



不同于传统的目标检测问题,少样本目标检测(FSOD)假设我们有许多的基础类样本,但只有少量的新颖类样本。其目标是研究如何将基础类的知识迁移到新颖类,进而提升检测器对新颖类的识别能力。
FSOD 通常遵循两阶段训练范式。在第一阶段,检测器使用丰富的基础类样本进行训练,以学习目标检测任务所需的通用表示,如目标定位和分类。在第二阶段中,检测器仅使用 少量(如 1, 2, 3...)新颖类样本进行微调。然而由于基础类和新颖类样本数量的不平衡,其学习到的模型通常偏向于基础类,进而导致新颖类目标与相似的基础类混淆。此外,由于每个新颖类只有少量样本,模型对新颖类的方差很敏感。例如,随机采样新颖类样本进行多次训练,每次的结果都会有较大的差异。因此十分有必要提升模型在少样本下的鲁棒性。
近期,腾讯优图实验室与武汉大学提出了基于变分特征聚合的少样本目标检测模型 VFA。VFA 的整体结构是基于改进版的元学习目标检测框架 Meta R-CNN ,并提出了两种特征聚合方法:类别无关特征聚合 CAA(Class-Agnostic Aggregation)和变分特征聚合 VFA(Variational Feature Aggregation)。
特征聚合是 FSOD 中的一个关键设计,其定义了 Query 和 Support 样本之间的交互方式。前面的方法如 Meta R-CNN 通常采用类别相关特征聚合 CSA(class-specific aggregation),即同类 Query 和 Support 样本的特征进行特征聚合。与此相反,本文提出的 CAA 允许不同类样本之间的特征聚合。由于 CAA 鼓励模型学习类别无关的表示,其降低了模型对基础类的偏向。此外,不同类之间的交互能够更好地建模类别间的关系,从而降低了类别的混淆。
基于 CAA,本文又提出了 VFA,其采用变分编码器(VAEs)将 Support 样本编码为类的分布,并从学习到的分布中采样新的 Support 特征进行特征融合。相关工作 [1] 指出类内方差(如外观的变化)在不同类之间是相似的,并且可以通过常见的分布进行建模。因此我们可以利用基础类的分布来估计新颖类的分布,进而提高少样本情况下特征聚合的鲁棒性。
VFA 在多个 FSOD 数据集上表现优于目前最好的模型,相关研究已经被 AAAI 2023 录用为 Oral。

论文地址:https://arxiv.org/abs/2301.13411
VFA 模型细节
更强的基线方法:Meta R-CNN
目前 FSOD 的工作主要可以分为两类:基于元学习(meta learning)的方法和基于微调(fine-tuning)的方法。早期的一些工作证明元学习对 FSOD 是有效的,但基于微调的方法在最近受到越来越多的关注。本文首先建立了一个基于元学习的基线方法 Meta R-CNN ,缩小了两种方法之间的差距,在某些指标上甚至超过了基于微调的方法。
我们首先分析了两种方法在实现上的一些差距,以元学习方法 Meta R-CNN [2] 和基于微调的方法 TFA [3] 为例,虽然这两种方法都遵循两阶段训练范式,TFA 在微调阶段使用额外的技术优化模型:
- TFA 冻结了大部分网络参数,只训练最后的分类和回归层,这样模型就不会过度拟合少样本类别。
- TFA 不是随机初始化分类层,而是复制基础类的预训练权重,只初始化新颖类的权重。
- TFA 采用余弦分类器(cosine classifier)而不是线性分类器。
考虑到 TFA 的成功,我们构建了 Meta R-CNN 。如下表 1 所示,只要我们仔细处理微调阶段,元学习方法也能够取得较好的效果。因此,本文选择 Meta R-CNN 作为基线方法。

表一:Meta R-CNN 和 TFA 的对比与分析
类别无关特征聚合 CAA

图一:类别无关特征聚合 CAA 示意图
本文提出一个简单而有效的类别无关特征聚合方法 CAA。如上图一所示,CAA 允许不同类之间的特征聚合,进而鼓励模型学习类别无关的表示,从而减少类别间的偏向和类之间的混淆。具体来说,对于类别 的每个 RoI 特征
的每个 RoI 特征 和一组 Support 特征
和一组 Support 特征 ,我们随机选择一个类的 Support 特征
,我们随机选择一个类的 Support 特征 的
的 与 Query 特征聚合:
与 Query 特征聚合:

然后我们将聚合特征

提供给检测子网络

以输出分类得分
 。
。
变分特征聚合 VFA

之前的工作通常将 Support 样本编码为单个特征向量来表示类别的中心。然而在样本较少且方差较大的情况下,我们很难对类中心做出准确的估计。在本文中,我们首先将 Support 特征转换为类别的分布。由于估计出的类别分布不偏向于特定样本,因此从分布中采样的特征对样本的方差有较好的鲁棒性。VFA 的框架如上图二所示。
a)变分特征学习。VFA 采用变分自编码器 VAEs [4] 来学习类别的分布。如图二所示,对于一个 Support 特征 S,我们首先使用编码器 来估计分布的参数
来估计分布的参数 和
和 ,接着从分布
,接着从分布 中通过变分推理(variational inference)采样
中通过变分推理(variational inference)采样 ,最后通过解码器
,最后通过解码器 得到重构的 Support 特征
得到重构的 Support 特征 。在优化 VAE 时,除了常见的 KL Loss
。在优化 VAE 时,除了常见的 KL Loss 和重构 Loss
和重构 Loss ,本文还使用了一致性 Loss 使得学习到的分布保留类别信息:
,本文还使用了一致性 Loss 使得学习到的分布保留类别信息:

b)变分特征融合。由于 Support 特征被转换为类别的分布,我们可以从分布中采样特征并与 Query 特征聚合。具体来说,VFA 同样采用类别无关聚合 CAA,但将 Query 特征 与变分特征
与变分特征 聚合在一起。给定类
聚合在一起。给定类 的 Query 特征
的 Query 特征 和类
和类 的 Support 特征
的 Support 特征
,我们首先估计其分布 ,并采样变分特征
,并采样变分特征 ;然后通过下面的公式将其融合在一起:
;然后通过下面的公式将其融合在一起:

其中 表示通道乘法,而 sig 是 sigmoid 操作的缩写。在训练阶段,我们随机选择一个 Support 特征
表示通道乘法,而 sig 是 sigmoid 操作的缩写。在训练阶段,我们随机选择一个 Support 特征 进行聚合;在测试阶段,我们对
进行聚合;在测试阶段,我们对
类的 个 Support 特征取平均值
个 Support 特征取平均值 ,并估计分布
,并估计分布 ,其中
,其中 。
。
分类 - 回归任务解耦
通常情况下,检测子网络 包含一个共享特征提取器
包含一个共享特征提取器 和两个独立的网络:分类子网络
和两个独立的网络:分类子网络 和回归子网络
和回归子网络 。在前面的工作中,聚合后的特征被输入到检测子网络中进行目标分类和边界框回归。但是分类任务需要平移不变特征,而回归需要平移协变的特征。由于 Support 特征表示的是类别的中心,具有平移不变性,因此聚合后特征会损害回归任务。
。在前面的工作中,聚合后的特征被输入到检测子网络中进行目标分类和边界框回归。但是分类任务需要平移不变特征,而回归需要平移协变的特征。由于 Support 特征表示的是类别的中心,具有平移不变性,因此聚合后特征会损害回归任务。
本文提出一种简单的分类 - 回归任务解耦。让 和
和 表示原始和聚合后的 Query 特征,之前的方法对这两个任务都采用
表示原始和聚合后的 Query 特征,之前的方法对这两个任务都采用 ,其中分类分数
,其中分类分数 和预测边界框
和预测边界框 定义为:
定义为:

为了解耦这些任务,我们采用单独的特征提取器并使用原始的 Support 特征 进行边界框回归:
进行边界框回归:

我们采用的数据集:PASCAL VOC、 MS COCO。评价指标:新颖类平均精度 nAP、基础类平均精度 bAP。
主要结果
VFA 在两个数据集上都取得了较好的结果。如在 PASCAL VOC 数据集上(下表二),VFA 显著高于之前的方法;VFA 的 1-shot 结果甚至高于一些方法 10-shot 的结果。

消融实验
a)不同模块的作用。如下表三所示,VFA 的不同模块可以共同作用,提升模型的性能。

b) 不同特征聚合方法可视化分析。如下图三所示,CAA 可以减小基础类与新颖类之间的混淆;VFA 在 CAA 的基础上,进一步增强了类间的区分度。

c)更加准确的类别中心点估计。如下图四所示,VFA 可以更加准确的估计出类别的中心。且随着样本数量的减少,估计的准确度逐渐高于基线方法。这也解释了为什么我们的方法在样本少的情况下(K=1)表现的更好。

d)结果可视化。

结语
本文回归了基于元学习的 FSOD 中特征聚合方法,并提出了类别无关特征聚合 CAA 和变分特征聚合 VFA。CAA 可以减少基础类和新颖类之间的类别偏差和混淆;VFA 将样本转换为类别分布以实现更加鲁棒的特征聚合。本文提出的方法在 PASCAL VOC 和 MS COCO 数据集上的实验证明了其有效性。
以上是回归元学习,基于变分特征聚合的少样本目标检测实现新SOTA的详细内容。更多信息请关注PHP中文网其他相关文章!

 什么是Power BI语义模型?Apr 15, 2025 am 10:46 AM
什么是Power BI语义模型?Apr 15, 2025 am 10:46 AM介绍 想象一个场景:您的团队被来自不同来源的大量数据集所淹没。 整合,分类和分析此信息以进行有意义的演示是一个挑战。这是Power BI语义模型(PBISM)EX
 如何使用Llama索引和Monsterapi建立AI代理Apr 15, 2025 am 10:44 AM
如何使用Llama索引和Monsterapi建立AI代理Apr 15, 2025 am 10:44 AMAI特工:由Llamaindex和Monsterapi提供支持的AI的未来 AI代理有望彻底改变我们与技术的互动方式。 这些自主系统模仿人类行为,执行需要推理,决策和REA的任务
 在没有人类干预的情况下训练LLM的7种方法Apr 15, 2025 am 10:38 AM
在没有人类干预的情况下训练LLM的7种方法Apr 15, 2025 am 10:38 AM解锁自治AI:自我训练LLMS的7种方法 想象一个未来AI系统在没有人类干预的情况下学习和发展的未来,就像孩子独立掌握复杂概念的孩子一样。这不是科幻小说;这是自我的应许
 通过AI和NLG进行财务报告 - 分析VidhyaApr 15, 2025 am 10:35 AM
通过AI和NLG进行财务报告 - 分析VidhyaApr 15, 2025 am 10:35 AMAI驱动的财务报告:通过自然语言产生革新见解 在当今动态的业务环境中,准确及时的财务分析对于战略决策至关重要。 传统财务报告
 这款Google DeepMind机器人会在2028年奥运会上演奏吗?Apr 15, 2025 am 10:16 AM
这款Google DeepMind机器人会在2028年奥运会上演奏吗?Apr 15, 2025 am 10:16 AMGoogle DeepMind的乒乓球机器人:体育和机器人技术的新时代 巴黎2024年奥运会可能已经结束,但是由于Google DeepMind,运动和机器人技术的新时代正在兴起。 他们的开创性研究(“实现人类水平的竞争
 使用Gemini Flash 1.5型号构建食物视觉网络应用Apr 15, 2025 am 10:15 AM
使用Gemini Flash 1.5型号构建食物视觉网络应用Apr 15, 2025 am 10:15 AM双子座闪光灯1.5解锁效率和可伸缩性:烧瓶食物视觉webapp 在快速发展的AI景观中,效率和可扩展性至关重要。 开发人员越来越多地寻求高性能模型,以最大程度地减少成本和延迟
 使用LlamainDex实施AI代理Apr 15, 2025 am 10:11 AM
使用LlamainDex实施AI代理Apr 15, 2025 am 10:11 AM利用LlamainDex的AI特工的力量:逐步指南 想象一下,一个私人助理了解您的要求并完美地执行它们,无论是快速计算还是检索最新的市场新闻。本文探索
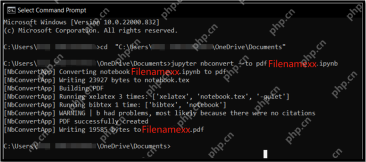 将.ipynb文件转换为PDF- Analytics Vidhya的5种方法Apr 15, 2025 am 10:06 AM
将.ipynb文件转换为PDF- Analytics Vidhya的5种方法Apr 15, 2025 am 10:06 AMJupyter Notebook (.ipynb) 文件广泛用于数据分析、科学计算和交互式编码。虽然这些 Notebook 非常适合开发和与其他数据科学家共享代码,但有时您需要将其转换为更普遍易读的格式,例如 PDF。本指南将引导您逐步了解将 .ipynb 文件转换为 PDF 的各种方法,以及技巧、最佳实践和故障排除建议。 目录 为什么将 .ipynb 转换为 PDF? 将 .ipynb 文件转换为 PDF 的方法 使用 Jupyter Notebook UI 使用 nbconve


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

SublimeText3 Linux新版
SublimeText3 Linux最新版

Dreamweaver CS6
视觉化网页开发工具

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

