



1、首先,要知道我们用哪些库来画图?
matplotlib
Python中最基本的作图库就是matplotlib,是一个最基础的Python可视化库,一般都是从matplotlib上手Python数据可视化,然后开始做纵向与横向拓展。
Seaborn
是一个基于matplotlib的高级可视化效果库,针对的点主要是数据挖掘和机器学习中的变量特征选取,seaborn可以用短小的代码去绘制描述更多维度数据的可视化效果图。
其他库还包括
Bokeh(是一个用于做浏览器端交互可视化的库,实现分析师与数据的交互);Mapbox(处理地理数据引擎更强的可视化工具库)等等。
本篇文章主要使用matplotlib进行案例分析
第一步:确定问题,选择图形
业务可能很复杂,但是经过拆分,我们要找到我们想通过图形表达什么具体问题。分析思维的训练可以学习《麦肯锡方法》和《金字塔原理》中的方法。
这是网上的一张关于图表类型选择的总结。
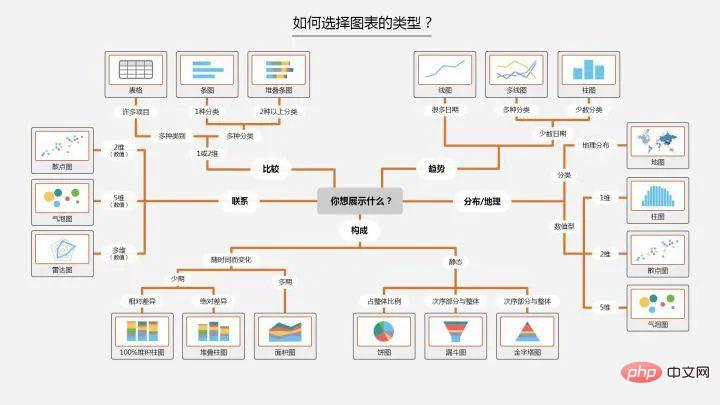
在Python中,我们可以总结为以下四种基本视觉元素来展现图形:
- 点:scatter plot 二维数据,适用于简单二维关系;
- 线:line plot 二维数据,适用于时间序列;
- 柱状:bar plot 二维数据,适用于类别统计;
- 颜色:heatmap 适用于展示第三维度;
数据间存在分布,构成,比较,联系以及变化趋势等关系。对应不一样的关系,选择相应的图形进行展示。
第二步:转换数据,应用函数
数据分析和建模方面的大量编程工作都是用在数据准备的基础上的:加载、清理、转换以及重塑。 我们可视化步骤也需要对数据进行整理,转换成我们需要的格式再套用可视化方法完成作图。
下面是一些常用的数据转换方法:
- 合并:merge,concat,combine_frist(类似于数据库中的全外连接)
- 重塑:reshape;轴向旋转:pivot(类似excel数据透视表)
- 去重:drop_duplicates
- 映射:map
- 填充替换:fillna,replace
- 重命名轴索引:rename
将分类变量转换‘哑变量矩阵’的get_dummies函数以及在df中对某列数据取限定值等等。
函数则根据第一步中选择好的图形,去找Python中对应的函数。
第三步:参数设置,一目了然
原始图形画完后,我们可以根据需求修改颜色(color),线型(linestyle),标记(maker)或者其他图表装饰项标题(Title),轴标签(xlabel,ylabel),轴刻度(set_xticks),还有图例(legend)等,让图形更加直观。
第三步是在第二步的基础上,为了使图形更加清晰明了,做的修饰工作。具体参数都可以在制图函数中找到。
2、可视化作图基础
Matplotlib作图基础
#导入包 import numpy as np import pandas as pd import matplotlib.pyplot as plt
Figure和Subplot
matplotlib的图形都位于Figure(画布)中,Subplot创建图像空间。不能通过figure绘图,必须用add_subplot创建一个或多个subplot。
figsize可以指定图像尺寸。
#创建画布 fig = plt.figure() <Figure size 432x288 with 0 Axes> #创建subplot,221表示这是2行2列表格中的第1个图像。 ax1 = fig.add_subplot(221) #但现在更习惯使用以下方法创建画布和图像,2,2表示这是一个2*2的画布,可以放置4个图像 fig , axes = plt.subplots(2,2,sharex=True,sharey=True) #plt.subplot的sharex和sharey参数可以指定所有的subplot使用相同的x,y轴刻度。
利用Figure的subplots_adjust方法可以调整间距。
subplots_adjust(left=None,bottom=None,right=None, top=None,wspace=None,hspace=None)
颜色color,标记marker,和线型linestyle
matplotlib的plot函数接受一组X和Y坐标,还可以接受一个表示颜色和线型的字符串缩写:**'g--',表示颜色是绿色green,线型是'--'虚线。**也可以使用参数明确的指定。
线型图还可以加上一些标记(marker),来突出显示数据点的位置。标记也可以放在格式字符串中,但标记类型和线型必须放在颜色后面。
plt.plot(np.random.randn(30),color='g', linestyle='--',marker='o')
[<matplotlib.lines.Line2D at 0x8c919b0>]
刻度,标签和图例
plt的xlim、xticks和xtickslabels方法分别控制图表的范围和刻度位置和刻度标签。
调用方法时不带参数,则返回当前的参数值;调用时带参数,则设置参数值。
plt.plot(np.random.randn(30),color='g', linestyle='--',marker='o') plt.xlim() #不带参数调用,显示当前参数; #可将xlim替换为另外两个方法试试
(-1.4500000000000002, 30.45)
img
plt.plot(np.random.randn(30),color='g', linestyle='--',marker='o') plt.xlim([0,15]) #横轴刻度变成0-15
(0, 15)
设置标题,轴标签,刻度以及刻度标签
fig = plt.figure();ax = fig.add_subplot(1,1,1)
ax.plot(np.random.randn(1000).cumsum())
ticks = ax.set_xticks([0,250,500,750,1000]) #设置刻度值
labels = ax.set_xticklabels(['one','two','three','four','five']) #设置刻度标签
ax.set_title('My first Plot') #设置标题
ax.set_xlabel('Stage') #设置轴标签
Text(0.5,0,'Stage')
添加图例
图例legend是另一种用于标识图标元素的重要工具。 可以在添加subplot的时候传入label参数。
fig = plt.figure(figsize=(12,5));ax = fig.add_subplot(111) ax.plot(np.random.randn(1000).cumsum(),'k',label='one') #传入label参数,定义label名称 ax.plot(np.random.randn(1000).cumsum(),'k--',label='two') ax.plot(np.random.randn(1000).cumsum(),'k.',label='three') #图形创建完后,只需要调用legend参数将label调出来即可。 ax.legend(loc='best') #要求不是很严格的话,建议使用loc=‘best’参数来让它自己选择最佳位置
注解
除标准的图表对象之外,我们还可以自定义添加一些文字注解或者箭头。
注解可以通过text,arrow和annotate等函数进行添加。text函数可以将文本绘制在指定的x,y坐标位置,还可以进行自定义格式
plt.plot(np.random.randn(1000).cumsum()) plt.text(600,10,'test ',family='monospace',fontsize=10) #中文注释在默认环境下并不能正常显示,需要修改配置文件, # 使其支持中文字体。具体步骤请自行搜索。
保存图表到文件
利用plt.savefig可以将当前图表保存到文件。例如,要将图表保存为png文件,可以执行
文件类型是根据拓展名而定的。其他参数还有:
- fname:含有文件路径的字符串,拓展名指定文件类型
- dpi:分辨率,默认100 facecolor,edgcolor 图像的背景色,默认‘w’白色
- format:显示设置文件格式('png','pdf','svg','ps','jpg'等)
- bbox_inches:图表需要保留的部分。如果设置为“tight”,则将尝试剪除图像周围的空白部分
plt.savefig('./plot.jpg') #保存图像为plot名称的jpg格式图像
<Figure size 432x288 with 0 Axes>3、Pandas中的绘图函数
Matplotlib作图
matplotlib是最基础的绘图函数,也是相对较低级的工具。 组装一张图表需要单独调用各个基础组件才行。Pandas中有许多基于matplotlib的高级绘图方法,原本需要多行代码才能搞定的图表,使用pandas只需要短短几行。
我们使用的就调用了pandas中的绘图包。
import matplotlib.pyplot as plt
线型图
Series和DataFrame都有一个用于生成各类图表的plot方法。 默认情况下,他们生成的是线型图。
s = pd.Series(np.random.randn(10).cumsum(),index=np.arange(0,100,10)) s.plot() #Series对象的索引index会传给matplotlib用作绘制x轴。
<matplotlib.axes._subplots.AxesSubplot at 0xf553128>
df = pd.DataFrame(np.random.randn(10,4).cumsum(0), columns=['A','B','C','D']) df.plot() #plot会自动为不同变量改变颜色,并添加图例
<matplotlib.axes._subplots.AxesSubplot at 0xf4f9eb8>
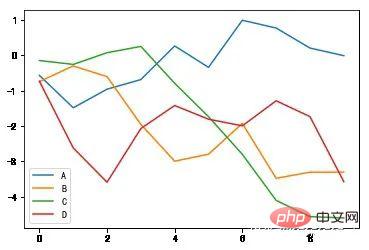
Series.plot方法的参数
- label:用于图表的标签
- style:风格字符串,'g--'
- alpha:图像的填充不透明度(0-1)
- kind:图表类型(bar,line,hist,kde等)
- xticks:设定x轴刻度值
- yticks:设定y轴刻度值
- xlim,ylim:设定轴界限,[0,10]
- grid:显示轴网格线,默认关闭
- rot:旋转刻度标签
- use_index:将对象的索引用作刻度标签
- logy:在Y轴上使用对数标尺
DataFrame.plot方法的参数
DataFrame除了Series中的参数外,还有一些独有的选项。
- subplots:将各个DataFrame列绘制到单独的subplot中
- sharex,sharey:共享x,y轴
- figsize:控制图像大小
- title:图像标题
- legend:添加图例,默认显示
- sort_columns:以字母顺序绘制各列,默认使用当前顺序
柱状图
在生成线型图的代码中加上kind=‘bar’或者kind=‘barh’,可以生成柱状图或水平柱状图。
fig,axes = plt.subplots(2,1)
data = pd.Series(np.random.rand(10),index=list('abcdefghij'))
data.plot(kind='bar',ax=axes[0],rot=0,alpha=0.3)
data.plot(kind='barh',ax=axes[1],grid=True)<matplotlib.axes._subplots.AxesSubplot at 0xfe39898>
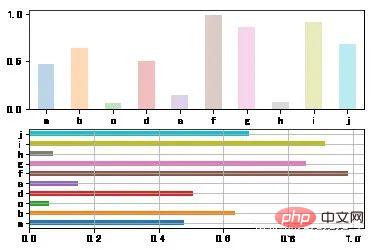
柱状图有一个非常实用的方法:
利用value_counts图形化显示Series或者DF中各值的出现频率。
比如df.value_counts().plot(kind='bar')
Python可视化的基础语法就到这里,其他图形的绘制方法大同小异。
重点是遵循三个步骤的思路来进行思考、选择、应用。多多练习可以更加熟练。
以上是Python 数据可视化的三大步骤的详细内容。更多信息请关注PHP中文网其他相关文章!

 您如何切成python阵列?May 01, 2025 am 12:18 AM
您如何切成python阵列?May 01, 2025 am 12:18 AMPython列表切片的基本语法是list[start:stop:step]。1.start是包含的第一个元素索引,2.stop是排除的第一个元素索引,3.step决定元素之间的步长。切片不仅用于提取数据,还可以修改和反转列表。
 在什么情况下,列表的表现比数组表现更好?May 01, 2025 am 12:06 AM
在什么情况下,列表的表现比数组表现更好?May 01, 2025 am 12:06 AMListSoutPerformarRaysin:1)DynamicsizicsizingandFrequentInsertions/删除,2)储存的二聚体和3)MemoryFeliceFiceForceforseforsparsedata,butmayhaveslightperformancecostsinclentoperations。
 如何将Python数组转换为Python列表?May 01, 2025 am 12:05 AM
如何将Python数组转换为Python列表?May 01, 2025 am 12:05 AMtoConvertapythonarraytoalist,usEthelist()constructororageneratorexpression.1)intimpthearraymoduleandcreateanArray.2)USELIST(ARR)或[XFORXINARR] to ConconverTittoalist,请考虑performorefformanceandmemoryfformanceandmemoryfformienceforlargedAtasetset。
 当Python中存在列表时,使用数组的目的是什么?May 01, 2025 am 12:04 AM
当Python中存在列表时,使用数组的目的是什么?May 01, 2025 am 12:04 AMchoosearraysoverlistsinpythonforbetterperformanceandmemoryfliceSpecificScenarios.1)largenumericaldatasets:arraysreducememoryusage.2)绩效 - 临界杂货:arraysoffersoffersOffersOffersOffersPoostSfoostSforsssfortasssfortaskslikeappensearch orearch.3)testessenforcety:arraysenforce:arraysenforc
 说明如何通过列表和数组的元素迭代。May 01, 2025 am 12:01 AM
说明如何通过列表和数组的元素迭代。May 01, 2025 am 12:01 AM在Python中,可以使用for循环、enumerate和列表推导式遍历列表;在Java中,可以使用传统for循环和增强for循环遍历数组。1.Python列表遍历方法包括:for循环、enumerate和列表推导式。2.Java数组遍历方法包括:传统for循环和增强for循环。
 什么是Python Switch语句?Apr 30, 2025 pm 02:08 PM
什么是Python Switch语句?Apr 30, 2025 pm 02:08 PM本文讨论了Python版本3.10中介绍的新“匹配”语句,该语句与其他语言相同。它增强了代码的可读性,并为传统的if-elif-el提供了性能优势

 Python中的功能注释是什么?Apr 30, 2025 pm 02:06 PM
Python中的功能注释是什么?Apr 30, 2025 pm 02:06 PMPython中的功能注释将元数据添加到函数中,以进行类型检查,文档和IDE支持。它们增强了代码的可读性,维护,并且在API开发,数据科学和图书馆创建中至关重要。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

Dreamweaver CS6
视觉化网页开发工具

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

