



译者 | 朱先忠
审校 | 孙淑娟
机器学习中的决策树
现代机器学习算法正在改变我们的日常生活。例如,像BERT这样的大型语言模型正在为谷歌搜索提供支持,GPT-3正在为许多高级语言应用程序提供支持。
另一方面,今天构建复杂的机器学习算法比以往任何时候都容易得多。然而,无论机器学习算法有多么复杂,都属于把它们归纳为以下学习类别之一:
- 监督学习
- 无监督学习
- 半监督学习
- 强化学习
其实,决策树算是最古老的有监督的机器学习算法之一,可以解决广泛的现实问题。研究表明,决策树算法的最早发明可以追溯到1963年。
接下来,让我们深入研究一下这个算法的细节,看看为什么这类算法今天仍然广为流行。
什么是决策树?
决策树算法是一种流行的有监督机器学习算法,因为它处理复杂数据集的方法相对简单得多。决策树的名字来源于它们与“树”这种结构的相似性;树结构包括以节点和边缘形式存在的根、枝和叶等几个组成部分。它们用于决策分析,很像一个基于if-else的决策流程图,这些决策会产生所需的预测。决策树能够学习这些if-else决策规则,从而拆分数据集,最后生成树状数据模型。
决策树在分类问题的离散结果预测和回归问题的连续数值结果预测中得到了应用。多年来科学家们开发出了许多不同的算法,如CART、C4.5和ensemble算法,如随机森林和梯度增强树等。
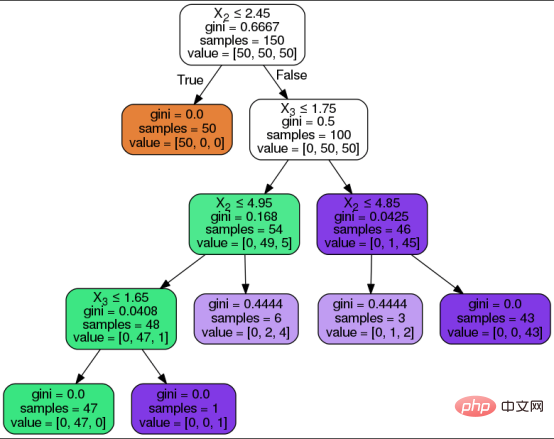
剖析决策树的各个组成部分
决策树算法的目标是预测输入数据集的结果。树的数据集共划分为三种形式:属性、属性的值和要预测的种类。与任何监督学习算法一样,数据集被划分为训练集和测试集两种类型。其中,训练集定义了算法学习并应用于测试集的决策规则。
在聚集介绍决策树算法的步骤之前,让我们先来了解一下决策树的组成部分:
- 根节点:它是决策树顶部的起始节点,包含所有属性值。根节点根据算法学习到的决策规则分成决策节点。
- 分支:分支是对应于属性值的节点之间的连接器。在二进制拆分中,分支表示真路径和假路径。
- 决策节点/内部节点:内部节点是根节点和叶节点之间的决策节点,对应于决策规则及其答案路径。节点表示问题,分支显示基于这些问题的相关答案的路径。
- 叶节点:叶节点是表示目标预测的终端节点。这些节点不会进一步分裂。
以下是决策树及其上述组件的可视化表示,决策树算法经过以下步骤以达到所需的预测:
- 算法从具有所有属性值的根节点开始。
- 根节点根据算法从训练集中学习到的决策规则分成决策节点。
- 基于问题及其答案路径,通过分支/边缘传递内部决策节点。
- 继续前面的步骤,直到到达叶节点或使用了所有属性。
为了在每个节点上选择最佳属性,将根据以下两个属性选择度量之一进行拆分:
- 基尼系数(Gini index)测量基尼不纯度(Gini Impurity),以指示算法对随机类别标签进行错误分类的可能性。
- 信息增益测量分割后熵的改善,以避免预测类的50/50分割。熵是给定数据样本中不纯度的数学度量。决策树中的混沌状态由接近50/50的划分表示。
使用决策树算法的花卉分类案例
在了解了上述基础知识后,接下来让我们着手实现一个应用案例。在本文中,我们将使用Scikit学习库在Python中实现决策树分类模型。
关于数据集的简单说明
本教程的数据集是一个鸢尾花数据集。Scikit开源库中已经内置了这个数据集,所以不需要开发人员再从外部加载它。该数据集共包括四个鸢尾属性及相应的属性值,这些属性将被输入到模型中,以便预测三种类型的鸢尾花之一。
- 数据集中的属性/特征:萼片长度、萼片宽度、花瓣长度、花瓣宽度。
- 数据集中的预测标签/花卉类型:Setosis、Versicolor、Virginica。
接下来,将给出决策树分类器基于python语言实现的分步代码说明。
导入库
首先,通过下面的一段代码导入执行决策树实现所需的库。
import pandas as pd import numpy as np from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier
加载鸢尾花(Iris)数据集
以下代码展示了使用load_iris函数加载存储到data_set变量中的sklearn.dataset库中的鸢尾花数据集。接下来的两行代码将实现打印鸢尾花类型和特征信息。
data_set = load_iris()
print('Iris plant classes to predict: ', data_set.target_names)
print('Four features of iris plant: ', data_set.feature_names)
分离属性和标签
下面的代码行实现了将花的特性和类型信息分离开来,并将它们存储在相应的变量中。其中,shape[0]函数负责确定存储在X_att变量中的属性数;数据集中的属性值总数为150。
#提取花的特性和类型信息
X_att = data_set.data
y_label = data_set.target
print('数据集中总的样本数:', X_att.shape[0])其实,我们还可以创建一个可视化表格来展示数据集中的一部分属性值,方法是将X_att变量中的值添加到panda库中的DataFrame函数中即可。
data_view=pd.DataFrame({
'sepal length':X_att[:,0],
'sepal width':X_att[:,1],
'petal length':X_att[:,2],
'petal width':X_att[:,3],
'species':y_label
})
data_view.head()拆分数据集
以下代码展示了使用train_test_split函数将数据集拆分为训练集和测试集两部分。其中,此函数中的random_state参数用于为函数提供随机种子,以便在每次执行时为给定数据集提供相同的结果;test_size表示测试集的大小;0.25表示拆分后测试数据占25%而训练数据占75%。
#数据集拆分为训练集和测试集两部分 X_att_train, X_att_test, y_label_train, y_label_test = train_test_split(X_att, y_label, random_state = 42, test_size = 0.25)
应用决策树分类函数
下面的代码通过使用DecisionTreeClassifier函数创建一个分类模型来实现一棵决策树,分类标准设置为“entropy”方式。该标准能够将属性选择度量设置为信息增益(Information gain)。然后,代码将模型与我们的属性和标签训练集相匹配。
#应用决策树分类器 clf_dt = DecisionTreeClassifier(criterion = 'entropy') clf_dt.fit(X_att_train, y_label_train)
计算模型精度
下面的代码负责计算并打印决策树分类模型在训练集和测试集上的准确性。为了计算准确度分数,我们使用了predict函数。测试结果是:训练集和测试集的准确率分别为100%和94.7%。
print('Training data accuracy: ', accuracy_score(y_true=y_label_train, y_pred=clf_dt.predict(X_att_train)))
print('Test data accuracy: ', accuracy_score(y_true=y_label_test, y_pred=clf_dt.predict(X_att_test)))真实世界中的决策树应用程序
当今社会,机器学习决策树在许多行业的决策过程中都得到广泛应用。其中,决策树的最常见应用首先是在金融和营销部门,例如可用于如下一些子领域:
- 贷款批准
- 支出管理
- 客户流失预测
- 新产品的可行性分析,等等。
如何改进决策树?
作为本文决策树主题讨论的总结,我们有充分的理由安全地假设:决策树的可解释性仍然很受欢迎。决策树之所以容易理解,是因为它们可以被人类以可视化方式展现并便于解释。因此,它们是解决机器学习问题的直观方法,同时也能够确保结果是可解释的。机器学习中的可解释性是我们过去讨论过的一个小话题,它也与即将到来的人工智能伦理主题存在密切联系。
与任何其他机器学习算法一样,决策树自然也可以加以改进,以避免过度拟合和出现过于偏向于优势预测类别。剪枝和ensembling技术是克服决策树算法缺点方案最常采用的方法。决策树尽管存在这些缺点,但仍然是决策分析算法的基础,并将在机器学习领域始终保持重要位置。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:An Introduction to Decision Trees for Machine Learning,作者:Stylianos Kampakis
以上是机器学习决策树实战演练的详细内容。更多信息请关注PHP中文网其他相关文章!

 脱衣服免费色情AI工具网站May 13, 2025 am 11:26 AM
脱衣服免费色情AI工具网站May 13, 2025 am 11:26 AMhttps://undressaitool.ai/是功能强大的移动应用程序,具有成人内容的高级AI功能。立即创建AI生成的色情图像或视频!
 如何使用Undressai创建色情图像/视频May 13, 2025 am 11:26 AM
如何使用Undressai创建色情图像/视频May 13, 2025 am 11:26 AM有关使用distressai创建色情图片/视频的教程:1。打开相应的工具Web链接; 2。单击工具按钮; 3。根据页面提示上传所需的生产内容; 4。保存并享受结果。
 Undress AI官方网站入口网站地址May 13, 2025 am 11:26 AM
Undress AI官方网站入口网站地址May 13, 2025 am 11:26 AM脱衣服AI的官方地址是:https://undressaitool.ai/; undressai是功能强大的移动应用程序,具有成人内容的高级AI功能。立即创建AI生成的色情图像或视频!
 垂undressai如何产生色情图像/视频?May 13, 2025 am 11:26 AM
垂undressai如何产生色情图像/视频?May 13, 2025 am 11:26 AM有关使用distressai创建色情图片/视频的教程:1。打开相应的工具Web链接; 2。单击工具按钮; 3。根据页面提示上传所需的生产内容; 4。保存并享受结果。
 垂ipersai色情AI官方网站地址May 13, 2025 am 11:26 AM
垂ipersai色情AI官方网站地址May 13, 2025 am 11:26 AM脱衣服AI的官方地址是:https://undressaitool.ai/; undressai是功能强大的移动应用程序,具有成人内容的高级AI功能。立即创建AI生成的色情图像或视频!
 脱衣舞用法教程指南文章May 13, 2025 am 10:43 AM
脱衣舞用法教程指南文章May 13, 2025 am 10:43 AM有关使用distressai创建色情图片/视频的教程:1。打开相应的工具Web链接; 2。单击工具按钮; 3。根据页面提示上传所需的生产内容; 4。保存并享受结果。
![[带AI的吉卜力风格图像]介绍如何使用Chatgpt和版权创建免费图像](https://img.php.cn/upload/article/001/242/473/174707263295098.jpg?x-oss-process=image/resize,p_40) [带AI的吉卜力风格图像]介绍如何使用Chatgpt和版权创建免费图像May 13, 2025 am 01:57 AM
[带AI的吉卜力风格图像]介绍如何使用Chatgpt和版权创建免费图像May 13, 2025 am 01:57 AMOpenAI发布的最新模型GPT-4o,不仅能生成文本,还具备图像生成功能,引发广泛关注。其中最受瞩目的功能便是“吉卜力风格插画”的生成。只需将照片上传至ChatGPT,并给出简单的指令,即可生成宛如吉卜力工作室作品般梦幻的图像。本文将详细解读实际操作流程、效果感受,以及需要注意的错误和版权问题。 OpenAI发布的最新模型“o3”详情请点击此处⬇️ OpenAI o3(ChatGPT o3)详解:特性、定价体系及o4-mini介绍 吉卜力风格文章的英文版请点击此处⬇️ 利用ChatGPT创作吉
 解释在地方政府中使用和实施CANTGPT的示例!还介绍了禁止的地方政府May 13, 2025 am 01:53 AM
解释在地方政府中使用和实施CANTGPT的示例!还介绍了禁止的地方政府May 13, 2025 am 01:53 AM作为一种新的交流方法,在地方政府中使用和引入Chatgpt引起了人们的关注。尽管这种趋势在广泛的领域正在发展,但一些地方政府拒绝使用Chatgpt。 在本文中,我们将介绍地方政府中ChatGPT实施的示例。我们将通过各种改革实例,包括支持文件创建和与公民对话,从而探索如何通过各种改革实例来实现地方政府服务的质量和效率提高。 不仅旨在减少员工工作量并改善公民的便利性的地方政府官员,而且都对高级用例感兴趣。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

WebStorm Mac版
好用的JavaScript开发工具

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

