



XAI的目标是为模型的行为和决定提供有意义的解释,本文整理了目前能够看到的10个用于可解释AI的Python库
什么是XAI?
XAI,Explainable AI是指可以为人工智能(AI)决策过程和预测提供清晰易懂的解释的系统或策略。XAI 的目标是为他们的行为和决策提供有意义的解释,这有助于增加信任、提供问责制和模型决策的透明度。XAI 不仅限于解释,还以一种使推理更容易为用户提取和解释的方式进行 ML 实验。
在实践中,XAI 可以通过多种方法实现,例如使用特征重要性度量、可视化技术,或者通过构建本质上可解释的模型,例如决策树或线性回归模型。方法的选择取决于所解决问题的类型和所需的可解释性水平。
AI 系统被用于越来越多的应用程序,包括医疗保健、金融和刑事司法,在这些应用程序中,AI 对人们生活的潜在影响很大,并且了解做出了决定特定原因至关重要。因为这些领域的错误决策成本很高(风险很高),所以XAI 变得越来越重要,因为即使是 AI 做出的决定也需要仔细检查其有效性和可解释性。

可解释性实践的步骤
数据准备:这个阶段包括数据的收集和处理。数据应该是高质量的、平衡的并且代表正在解决的现实问题。拥有平衡的、有代表性的、干净的数据可以减少未来为保持 AI 的可解释性而付出的努力。
模型训练:模型在准备好的数据上进行训练,传统的机器学习模型或深度学习神经网络都可以。模型的选择取决于要解决的问题和所需的可解释性水平。模型越简单就越容易解释结果,但是简单模型的性能并不会很高。
模型评估:选择适当的评估方法和性能指标对于保持模型的可解释性是必要的。在此阶段评估模型的可解释性也很重要,这样确保它能够为其预测提供有意义的解释。
解释生成:这可以使用各种技术来完成,例如特征重要性度量、可视化技术,或通过构建固有的可解释模型。
解释验证:验证模型生成的解释的准确性和完整性。这有助于确保解释是可信的。
部署和监控:XAI 的工作不会在模型创建和验证时结束。它需要在部署后进行持续的可解释性工作。在真实环境中进行监控,定期评估系统的性能和可解释性非常重要。
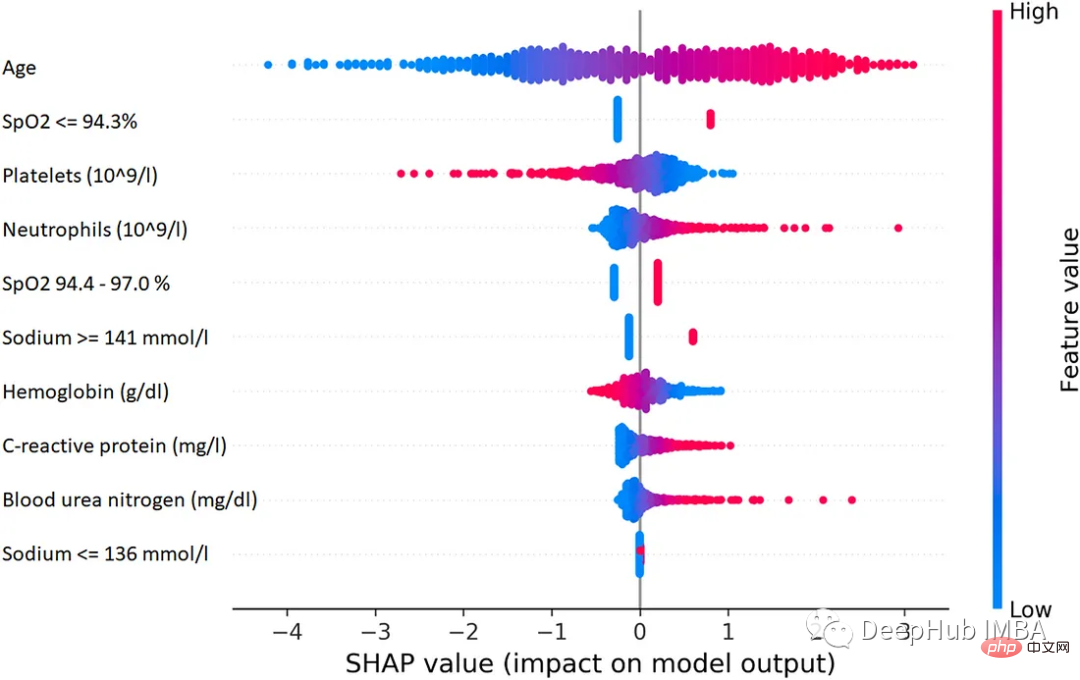
1、SHAP (SHapley Additive exPlanations)
SHAP是一种博弈论方法,可用于解释任何机器学习模型的输出。它使用博弈论中的经典Shapley值及其相关扩展将最佳信用分配与本地解释联系起来。
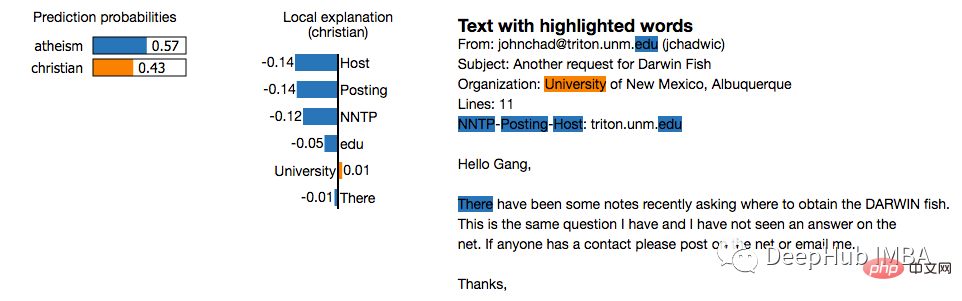
2、LIME(Local Interpretable Model-agnostic Explanations)
LIME 是一种与模型无关的方法,它通过围绕特定预测在局部近似模型的行为来工作。LIME 试图解释机器学习模型在做什么。LIME 支持解释文本分类器、表格类数据或图像的分类器的个别预测。
3、Eli5
ELI5是一个Python包,它可以帮助调试机器学习分类器并解释它们的预测。它提供了以下机器学习框架和包的支持:
- scikit-learn:ELI5可以解释scikit-learn线性分类器和回归器的权重和预测,可以将决策树打印为文本或SVG,显示特征的重要性,并解释决策树和基于树集成的预测。ELI5还可以理解scikit-learn中的文本处理程序,并相应地突出显示文本数据。
- Keras -通过Grad-CAM可视化解释图像分类器的预测。
- XGBoost -显示特征的重要性,解释XGBClassifier, XGBRegressor和XGBoost . booster的预测。
- LightGBM -显示特征的重要性,解释LGBMClassifier和LGBMRegressor的预测。
- CatBoost:显示CatBoostClassifier和CatBoostRegressor的特征重要性。
- lightning -解释lightning 分类器和回归器的权重和预测。
- sklearn-crfsuite。ELI5允许检查sklearn_crfsuite.CRF模型的权重。
基本用法:
Show_weights() 显示模型的所有权重,Show_prediction() 可用于检查模型的个体预测

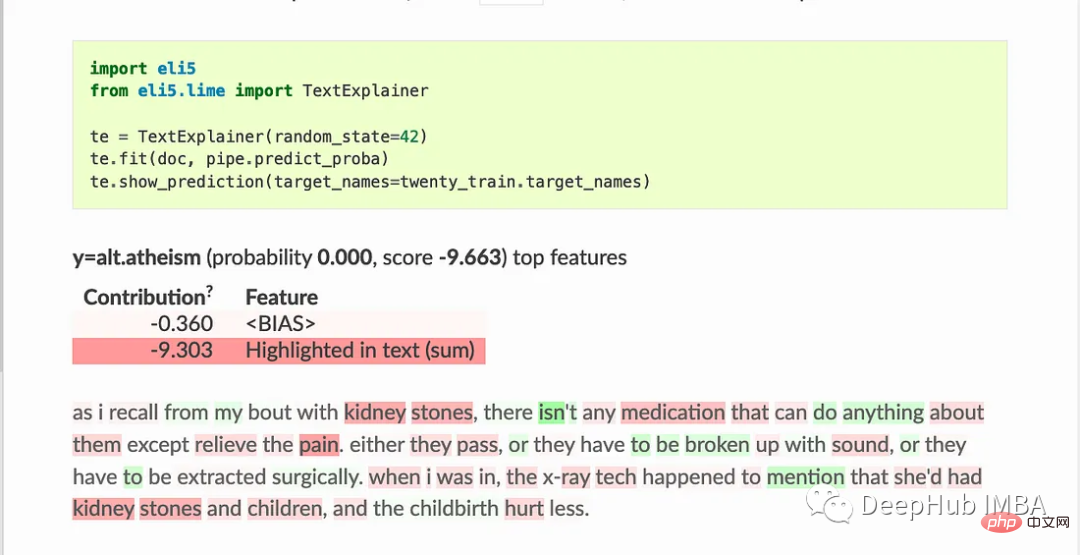
ELI5还实现了一些检查黑盒模型的算法:
TextExplainer使用LIME算法解释任何文本分类器的预测。排列重要性法可用于计算黑盒估计器的特征重要性。
4、Shapash
Shapash提供了几种类型的可视化,可以更容易地理解模型。通过摘要来理解模型提出的决策。该项目由MAIF数据科学家开发。Shapash主要通过一组出色的可视化来解释模型。
Shapash通过web应用程序机制工作,与Jupyter/ipython可以完美的结合。
from shapash import SmartExplainer
xpl = SmartExplainer(
model=regressor,
preprocessing=encoder, # Optional: compile step can use inverse_transform method
features_dict=house_dict# Optional parameter, dict specifies label for features name
)
xpl.compile(x=Xtest,
y_pred=y_pred,
y_target=ytest, # Optional: allows to display True Values vs Predicted Values
)
xpl.plot.contribution_plot("OverallQual")
5、Anchors
Anchors使用称为锚点的高精度规则解释复杂模型的行为,代表局部的“充分”预测条件。该算法可以有效地计算任何具有高概率保证的黑盒模型的解释。
Anchors可以被看作为LIME v2,其中LIME的一些限制(例如不能为数据的不可见实例拟合模型)已经得到纠正。Anchors使用局部区域,而不是每个单独的观察点。它在计算上比SHAP轻量,因此可以用于高维或大数据集。但是有些限制是标签只能是整数。

6、BreakDown
BreakDown是一种可以用来解释线性模型预测的工具。它的工作原理是将模型的输出分解为每个输入特征的贡献。这个包中有两个主要方法。Explainer()和Explanation()
model = tree.DecisionTreeRegressor() model = model.fit(train_data,y=train_labels) #necessary imports from pyBreakDown.explainer import Explainer from pyBreakDown.explanation import Explanation #make explainer object exp = Explainer(clf=model, data=train_data, colnames=feature_names) #What do you want to be explained from the data (select an observation) explanation = exp.explain(observation=data[302,:],direction="up")

7、Interpret-Text
Interpret-Text 结合了社区为 NLP 模型开发的可解释性技术和用于查看结果的可视化面板。可以在多个最先进的解释器上运行实验,并对它们进行比较分析。这个工具包可以在每个标签上全局或在每个文档本地解释机器学习模型。
以下是此包中可用的解释器列表:
- Classical Text Explainer——(默认:逻辑回归的词袋)
- Unified Information Explainer
- Introspective Rationale Explainer

它的好处是支持CUDA,RNN和BERT等模型。并且可以为文档中特性的重要性生成一个面板
from interpret_text.widget import ExplanationDashboard from interpret_text.explanation.explanation import _create_local_explanation # create local explanation local_explanantion = _create_local_explanation( classification=True, text_explanation=True, local_importance_values=feature_importance_values, method=name_of_model, model_task="classification", features=parsed_sentence_list, classes=list_of_classes, ) # Dash it ExplanationDashboard(local_explanantion)

8、aix360 (AI Explainability 360)
AI Explainbability 360工具包是一个开源库,这个包是由IBM开发的,在他们的平台上广泛使用。AI Explainability 360包含一套全面的算法,涵盖了不同维度的解释以及代理解释性指标。

工具包结合了以下论文中的算法和指标:
- Towards Robust Interpretability with Self-Explaining Neural Networks, 2018. ref
- Boolean Decision Rules via Column Generation, 2018. ref
- Explanations Based on the Missing: Towards Contrastive Explanations with Pertinent Negatives, 2018. ref
- Improving Simple Models with Confidence Profiles, , 2018. ref
- Efficient Data Representation by Selecting Prototypes with Importance Weights, 2019. ref
- TED: Teaching AI to Explain Its Decisions, 2019. ref
- Variational Inference of Disentangled Latent Concepts from Unlabeled Data, 2018. ref
- Generating Contrastive Explanations with Monotonic Attribute Functions, 2019. ref
- Generalized Linear Rule Models, 2019. ref
9、OmniXAI
OmniXAI (Omni explable AI的缩写),解决了在实践中解释机器学习模型产生的判断的几个问题。
它是一个用于可解释AI (XAI)的Python机器学习库,提供全方位的可解释AI和可解释机器学习功能,并能够解决实践中解释机器学习模型所做决策的许多痛点。OmniXAI旨在成为一站式综合库,为数据科学家、ML研究人员和从业者提供可解释的AI。
from omnixai.visualization.dashboard import Dashboard # Launch a dashboard for visualization dashboard = Dashboard( instances=test_instances,# The instances to explain local_explanations=local_explanations, # Set the local explanations global_explanations=global_explanations, # Set the global explanations prediction_explanations=prediction_explanations, # Set the prediction metrics class_names=class_names, # Set class names explainer=explainer# The created TabularExplainer for what if analysis ) dashboard.show()

10、XAI (eXplainable AI)
XAI 库由 The Institute for Ethical AI & ML 维护,它是根据 Responsible Machine Learning 的 8 条原则开发的。它仍处于 alpha 阶段因此请不要将其用于生产工作流程。
以上是十个用于可解释AI的Python库的详细内容。更多信息请关注PHP中文网其他相关文章!

 2023年机器学习的十大概念和技术Apr 04, 2023 pm 12:30 PM
2023年机器学习的十大概念和技术Apr 04, 2023 pm 12:30 PM机器学习是一个不断发展的学科,一直在创造新的想法和技术。本文罗列了2023年机器学习的十大概念和技术。 本文罗列了2023年机器学习的十大概念和技术。2023年机器学习的十大概念和技术是一个教计算机从数据中学习的过程,无需明确的编程。机器学习是一个不断发展的学科,一直在创造新的想法和技术。为了保持领先,数据科学家应该关注其中一些网站,以跟上最新的发展。这将有助于了解机器学习中的技术如何在实践中使用,并为自己的业务或工作领域中的可能应用提供想法。2023年机器学习的十大概念和技术:1. 深度神经网
 人工智能自动获取知识和技能,实现自我完善的过程是什么Aug 24, 2022 am 11:57 AM
人工智能自动获取知识和技能,实现自我完善的过程是什么Aug 24, 2022 am 11:57 AM实现自我完善的过程是“机器学习”。机器学习是人工智能核心,是使计算机具有智能的根本途径;它使计算机能模拟人的学习行为,自动地通过学习来获取知识和技能,不断改善性能,实现自我完善。机器学习主要研究三方面问题:1、学习机理,人类获取知识、技能和抽象概念的天赋能力;2、学习方法,对生物学习机理进行简化的基础上,用计算的方法进行再现;3、学习系统,能够在一定程度上实现机器学习的系统。
 超参数优化比较之网格搜索、随机搜索和贝叶斯优化Apr 04, 2023 pm 12:05 PM
超参数优化比较之网格搜索、随机搜索和贝叶斯优化Apr 04, 2023 pm 12:05 PM本文将详细介绍用来提高机器学习效果的最常见的超参数优化方法。 译者 | 朱先忠审校 | 孙淑娟简介通常,在尝试改进机器学习模型时,人们首先想到的解决方案是添加更多的训练数据。额外的数据通常是有帮助(在某些情况下除外)的,但生成高质量的数据可能非常昂贵。通过使用现有数据获得最佳模型性能,超参数优化可以节省我们的时间和资源。顾名思义,超参数优化是为机器学习模型确定最佳超参数组合以满足优化函数(即,给定研究中的数据集,最大化模型的性能)的过程。换句话说,每个模型都会提供多个有关选项的调整“按钮
 得益于OpenAI技术,微软必应的搜索流量超过谷歌Mar 31, 2023 pm 10:38 PM
得益于OpenAI技术,微软必应的搜索流量超过谷歌Mar 31, 2023 pm 10:38 PM截至3月20日的数据显示,自微软2月7日推出其人工智能版本以来,必应搜索引擎的页面访问量增加了15.8%,而Alphabet旗下的谷歌搜索引擎则下降了近1%。 3月23日消息,外媒报道称,分析公司Similarweb的数据显示,在整合了OpenAI的技术后,微软旗下的必应在页面访问量方面实现了更多的增长。截至3月20日的数据显示,自微软2月7日推出其人工智能版本以来,必应搜索引擎的页面访问量增加了15.8%,而Alphabet旗下的谷歌搜索引擎则下降了近1%。这些数据是微软在与谷歌争夺生
 荣耀的人工智能助手叫什么名字Sep 06, 2022 pm 03:31 PM
荣耀的人工智能助手叫什么名字Sep 06, 2022 pm 03:31 PM荣耀的人工智能助手叫“YOYO”,也即悠悠;YOYO除了能够实现语音操控等基本功能之外,还拥有智慧视觉、智慧识屏、情景智能、智慧搜索等功能,可以在系统设置页面中的智慧助手里进行相关的设置。
 人工智能在教育领域的应用主要有哪些Dec 14, 2020 pm 05:08 PM
人工智能在教育领域的应用主要有哪些Dec 14, 2020 pm 05:08 PM人工智能在教育领域的应用主要有个性化学习、虚拟导师、教育机器人和场景式教育。人工智能在教育领域的应用目前还处于早期探索阶段,但是潜力却是巨大的。
 30行Python代码就可以调用ChatGPT API总结论文的主要内容Apr 04, 2023 pm 12:05 PM
30行Python代码就可以调用ChatGPT API总结论文的主要内容Apr 04, 2023 pm 12:05 PM阅读论文可以说是我们的日常工作之一,论文的数量太多,我们如何快速阅读归纳呢?自从ChatGPT出现以后,有很多阅读论文的服务可以使用。其实使用ChatGPT API非常简单,我们只用30行python代码就可以在本地搭建一个自己的应用。 阅读论文可以说是我们的日常工作之一,论文的数量太多,我们如何快速阅读归纳呢?自从ChatGPT出现以后,有很多阅读论文的服务可以使用。其实使用ChatGPT API非常简单,我们只用30行python代码就可以在本地搭建一个自己的应用。使用 Python 和 C
 人工智能在生活中的应用有哪些Jul 20, 2022 pm 04:47 PM
人工智能在生活中的应用有哪些Jul 20, 2022 pm 04:47 PM人工智能在生活中的应用有:1、虚拟个人助理,使用者可通过声控、文字输入的方式,来完成一些日常生活的小事;2、语音评测,利用云计算技术,将自动口语评测服务放在云端,并开放API接口供客户远程使用;3、无人汽车,主要依靠车内的以计算机系统为主的智能驾驶仪来实现无人驾驶的目标;4、天气预测,通过手机GPRS系统,定位到用户所处的位置,在利用算法,对覆盖全国的雷达图进行数据分析并预测。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

Atom编辑器mac版下载
最流行的的开源编辑器

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

