



译者 | 朱先忠
审校 | 孙淑娟
在经典的机器学习中,随机森林(Random Forests)算法可谓是一种“银弹”类型的算法模型。
该模型之所以很棒,有如下几个原因:
- 与其他许多算法相比,需要更少的数据预处理,这使得该算法设置起来更容易
- 可以充当分类或回归模型
- 不易过度拟合
- 能够轻松计算出特征的重要程度
在这篇文章中,我想更好地分析一下组成随机森林算法的各个组成部分。为了实现这一点,我将把随机森林算法分解为最基本的组成部分,并解释每一组成部分计算任务的情况。到文章最后,我们就能够对随机森林算法如何工作以及如何以更直观的方式使用它们有更深入的理解。需要说明的是,本文中我们将使用的示例将侧重于分类功能,但其中的许多原则也同样适用于回归场景的应用。
运行随机森林算法
让我们首先从调用一个经典的随机森林模式开始。这是最高级别的,也是许多人在使用Python语言训练随机森林时所采用的方案。
模拟的数据
如果我想运行一个随机森林算法来预测我的目标列,那么我只需要执行以下操作:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df.drop('target', axis=1), df['target'], test_size=0.2, random_state=0)
# 训练随机森林算法并计算得分
simple_rf_model = RandomForestClassifier(n_estimators=100, random_state=0)
simple_rf_model.fit(X_train, y_train)
print(f"accuracy: {simple_rf_model.score(X_test, y_test)}")
# accuracy: 0.93运行随机森林分类器非常简单。如上面代码所示,我只是定义了n_estimators参数,并将参数random_state设置为0。我可以从个人经验告诉你,很多人都会盯着0.93这个精确度不放松。他们似乎感觉非常满意,于是轻易地开始了疯狂的部署工作。但是,我们今天不会这么做。
首先,让我们重新审视下面这一行“无伤大雅”的代码:
simple_rf_model = RandomForestClassifier(n_estimators=100, random_state=0)
随机状态是大多数数据科学模型的一个特征,它可以确保其他人可以复制您的工作。因此,我们不会太担心random_state这个参数。
但是,让我们深入研究一下n_estimators这个参数。如果我们查看一下scikit-learn中的有关文档,会找到其如下的简洁定义:
“森林中的树木数量。”
树木数量研究
现在,让我们更具体地定义一个随机森林。随机森林是一个集成模型,是许多决策树的共识内容。这个定义可能是不完整的,但我们稍后还会回来讨论它的。
许多树木间相互通信并达成共识
这可能会让你认为,如果你把它分解成以下内容,你可能会得到一个随机森林:
#创建决策树 tree1 = DecisionTreeClassifier().fit(X_train, y_train) tree2 = DecisionTreeClassifier().fit(X_train, y_train) tree3 = DecisionTreeClassifier().fit(X_train, y_train) # 预测X_test上的每一棵决策树 predictions_1 = tree1.predict(X_test) predictions_2 = tree2.predict(X_test) predictions_3 = tree3.predict(X_test) print(predictions_1, predictions_2, predictions_3) # 采取优先级策略 final_prediction = np.array([np.round((predictions_1[i] + predictions_2[i] + predictions_3[i])/3) for i in range(len(predictions_1))]) print(final_prediction)
在上面的例子中,我们在X_train上训练了3棵决策树,这意味着n_estimators=3。在训练了3棵树之后,我们在同一测试集上预测了每棵树,然后最终得到3棵树中有2棵选择的预测。
这是有道理的,但这看起来并不完全正确。如果所有的决策树都是在相同的数据上训练的,那么它们不会得出相同的结论,从而导致否定整体的优势吗?
放回抽样详解
让我们在前面的定义的基础上再补充上这样一句:“随机森林是一个集成模型,它是许多不相关决策树的共识。”
决策树可以通过两种方式变得不相关:
1. 您有足够大的数据集大小,可以将数据的独特部分采样到每个决策树中。这种方式并不流行,因为通常需要大量数据。
2. 您可以利用一种叫做放回抽样(sampling with replacement)的技术。放回抽样是指从总体中抽取的样本在抽取下一个样本之前返回到样本总体中。
为了解释放回抽样,假设我有5个3种颜色的弹珠,所以总体看起来是这样的:
blue, blue, red, green, red
如果我想取样一些弹珠,我通常会从中抽出几颗,也许最后会得到:
blue, red
这是因为一旦我拿起红色,我就没有把它放回原来的弹珠堆中。
然而,如果我用放回方式进行采样,我实际上可以两次拾取任何弹珠。因为红色回到了我的堆中,所以我仍然有机会再次捡起它。
red, red
在随机森林算法中,默认值是构建约为原始样本总体大小2/3的样本。如果我的原始训练数据是1000行,那么我输入到树中的训练数据样本可能大约是670行。也就是说,在构建随机森林时,尝试不同的采样率将是一个很好的参数。
与上一段代码不同,下面的代码更接近随机森林,其中参数n_estimators=3。
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
# 对于每一棵树从X_train中采用3次放回抽样
df_sample1 = df.sample(frac=.67, replace=True)
df_sample2 = df.sample(frac=.67, replace=True)
df_sample3 = df.sample(frac=.67, replace=True)
X_train_sample1, X_test_sample1, y_train_sample1, y_test_sample1 = train_test_split(df_sample1.drop('target', axis=1), df_sample1['target'], test_size=0.2)
X_train_sample2, X_test_sample2, y_train_sample2, y_test_sample2 = train_test_split(df_sample2.drop('target', axis=1), df_sample2['target'], test_size=0.2)
X_train_sample3, X_test_sample3, y_train_sample3, y_test_sample3 = train_test_split(df_sample3.drop('target', axis=1), df_sample3['target'], test_size=0.2)
#生成决策树
tree1 = DecisionTreeClassifier().fit(X_train_sample1, y_train_sample1)
tree2 = DecisionTreeClassifier().fit(X_train_sample2, y_train_sample2)
tree3 = DecisionTreeClassifier().fit(X_train_sample3, y_train_sample3)
# 在X_test上预测每一棵决策树
predictions_1 = tree1.predict(X_test)
predictions_2 = tree2.predict(X_test)
predictions_3 = tree3.predict(X_test)
df = pd.DataFrame([predictions_1, predictions_2, predictions_3]).T
df.columns = ["tree1", "tree2", "tree3"]
# 采取优先级策略
final_prediction = np.array([np.round((predictions_1[i] + predictions_2[i] + predictions_3[i])/3) for i in range(len(predictions_1))])
preds = pd.DataFrame([predictions_1, predictions_2, predictions_3, final_prediction, y_test]).T.head(20)
preds.columns = ["tree1", "tree2", "tree3", "final", "label"]
preds
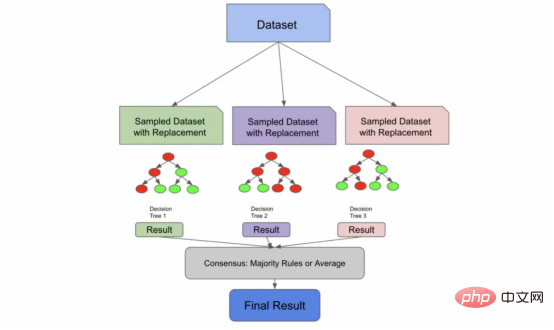
我们用放回抽样,把这些样本输送给树,产生结果,并达成共识。
袋装分类器(Bagging Classifier)
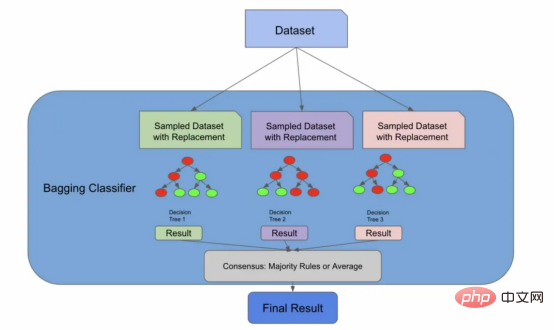
早期的架构实际上就是一个装袋分类器
我们现在将引入一种新的算法,一种称为自助聚集(Bootstrap Aggregation,也称为“Bagging”)的有监督的学习算法。但请放心,这又会与随机森林算法联系起来。我们引入这个新概念的原因是,正如我们将要在文章后面的图中看到的,我们到目前为止所做的一切实际上都是装袋分类器所做的!
在下面的代码中,装袋分类器使用了一个名为bootstrap的参数,它实际上执行了我们刚才手动执行的放回抽样步骤。其实,sklearn库的随机森林算法实现也存在相同的参数。如果bootstrap参数的值是false,那么我们将为每个分类器使用整个总体。
import numpy as np from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import BaggingClassifier # 集合中所使用的树的数量 n_estimators = 3 # 初始化装袋分类器 bag_clf = BaggingClassifier( DecisionTreeClassifier(), n_estimators=n_estimators, bootstrap=True) # 根据训练数据拟合装袋分类器 bag_clf.fit(X_train, y_train) # 对测试数据进行预测 y_pred = bag_clf.predict(X_test) pd.DataFrame([y_pred, y_test]).T
装袋分类器BaggingClassifier非常棒,因为您可以将它们与未命名为决策树的评估器一起使用!您可以插入许多算法,Bagging算法会将其转化为集成解决方案。随机森林算法实际上扩展了装袋算法(如果bootstrapping = true),因为它部分地利用Bagging算法来形成不相关的决策树。
然而,即使bootstrapping=false,随机森林算法也需要额外一步来确保树之间的不相关性——特征采样。
特征采样详解
特征采样(Feature sampling)意味着不仅对行进行采样,还对列进行采样。与行不同,随机森林的列在没有放回的情况下被采样,这意味着我们不会有重复的列来训练1棵树。
有许多方法可以对特征进行采样。您可以指定要采样的固定最大特征数量,获取特征总数的平方根,或者尝试使用日志数据。这些方法中的每一种都有各自的利弊,并将取决于您的数据和具体使用场景。
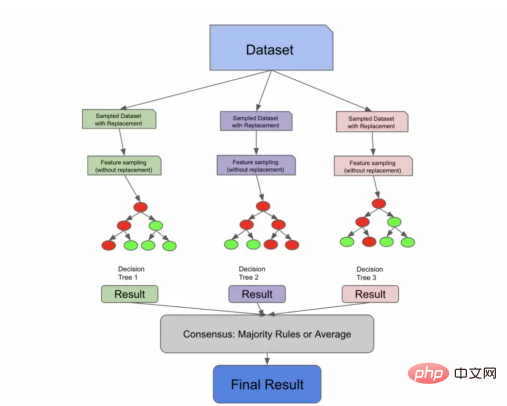
通过特征采样扩展了Bagging算法
下面的代码片段使用sqrt技术对列进行采样,对行进行采样,训练3个决策树,并使用优先级规则进行预测。我们首先使用放回进行采样,他们对列进行采样,训练我们的单个树,让我们的树根据测试数据进行预测,然后采用优先级规则实现共识。
import numpy as np
import pandas as pd
import math
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
#对于每一棵树从X_train中取3个样本
df_sample1 = df.sample(frac=.67, replace=True)
df_sample2 = df.sample(frac=.67, replace=True)
df_sample3 = df.sample(frac=.67, replace=True)
# 分割训练集
X_train_sample1, y_train_sample1 = df_sample1.drop('target', axis=1), df_sample1['target']
X_train_sample2, y_train_sample2 = df_sample2.drop('target', axis=1), df_sample2['target']
X_train_sample3, y_train_sample3 = df_sample3.drop('target', axis=1), df_sample3['target']
# 使用sqrt获取训练和测试的采样特征,现在注意replace如何等于False的
num_features = len(X_train.columns)
X_train_sample1 = X_train_sample1.sample(n=int(math.sqrt(num_features)), replace=False, axis = 1)
X_train_sample2 = X_train_sample2.sample(n=int(math.sqrt(num_features)), replace=False, axis = 1)
X_train_sample3 = X_train_sample3.sample(n=int(math.sqrt(num_features)), replace=False, axis = 1)
# 创建决策树,这次我们对列进行采样
tree1 = DecisionTreeClassifier().fit(X_train_sample1, y_train_sample1)
tree2 = DecisionTreeClassifier().fit(X_train_sample2, y_train_sample2)
tree3 = DecisionTreeClassifier().fit(X_train_sample3, y_train_sample3)
# 预测X_test上的每个决策树
predictions_1 = tree1.predict(X_test[X_train_sample1.columns])
predictions_2 = tree2.predict(X_test[X_train_sample2.columns])
predictions_3 = tree3.predict(X_test[X_train_sample3.columns])
preds = pd.DataFrame([predictions_1, predictions_2, predictions_3]).T
preds.columns = ["tree1", "tree2", "tree3"]
# 使用优先级规则
final_prediction = np.array([np.round((predictions_1[i] + predictions_2[i] + predictions_3[i])/3) for i in range(len(predictions_1))])
preds = pd.DataFrame([predictions_1, predictions_2, predictions_3, final_prediction, y_test]).T.head(20)
preds.columns = ["tree1", "tree2", "tree3", "final", "label"]当我运行这段代码时,我发现我的决策树开始预测不同的事情,这表明我们已经删除了树之间的许多相关性。
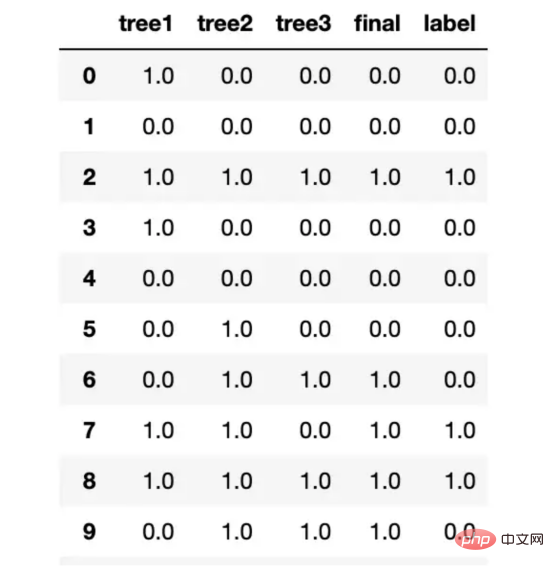
我的测试结果树之间不再总是彼此保持一致了
决策树基础
到目前为止,我们已经剖析了数据是如何被送入大量决策树的。在前面的代码示例中,我们使用DecisionTreeClassifier函数来训练决策树,但为了完全理解随机森林,我们需要先来解释一下什么是决策树。
一棵名副其实的决策树看起来像一棵倒挂的树。从一种高级别角度上看,该算法试图提出问题,并将数据分割成不同的节点。下图显示了决策树的形象示意。
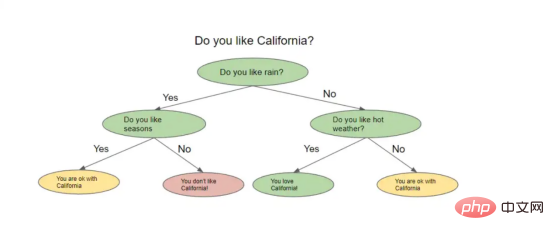
决策树示例
决策树根据前一个问题的答案提出一系列问题。对于它提出的每一个问题,可能都有多个答案,我们不妨可以将其想象为分割节点。上一个问题的答案将决定树将询问的下一个问题。在询问了一系列问题之后的某个时刻,你得到了答案。
但是你怎么知道你的答案是准确的,或者你询问了正确的问题呢?实际上,您可以用几种不同的方法来评估决策树,我们当然也会对这些方法加以解释。
熵与信息增益
介绍到现在,我们需要讨论一个叫做熵(entropy)的新术语。从一种高角度来看,熵是衡量节点中杂质或随机性水平的一种方法。顺便说一句,还有另一种流行的方法来测量节点的杂质,称为基尼系数(Gini impurity),但我们不会在本文中解析该方法,因为它与许多关于熵的概念重叠,尽管计算略有不同。一般的想法是,熵或基尼系数越高,节点中的方差越大,我们的目标是减少这种不确定性。
决策树试图通过将所询问的节点拆分为更小、更同质的节点来最小化熵。熵的实际公式是:
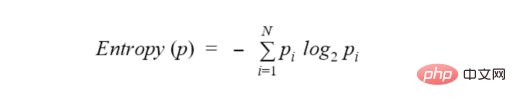
为了进一步解释熵的概念,让我们回到那个弹珠的例子:
假设我有10个弹珠。其中5个是蓝色的,5个是绿色的。我的总体数据集的熵为1.0,那么计算熵的代码如下:
from collections import Counter from math import log2 #我的预测分类为:0或者1。其中,0代表蓝色弹珠,1代表是绿色弹珠。 data = [0, 0, 0, 1, 1, 1, 1, 0, 1, 0] # 获取标签的长度 len_labels = len(data) def calculate_entropy(data, len_labels): # 对每一种分类进行计数 counts = Counter(labels) # 我们计算分数,这个例子的输出应该是[.5,.5] probs = [count / num_labels for count in counts.values()] # 实际熵计算 return - sum(p * log2(p) for p in probs) calculate_entropy(labels, num_labels)
如果数据完全充满绿色弹珠,熵将为0,并且熵将随着我们接近50%的分割而增加。
每次减少熵,我们都会获得一些关于数据集的信息,因为我们减少了随机性。信息增益告诉我们哪个特征相对来说最能让我们最小化熵。计算信息增益的方法是:
entropy(parent) — [weighted_average_of_entropy(children)]
在这种情况下,父节点是原始节点,子节点是拆分节点的结果。
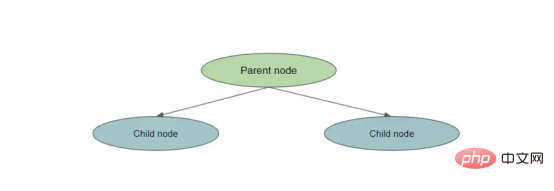
拆分一个节点
为了计算信息增益,我们执行以下操作:
- 计算父节点的熵
- 将父节点拆分为子节点
- 为每个子节点创建权重。这是通过number_of_samples_in_child_node/number_of_ssamples_in_parent_node测量的
- 计算每个子节点的熵
- 通过计算weight*entropy_of_child1+weight*entropy_of_child2创建[weighted_average_of_entropy(children)]
- 从父节点的熵中减去此加权熵
下面的代码实现了将父节点拆分为两个子节点的简单信息增益:
def information_gain(left_labels, right_labels, parent_entropy): """计算拆分的信息增益""" #计算左侧节点的权重 proportion_left_node = float(len(left_labels)) / (len(left_labels) + len(right_labels)) #计算右节点的权重 proportion_right_node = 1 - proportion_left_node # 计算子节点的加权平均值 weighted_average_of_child_nodes = ((proportion_left_node * entropy(left_labels)) + (proportion_right_node * entropy(right_labels))) #返回父节点熵——子节点的加权熵 return parent_entropy - weighted_average_of_child_nodes
决策树详解
考虑到上述这些概念,我们现在已经准备好实现一棵小型决策树了!
在没有任何指导的情况下,决策树将继续拆分节点,直到所有最终的叶节点都是纯的。控制树的复杂性的想法被称为修剪(pruning),我们可以在树完全建成后修剪它,也可以在生长阶段之前使用特定参数对树进行预修剪。预修剪树复杂度的一些方法是控制拆分的数量、限制最大深度(从根节点到叶节点的最长距离)或设置信息增益。
以下代码将所有这些概念联系在一起:
- 从一个数据集开始,其中有一个要预测的目标变量
- 计算原始数据集(根节点)的熵(或基尼系数)
- 查看每个特征并计算信息增益
- 选择具有最佳信息增益的最佳特征,这与导致熵降低最多的特征相同
保持增长,直到满足停止条件——在这种情况下,这是我们的最大深度限制,节点的熵为0。
import pandas as pd
import numpy as np
from math import log2
def entropy(data, target_col):
# calculate the entropy of the entire dataset
values, counts = np.unique(data[target_col], return_counts=True)
entropy = np.sum([-count/len(data) * log2(count/len(data)) for count in counts])
return entropy
def compute_information_gain(data, feature, target_col):
parent_entropy = entropy(data, target_col)
# 计算在给定特征上拆分的信息增益
split_values = np.unique(data[feature])
# initialize at 0
weighted_child_entropy = 0
# 计算加权熵,记住这与新节点中的点数有关
for value in split_values:
sub_data = data[data[feature] == value]
node_weight = len(sub_data)/len(data)
weighted_child_entropy += node_weight * entropy(sub_data, target_col)
#与之前相同的计算,我们只是从父节点熵中减去加权熵
return parent_entropy - weighted_child_entropy
def grow_tree(data, features, target_col, depth=0, max_depth=3):
# 我们将最大深度设置为3以“预修剪”或限制树的复杂性
if depth >= max_depth or len(np.unique(data[target_col])) == 1:
# 如果达到最大深度或所有标签都相同,则停止生长树。所有标签相同意味着熵为0
return np.unique(data[target_col])[0]
# 我们根据信息增益计算最佳特征(或最佳问题)
node = {}
gains = [compute_information_gain(data, feature, target_col) for feature in features]
best_feature = features[np.argmax(gains)]
for value in np.unique(data[best_feature]):
sub_data = data[data[best_feature] == value]
node[value] = grow_tree(sub_data, features, target_col, depth+1, max_depth)
return node
# 模拟一些数据并制作一个数据帧,注意我们是如何建立一个目标的
data = {
'A': [1, 2, 1, 2, 1, 2, 1, 2],
'B': [3, 3, 4, 4, 3, 3, 4, 4],
'C': [5, 5, 5, 5, 6, 6, 6, 6],
'target': [0, 0, 0, 1, 1, 1, 1, 0]
}
df = pd.DataFrame(data)
# 定义我们的特征和标签
features = ["A", "B", "C"]
target_col = "target"
# 成长树
tree = grow_tree(df, features, target_col, max_depth=3)
print(tree)预测这棵树意味着,用新数据遍历生长的树,直到它到达叶节点。最后一个叶节点是预测。
关于随机森林的一些有趣的事情
我们在上一节中讨论的所有内容都是有关单棵决策树如何做出决策。下图将这些概念与我们之前讨论的随机森林采样概念联系起来。
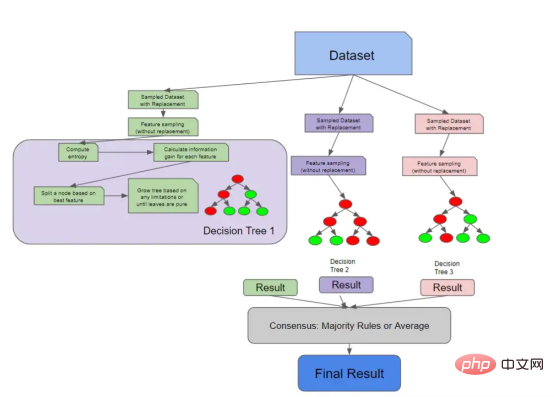
具有解构决策树的随机森林架构
因为决策树实际上检查每个特征的信息增益,所以您可以计算随机森林中的特征重要性。特征重要性的计算通常被视为所有树中杂质的平均减少。随机森林不像Logistic回归模型那样可解释,因此特征重要性为我们提供了一点关于树如何生长的知识。
最后,有几种方法可以测试你训练过的随机森林。您可以始终使用经典的机器学习方法,并使用测试集来衡量模型对未知数据的概括程度。然而,这通常需要第二次计算。随机森林有一个独特的属性,称为袋外错误或OOB错误。还记得我们如何仅对数据集的一部分进行采样以构建每个树吗?
实际上,您可以在训练时使用其余的样本来进行验证,这实际上只有在算法存在集成特性的情况下才是可能的。这意味着,在一次试验中,我们就可以了解我们的模型如何很好地推广到未知数据。
总结
总结一下,我们在本文中所学到的内容:
- 随机森林实际上是一组不相关的决策树,它们做出预测并达成共识。这种共识是回归问题的平均分数和分类问题的优先级规则。
- 随机森林通过利用装袋算法和特征采样减轻相关性。通过利用这两种技术,单棵决策树可以查看我们集合的特定维度,并根据不同的因素进行预测。
- 决策树是通过在产生最高信息增益的特征上分割数据来生长的。信息增益被测量为杂质的最高减少。杂质通常通过熵或基尼系统来测量。
- 随机森林能够通过特征重要性实现有限程度的可解释性,这是特征的平均信息增益的度量。
- 随机森林也有能力在训练时进行交叉验证,这是一种被称为OOB错误的独特技术。这是可能的,得益于算法对上游数据进行采样的方式。
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df.drop('target', axis=1), df['target'], test_size=0.2, random_state=0)
# 训练和评分随机森林
simple_rf_model = RandomForestClassifier(n_estimators=100, random_state=0)
simple_rf_model.fit(X_train, y_train)
print(f"accuracy: {simple_rf_model.score(X_test, y_test)}")
# accuracy: 0.93当查看训练随机森林的原始代码时,这几行代码中发生了多少不同的计算和评估,这让我感到惊讶。为了防止过度拟合,在树木和森林层面上进行评估,并实现一些基本的可解释性,需要考虑很多因素,此外,由于现有的所有框架,很容易进行设置。
我希望下次你训练随机森林模型时,你能够查看随机森林的scikit学习文档页面,并更好地了解你的所有选项。虽然有一些直观的默认设置,但应该清楚您可以进行多少不同的调整,以及这些技术中有多少可以扩展到其他模型。
我在写这篇文章时很开心,并且亲自了解了很多关于这个漂亮算法的工作原理。我希望你也能从中学习到一些东西!
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Demystifying the Random Forest,作者:Siddarth Ramesh
以上是机器学习随机森林算法实战解析的详细内容。更多信息请关注PHP中文网其他相关文章!

 微软工作趋势指数2025显示工作场所容量应变Apr 24, 2025 am 11:19 AM
微软工作趋势指数2025显示工作场所容量应变Apr 24, 2025 am 11:19 AM由于AI的快速整合而加剧了工作场所的迅速危机危机,要求战略转变以外的增量调整。 WTI的调查结果强调了这一点:68%的员工在工作量上挣扎,导致BUR
 AI可以理解吗?中国房间的论点说不,但是对吗?Apr 24, 2025 am 11:18 AM
AI可以理解吗?中国房间的论点说不,但是对吗?Apr 24, 2025 am 11:18 AM约翰·塞尔(John Searle)的中国房间论点:对AI理解的挑战 Searle的思想实验直接质疑人工智能是否可以真正理解语言或具有真正意识。 想象一个人,对下巴一无所知
 中国的'智能” AI助手回应微软召回的隐私缺陷Apr 24, 2025 am 11:17 AM
中国的'智能” AI助手回应微软召回的隐私缺陷Apr 24, 2025 am 11:17 AM与西方同行相比,中国的科技巨头在AI开发方面的课程不同。 他们不专注于技术基准和API集成,而是优先考虑“屏幕感知” AI助手 - AI T
 Docker将熟悉的容器工作流程带到AI型号和MCP工具Apr 24, 2025 am 11:16 AM
Docker将熟悉的容器工作流程带到AI型号和MCP工具Apr 24, 2025 am 11:16 AMMCP:赋能AI系统访问外部工具 模型上下文协议(MCP)让AI应用能够通过标准化接口与外部工具和数据源交互。由Anthropic开发并得到主要AI提供商的支持,MCP允许语言模型和智能体发现可用工具并使用合适的参数调用它们。然而,实施MCP服务器存在一些挑战,包括环境冲突、安全漏洞以及跨平台行为不一致。 Forbes文章《Anthropic的模型上下文协议是AI智能体发展的一大步》作者:Janakiram MSVDocker通过容器化解决了这些问题。基于Docker Hub基础设施构建的Doc
 使用6种AI街头智能策略来建立一家十亿美元的创业Apr 24, 2025 am 11:15 AM
使用6种AI街头智能策略来建立一家十亿美元的创业Apr 24, 2025 am 11:15 AM有远见的企业家采用的六种策略,他们利用尖端技术和精明的商业敏锐度来创造高利润的可扩展公司,同时保持控制权。本指南是针对有抱负的企业家的,旨在建立一个
 Google照片更新解锁了您所有图片的惊人Ultra HDRApr 24, 2025 am 11:14 AM
Google照片更新解锁了您所有图片的惊人Ultra HDRApr 24, 2025 am 11:14 AMGoogle Photos的新型Ultra HDR工具:改变图像增强的游戏规则 Google Photos推出了一个功能强大的Ultra HDR转换工具,将标准照片转换为充满活力的高动态范围图像。这种增强功能受益于摄影师
 Descope建立AI代理集成的身份验证框架Apr 24, 2025 am 11:13 AM
Descope建立AI代理集成的身份验证框架Apr 24, 2025 am 11:13 AM技术架构解决了新兴的身份验证挑战 代理身份集线器解决了许多组织仅在开始AI代理实施后发现的问题,即传统身份验证方法不是为机器设计的
 Google Cloud Next 2025以及现代工作的未来Apr 24, 2025 am 11:12 AM
Google Cloud Next 2025以及现代工作的未来Apr 24, 2025 am 11:12 AM(注意:Google是我公司的咨询客户,Moor Insights&Strateging。) AI:从实验到企业基金会 Google Cloud Next 2025展示了AI从实验功能到企业技术的核心组成部分的演变,


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

Dreamweaver Mac版
视觉化网页开发工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

Dreamweaver CS6
视觉化网页开发工具

