




大家好,我是啃书君!
正所谓:有朋自远方来,不亦乐乎?有朋友来找我们玩,是一件很快乐的事情,那么我们要尽地主之谊,好好带朋友去玩耍!那么问题来了,什么时候去哪里玩最好呢,哪里玩的地方最多呢?
今天将手把手教你使用线程池爬取同程旅行的景点信息及评论数据并做词云、数据可视化!!!带你了解各个城市的游玩景点信息。
在开始爬取数据之前,我们首先来了解一下线程。
线程
进程:进程是代码在数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位。
线程:是轻量级的进程,是程序执行的最小单元,是进程的一个执行路径。
一个进程中至少有一个线程,进程中的多个线程共享进程的资源。
线程生命周期
在创建多线程之前,我们先来学习一下线程生命周期,如下图所示:
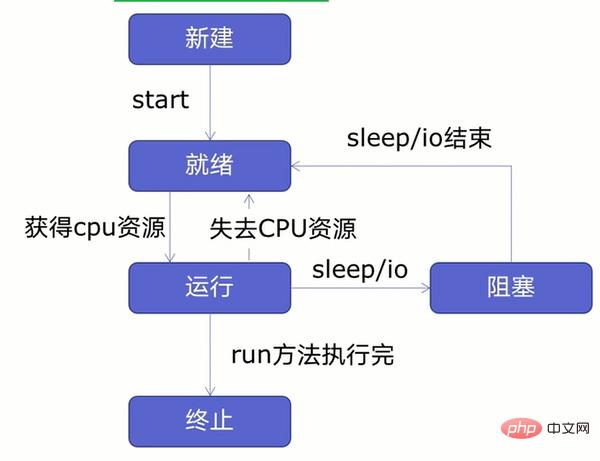
由图可知,线程可以分为五个状态——新建、就绪、运行、阻塞、终止。
首先新建一个线程并开启线程后线程进入就绪状态,就绪状态的线程不会马上运行,要获得CPU资源才会进入运行状态,在进入运行状态后,线程有可能会失去CPU资源或者遇到休眠、io操作(读写等操作)线程进入就绪状态或者阻塞状态,要等休眠、io操作结束或者重新获得CPU资源后,才会进入运行状态,等到运行完后进入终止状态。
注意:新建线程系统是需要分配资源的,终止线程系统是需要回收资源的,那么如何减去新建/终止线程的系统开销呢,这时我们可以创建线程池来重用线程,这样就可以减少系统的开销了。
在创建线程池之前,我们先来学习如何创建多线程。
创建多线程
创建多线程可以分为四步:
- 创建函数;
- 创建线程;
- 启动线程;
- 等待结束;
创建函数
为了方便演示,我们拿博客园的网页做爬虫函数,具体代码如下所示:
import requests
urls=[
f'https://www.cnblogs.com/#p{page}'
for page in range(1,50)
]
def get_parse(url):
response=requests.get(url)
print(url,len(response.text))首先导入requests网络请求库,把我们所有的要爬取的URL保存在列表中,然后自定义函数get_parse来发送网络请求、打印请求的URL和响应的字符长度。
创建线程
在上一步我们创建了爬虫函数,接下来将创建线程了,具体代码如下所示:
import threading #多线程 def multi_thread(): threads=[] for url in urls: threads.append( threading.Thread(target=get_parse,args=(url,)) )
首先我们导入threading模块,自定义multi_thread函数,再创建一个空列表threads来存放线程任务,通过threading.Thread()方法来创建线程。其中:
- target为运行函数;
- args为运行函数所需的参数。
注意args中的参数要以元组的方式传入,然后通过.append()方法把线程添加到threads空列表中。
启动线程
线程已经创建好了,接下来将启动线程了,启动线程很简单,具体代码如下所示:
for thread in threads: thread.start()
首先我们通过for循环把threads列表中的线程任务获取下来,通过.start()来启动线程。
等待结束
启动线程后,接下来将等待线程结束,具体代码如下所示:
for thread in threads: thread.join()
和启动线程一样,先通过for循环把threads列表中的线程任务获取下来,再使用.join()方法等待线程结束。
多线程已经创建好了,接下来将测试一下多线程的速度如何,具体代码如下所示:
if __name__ == '__main__': t1=time.time() multi_thread() t2=time.time() print(t2-t1)
运行结果如下图所示:
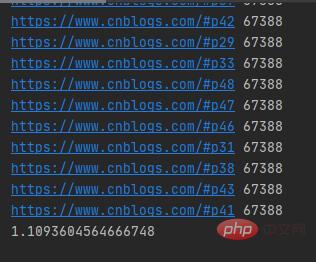
多线程爬取50个博客园网页只要1秒多,而且多线程的发送网络请求的URL是随机的。
我们来测试一下单线程的运行时间,具体代码如下所示:
if __name__ == '__main__': t1=time.time() for i in urls: get_parse(i) t2=time.time() print(t2-t1)
运行结果如下图所示:
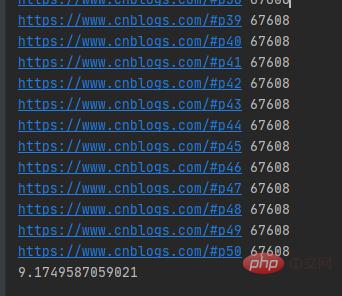
单线程爬取50个博客园网页用了9秒多,单线程的发送网络请求的URL是按顺序的。
在上面我们说了,新建线程系统是需要分配资源的,终止线程系统是需要回收资源的,为了减少系统的开销,我们可以创建线程池。
线程池原理
一个线程池由两部分组成,如下图所示:
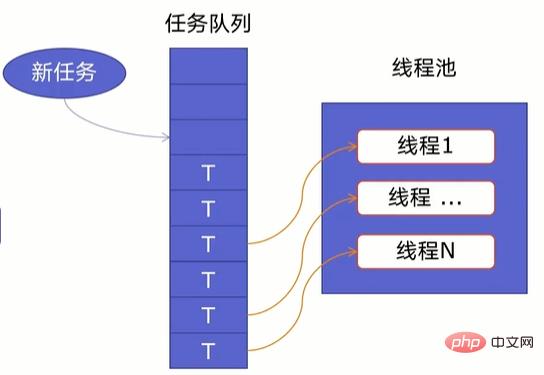
- 线程池:里面提前建好N个线程,这些都会被重复利用;
- 任务队列:当有新任务的时候,会把任务放在任务队列中。
当任务队列里有任务时,线程池的线程会从任务队列中取出任务并执行,执行完任务后,线程会执行下一个任务,直到没有任务执行后,线程会回到线程池中等待任务。
使用线程池可以处理突发性大量请求或需要大量线程完成任务(处理时间较短的任务)。
好了,了解了线程池原理后,我们开始创建线程池。
线程池创建
Python提供了ThreadPoolExecutor类来创建线程池,其语法如下所示:
ThreadPoolExecutor(max_workers=None, thread_name_prefix='', initializer=None, initargs=())
其中:
- max_workers:最大线程数;
- thread_name_prefix:允许用户控制由线程池创建的threading.Thread工作线程名称以方便调试;
- initializer:是在每个工作者线程开始处调用的一个可选可调用对象;
- initargs:传递给初始化器的元组参数。
注意:在启动 max_workers 个工作线程之前也会重用空闲的工作线程。
在ThreadPoolExecutor类中提供了map()和submit()函数来插入任务队列。其中:
map()函数
map()语法格式为:
map(调用方法,参数队列)
具体示例如下所示:
import requestsimport concurrent.futuresimport timeurls=[f'https://www.cnblogs.com/#p{page}'for page in range(1,50)]def get_parse(url):response=requests.get(url)return response.textdef map_pool():with concurrent.futures.ThreadPoolExecutor(max_workers=20) as pool:htmls=pool.map(get_parse,urls)htmls=list(zip(urls,htmls))for url,html in htmls:print(url,len(html))if __name__ == '__main__':t1=time.time()map_pool()t2=time.time()print(t2-t1)首先我们导入requests网络请求库、concurrent.futures模块,把所有的URL放在urls列表中,然后自定义get_parse()方法来返回网络请求返回的数据,再自定义map_pool()方法来创建代理池,其中代理池的最大max_workers为20,调用map()方法把网络请求任务放在任务队列中,在把返回的数据和URL合并为元组,并放在htmls列表中。
运行结果如下图所示:
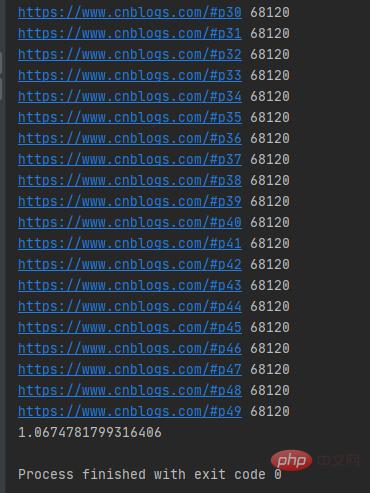
可以发现map()函数返回的结果和传入的参数顺序是对应的。
注意:当我们直接在自定义方法get_parse()中打印结果时,打印结果是乱序的。
submit()函数
submit()函数语法格式如下:
submit(调用方法,参数)
具体示例如下:
def submit_pool():with concurrent.futures.ThreadPoolExecutor(max_workers=20)as pool:futuress=[pool.submit(get_parse,url)for url in urls]futures=zip(urls,futuress)for url,future in futures:print(url,len(future.result()))
运行结果如下图所示:
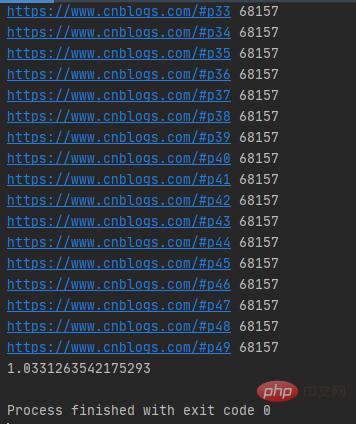
注意:submit()函数输出结果需需要调用result()方法。
好了,线程知识就学到这里了,接下来开始我们的爬虫。
爬前分析
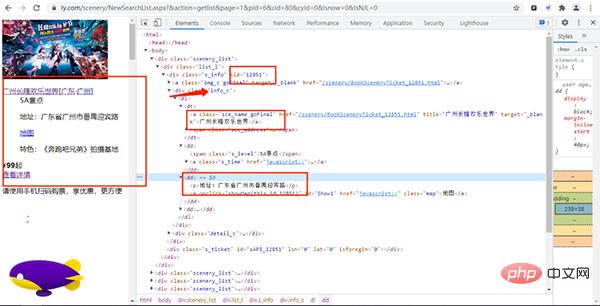
首先我们进入同程旅行的景点网页并打开开发者工具,如下图所示:
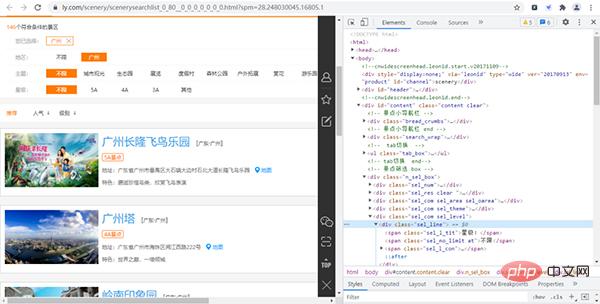
经过寻找,我们发现各个景点的基础信息(详情页URL、景点id等)都存放在下图的URL链接中,
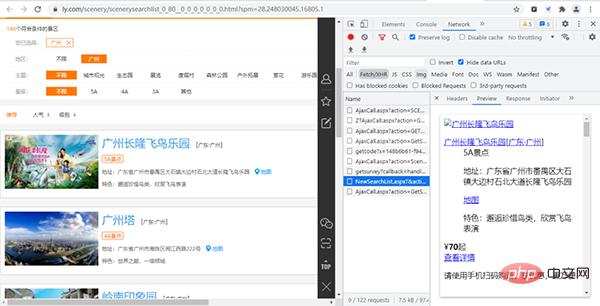
其URL链接为:
https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page=2&kw=&pid=6&cid=80&cyid=0&sort=&isnow=0&spType=&lbtypes=&IsNJL=0&classify=0&grade=&dctrack=1%CB%871629537670551030%CB%8720%CB%873%CB%872557287248299209%CB%870&iid=0.6901326566387387
经过增删改查操作,我们可以把该URL简化为:
https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page=1&pid=6&cid=80&cyid=0&isnow=0&IsNJL=0
其中page为我们翻页的重要参数。
打开该URL链接,如下图所示:
通过上面的URL链接,我们可以获取到很多景点的基础信息,随机打开一个景点的详情网页并打开开发者模式,经过查找,评论数据存放在如下图的URL链接中,
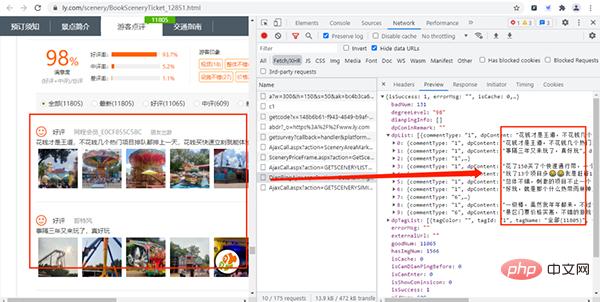
其URL链接如下所示:
https://www.ly.com/scenery/AjaxHelper/DianPingAjax.aspx?action=GetDianPingList&sid=12851&page=1&pageSize=10&labId=1&sort=0&iid=0.48901069375088
其中:action、labId、iid、sort为常量,sid是景点的id,page控制翻页,pageSize是每页获取的数据量。
在上上步中,我们知道景点id的存放位置,那么构造评论数据的URL就很简单了。
实战演练
这次我们爬虫步骤是:
- 获取景点基本信息
- 获取评论数据
- 创建MySQL数据库
- 保存数据
- 创建线程池
- 数据分析
获取景点基本信息
首先我们先获取景点的名字、id、价格、特色、地点和等级,主要代码如下所示:
def get_parse(url):response=requests.get(url,headers=headers)Xpath=parsel.Selector(response.text)data=Xpath.xpath('/html/body/div')for i in data:Scenery_data={'title':i.xpath('./div/div[1]/div[1]/dl/dt/a/text()').extract_first(),'sid':i.xpath('//div[@]/div/@sid').extract_first(),'Grade':i.xpath('./div/div[1]/div[1]/dl/dd[1]/span/text()').extract_first(), 'Detailed_address':i.xpath('./div/div[1]/div[1]/dl/dd[2]/p/text()').extract_first().replace('地址:',''),'characteristic':i.xpath('./div/div[1]/div[1]/dl/dd[3]/p/text()').extract_first(),'price':i.xpath('./div/div[1]/div[2]/div[1]/span/b/text()').extract_first(),'place':i.xpath('./div/div[1]/div[1]/dl/dd[2]/p/text()').extract_first().replace('地址:','')[6:8]}首先自定义方法get_parse()来发送网络请求后使用parsel.Selector()方法来解析响应的文本数据,然后通过xpath来获取数据。
获取评论数据
获取景点基本信息后,接下来通过景点基本信息中的sid来构造评论信息的URL链接,主要代码如下所示:
def get_data(Scenery_data):for i in range(1,3):link = f'https://www.ly.com/scenery/AjaxHelper/DianPingAjax.aspx?action=GetDianPingList&sid={Scenery_data["sid"]}&page={i}&pageSize=100&labId=1&sort=0&iid=0.20105777381446832'response=requests.get(link,headers=headers)Json=response.json()commtent_detailed=Json.get('dpList')# 有评论数据if commtent_detailed!=None:for i in commtent_detailed:Comment_information={'dptitle':Scenery_data['title'],'dpContent':i.get('dpContent'),'dpDate':i.get('dpDate')[5:7],'lineAccess':i.get('lineAccess')}#没有评论数据elif commtent_detailed==None:Comment_information={'dptitle':Scenery_data['title'],'dpContent':'没有评论','dpDate':'没有评论','lineAccess':'没有评论'}首先自定义方法get_data()并传入刚才获取的景点基础信息数据,然后通过景点基础信息的sid来构造评论数据的URL链接,当在构造评论数据的URL时,需要设置pageSize和page这两个变量来获取多条评论和进行翻页,构造URL链接后就发送网络请求。
这里需要注意的是:有些景点是没有评论,所以我们需要通过if语句来进行设置。
创建MySQL数据库
这次我们把数据存放在MySQL数据库中,由于数据比较多,所以我们把数据分为两种数据表,一种是景点基础信息表,一种是景点评论数据表,主要代码如下所示:
#创建数据库def create_db():db=pymysql.connect(host=host,user=user,passwd=passwd,port=port)cursor=db.cursor()sql='create database if not exists commtent default character set utf8'cursor.execute(sql)db.close()create_table()#创建景点信息数据表def create_table():db=pymysql.connect(host=host,user=user,passwd=passwd,port=port,db='commtent')cursor=db.cursor()sql = 'create table if not exists Scenic_spot_data (title varchar(255) not null, link varchar(255) not null,Grade varchar(255) not null, Detailed_address varchar(255) not null, characteristic varchar(255)not null, price int not null, place varchar(255) not null)'cursor.execute(sql)db.close()
首先我们调用pymysql.connect()方法来连接数据库,通过.cursor()获取游标,再通过.execute()方法执行单条的sql语句,执行成功后返回受影响的行数,然后关闭数据库连接,最后调用自定义方法create_table()来创建景点信息数据表。
这里我们只给出了创建景点信息数据表的代码,因为创建数据表只是sql这条语句稍微有点不同,其他都一样,大家可以参考这代码来创建各个景点评论数据表。
保存数据
创建好数据库和数据表后,接下来就要保存数据了,主要代码如下所示:
首先我们调用pymysql.connect()方法来连接数据库,通过.cursor()获取游标,再通过.execute()方法执行单条的sql语句,执行成功后返回受影响的行数,使用了try-except语句,当保存的数据不成功,就调用rollback()方法,撤消当前事务中所做的所有更改,并释放此连接对象当前使用的任何数据库锁。
#保存景点数据到景点数据表中def saving_scenery_data(srr):db = pymysql.connect(host=host, user=user, password=passwd, port=port, db='commtent')cursor = db.cursor()sql = 'insert into Scenic_spot_data(title, link, Grade, Detailed_address, characteristic,price,place) values(%s,%s,%s,%s,%s,%s,%s)'try:cursor.execute(sql, srr)db.commit()except:db.rollback()db.close()
注意:srr是传入的景点信息数据。
创建线程池
好了,单线程爬虫已经写好了,接下来将创建一个函数来创建我们的线程池,使单线程爬虫变为多线程,主要代码如下所示:
urls = [f'https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page={i}&pid=6&cid=80&cyid=0&isnow=0&IsNJL=0'for i in range(1, 6)]def multi_thread():with concurrent.futures.ThreadPoolExecutor(max_workers=8)as pool:h=pool.map(get_parse,urls)if __name__ == '__main__':create_db()multi_thread()创建线程池的代码很简单就一个with语句和调用map()方法
运行结果如下图所示:
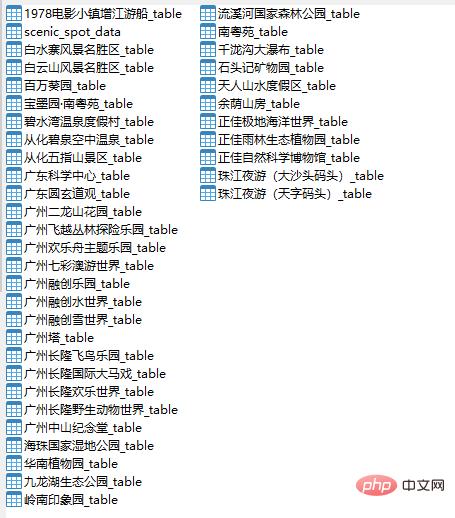
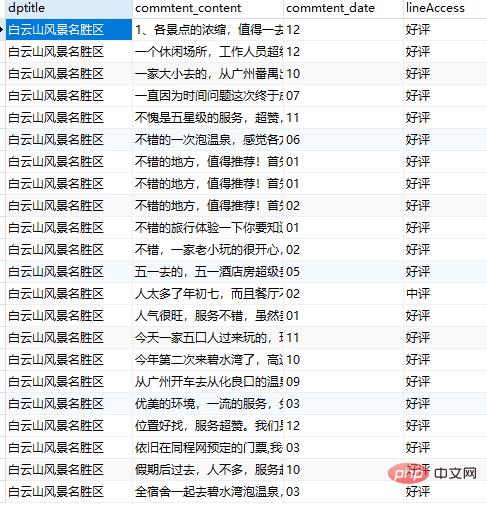
好了,数据已经获取到了,接下来将进行数据分析。
数据可视化
首先我们来分析一下各个景点那个月份游玩的人数最多,这样我们就不用担心去游玩的时机不对了。
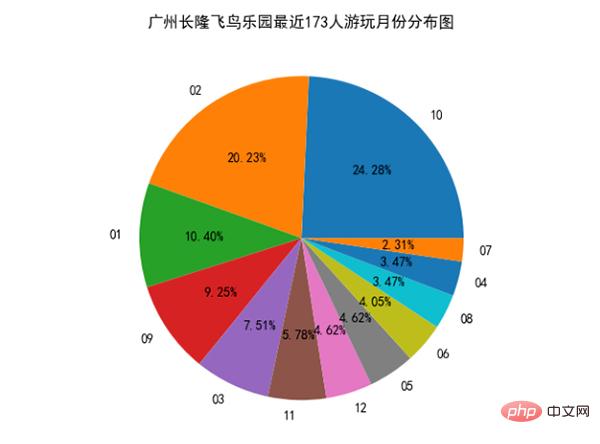
我们发现10月、2月、1月去广州长隆飞鸟乐园游玩的人数占总体比例最多。分析完月份后,我们来看看评论情况如何:
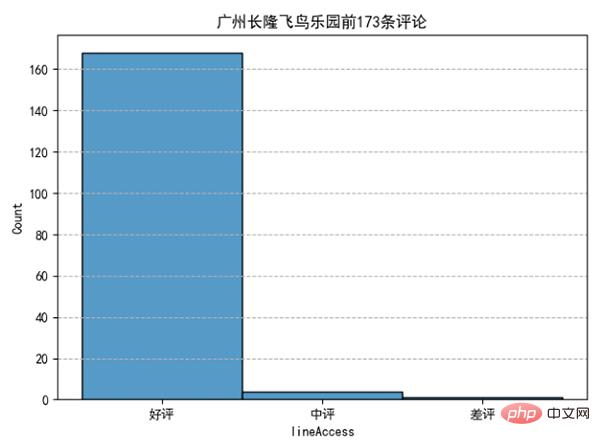
可以发现去好评占了绝大部分,可以说:去长隆飞鸟乐园玩耍,去了都说好。看了评论情况,评论内容有什么:

好了,获取旅游景点信息及评论并做词云、数据可视化就讲到这里了。
以上是Python 获取旅游景点信息及评论并作词云、数据可视化的详细内容。更多信息请关注PHP中文网其他相关文章!

 学习Python:2小时的每日学习是否足够?Apr 18, 2025 am 12:22 AM
学习Python:2小时的每日学习是否足够?Apr 18, 2025 am 12:22 AM每天学习Python两个小时是否足够?这取决于你的目标和学习方法。1)制定清晰的学习计划,2)选择合适的学习资源和方法,3)动手实践和复习巩固,可以在这段时间内逐步掌握Python的基本知识和高级功能。
 Web开发的Python:关键应用程序Apr 18, 2025 am 12:20 AM
Web开发的Python:关键应用程序Apr 18, 2025 am 12:20 AMPython在Web开发中的关键应用包括使用Django和Flask框架、API开发、数据分析与可视化、机器学习与AI、以及性能优化。1.Django和Flask框架:Django适合快速开发复杂应用,Flask适用于小型或高度自定义项目。2.API开发:使用Flask或DjangoRESTFramework构建RESTfulAPI。3.数据分析与可视化:利用Python处理数据并通过Web界面展示。4.机器学习与AI:Python用于构建智能Web应用。5.性能优化:通过异步编程、缓存和代码优
 Python vs.C:探索性能和效率Apr 18, 2025 am 12:20 AM
Python vs.C:探索性能和效率Apr 18, 2025 am 12:20 AMPython在开发效率上优于C ,但C 在执行性能上更高。1.Python的简洁语法和丰富库提高开发效率。2.C 的编译型特性和硬件控制提升执行性能。选择时需根据项目需求权衡开发速度与执行效率。
 python在行动中:现实世界中的例子Apr 18, 2025 am 12:18 AM
python在行动中:现实世界中的例子Apr 18, 2025 am 12:18 AMPython在现实世界中的应用包括数据分析、Web开发、人工智能和自动化。1)在数据分析中,Python使用Pandas和Matplotlib处理和可视化数据。2)Web开发中,Django和Flask框架简化了Web应用的创建。3)人工智能领域,TensorFlow和PyTorch用于构建和训练模型。4)自动化方面,Python脚本可用于复制文件等任务。
 Python的主要用途:综合概述Apr 18, 2025 am 12:18 AM
Python的主要用途:综合概述Apr 18, 2025 am 12:18 AMPython在数据科学、Web开发和自动化脚本领域广泛应用。1)在数据科学中,Python通过NumPy、Pandas等库简化数据处理和分析。2)在Web开发中,Django和Flask框架使开发者能快速构建应用。3)在自动化脚本中,Python的简洁性和标准库使其成为理想选择。
 Python的主要目的:灵活性和易用性Apr 17, 2025 am 12:14 AM
Python的主要目的:灵活性和易用性Apr 17, 2025 am 12:14 AMPython的灵活性体现在多范式支持和动态类型系统,易用性则源于语法简洁和丰富的标准库。1.灵活性:支持面向对象、函数式和过程式编程,动态类型系统提高开发效率。2.易用性:语法接近自然语言,标准库涵盖广泛功能,简化开发过程。
 Python:多功能编程的力量Apr 17, 2025 am 12:09 AM
Python:多功能编程的力量Apr 17, 2025 am 12:09 AMPython因其简洁与强大而备受青睐,适用于从初学者到高级开发者的各种需求。其多功能性体现在:1)易学易用,语法简单;2)丰富的库和框架,如NumPy、Pandas等;3)跨平台支持,可在多种操作系统上运行;4)适合脚本和自动化任务,提升工作效率。
 每天2小时学习Python:实用指南Apr 17, 2025 am 12:05 AM
每天2小时学习Python:实用指南Apr 17, 2025 am 12:05 AM可以,在每天花费两个小时的时间内学会Python。1.制定合理的学习计划,2.选择合适的学习资源,3.通过实践巩固所学知识,这些步骤能帮助你在短时间内掌握Python。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

禅工作室 13.0.1
功能强大的PHP集成开发环境

WebStorm Mac版
好用的JavaScript开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

Dreamweaver Mac版
视觉化网页开发工具

