



从来没有见过的新物体,它也能进行很好地分割。
这是DeepMind研究出的一种新的学习框架:目标发现和表示网络(Object discovery and representation networks,简称Odin)

以往的自我监督学习(SSL)方法能够很好地描述整个大的场景,但是很难区分出单个的物体。
现在,Odin方法做到了,并且是在没有任何监督的情况下做到的。
区分出图像中的单个物体可不是很容易的事,它是怎么做到的呢?
方法原理
能够很好地区分出图像中的各个物体,主要归功于Odin学习框架的“自我循环”。
Odin学习了两组协同工作的网络,分别是目标发现网络和目标表示网络。
目标发现网络以图像的一个裁剪部分作为输入,裁剪的部分应该包含图像的大部分区域,且这部分图像并没有在其他方面进行增强处理。
然后对输入图像生成的特征图进行聚类分析,根据不同的特征对图像中各个物体的进行分割。

目标表示网络的输入视图是目标发现网络中所生成的分割图像。
视图输入之后,对它们分别进行随机预处理,包括翻转、模糊和点级颜色转换等。
这样就能够获得两组掩模,它们除了剪裁之外的差异,其他信息都和底层图像内容相同。
而后两个掩模会通过对比损失,进而学习能够更好地表示图像中物体的特征。
具体来说,就是通过对比检测,训练一个网络来识别不同目标物体的特征,同时还有许多来自其他不相干物体的“负面”特征。
然后,最大化不同掩模中同一目标物体的相似性,最小化不同目标物体之间的相似性,进而更好地进行分割以区别不同目标物体。

与此同时,目标发现网络会定期根据目标表示网络的参数进行相应的更新。
最终的目的是确保这些对象级的特性在不同的视图中大致不变,换句话说就是将图像中的物体分隔开来。
那么Odin学习框架的效果究竟如何呢?
能够很好地区分未知物体
Odin方法在场景分割时,没有先验知识的情况下迁移学习的性能也很强大。
首先,使用Odin方法在ImageNet数据集上进行预训练,然后评估其在COCO数据集以及PASCAL和Cityscapes语义分割上的效果。
已经知道目标物体,即获得先验知识的方法在进行场景分割时,效果要明显好于其他未获得先验知识的方法。
而Odin方法即使未获得先验知识,其效果也要优于获得先验知识的DetCon和ReLICv2。


除此之外,Odin方法不仅可以应用在ResNet模型中,还可以应用到更复杂的模型中,如Swim Transformer。

在数据上,Odin框架学习的优势很明显,那在可视化的图像中,Odin的优势在何处体现了呢?
将使用Odin生成的分割图像与随机初始化的网络(第3列),ImageNet监督的网络(第4列)中获得的分割图像进行比较。
第3、4列都未能清晰地描绘出物体的边界,或者缺乏现实世界物体的一致性和局部性,而Odin生成的图像效果很明显要更好一些。

参考链接:
[1] https://twitter.com/DeepMind/status/1554467389290561541
[2] https://arxiv.org/abs/2203.08777
以上是未知物体也能轻松识别分割,效果可迁移的详细内容。更多信息请关注PHP中文网其他相关文章!


 您需要查看的3台Openai' s的动手实验 - 分析VidhyaApr 13, 2025 am 11:06 AM
您需要查看的3台Openai' s的动手实验 - 分析VidhyaApr 13, 2025 am 11:06 AM介绍 您在讲话之前真正思考和理性多久?当前最新的LLM GPT-4O已经在不花很多时间做出回应的情况下提供了令人印象深刻的回应。但是想象一下它是否开始服用
 如何访问OpenAi O1? - 分析VidhyaApr 13, 2025 am 11:05 AM
如何访问OpenAi O1? - 分析VidhyaApr 13, 2025 am 11:05 AM介绍 草莓在市场上!!!我希望这将像其他OpenAI最新车型带来的人工智能的最新进步一样富有成果。 我们一直在等待GPT-5这么长时间
 使用llamaindex构建多文件代理抹布Apr 13, 2025 am 11:03 AM
使用llamaindex构建多文件代理抹布Apr 13, 2025 am 11:03 AM介绍 在人工智能快速发展的领域中,处理和理解大量信息的能力变得越来越重要。输入多文件代理抹布 - 一个功能强大的应用
 免费学习SQL的YouTube频道 - 分析VidhyaApr 13, 2025 am 10:46 AM
免费学习SQL的YouTube频道 - 分析VidhyaApr 13, 2025 am 10:46 AM介绍 掌握SQL(结构化查询语言)对于追求数据管理,数据分析和数据库管理的个人至关重要。如果您是从新手开始的,或者是经验丰富的专业人士,请寻求改进,
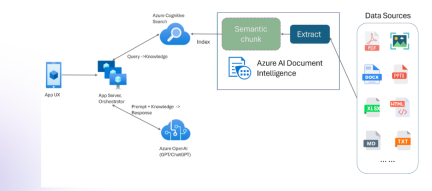 具有多模式和Azure文档智能的抹布Apr 13, 2025 am 10:38 AM
具有多模式和Azure文档智能的抹布Apr 13, 2025 am 10:38 AM介绍 在基于数据运行的当前世界中,关系AI图(RAG)通过关联数据并绘制关系来对行业产生很大影响。但是,如果一个人可以再进一步多怎么办
 在生成AI时代负责的AIApr 13, 2025 am 10:28 AM
在生成AI时代负责的AIApr 13, 2025 am 10:28 AM介绍 现在,我们生活在人工智能时代,我们周围的一切都在一天变得更加聪明。最先进的大语言模型(LLM)和AI代理,能够执行复杂的任务
 GPT-4O vs OpenAI O1:新的Openai模型值得炒作吗?Apr 13, 2025 am 10:18 AM
GPT-4O vs OpenAI O1:新的Openai模型值得炒作吗?Apr 13, 2025 am 10:18 AM介绍 Openai已根据备受期待的“草莓”建筑发布了其新模型。这种称为O1的创新模型增强了推理能力,使其可以通过问题进行思考


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

Dreamweaver Mac版
视觉化网页开发工具

