




通过上面爬取股票个股资金流的例子,大家应该已经能够学会自己编写爬取代码。现在巩固一下,做个相似的小练习题。要动手自己编写Python程序,爬取网上板块的资金流。爬取网址为http://data.eastmoney.com/bkzj/hy.html,显示界面如图1所示。
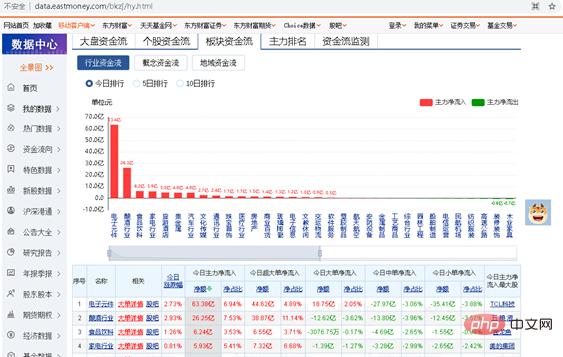
图1 板块资金流网址界面
1,查找JS
直接按F12键,打开开发调试工具并查找数据所对应的网页,如图2所示。
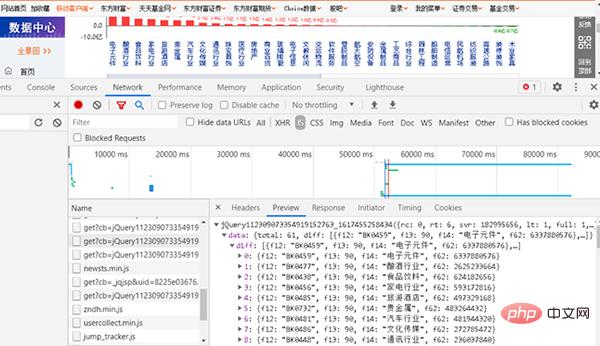
图2 查找JS所对应的网页
然后把网址输入浏览器中,网址比较长。
http://push2.eastmoney.com/api/qt/clist/get?cb=jQuery112309073354919152763_1617455258434&pn=1&pz=500&po=1&np=1&fields=f12%2Cf13%2Cf14%2Cf62&fid=f62&fs=m%3A90%2Bt%3A2&ut=b2884a393a59ad64002292a3e90d46a5&_=1617455258435
此时,会得到网站的反馈,如图3所示。

图3 从网站获得板块及资金流
该网址对应的内容即是我们想要爬取的内容。
2,request请求及response响应状态
编写爬虫代码,详见如下代码:
# coding=utf-8 import requests url=" http://push2.eastmoney.com/api/qt/clist/get?cb=jQuery112309073354919152763_ 1617455258436&fid=f62&po=1&pz=50&pn=1&np=1&fltt=2&invt=2&ut=b2884a393a59ad64002292a3 e90d46a5&fs=m%3A90+t%3A2&fields=f12%2Cf14%2Cf2%2Cf3%2Cf62%2Cf184%2Cf66%2Cf69%2Cf72%2 Cf75%2Cf78%2Cf81%2Cf84%2Cf87%2Cf204%2Cf205%2Cf124" r = requests.get(url)
r.status_code显示200,表示响应状态正常。r.text也有数据,说明爬取资金流数据是成功的,如图4所示。
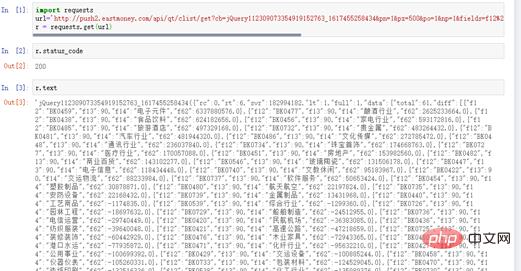
图4 response响应状态
3,清洗str变成JSON标准格式
(1)分析r.text数据。其内部是标准的JSON格式,只是前面多了一些前缀。将jQ前缀去掉,使用split()函数就能完成这个操作。详见如下代码:
r_text=r.text.split("{}".format("jQuery112309073354919152763_1617455258436"))[1]
r_text运行结果如图5所示。

图5 去掉前缀的运行结果
(2)整理JSON数据。详见如下代码:
r_text_qu=r_text.rstrip(';')
r_text_json=json.loads(r_text_qu[1:-1])['data']['diff']
dfcf_code={"f12":"code","f2":"价格","f3":"涨幅","f14":"name","f62":"主净入√","f66":"超净入","f69":"超占比", "f72":"大净入","f75":"大占比","f78":"中净入","f81":"中占比","f84":"小净入","f87":"小占比","f124":"不知道","f184":"主占比√"}
result_=pd.DataFrame(r_text_json).rename(columns=dfcf_code)
result_["主净入√"]=round(result_["主净入√"]/100000000,2)#一亿,保留2位
result_=result_[result_["主净入√"]>0]
result_["超净入"]=round(result_["超净入"]/100000000,2)#一亿,保留2位
result_["大净入"]=round(result_["大净入"]/100000000,2)#一亿,保留2位
result_["中净入"]=round(result_["中净入"]/100000000,2)#一亿,保留2位
result_["小净入"]=round(result_["小净入"]/100000000,2)#一亿,保留2位
result_运行结果如图6所示。
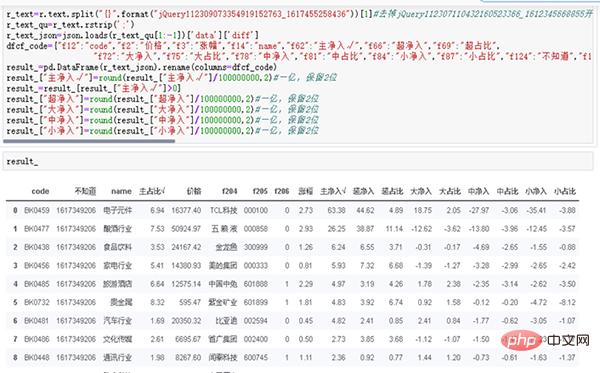
图6 整理后的运行结果
4,保存资金流数据
将清洗好的数据使用to_csv()函数保存到本地,如图7所示。
通过以上两种资金爬取的例子,想必大家已经了解了爬虫的一部分使用方法。其核心思路是:
(1)选取股票个股资金流的优势;
(2)获得网址并加以分析;
(3)使用爬虫进行数据获取并保存数据。
图6 数据保存
总结
JSON格式的数据是诸多网站使用的标准化数据格式之一,是一种轻量级的数据交换格式,十分易于阅读和编写,可以有效地提升网络传输效率。首先爬取到的是str格式的字符串,通过数据加工与处理,将其变成标准的JSON格式,继而变成Pandas格式。
通过案例分析与实战,我们要学会自己编写代码爬取金融数据并具备转化为JSON标准格式的能力。完成每日数据爬取工作与数据保存工作,为日后对数据进行历史测试与历史分析提供有效的数据支撑。
当然,有能力的读者可以将结果保存到MySQL、MongoDB等数据库中,甚至云端数据库Mongo Atlas中,这里作者不作重点讲解。我们将重点完全放在量化学习与策略的研究上面。使用txt格式保存数据,完全可以解决前期数据存储问题,数据也是完整有效的。
以上是写一个爬取板块资金流的Python程序的详细内容。更多信息请关注PHP中文网其他相关文章!

 Python 文本终端 GUI 框架,太酷了Apr 12, 2023 pm 12:52 PM
Python 文本终端 GUI 框架,太酷了Apr 12, 2023 pm 12:52 PMCurses首先出场的是 Curses[1]。CurseCurses 是一个能提供基于文本终端窗口功能的动态库,它可以: 使用整个屏幕 创建和管理一个窗口 使用 8 种不同的彩色 为程序提供鼠标支持 使用键盘上的功能键Curses 可以在任何遵循 ANSI/POSIX 标准的 Unix/Linux 系统上运行。Windows 上也可以运行,不过需要额外安装 windows-curses 库:pip install windows-curses 上面图片,就是一哥们用 Curses 写的 俄罗斯
 五个方便好用的Python自动化脚本Apr 11, 2023 pm 07:31 PM
五个方便好用的Python自动化脚本Apr 11, 2023 pm 07:31 PM相比大家都听过自动化生产线、自动化办公等词汇,在没有人工干预的情况下,机器可以自己完成各项任务,这大大提升了工作效率。编程世界里有各种各样的自动化脚本,来完成不同的任务。尤其Python非常适合编写自动化脚本,因为它语法简洁易懂,而且有丰富的第三方工具库。这次我们使用Python来实现几个自动化场景,或许可以用到你的工作中。1、自动化阅读网页新闻这个脚本能够实现从网页中抓取文本,然后自动化语音朗读,当你想听新闻的时候,这是个不错的选择。代码分为两大部分,第一通过爬虫抓取网页文本呢,第二通过阅读工
 用Python写了个小工具,再复杂的文件夹,分分钟帮你整理!Apr 11, 2023 pm 08:19 PM
用Python写了个小工具,再复杂的文件夹,分分钟帮你整理!Apr 11, 2023 pm 08:19 PM糟透了我承认我不是一个爱整理桌面的人,因为我觉得乱糟糟的桌面,反而容易找到文件。哈哈,可是最近桌面实在是太乱了,自己都看不下去了,几乎占满了整个屏幕。虽然一键整理桌面的软件很多,但是对于其他路径下的文件,我同样需要整理,于是我想到使用Python,完成这个需求。效果展示我一共为将文件分为9个大类,分别是图片、视频、音频、文档、压缩文件、常用格式、程序脚本、可执行程序和字体文件。# 不同文件组成的嵌套字典 file_dict = { '图片': ['jpg','png','gif','webp
 用 WebAssembly 在浏览器中运行 PythonApr 11, 2023 pm 09:43 PM
用 WebAssembly 在浏览器中运行 PythonApr 11, 2023 pm 09:43 PM长期以来,Python 社区一直在讨论如何使 Python 成为网页浏览器中流行的编程语言。然而网络浏览器实际上只支持一种编程语言:JavaScript。随着网络技术的发展,我们已经把越来越多的程序应用在网络上,如游戏、数据科学可视化以及音频和视频编辑软件。这意味着我们已经把繁重的计算带到了网络上——这并不是JavaScript的设计初衷。所有这些挑战提出了对新编程语言的需求,这种语言可以提供快速、可移植、紧凑和安全的代码执行。因此,主要的浏览器供应商致力于实现这个想法,并在2017年向世界推出
 从头开始构建,DeepMind新论文用伪代码详解TransformerApr 09, 2023 pm 08:31 PM
从头开始构建,DeepMind新论文用伪代码详解TransformerApr 09, 2023 pm 08:31 PM2017 年 Transformer 横空出世,由谷歌在论文《Attention is all you need》中引入。这篇论文抛弃了以往深度学习任务里面使用到的 CNN 和 RNN。这一开创性的研究颠覆了以往序列建模和 RNN 划等号的思路,如今被广泛用于 NLP。大热的 GPT、BERT 等都是基于 Transformer 构建的。Transformer 自推出以来,研究者已经提出了许多变体。但大家对 Transformer 的描述似乎都是以口头形式、图形解释等方式介绍该架构。关于 Tra
 一文读懂层次聚类(Python代码)Apr 11, 2023 pm 09:13 PM
一文读懂层次聚类(Python代码)Apr 11, 2023 pm 09:13 PM首先要说,聚类属于机器学习的无监督学习,而且也分很多种方法,比如大家熟知的有K-means。层次聚类也是聚类中的一种,也很常用。下面我先简单回顾一下K-means的基本原理,然后慢慢引出层次聚类的定义和分层步骤,这样更有助于大家理解。层次聚类和K-means有什么不同?K-means 工作原理可以简要概述为: 决定簇数(k) 从数据中随机选取 k 个点作为质心 将所有点分配到最近的聚类质心 计算新形成的簇的质心 重复步骤 3 和 4这是一个迭代过程,直到新形成的簇的质心不变,或者达到最大迭代次数
 用 Python 实现导弹自动追踪,超燃!Apr 12, 2023 am 08:04 AM
用 Python 实现导弹自动追踪,超燃!Apr 12, 2023 am 08:04 AM大家好,我是J哥。这个没有点数学基础是很难算出来的。但是我们有了计算机就不一样了,依靠计算机极快速的运算速度,我们利用微分的思想,加上一点简单的三角学知识,就可以实现它。好,话不多说,我们来看看它的算法原理,看图:由于待会要用pygame演示,它的坐标系是y轴向下,所以这里我们也用y向下的坐标系。算法总的思想就是根据上图,把时间t分割成足够小的片段(比如1/1000,这个时间片越小越精确),每一个片段分别构造如上三角形,计算出导弹下一个时间片走的方向(即∠a)和走的路程(即vt=|AC|),这时
 集成GPT-4的Cursor让编写代码和聊天一样简单,用自然语言编写代码的新时代已来Apr 04, 2023 pm 12:15 PM
集成GPT-4的Cursor让编写代码和聊天一样简单,用自然语言编写代码的新时代已来Apr 04, 2023 pm 12:15 PM集成GPT-4的Github Copilot X还在小范围内测中,而集成GPT-4的Cursor已公开发行。Cursor是一个集成GPT-4的IDE,可以用自然语言编写代码,让编写代码和聊天一样简单。 GPT-4和GPT-3.5在处理和编写代码的能力上差别还是很大的。官网的一份测试报告。前两个是GPT-4,一个采用文本输入,一个采用图像输入;第三个是GPT3.5,可以看出GPT-4的代码能力相较于GPT-3.5有较大能力的提升。集成GPT-4的Github Copilot X还在小范围内测中,而


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

Dreamweaver Mac版
视觉化网页开发工具

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

记事本++7.3.1
好用且免费的代码编辑器

