


如何在卷积神经网络上运行 BERT?
你可以直接用 SparK —— 字节跳动技术团队提出的稀疏层次化掩码建模 (Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling),近期已被人工智能顶会收录为 Spotlight 焦点论文:

论文链接:
https://www.php.cn/link/e38e37a99f7de1f45d169efcdb288dd1
开源代码:
https://www.php.cn/link/9dfcf16f0adbc5e2a55ef02db36bac7f
这也是 BERT 在卷积神经网络 (CNN) 上的首次成功。先来感受一下 SparK 在预训练中的表现吧。
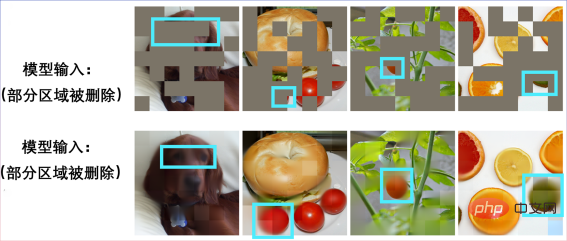
输入一张残缺不全的图片:

还原出一只小狗:

另一张残缺图片:

原来是贝果三明治:

其他场景也可实现图片复原:

BERT 和 Transformer 的天作之合
“任何伟大的行动和思想,都有一个微不足道的开始。”
在 BERT 预训练算法的背后,是简洁而深刻的设计。 BERT 使用“完形填空”:将一句话中的若干词语进行随机删除,并让模型学会恢复。
BERT 非常依赖于 NLP 领域的核心模型 —— Transformer。
Transformer 由于生来就适合处理可变长度的序列数据(例如一个英文句子),所以能轻松应付 BERT 完形填空的“随机删除”。
视觉领域的 CNN 也想享受 BERT:两个挑战何在?
回顾计算机视觉发展史,卷积神经网络模型凝练了平移等变性、多尺度结构等等众多经典模型精华,可谓CV 界的中流砥柱。但与 Transformer 大相径庭的是,CNN 天生无法适应经过完形填空“挖空”的、充满“随机孔洞”的数据,因此乍一看无法享受到 BERT 预训练的红利。
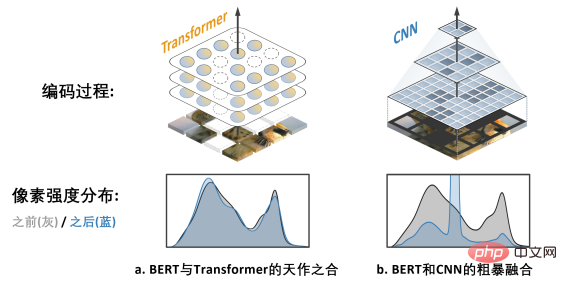
上图 a. 展示的是 MAE (Masked Autoencoders are Scalable Visual Learners) 这项工作,由于使用的是 Transformer 模型而非 CNN 模型,其可以灵活应对经过带有空洞的输入,乃与 BERT “天作之合”。
而右图 b. 则展示了一种粗暴融合 BERT 和 CNN 模型的方式——即把全部空洞区域“涂黑”,并将这张“黑马赛克”图输入到 CNN 中,结果可想而知,会带来严重的像素强度分布偏移问题,并导致很差的性能 (后文有验证)。这就是阻碍 BERT 在 CNN 上成功应用的挑战一。
此外,作者团队还指出,源自 NLP 领域的 BERT 算法,天然不具备“多尺度”的特点,而多尺度的金字塔结构在计算机视觉的悠久历史中可谓“金标准”。单尺度的 BERT,和天然多尺度的 CNN 之间的冲突,则是挑战二。
解决方案 SparK:稀疏且层次化的掩码建模
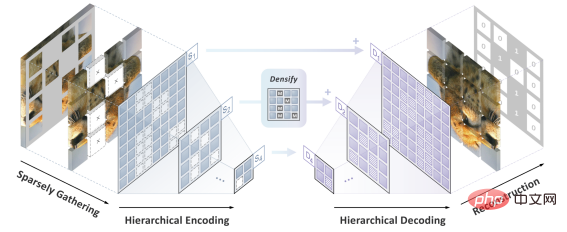
作者团队提出了 SparK (Sparse and hierarchical masKed modeling) 来解决前文两个挑战。
其一,受三维点云数据处理的启发,作者团队提出将经过掩码操作 (挖空操作) 后的零碎图片视为稀疏点云,并使用子流形稀疏卷积 (Submanifold Sparse Convolution) 来进行编码。这就让卷积网络能够自如处理随机删除后的图像。
其二,受 UNet 优雅设计的启发,作者团队自然地设计了一种带有横向连接的编码器-解码器模型,让多尺度特征在模型的多层次之间流动,让 BERT 彻底拥抱计算机视觉的多尺度黄金标准。
至此,一种为卷积网络 (CNN) 量身定制的稀疏的、多尺度的掩码建模算法 SparK 诞生了。
SparK 是通用的:其可被直接运用在任何卷积网络上,而无需对它们的结构进行任何修改,或引入任何额外的组件——不论是我们耳熟能详的经典 ResNet,还是近期的先进模型 ConvNeXt,均可直接从 SparK 中受益。
从 ResNet 到 ConvNeXt:三大视觉任务性能提升
作者团队选择了具代表性的两个卷积模型家族 ResNet 和 ConvNeXt,并在图像分类,目标检测、实例分割任务上进行了性能测试。
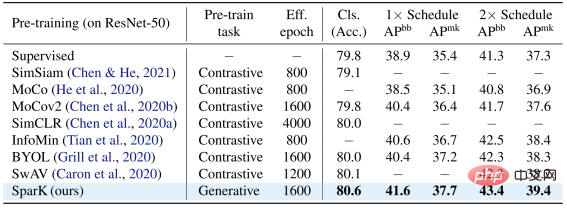
在经典 ResNet-50 模型上,SparK 作为唯一的生成式预训练,达到了 State-of-the-art 水准:
在 ConvNeXt 模型上,SparK 依旧领先。在预训练前,ConvNeXt 与 Swin-Transformer 平分秋色;而经预训练后,ConvNeXt 在三个任务上均压倒性超过了 Swin-Transformer:
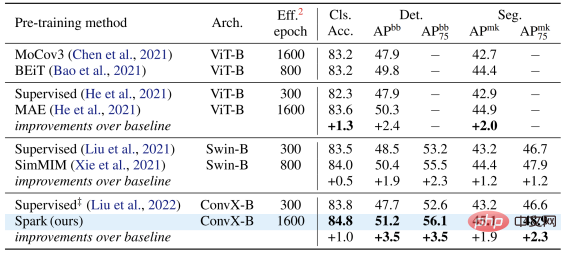
当从小到大,在完整的模型家族上验证 SparK,便可观察到:
无论模型的大与小、新与旧,均可从 SparK 中受益,且随着模型尺寸/训练开销的增长,涨幅甚至更高,体现出 SparK 算法的扩放 (scaling) 能力:
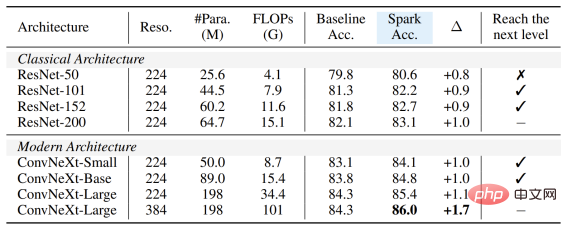
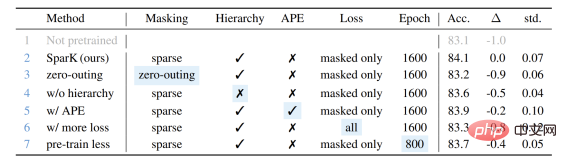
最后,作者团队还设计了一个验证性的消融实验,从中可见稀疏掩码和层次化结构第3行和第4行) 均是非常关键的设计,一旦缺失就会造成严重的性能衰退:
以上是BERT在CNN上也能用?字节跳动研究成果中选ICLR 2023 Spotlight的详细内容。更多信息请关注PHP中文网其他相关文章!

 字节跳动旗下视频编辑 App CapCut 全球用户总支出超 1 亿美元Sep 14, 2023 pm 09:41 PM
字节跳动旗下视频编辑 App CapCut 全球用户总支出超 1 亿美元Sep 14, 2023 pm 09:41 PM字节跳动旗下的创意视频剪辑工具CapCut在中国、美国和东南亚拥有大量用户。该工具支持安卓、iOS和PC平台市场调研机构data.ai最新报告指出,截至2023年9月11日,CapCut在iOS和GooglePlay上的用户总支出已突破1亿美元(本站备注:当前约7.28亿元人民币),成功超越Splice(2022年下半年排名第一)成为2023年上半年全球最吸金的视频剪辑应用,与2022年下半年相比增长了180%。截至2023年8月,全球有4.9亿人通过iPhone和安卓手机使用CapCut。da
 字节跳动模型大规模部署实战Apr 12, 2023 pm 08:31 PM
字节跳动模型大规模部署实战Apr 12, 2023 pm 08:31 PM一. 背景介绍在字节跳动,基于深度学习的应用遍地开花,工程师关注模型效果的同时也需要关注线上服务一致性和性能,早期这通常需要算法专家和工程专家分工合作并紧密配合来完成,这种模式存在比较高的 diff 排查验证等成本。随着 PyTorch/TensorFlow 框架的流行,深度学习模型训练和在线推理完成了统一,开发者仅需要关注具体算法逻辑,调用框架的 Python API 完成训练验证过程即可,之后模型可以很方便的序列化导出,并由统一的高性能 C++ 引擎完成推理工作。提升了开发者训练到部署的体验
 深圳字节跳动后海中心总建筑面积 7.74 万平方米完成主体结构封顶Jan 24, 2024 pm 05:27 PM
深圳字节跳动后海中心总建筑面积 7.74 万平方米完成主体结构封顶Jan 24, 2024 pm 05:27 PM据南山区政府官方微信公众号“创新南山”透露,深圳字节跳动后海中心项目最近取得了重要进展。根据中建一局建设发展公司的消息,该项目主体结构提前3天全部完成封顶工作。这一消息意味着南山后海核心区将迎来一个新的地标建筑。深圳字节跳动后海中心项目位于南山区后海核心区,是今日头条科技有限公司在深圳市的总部办公大楼。总建筑面积为7.74万平方米,高约150米,共有地下4层和地上32层。据悉,深圳字节跳动后海中心项目将成为一座创新型超高层建筑,集办公、娱乐、餐饮等功能为一体。该项目将有助于深圳推动互联网产业的集
 NUS和字节跨界合作,通过模型优化实现训练提速72倍,并荣获AAAI2023杰出论文。May 06, 2023 pm 10:46 PM
NUS和字节跨界合作,通过模型优化实现训练提速72倍,并荣获AAAI2023杰出论文。May 06, 2023 pm 10:46 PM近日,人工智能国际顶会AAAI2023公布评选结果。新加坡国立大学(NUS)与字节跳动机器学习团队(AML)合作的CowClip技术论文入围杰出论文(DistinguishedPapers)。CowClip是一项模型训练优化策略,可以在保证模型精度的前提下,实现在单张GPU上的模型训练速度提升72倍,相关代码现已开源。论文地址:https://arxiv.org/abs/2204.06240开源地址:https://github.com/bytedance/LargeBatchCTRAAA
 字节跳动拓展全球研发中心,派遣工程师加拿大和澳大利亚等地Jan 18, 2024 pm 04:00 PM
字节跳动拓展全球研发中心,派遣工程师加拿大和澳大利亚等地Jan 18, 2024 pm 04:00 PMIT之家1月18日消息,针对近日TikTok国内员工转岗海外的传言,据接近字节跳动的人士透露,该公司正在加拿大、澳大利亚等地筹建研发中心。目前,部分研发中心已试运营半年左右,未来将支持TikTok、CapCut、Lemon8等多个海外业务研发。字节跳动计划以当地招聘为主,并辅助少量外派的方式筹建相关研发中心。据了解,过去半年,该公司已从美国、中国、新加坡等地选派少量工程师参与筹建。其中,从中国向两地研发中心累计派出包括产品、研发和运营岗位120人。相关人士表示,此举是为了应对海外业务的发展,更好
 PICO 4 销量远远低于预期,消息称字节跳动将取消下一代 VR 头显 PICO 5Dec 15, 2023 am 09:34 AM
PICO 4 销量远远低于预期,消息称字节跳动将取消下一代 VR 头显 PICO 5Dec 15, 2023 am 09:34 AM本站12月13日消息,据TheInformation,字节跳动准备砍掉其PICO新一代VR头显PICO5,因为现款PICO4的销量远远低于预期。根据EqualOcean在今年10月的一篇文章,据称字节跳动将逐步关闭PICO,并放弃元宇宙领域。文章指出,字节跳动认为PICO所处的硬件领域并非其专长,几年来的成绩未达到预期,并且对未来缺乏希望在当时,字节跳动的相关负责人对于关于“逐步放弃PICO业务”的传闻进行了回应,称这一消息是不实的。他们表示PICO业务仍在正常运营,并且公司将会长期投入扩展现实
 抖音子公司推出基于云雀模型的 AI 机器人“豆包”Aug 23, 2023 am 10:53 AM
抖音子公司推出基于云雀模型的 AI 机器人“豆包”Aug 23, 2023 am 10:53 AM本站8月17日消息,字节跳动旗下LLM人工智能机器人“豆包”现已开始小范围邀请测试,用户可通过手机号、抖音或者AppleID登录。根据报道,据称字节跳动公司开发了一款名为"豆包"的AI工具,该工具基于云雀模型,提供聊天机器人、写作助手和英语学习助手等功能。它可以回答各种问题并进行对话,帮助人们获取信息。"豆包"支持网页Web平台、iOS和安卓平台,但在iOS平台上需要通过TestFlight进行安装官网用户协议显示,“豆包”软件及相关服务系指北京春田知韵科
 Go语言在华为、字节跳动等知名公司的应用案例解析Mar 07, 2024 pm 03:51 PM
Go语言在华为、字节跳动等知名公司的应用案例解析Mar 07, 2024 pm 03:51 PMGo语言作为一种高效、简洁的编程语言,近年来在许多知名公司中得到广泛应用。本文将以华为和字节跳动这两家知名公司为例,分析它们在Go语言领域的应用案例,并提供具体的代码示例。华为华为作为全球领先的信息通信技术解决方案提供商,一直致力于技术创新和产品研发。在软件开发方面,华为工程师们也积极尝试新技术,其中Go语言成为他们越来越重要的选择之一。1.Prometh


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3汉化版
中文版,非常好用

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

禅工作室 13.0.1
功能强大的PHP集成开发环境

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

WebStorm Mac版
好用的JavaScript开发工具

