



圣诞将至,虽然咱不过这洋节,但是热闹还是要凑一下的,相信已经有很多圣诞帽相关的周边在流传了,今天咱们就自己动手,给头像增加一个圣诞帽
基础知识准备
在计算机中,图像是以矩阵的形式保存的,先行后列。所以,一张宽×高×颜色通道=480×256×3的图片会保存在一个256×480×3的三维张量中。图像处理时也是按照这种思想进行计算的(其中就包括 OpenCV 下的图像处理),即 高×宽×颜色通道。
数字图像
对于一幅的数字图像,我们看到的是 肉眼可见的一幅真正的图片,但是计算机看来,这副图像只是一堆亮度各异的点。一副尺寸为 M × N 的图像可以用一个 M × N 的矩阵来表示,矩阵元素的值表示这个位置上的像素的亮度,一般来说像素值越大表示该点越亮。
一般来说,灰度图用 2 维矩阵表示,彩色(多通道)图像用 3 维矩阵(M× N × 3)表示。
图像通道
描述一个像素点,如果是灰度,那么只需要一个数值来描述它,就是单通道。如果一个像素点,有RGB三种颜色来描述它,就是三通道。而四通道图像,就是R、G、B加上一个A通道,表示透明度。一般叫做alpha通道,表示透明度。
ROI和mask
Setting Region of Interest (ROI),翻译成白话为,设置感兴趣的区域。mask是做图像掩膜处理,相当于把我们不关心的部位覆盖住,留下ROI部分。上面说的alpha就可以作为mask。
矩阵(Numpy)知识
矩阵索引、切片等,这里我自己掌握的也不好,就不多说了,小伙伴儿们可以自行学习。
环境准备
有了基础知识后,我们来简单看下代码。
首先安装需要要用到的 OpenCV 和 dlib 库,使用pip分别安装之
pip install python-opencv pip install dlib
然后手工在网上下载数据模型文件 shape_predictor_5_face_landmarks.dat,地址如下:http://dlib.net/files/,下载后放到项目目录下。
有兴趣的同学可以玩玩那个 shape_predictor_68_face_landmarks.dat,识别出的人脸关键点有68个之多呢。

代码处理
帽子处理
我们首先要做的就是处理帽子,我们使用的图片如下

先提取帽子图片的rgb和alpha值
# 帽子图片
hat_img3 = cv2.imread("hat.png", -1)
r, g, b, a = cv2.split(hat_img3)
rgb_hat = cv2.merge((r, g, b))
cv2.imwrite("rgb_hat.jpg", rgb_hat)
cv2.imwrite("alpha.jpg", a)
print(a)
print(hat_img3.shape)
print(rgb_hat.shape)
我们得到的效果如下:
rgb图

alpha图

对于的打印出的a数值如下:
[[0 0 0 ... 0 0 0] [0 0 0 ... 0 0 0] [0 0 0 ... 0 0 0] ... [0 0 0 ... 0 0 0] [0 0 0 ... 0 0 0] [0 0 0 ... 0 0 0]]
人脸检测
下面进行人脸检测,使用dlib处理。
# 人脸检测 dets = self.detector(img, 1) x, y, w, h = dets[0].left(), dets[0].top(), dets[0].right() - dets[0].left(), dets[0].bottom() - dets[0].top() # 关键点检测 shape = self.predictor(img, dets[0]) point1 = shape.parts()[0] point2 = shape.parts(2) # 求两点中心 eyes_center = ((point1.x + point2.x) // 2, (point1.y + point2.y) // 2)
接下来是按照比例缩小帽子的图片
# 帽子和人脸转换比例 hat_w = int(round(dets[0].right()/1.5)) hat_h = int(round(dets[0].bottom() / 2)) if hat_h > y: hat_h = y - 1 hat_newsize = cv2.resize(rgb_hat, (hat_w, hat_h)) mask = cv2.resize(a, (hat_w, hat_h)) mask_inv = cv2.bitwise_not(mask) dh = 0 dw = 0 bg_roi = img[y+dh-hat_h:y+dh,(eyes_center[0]-hat_w//3):(eyes_center[0]+hat_w//3*2)]
ROI 提取
进行 ROI 提取
# 用alpha通道作为mask mask = cv2.resize(a, (resized_hat_w, resized_hat_h)) mask_inv = cv2.bitwise_not(mask)
mask 变量,取出了帽子的区域。

mask_inv 变量,用来取出人脸图片中安装帽子的区域。

接下来在人脸图片中取出安装帽子的区域(ROI)
# 原图ROI # bg_roi = img[y+dh-resized_hat_h:y+dh, x+dw:x+dw+resized_hat_w] bg_roi = img[y + dh - resized_hat_h:y + dh, (eyes_center[0] - resized_hat_w // 3):(eyes_center[0] + resized_hat_w // 3 * 2)]
再接下来在人脸图片中取出帽子形状区域
# 原图ROI中提取放帽子的区域
bg_roi = bg_roi.astype(float)
mask_inv = cv2.merge((mask_inv, mask_inv, mask_inv))
alpha = mask_inv.astype(float) / 255
# 相乘之前保证两者大小一致(可能会由于四舍五入原因不一致)
alpha = cv2.resize(alpha, (bg_roi.shape[1], bg_roi.shape[0]))
# print("alpha size: ",alpha.shape)
# print("bg_roi size: ",bg_roi.shape)
bg = cv2.multiply(alpha, bg_roi)
bg = bg.astype('uint8')
这里是把图片默认的uint8类型转换成了float类型进行运算,最后又转换回来。
合成的图片

黑黑的部分就是我们要放置帽子的地方。
在帽子图片中提取帽子部分。
# 提取帽子区域 hat = cv2.bitwise_and(resized_hat, resized_hat, mask=mask)
使用刚刚调整大小的帽子图片来提取。

可以看到,除了帽子部分,其他区域已经掩模处理了。
以上就是提取ROI的过程,比较难懂,需要好好琢磨,尤其是矩阵的切片、mask处理部分。
合成图片
最后一步就是把人脸图片与帽子合成到一起了,也就是把人脸空余帽子部分的图片区域和帽子只展示帽子区域的图片区域(有点拗口)合并在一起。
# 相加之前保证两者大小一致(可能会由于四舍五入原因不一致) hat = cv2.resize(hat, (bg_roi.shape[1], bg_roi.shape[0])) # 两个ROI区域相加 add_hat = cv2.add(bg, hat)
效果如下:

刚刚好,完美叠加图片。
最后把这个片段放回人脸原图中,展示图片
img[y+dh-hat_h:y+dh, (eyes_center[0]-hat_w//3):(eyes_center[0]+hat_w//3*2)] = add_hat

美美的图片就出来啦!
我们再尝试几张不同的图片。


整体效果还不错哦,需要注意的是,在测试的时候,我们尽量选择人脸占比比较大的图片来合成,效果要好很多哦~
以上是用 Python 给你一个圣诞帽的详细内容。更多信息请关注PHP中文网其他相关文章!

 如何在 Windows 11 中清除桌面背景最近的图像历史记录Apr 14, 2023 pm 01:37 PM
如何在 Windows 11 中清除桌面背景最近的图像历史记录Apr 14, 2023 pm 01:37 PM<p>Windows 11 改进了系统中的个性化功能,这使用户可以查看之前所做的桌面背景更改的近期历史记录。当您进入windows系统设置应用程序中的个性化部分时,您可以看到各种选项,更改背景壁纸也是其中之一。但是现在可以看到您系统上设置的背景壁纸的最新历史。如果您不喜欢看到此内容并想清除或删除此最近的历史记录,请继续阅读这篇文章,它将帮助您详细了解如何使用注册表编辑器进行操作。</p><h2>如何使用注册表编辑
 如何在电脑上下载 Windows 聚光灯壁纸图像Aug 23, 2023 pm 02:06 PM
如何在电脑上下载 Windows 聚光灯壁纸图像Aug 23, 2023 pm 02:06 PM窗户从来不是一个忽视美学的人。从XP的田园绿场到Windows11的蓝色漩涡设计,默认桌面壁纸多年来一直是用户愉悦的源泉。借助WindowsSpotlight,您现在每天都可以直接访问锁屏和桌面壁纸的美丽、令人敬畏的图像。不幸的是,这些图像并没有闲逛。如果您爱上了Windows聚光灯图像之一,那么您将想知道如何下载它们,以便将它们作为背景保留一段时间。以下是您需要了解的所有信息。什么是WindowsSpotlight?窗口聚光灯是一个自动壁纸更新程序,可以从“设置”应用中的“个性化>
 如何在Python中使用图像语义分割技术?Jun 06, 2023 am 08:03 AM
如何在Python中使用图像语义分割技术?Jun 06, 2023 am 08:03 AM随着人工智能技术的不断发展,图像语义分割技术已经成为图像分析领域的热门研究方向。在图像语义分割中,我们将一张图像中的不同区域进行分割,并对每个区域进行分类,从而达到对这张图像的全面理解。Python是一种著名的编程语言,其强大的数据分析和数据可视化能力使其成为了人工智能技术研究领域的首选。本文将介绍如何在Python中使用图像语义分割技术。一、前置知识在深入
 如何在Windows上使用PowerToys批量调整图像大小Aug 23, 2023 pm 07:49 PM
如何在Windows上使用PowerToys批量调整图像大小Aug 23, 2023 pm 07:49 PM那些必须每天处理图像文件的人经常不得不调整它们的大小以适应他们的项目和工作的需求。但是,如果要处理的图像太多,则单独调整它们的大小会消耗大量时间和精力。在这种情况下,像PowerToys这样的工具可以派上用场,除其他外,可以使用其图像调整大小器实用程序批量调整图像文件的大小。以下是设置图像调整器设置并开始使用PowerToys批量调整图像大小的方法。如何使用PowerToys批量调整图像大小PowerToys是一个多合一的程序,具有各种实用程序和功能,可帮助您加快日常任务。它的实用程序之一是图像
 2D图像脑补3D人体,衣服随便搭,还能改动作Apr 11, 2023 pm 02:31 PM
2D图像脑补3D人体,衣服随便搭,还能改动作Apr 11, 2023 pm 02:31 PM得益于 NeRF 提供的可微渲染,近期的三维生成模型已经在静止物体上达到了很惊艳的效果。但是在人体这种更加复杂且可形变的类别上,三维生成依旧有很大的挑战。本文提出了一个高效的组合的人体 NeRF 表达,实现了高分辨率(512x256)的三维人体生成,并且没有使用超分模型。EVA3D 在四个大型人体数据集上均大幅超越了已有方案,代码已开源。论文名称:EVA3D: Compositional 3D Human Generation from 2D image Collections论文地址:http
 无需下游训练,Tip-Adapter大幅提升CLIP图像分类准确率Apr 12, 2023 pm 03:25 PM
无需下游训练,Tip-Adapter大幅提升CLIP图像分类准确率Apr 12, 2023 pm 03:25 PM论文链接:https://arxiv.org/pdf/2207.09519.pdf代码链接:https://github.com/gaopengcuhk/Tip-Adapter一.研究背景对比性图像语言预训练模型(CLIP)在近期展现出了强大的视觉领域迁移能力,可以在一个全新的下游数据集上进行 zero-shot 图像识别。为了进一步提升 CLIP 的迁移性能,现有方法使用了 few-shot 的设置,例如 CoOp 和 CLIP-Adapter,即提供了少量下游数据集的训练数据,使得 CLIP
 如何使用Python对图片进行图像去噪处理Aug 18, 2023 am 09:48 AM
如何使用Python对图片进行图像去噪处理Aug 18, 2023 am 09:48 AM如何使用Python对图片进行图像去噪处理图像去噪是图像处理中的一项重要任务,它的目的是去除图像中的噪声,提高图像的质量和清晰度。Python是一种功能强大的编程语言,拥有丰富的图像处理库,如PIL、OpenCV等,可以帮助我们实现图像去噪的功能。本文将介绍如何使用Python对图片进行图像去噪处理,并给出相应的代码示例。导入所需的库首先,我们需要导入所需的
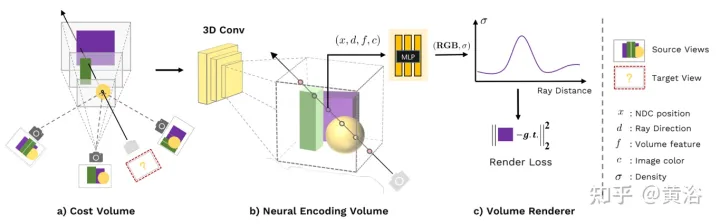 新视角图像生成:讨论基于NeRF的泛化方法Apr 09, 2023 pm 05:31 PM
新视角图像生成:讨论基于NeRF的泛化方法Apr 09, 2023 pm 05:31 PM新视角图像生成(NVS)是计算机视觉的一个应用领域,在1998年SuperBowl的比赛,CMU的RI曾展示过给定多摄像头立体视觉(MVS)的NVS,当时这个技术曾转让给美国一家体育电视台,但最终没有商业化;英国BBC广播公司为此做过研发投入,但是没有真正产品化。在基于图像渲染(IBR)领域,NVS应用有一个分支,即基于深度图像的渲染(DBIR)。另外,在2010年曾很火的3D TV,也是需要从单目视频中得到双目立体,但是由于技术的不成熟,最终没有流行起来。当时基于机器学习的方法已经开始研究,比


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

Dreamweaver CS6
视觉化网页开发工具

禅工作室 13.0.1
功能强大的PHP集成开发环境

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

Atom编辑器mac版下载
最流行的的开源编辑器

