



图像抠图是指提取图像中准确的前景。当前的自动方法倾向于不加区别地提取图像中的所有显著对象。在本文中,作者提出了一个新的任务称为 参考图像抠图 (Referring Image Matting,RIM),指的是提取特定对象的细致的alpha抠图,它可以最好地匹配给定的自然语言描述。 然而,流行的visual grounding方法都局限于分割水平,可能是由于缺乏高质量的RIM数据集。为了填补这一空白, 作者通过设计一个全面的图像合成和表达生成引擎,建立了第一个大规模挑战性数据集RefMatte ,以在当前公共高质量抠图前景的基础上生成合成图像,具有灵活的逻辑和重新标记的多样化属性。
RefMatte由230个对象类别、47,500个图像、118,749个表达式区域实体和474,996个表达式组成,将来可以很容易地进一步扩展。除此之外,作者还构建了一个真实世界测试集,该测试集由100幅自然图像组成,使用人工生成的短语标注来进一步评估RIM模型的泛化能力。首先定义了基于提示和基于表达两种背景下的RIM任务,然后测试了几种典型的图像抠图方法以及具体的模型设计。这些结果为现有方法的局限性以及可能的解决方案提供了经验性的见解。相信新任务RIM和新数据集RefMatte将在该领域开辟新的研究方向,并促进未来的研究。

论文标题:Referring Image Matting
论文地址: https:// arxiv.org/abs/2206.0514 9
代码地址: https:// github.com/JizhiziLi/RI M
1. Motivation
图像抠图是指提取自然图像中前景的软ahpha抠图,这有利于各种下游应用,如视频会议、广告制作和电子商务推广。典型的抠图方法可以分为两组:1)基于辅助输入的方法,例如trimap,以及2)无需任何人工干预即可提取前景的自动抠图方法。但前者不适用于自动应用场景,后者一般局限于特定的对象类别,如人、动物或所有显著的物体。如何对任意对象进行可控的图像抠图,即提取与给定的自然语言描述最匹配的特定对象的alpha抠图,仍是一个有待探索的问题。
语言驱动的任务,例如referring expression segmentation(RES)、referring image segmentation(RIS)、视觉问答 (VQA) 和 referring expression comprehension (REC) 已被广泛探索。基于ReferIt、Google RefExp、RefCOCO、VGPhraseCut和Cops-Ref等许多数据集,这些领域已经取得了很大进展。例如,RES 方法旨在分割由自然语言描述指示的任意对象。然而,获得的mask仅限于没有精细细节的分割级别,由于数据集中的低分辨率图像和粗略的mask标注。因此,它们不可能用于需要对前景对象进行细致 Alpha 抠图的场景。

为了填补这一空白,作者在本文中提出了一项名为“Referring Image Matting (RIM)”的新任务。 RIM 是指在图像中提取与给定自然语言描述最匹配的特定前景对象以及细致的高质量 alpha 抠图。与上述两种抠图方法解决的任务不同,RIM 旨在对语言描述指示的图像中的任意对象进行可控的图像抠图。在工业应用领域具有现实意义,为学术界开辟了新的研究方向。
为了促进 RIM 的研究,作者建立了第一个名为 RefMatte 的数据集,该数据集由 230 个对象类别、47,500 个图像和 118,749 个表达式区域实体以及相应的高质量 alpha matte 和 474,996 个表达式组成。
具体来说,为了构建这个数据集,作者首先重新访问了许多流行的公共抠图数据集,如 AM-2k、P3M-10k、AIM-500、SIM,并手动标记仔细检查每个对象。作者还采用了多种基于深度学习的预训练模型为每个实体生成各种属性,例如人类的性别、年龄和衣服类型。然后,作者设计了一个综合的构图和表达生成引擎,以生成具有合理绝对和相对位置的合成图像,并考虑其他前景对象。最后,作者提出了几种表达逻辑形式,利用丰富的视觉属性生成不同的语言描述。此外,作者提出了一个真实世界的测试集 RefMatte-RW100,其中包含 100 张包含不同对象和人类注释表达的图像,用于评估 RIM 方法的泛化能力。上图显示了一些示例。
为了对相关任务中的最新方法进行公平和全面的评估,作者在 RefMatte 上根据语言描述的形式在两种不同的设置下对它们进行基准测试,即基于提示的设置和基于表达的设置。由于代表性方法是专门为分割任务设计的,直接将它们应用于 RIM 任务时仍然存在差距。
为了解决这个问题,作者提出了两种为 RIM 定制它们的策略,即 1)在 CLIPSeg 之上精心设计了一个名为 CLIPmat 的轻量级抠图头,以生成高质量的 alpha 抠图结果,同时保持其端到端可训练的管道; 2)提供了几种单独的基于粗图的抠图方法作为后期精炼器,以进一步改善分割/抠图结果。广泛的实验结果 1) 展示了所提出的 RefMatte 数据集对于 RIM 任务研究的价值,2) 确定语言描述形式的重要作用; 3) 验证提议的定制策略的有效性。
本研究的主要贡献有三方面。 1)定义了一个名为 RIM 的新任务,旨在识别和提取与给定自然语言描述最匹配的特定前景对象的 alpha抠图;2)建立了第一个大规模数据集RefMatte,由47,500张图像和118,749个表达区域实体组成,具有高质量的alpha抠图和丰富的表达; 3)在两种不同的设置下使用两种针对 RefMatte 的 RIM 定制策略对具有代表性的最先进方法进行了基准测试,并获得了一些有用的见解。
2.方法

在本节中,将介绍构建 RefMatte(第 3.1 节和第 3.2 节)的pipeline以及任务设置(第 3.3 节)和数据集的统计信息(第 3.5 节)。 上图展示RefMatte 的一些示例。此外,作者还构建了一个真实世界的测试集,由 100 张自然图像组成,并带有手动标记的丰富语言描述注释(第 3.4 节)。
2.1 Preparation of matting entities
为了准备足够多的高质量抠图实体来帮助构建 RefMatte 数据集,作者重新访问当前可用的抠图数据集以过滤出满足要求的前景。然后手动标记所有候选实体的类别并利用多个基于深度学习的预训练模型注释它们的属性。
Pre-processing and filtering
由于图像抠图任务的性质,所有候选实体都应该是高分辨率的,并且在 alpha 抠图中具有清晰和精细的细节。此外,数据应该通过开放许可公开获得,并且没有隐私问题,以促进未来的研究。针对这些要求,作者采用了来自 AM-2k 、P3M-10k 和 AIM-500的所有前景图像。具体来说,对于 P3M-10k,作者过滤掉具有两个以上粘性前景实例的图像,以确保每个实体仅与一个前景实例相关。对于其他可用的数据集,如 SIM、DIM和 HATT,作者过滤掉那些在人类实例中具有可识别面孔的前景图像。作者还过滤掉那些低分辨率或具有低质量 alpha 抠图的前景图像。最终实体总数为 13,187 个。对于后续合成步骤中使用的背景图像,作者选择 BG-20k 中的所有图像。
Annotate the category names of entities
由于以前的自动抠图方法倾向于从图像中提取所有显着的前景对象,因此它们没有为每个实体提供特定的(类别)名称。但是,对于 RIM 任务,需要实体名称来描述它。作者为每个实体标记了入门级类别名称,它代表人们对特定实体最常用的名称。在这里,采用半自动策略。具体来说,作者使用带有 ResNet-50-FPN主干的 Mask RCNN 检测器来自动检测和标记每个前景实例的类别名称,然后手动检查和纠正它们。 RefMatte 共有 230 个类别。此外,作者采用 WordNet为每个类别名称生成同义词以增强多样性。作者手动检查同义词并将其中一些替换为更合理的同义词。
Annotate the attributes of entities
为了确保所有实体具有丰富的视觉属性以支持形成丰富的表达式,作者为所有实体标注了颜色、人类实体的性别、年龄和衣服类型等多种属性。作者还采用半自动策略来生成此类属性。为了生成颜色,作者将前景图像的所有像素值聚类,找出最常见的值,并将其与 webcolors 中的特定颜色进行匹配。对于性别和年龄,作者采用预训练模型。按照常识根据预测的年龄来定义年龄组。对于衣服类型,作者采用 预训练模型。此外,受前景分类的启发,作者为所有实体添加了显着或不显着以及透明或不透明的属性,因为这些属性在图像抠图任务中也很重要。最终,每个实体至少有 3 个属性,人类实体至少有 6 个属性。
2.2 Image composition and expression generation
基于上一节收集的抠图实体,作者提出了一个图像合成引擎和表达式生成引擎来构建RefMatte 数据集。如何将不同的实体排列形成合理的合成图像,同时生成语义清晰、语法正确、丰富、花哨的表达方式来描述这些合成图像中的实体,是构建RefMatte的关键,也是具有挑战性的。为此,作者定义了六种位置关系,用于在合成图像中排列不同的实体,并利用不同的逻辑形式来产生适当的表达。
Image composition engine
为了保持实体的高分辨率,同时以合理的位置关系排列它们,作者为每个合成图像采用两个或三个实体。作者定义了六种位置关系:左、右、上、下、前、后。对于每个关系,首先生成前景图像,并通过 alpha 混合将它们与来自 BG-20k的背景图像合成。具体来说,对于左、右、上、下的关系,作者确保前景实例中没有遮挡以保留它们的细节。对于前后关系,通过调整它们的相对位置来模拟前景实例之间的遮挡。作者准备了一袋候选词来表示每个关系。
Expression generation engine
为了给合成图像中的实体提供丰富的表达方式,作者从定义的不同逻辑形式的角度为每个实体定义了三种表达方式,其中 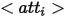 代表属性,
代表属性, 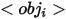 代表类别名称,
代表类别名称, 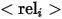 代表参考实体和相关实体之间的关系,具体三种表达的例子如上图(a),(b)和(c)所示。
代表参考实体和相关实体之间的关系,具体三种表达的例子如上图(a),(b)和(c)所示。
2.3 Dataset split and task settings
Dataset split
数据集总共有 13,187 个抠图实体,其中 11,799 个用于构建训练集,1,388 个用于测试集。然而,训练集和测试集的类别并不平衡,因为大多数实体属于人类或动物类别。具体来说,在训练集中的 11799 个实体中,有 9186 个人类、1800 个动物和 813 个物体。在包含 1,388 个实体的测试集中,有 977 个人类、200 个动物和 211 个对象。为了平衡类别,作者复制实体以实现人类:动物:对象的 5:1:1 比率。因此,在训练集中有 10,550 个人类、2,110 个动物和 2,110 个对象,在测试集中有 1,055 个人类、211 个动物和 211 个对象。
为了为 RefMatte 生成图像,作者从训练或测试split中挑选 5 个人类、1 个动物和 1 个对象作为一组,并将它们输入图像合成引擎。对于训练或测试split中的每一组,作者生成 20 张图像来形成训练集,并生成 10 幅图像来形成测试集。左/右:上/下:前/后关系的比例设置为 7:2:1。每个图像中的实体数量设置为 2 或 3。对于前后关系,作者总是选择 2 个实体来保持每个实体的高分辨率。在这个过程之后,就有 42,200 个训练图像和 2,110 个测试图像。为了进一步增强实体组合的多样性,我作者所有候选者中随机选择 实体和关系,形成另外 2800 个训练图像和 390 个测试图像。最后,在训练集中有 45,000 张合成图像,在测试集中有 2,500 张图像。
Task setting
为了在给定不同形式的语言描述的情况下对 RIM 方法进行基准测试,作者在 RefMatte 中设置了两个设置:
基于提示的设置(Prompt-based settin):该设置中的文字描述为提示,即实体的入门级类别名称,例如上图中的提示分别为花、人、羊驼;
基于表达式的设置(Expression-based setting):该设置中的文字描述是上一节中生成的表达式,从基本表达式、绝对位置表达式和相对位置表达式中选择。从上图中也可以看到一些示例。
2.4 Real-world test set

由于 RefMatte 是基于合成图像构建的,因此它们与真实世界图像之间可能存在域差距。为了研究在其上训练的 RIM 模型对真实世界图像的泛化能力,作者进一步建立了一个名为 RefMatte-RW100 的真实世界测试集,它由 100 张真实世界的高分辨率图像组成,每张图像中有 2 到 3 个实体。然后,作者按照3.2节中相同的三个设置来注释它们的表达式。此外,作者在注释中添加了一个自由表达式。对于高质量的 alpha 抠图标签,作者使用图像编辑软件生成它们,例如 Adobe Photoshop 和 GIMP。 RefMatte-RW100 的一些示例如上图所示。
2.5 Statistics of the RefMatte dataset and RefMatte-RW100 test set
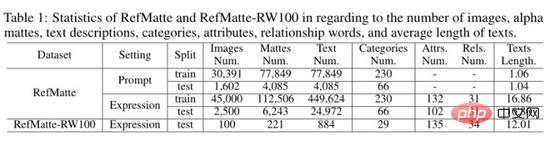
作者计算了 RefMatte 数据集和 RefMatte-RW100 测试集的统计数据如上表所示。对于基于提示的设置,由于文本描述是入门级类别名称,作者将具有多个实体属于同一类别的图像删除以避免模棱两可的推理。因此,在此设置中,在训练集中有 30,391 张图像,在测试集中有 1,602 张图像。alpha抠图的数量、文本描述、类别、属性和关系分别显示在上表中。在基于提示的设置中,平均文本长度约为 1,因为每个类别通常只有一个单词,而在基于表达的设置中则要大得多,即在 RefMatte 中约为 16.8,在 RefMatte-RW100 中约为 12。

作者还在上图中生成了 RefMatte 中的提示、属性和关系的词云。可以看出,数据集有很大一部分人类和动物,因为它们在图像抠图任务中非常常见。 RefMatte 中最常见的属性是男性、灰色、透明和显着,而关系词则更加平衡。
3.实验
由于 RIM 和 RIS/RES 之间存在任务差异,直接将 RIS/RES 方法应用于 RIM 的结果并不乐观。为了解决这个问题,作者提出了两种为 RIM 定制它们的策略:
1)Adding matting head:在现有模型之上设计轻量级 matting heads,以生成高质量的 alpha 抠图,同时保持端到端可训练pipeline。具体来说,作者在 CLIPSeg之上设计了一个轻量级的抠图解码器,称为 CLIPMat;
2)Using matting refiner:作者采用单独的基于粗图的抠图方法作为后细化器,以进一步改善上述方法的分割/抠图结果。具体来说,作者训练 GFM和 P3M,输入图像和粗图作为抠图细化器。
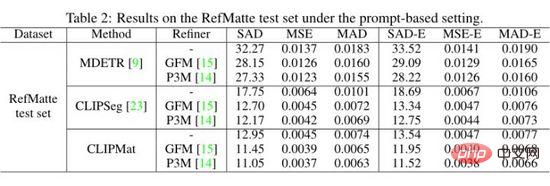
作者在 RefMatte 测试集的基于提示的设置上评估 MDETR 、CLIPSeg和 CLIPMat,并将定量结果显示在上表中。可以看出,与 MDETR 和 CLIPSeg 相比, CLIPMat 表现最好,无论是否使用抠图精炼器,验证添加抠图头为 RIM 任务自定义 CLIPSeg 的有效性。此外,使用两种抠图细化器中的任何一种都可以进一步提高三种方法的性能。
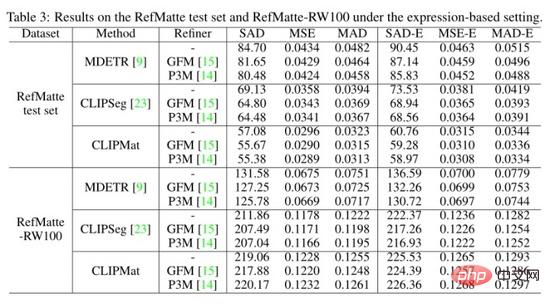
作者还在 RefMatte 测试集和 RefMatte-RW100 的基于表达式的设置下评估了这三种方法,并在上表中显示了定量结果。CLIPMat 再次在 RefMatte 测试集上表现出良好的保留更多细节的能力。在 RefMatte-RW100 上进行测试时,像 CLIPSeg 和 CLIPMat 这样的单阶段方法落后于两阶段方法,即 MDETR,这可能是由于 MDETR 的检测器在理解跨模态语义方面的能力更好。
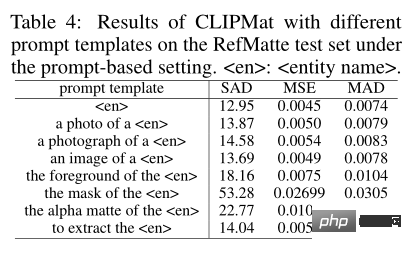
为了调查提示输入形式的影响,作者评估了不同提示模板的性能。除了 使用的传统模板外,作者还添加了更多专门为图像抠图任务设计的模板,例如the foreground/mask/alpha matte of
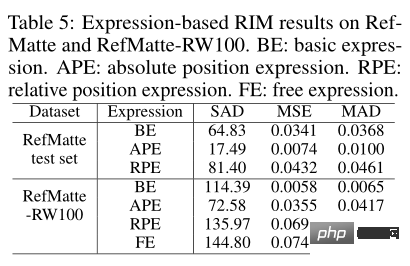
由于本文在任务中引入了不同类型的表达式,因此可以看到每种类型对抠图性能的影响。如上表所示,在 RefMatte 测试集上测试了性能最好的模型 CLIPMat,在 RefMatte-RW100 上测试了模型 MDETR。
4. 总结
在本文中,本文提出了一个名为引用图像抠图(RIM)的新任务,并建立了一个大规模的数据集 RefMatte。作者在 RIM 的相关任务中定制现有的代表性方法,并通过在 RefMatte 上的广泛实验来衡量它们的性能。本文的实验结果为模型设计、文本描述的影响以及合成图像和真实图像之间的域差距提供了有用的见解。RIM的研究可以有益于交互式图像编辑和人机交互等许多实际应用。 RefMatte 可以促进该领域的研究。然而,合成到真实的领域差距可能会导致对真实世界图像的泛化有限。
以上是深度学习又有新坑了!悉尼大学提出全新跨模态任务,用文本指导图像进行抠图的详细内容。更多信息请关注PHP中文网其他相关文章!

 易于理解的解释如何保存对话历史记录(对话日志)!May 16, 2025 am 05:41 AM
易于理解的解释如何保存对话历史记录(对话日志)!May 16, 2025 am 05:41 AM高效保存ChatGPT对话记录的多种方法 您是否曾想过保存ChatGPT生成的对话记录?本文将详细介绍多种保存方法,包括官方功能、Chrome扩展程序和截图等,助您充分利用ChatGPT对话记录。 了解各种方法的特点和步骤,选择最适合您的方式。 [OpenAI最新发布的AI代理“OpenAI Operator”介绍](此处应插入OpenAI Operator的链接) 目录 使用ChatGPT导出功能保存对话记录 官方导出功能的使用步骤 使用Chrome扩展程序保存ChatGPT日志 ChatGP
 使用Chatgpt创建时间表!解释可用于创建和调整表的提示May 16, 2025 am 05:40 AM
使用Chatgpt创建时间表!解释可用于创建和调整表的提示May 16, 2025 am 05:40 AM现代社会节奏紧凑,高效的日程管理至关重要。工作、生活、学习等任务交织在一起,优先级排序和日程安排常常让人头疼不已。 因此,利用AI技术的智能日程管理方法备受关注。特别是利用ChatGPT强大的自然语言处理能力,可以自动化繁琐的日程安排和任务管理,显着提高生产力。 本文将深入讲解如何利用ChatGPT进行日程管理。我们将结合具体的案例和步骤,展示AI如何提升日常生活和工作效率。 此外,我们还会讨论使用ChatGPT时需要注意的事项,确保安全有效地利用这项技术。 立即体验ChatGPT,让您的日程
 如何将chatgpt与电子表格连接!对您可以做什么的详尽解释May 16, 2025 am 05:39 AM
如何将chatgpt与电子表格连接!对您可以做什么的详尽解释May 16, 2025 am 05:39 AM我们将解释如何将Google表和Chatgpt联系起来,以提高业务效率。在本文中,我们将详细解释如何使用易于使用的“床单和文档的GPT”附加组件。无需编程知识。 通过CHATGPT和电子表格集成提高业务效率 本文将重点介绍如何使用附加组件将Chatgpt与电子表格连接。附加组件使您可以轻松地将ChatGpt功能集成到电子表格中。 gpt for shee
 6个投资者对AI的预测于2025年May 16, 2025 am 05:37 AM
6个投资者对AI的预测于2025年May 16, 2025 am 05:37 AM专家们预测AI革命的未来几年,专家们预测专家们都在强调了总体趋势和模式。例如,对数据的需求很大,我们将在后面讨论。此外,对能量的需求是D
 使用chatgpt进行写作!提示的提示和示例的详尽说明!May 16, 2025 am 05:36 AM
使用chatgpt进行写作!提示的提示和示例的详尽说明!May 16, 2025 am 05:36 AMChatgpt不仅是文本生成工具,而且是一个真正的合作伙伴,可显着提高作家的创造力。通过在整个写作过程中使用chatgpt,例如初始手稿创建,构思想法和风格变化,您可以同时节省时间并提高质量。本文将详细说明在每个阶段使用Chatgpt的特定方法,以及最大化生产力和创造力的技巧。此外,我们将研究将Chatgpt与语法检查工具和SEO优化工具相结合的协同作用。通过与AI的合作,作家可以通过免费想法创造独创性
 如何在chatgpt中创建图形!无需插件,因此也可以用于Excel!May 16, 2025 am 05:35 AM
如何在chatgpt中创建图形!无需插件,因此也可以用于Excel!May 16, 2025 am 05:35 AM使用chatgpt的数据可视化:从图创建到数据分析 数据可视化以易于理解的方式传达复杂信息,在现代社会中至关重要。近年来,由于AI技术的进步,使用Chatgpt的图形创建引起了人们的关注。在本文中,我们将解释如何以易于理解的方式使用Chatgpt创建图形,甚至对于初学者。我们将介绍免费版本和付费版本(Chatgpt Plus),特定创建步骤以及如何显示日语标签以及实际示例之间的差异。 使用chatgpt创建图形:从基础到高级使用 chatg
 用餐盘推动现代LLM的极限?May 16, 2025 am 05:34 AM
用餐盘推动现代LLM的极限?May 16, 2025 am 05:34 AM通常,我们知道AI很大,而且越来越大。快速,越来越快。 但是,具体来说,并不是每个人都熟悉行业中一些最新的硬件和软件方法,以及它们如何促进更好的结果。人民
 归档您的Chatgpt对话历史!解释保存的步骤以及如何还原May 16, 2025 am 05:33 AM
归档您的Chatgpt对话历史!解释保存的步骤以及如何还原May 16, 2025 am 05:33 AMChatGPT对话记录管理指南:高效整理,充分利用你的知识宝库! ChatGPT对话记录是创意和知识的源泉,但不断增长的记录如何有效管理呢? 查找重要信息耗时费力?别担心!本文将详细讲解如何有效“归档”(保存和管理)你的ChatGPT对话记录。我们将涵盖官方归档功能、数据导出、共享链接以及数据利用和注意事项。 目录 ChatGPT的“归档”功能详解 ChatGPT归档功能使用方法 ChatGPT归档记录的保存位置和查看方法 ChatGPT归档记录的取消和删除方法 取消归档 删除归档 总结 Ch


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

禅工作室 13.0.1
功能强大的PHP集成开发环境

SublimeText3汉化版
中文版,非常好用

Dreamweaver CS6
视觉化网页开发工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

