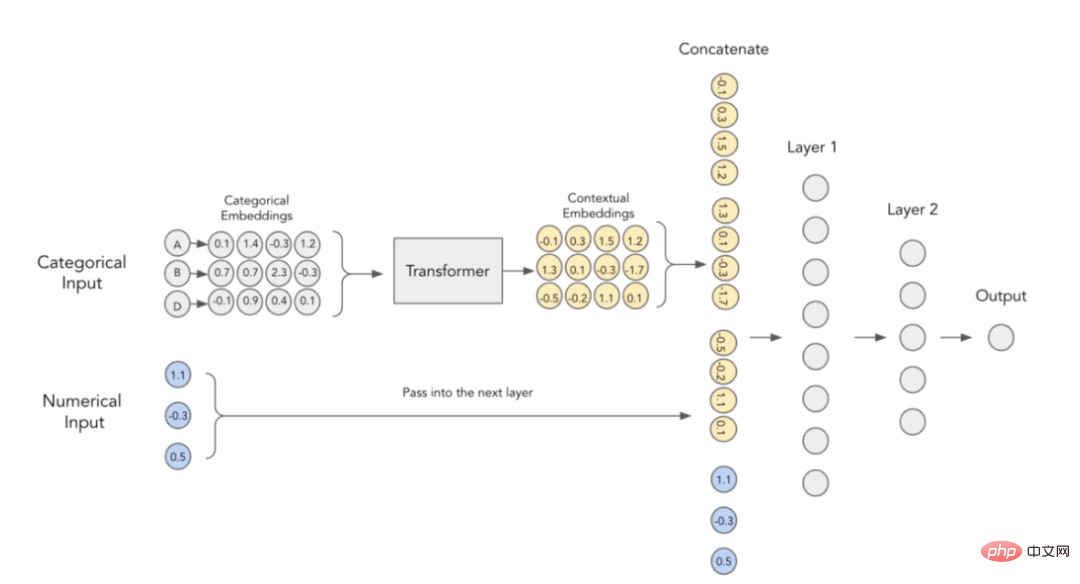
TabTransformer转换器中的上下文嵌入
为了以可视化方式形象地展示上述想法,我们不妨考虑下面这个训练后得到的上下文嵌入图像。其中,突出显示了两个分类特征:关系(黑色)和婚姻状况(蓝色)。这些特征是相关的;所以,“已婚(Married)”、“丈夫(Husband)”和“妻子(Wife)”的值应该在向量空间中彼此接近,即使它们来自不同的变量。
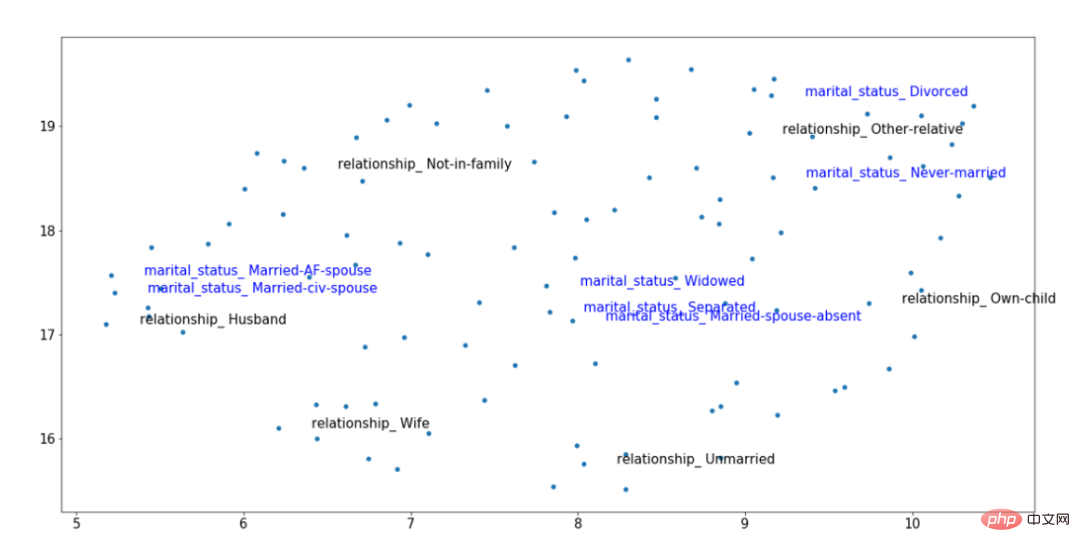
经训练后的TabTransformer转换器嵌入结果示例
通过上图中经过训练的上下文嵌入结果,我们可以看到,“已婚(Married)”的婚姻状况更接近“丈夫(Husband)”和“妻子(Wife)”的关系水平,而“未结婚(non-married)”的分类值则来自右侧的单独数据簇。这种类型的上下文使这样的嵌入更加有用,而使用简单形式的类别嵌入技术是不可能实现这种效果的。
3.TabTransformer架构
为了达到上述目的,论文作者提出了以下架构:
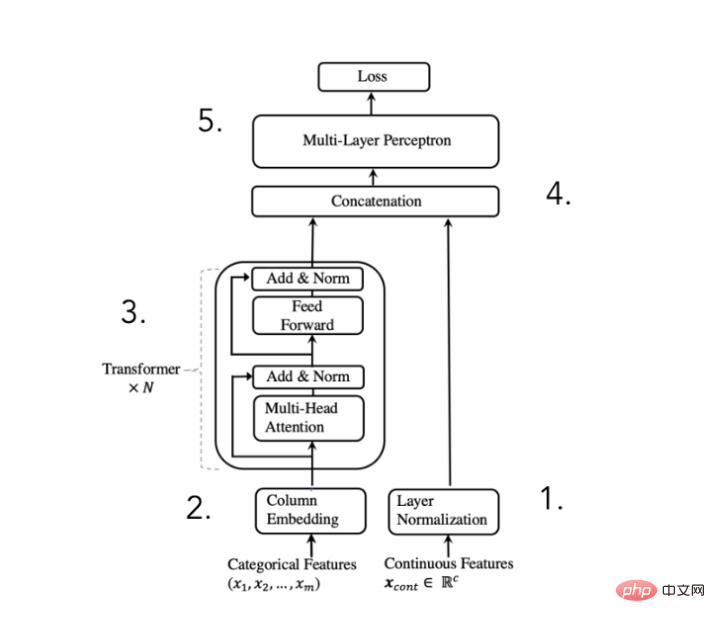
TabTransformer转换器架构示意图
(摘取自Huang等人2020年发表的论文)
我们可以将此体系结构分解为5个步骤:
- 标准化数字特征并向前传递
- 嵌入分类特征
- 嵌入经过N次转换器块处理,以便获得上下文嵌入
- 把上下文分类嵌入与数字特征进行串联
- 通过MLP进行串联获得所需的预测
虽然模型架构非常简单,但论文作者表示,添加转换器层可以显著提高计算性能。当然,所有的“魔术”发生在这些转换器块内部;所以,接下来让我们更加详细地研究一下其中的实现过程。
4.转换器
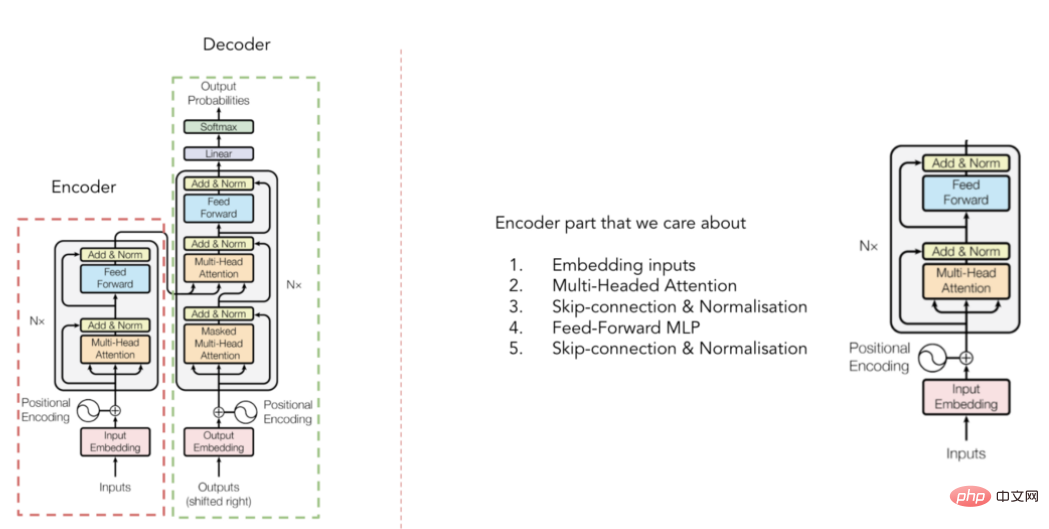
转换器(Transformer)架构示意
(选自Vaswani等人于2017年发表的论文)
您可能以前见过转换器架构,但为了快速介绍起见,请记住该转换器是由编码器和解码器两部分组成(见上图)。对于TabTransformer,我们只关心将输入的嵌入内容上下文化的编码器部分(解码器部分将这些嵌入内容转换为最终输出结果)。但它到底是如何做到的呢?答案是——多头注意力机制。
5.多头注意力机制(Multi-head-attention)
引用我最喜欢的关于注意力机制的文章的描述,是这样的:
“自我关注(self attention)背后的关键概念是,这种机制允许神经网络学习如何在输入序列的各个片段之间以最好的路由方案进行信息调度。”
换句话说,自我关注(self-attention)有助于模型找出在表示某个单词/类别时,输入的哪些部分更重要,哪些部分相对不重要。为此,我强烈建议您阅读一下上面引用的这篇文章,以便对自我关注为什么如此有效有一个更为直观的理解。
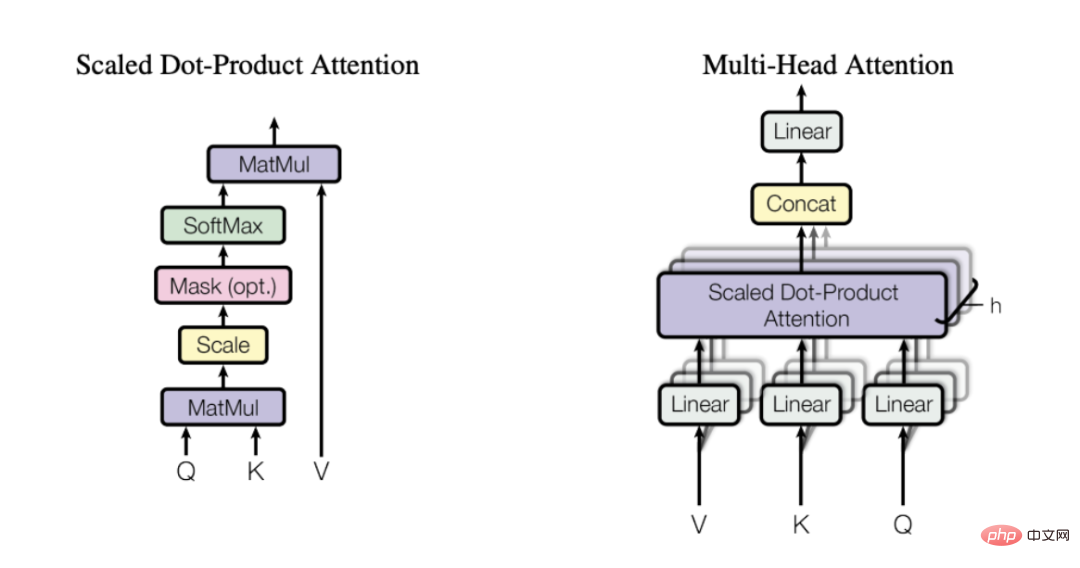
多头注意力机制
(选自Vaswani等人于2017年发表的论文)
注意力是通过3个学习过的矩阵来计算的——Q、K和V,它们代表查询(Query)、键(Key)和值(Value)。首先,我们将矩阵Q和K相乘得到注意力矩阵。该矩阵被缩放并通过softmax层传递。然后,我们将其乘以V矩阵,得出最终值。为了更直观地理解起见,请考虑下面的示意图,它显示了我们如何使用矩阵Q、K和V实现从输入嵌入转换到上下文嵌入。
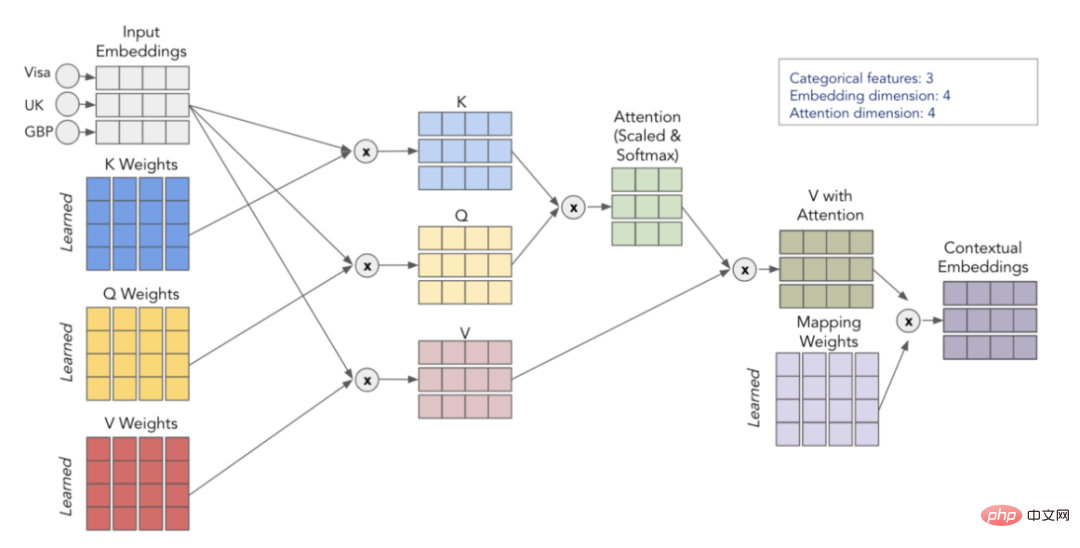
自我关注流程可视化
通过重复该过程h次(使用不同的Q、K、V矩阵),我们就能够得到多个上下文嵌入,它们形成我们最终的多头注意力。
6.简短回顾
让我们总结一下上面所介绍的内容:
- 简单的分类嵌入不包含上下文信息
- 通过转换器编码器传递分类嵌入,我们就能够将嵌入上下文化
- 转换器部分能够将嵌入上下文化,因为它使用了多头注意力机制
- 多头注意力机制在编码变量时使用矩阵Q、K和V来寻找有用的相互作用和相关性信息
- 在TabTransformer中,被上下文化的嵌入与数字输入相串联,并通过一个简单的MLP输出预测
虽然TabTransformer背后的想法很简单,但您可能需要一些时间才能掌握注意力机制。因此,我强烈建议您重新阅读以上解释。如果您感到有些迷茫,请认真阅读本文中所有建议的链接相关内容。我保证,做到这些后,您就不难搞明白注意力机制的原理了。
7.试验结果展示
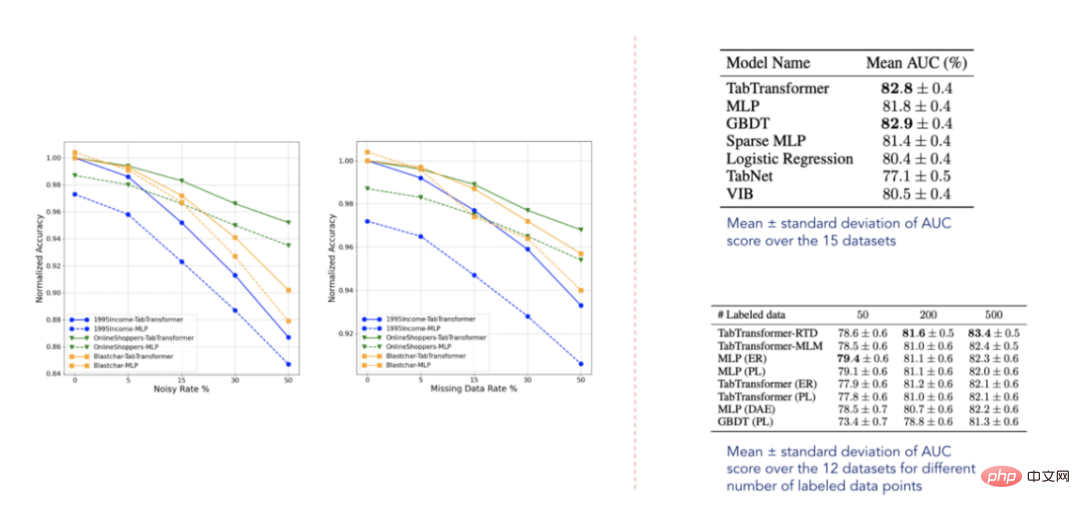
结果数据(选自Huang等人2020年发表的论文)
根据报告的结果,TabTransformer转换器优于所有其他深度学习表格模型,此外,它接近GBDT的性能水平,这非常令人鼓舞。该模型对缺失数据和噪声数据也相对稳健,并且在半监督环境下优于其他模型。然而,这些数据集显然不是详尽无遗的,正如以后发表的一些相关论文所证实的那样,仍有很大的改进空间。
二、构建我们自己的示例程序
现在,让我们最终来确定一下如何将模型应用于我们自己的数据。接下来的示例数据取自著名的Tabular Playground Kaggle比赛。为了方便使用TabTransformer转换器,我创建了一个tabtransformertf包。它可以使用如下pip命令进行安装:
pip install tabtransformertf
并允许我们使用该模型,而无需进行大量预处理。
1.数据预处理
第一步是设置适当的数据类型,并将我们的训练和验证数据转换为TF数据集。其中,前面安装的软件包中就提供了一个很好的实用程序可以做到这一点。
from tabtransformertf.utils.preprocessing import df_to_dataset, build_categorical_prep # 设置数据类型 train_data[CATEGORICAL_FEATURES] = train_data[CATEGORICAL_FEATURES].astype(str) val_data[CATEGORICAL_FEATURES] = val_data[CATEGORICAL_FEATURES].astype(str) train_data[NUMERIC_FEATURES] = train_data[NUMERIC_FEATURES].astype(float) val_data[NUMERIC_FEATURES] = val_data[NUMERIC_FEATURES].astype(float) # 转换成TF数据集 train_dataset = df_to_dataset(train_data[FEATURES + [LABEL]], LABEL, batch_size=1024) val_dataset = df_to_dataset(val_data[FEATURES + [LABEL]], LABEL, shuffle=False, batch_size=1024)
下一步是为分类数据准备预处理层。该分类数据稍后将被传递给我们的主模型。
from tabtransformertf.utils.preprocessing import build_categorical_prep
category_prep_layers = build_categorical_prep(train_data, CATEGORICAL_FEATURES)
# 输出结果是一个字典结构,其中键部分是特征名称,值部分是StringLookup层
# category_prep_layers ->
# {'product_code': <keras.layers.preprocessing.string_lookup.StringLookup at 0x7f05d28ee4e0>,
#'attribute_0': <keras.layers.preprocessing.string_lookup.StringLookup at 0x7f05ca4fb908>,
#'attribute_1': <keras.layers.preprocessing.string_lookup.StringLookup at 0x7f05ca4da5f8>}
这就是预处理!现在,我们可以开始构建模型了。
2.构建TabTransformer模型
初始化模型很容易。其中,有几个参数需要指定,但最重要的几个参数是:embeding_dim、depth和heads。所有参数都是在超参数调整后选择的。
from tabtransformertf.models.tabtransformer import TabTransformer tabtransformer = TabTransformer( numerical_features = NUMERIC_FEATURES,# 带有数字特征名称的列表 categorical_features = CATEGORICAL_FEATURES, # 带有分类特征名称的列表 categorical_lookup=category_prep_layers, # 带StringLookup层的Dict numerical_discretisers=None,# None代表我们只是简单地传递数字特征 embedding_dim=32,# 嵌入维数 out_dim=1,# Dimensionality of output (binary task) out_activatinotallow='sigmoid',# 输出层激活 depth=4,# 转换器块层的个数 heads=8,# 转换器块中注意力头的个数 attn_dropout=0.1,# 在转换器块中的丢弃率 ff_dropout=0.1,# 在最后MLP中的丢弃率 mlp_hidden_factors=[2, 4],# 我们为每一层划分最终嵌入的因子 use_column_embedding=True,#如果我们想使用列嵌入,设置此项为真 ) # 模型运行中摘要输出: # 总参数个数: 1,778,884 # 可训练的参数个数: 1,774,064 # 不可训练的参数个数: 4,820
模型初始化后,我们可以像任何其他Keras模型一样安装它。训练参数也可以调整,所以可以随意调整学习速度和提前停止。
LEARNING_RATE = 0.0001 WEIGHT_DECAY = 0.0001 NUM_EPOCHS = 1000 optimizer = tfa.optimizers.AdamW( learning_rate=LEARNING_RATE, weight_decay=WEIGHT_DECAY ) tabtransformer.compile( optimizer = optimizer, loss = tf.keras.losses.BinaryCrossentropy(), metrics= [tf.keras.metrics.AUC(name="PR AUC", curve='PR')], ) out_file = './tabTransformerBasic' checkpoint = ModelCheckpoint( out_file, mnotallow="val_loss", verbose=1, save_best_notallow=True, mode="min" ) early = EarlyStopping(mnotallow="val_loss", mode="min", patience=10, restore_best_weights=True) callback_list = [checkpoint, early] history = tabtransformer.fit( train_dataset, epochs=NUM_EPOCHS, validation_data=val_dataset, callbacks=callback_list )
3.评价
竞赛中最关键的指标是ROC AUC。因此,让我们将其与PR AUC指标一起输出来评估一下模型的性能。
val_preds = tabtransformer.predict(val_dataset)
print(f"PR AUC: {average_precision_score(val_data['isFraud'], val_preds.ravel())}")
print(f"ROC AUC: {roc_auc_score(val_data['isFraud'], val_preds.ravel())}")
# PR AUC: 0.26
# ROC AUC: 0.58您也可以自己给测试集评分,然后将结果值提交给Kaggle官方。我现在选择的这个解决方案使我跻身前35%,这并不坏,但也不太好。那么,为什么TabTransfromer在上述方案中表现不佳呢?可能有以下几个原因:
- 数据集太小,而深度学习模型以需要大量数据著称
- TabTransformer很容易在表格式数据示例领域出现过拟合
- 没有足够的分类特征使模型有用
三、结论
本文探讨了TabTransformer背后的主要思想,并展示了如何使用Tabtransformertf包来具体应用此转换器。
归纳起来看,TabTransformer的确是一种有趣的体系结构,它在当时的表现明显优于大多数深度表格模型。它的主要优点是将分类嵌入语境化,从而增强其表达能力。它使用在分类特征上的多头注意力机制来实现这一点,而这是在表格数据领域使用转换器的第一个应用实例。
TabTransformer体系结构的一个明显缺点是,数字特征被简单地传递到最终的MLP层。因此,它们没有语境化,它们的价值也没有在分类嵌入中得到解释。在下一篇文章中,我将探讨如何修复此缺陷并进一步提高性能。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文链接:https://towardsdatascience.com/transformers-for-tabular-data-tabtransformer-deep-dive-5fb2438da820?source=collection_home---------4----------------------------
以上是TabTransformer转换器提升多层感知机性能深度解析的详细内容。更多信息请关注PHP中文网其他相关文章!

 您必须在无知的面纱后面建立工作场所Apr 29, 2025 am 11:15 AM
您必须在无知的面纱后面建立工作场所Apr 29, 2025 am 11:15 AM在约翰·罗尔斯1971年具有开创性的著作《正义论》中,他提出了一种思想实验,我们应该将其作为当今人工智能设计和使用决策的核心:无知的面纱。这一理念为理解公平提供了一个简单的工具,也为领导者如何利用这种理解来公平地设计和实施人工智能提供了一个蓝图。 设想一下,您正在为一个新的社会制定规则。但有一个前提:您事先不知道自己在这个社会中将扮演什么角色。您最终可能富有或贫穷,健康或残疾,属于多数派或边缘少数群体。在这种“无知的面纱”下运作,可以防止规则制定者做出有利于自身的决策。相反,人们会更有动力制定公
 决策,决策……实用应用AI的下一步Apr 29, 2025 am 11:14 AM
决策,决策……实用应用AI的下一步Apr 29, 2025 am 11:14 AM许多公司专门从事机器人流程自动化(RPA),提供机器人以使重复性任务自动化 - UIPATH,在任何地方自动化,蓝色棱镜等。 同时,过程采矿,编排和智能文档处理专业
 代理人来了 - 更多关于我们将在AI合作伙伴旁边做什么Apr 29, 2025 am 11:13 AM
代理人来了 - 更多关于我们将在AI合作伙伴旁边做什么Apr 29, 2025 am 11:13 AMAI的未来超越了简单的单词预测和对话模拟。 AI代理人正在出现,能够独立行动和任务完成。 这种转变已经在诸如Anthropic的Claude之类的工具中很明显。 AI代理:研究
 为什么同情在AI驱动的未来中对领导者更重要Apr 29, 2025 am 11:12 AM
为什么同情在AI驱动的未来中对领导者更重要Apr 29, 2025 am 11:12 AM快速的技术进步需要对工作未来的前瞻性观点。 当AI超越生产力并开始塑造我们的社会结构时,会发生什么? Topher McDougal即将出版的书Gaia Wakes:
 用于产品分类的AI:机器可以总税法吗?Apr 29, 2025 am 11:11 AM
用于产品分类的AI:机器可以总税法吗?Apr 29, 2025 am 11:11 AM产品分类通常涉及复杂的代码,例如诸如统一系统(HS)等系统的“ HS 8471.30”,对于国际贸易和国内销售至关重要。 这些代码确保正确的税收申请,影响每个INV
 数据中心的需求会引发气候技术反弹吗?Apr 29, 2025 am 11:10 AM
数据中心的需求会引发气候技术反弹吗?Apr 29, 2025 am 11:10 AM数据中心能源消耗与气候科技投资的未来 本文探讨了人工智能驱动的数据中心能源消耗激增及其对气候变化的影响,并分析了应对这一挑战的创新解决方案和政策建议。 能源需求的挑战: 大型超大规模数据中心耗电量巨大,堪比数十万个普通北美家庭的总和,而新兴的AI超大规模中心耗电量更是数十倍于此。2024年前八个月,微软、Meta、谷歌和亚马逊在AI数据中心建设和运营方面的投资已达约1250亿美元(摩根大通,2024)(表1)。 不断增长的能源需求既是挑战也是机遇。据Canary Media报道,迫在眉睫的电
 AI和好莱坞的下一个黄金时代Apr 29, 2025 am 11:09 AM
AI和好莱坞的下一个黄金时代Apr 29, 2025 am 11:09 AM生成式AI正在彻底改变影视制作。Luma的Ray 2模型,以及Runway的Gen-4、OpenAI的Sora、Google的Veo等众多新模型,正在以前所未有的速度提升生成视频的质量。这些模型能够轻松制作出复杂的特效和逼真的场景,甚至连短视频剪辑和具有摄像机感知的运动效果也已实现。虽然这些工具的操控性和一致性仍有待提高,但其进步速度令人惊叹。 生成式视频正在成为一种独立的媒介形式。一些模型擅长动画制作,另一些则擅长真人影像。值得注意的是,Adobe的Firefly和Moonvalley的Ma
 Chatgpt是否会慢慢成为AI最大的Yes-Man?Apr 29, 2025 am 11:08 AM
Chatgpt是否会慢慢成为AI最大的Yes-Man?Apr 29, 2025 am 11:08 AMChatGPT用户体验下降:是模型退化还是用户期望? 近期,大量ChatGPT付费用户抱怨其性能下降,引发广泛关注。 用户报告称模型响应速度变慢,答案更简短、缺乏帮助,甚至出现更多幻觉。一些用户在社交媒体上表达了不满,指出ChatGPT变得“过于讨好”,倾向于验证用户观点而非提供批判性反馈。 这不仅影响用户体验,也给企业客户带来实际损失,例如生产力下降和计算资源浪费。 性能下降的证据 许多用户报告了ChatGPT性能的显着退化,尤其是在GPT-4(即将于本月底停止服务)等旧版模型中。 这


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

SublimeText3汉化版
中文版,非常好用

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

