



最强组合HuggingFace+ChatGPT=「贾维斯」现在开放demo了。

前段时间,浙大&微软发布了一个大模型协作系统HuggingGPT直接爆火。
研究者提出了用ChatGPT作为控制器,连接HuggingFace社区中的各种AI模型,完成多模态复杂任务。
整个过程,只需要做的是:用自然语言将你的需求输出。
英伟达科学家称,这是我本周读到的最有意思的论文。它的思想非常接近我之前说的「Everything App」,即万物皆App,被AI直接读取信息。
上手体验
现在,HuggingGPT增加了Gradio演示。

项目地址:https://github.com/microsoft/JARVIS
有网友便上手体验了一番,先来「识别图上有几个人」?

HuggingGPT根据推理结果,得出图片中有2个人正在街道上行走。
具体过程如下:
首先使用图像到文本模型nlpconnect/vit-gpt2-image-captioning进行图像描述,生成的文本「2个女人在有火车的街道上行走」。
接着,使用了目标检测模型facebook/detrresnet 50来检测图片中的人数。模型检测出7个物体,2个人。
再使用视觉问题回答模型dandelin/vilt-b32-finetuned-vqa得出结果。最后,系统提供了详细的响应和用于解答问题的模型信息。

另外,让它理解「我爱你」这句话的情感,并将其翻译成泰米尔语(Tamiḻ)。
HuggingGPT调用了以下模型:
首先,使用了模型「dslim/bert-base-NER」对文本「l love you」进行情感分类,是「浪漫」。
然后,使用「ChatGPT」将文本翻译成泰米尔语,即「Nan unnai kadalikiren」。
在推理结果中没有生成的图片、音频或视频文件。

转录MP3文件时,HuggingGPT却失败了。网友表示,「不确定这是否是我的输入文件的问题。」
再来看看图像生成的能力。
输入「一只猫跳舞」图像上添加文字「I LOVE YOU」作为叠加层。
HuggingGPT首先使用了「runwayml/stable-diffusion-1-5」模型根据给定的文本生成「跳舞的猫」的图片。
然后,使用同一个模型根据给定的文本生成了「I LOVE YOU」的图片。
最后,将2个图片合并在一起,输出如下图:
贾维斯照进现实
项目公开没几天,贾维斯已经在GitHub上收获了12.5k星,以及811个fork。
研究者指出解决大型语言模型(LLMs)当前的问题,可能是迈向AGI的第一步,也是关键的一步。
因为当前大型语言模型的技术仍然存在着一些缺陷,因此在构建 AGI 系统的道路上面临着一些紧迫的挑战。

为了处理复杂的人工智能任务,LLMs应该能够与外部模型协调,以利用它们的能力。
因此,关键点在于如何选择合适的中间件来桥接LLMs和AI模型。
在这篇研究论文中,研究者提出在HuggingGPT中语言是通用的接口。其工作流程主要分为四步:

论文地址:https://arxiv.org/pdf/2303.17580.pdf
首先是任务规划,ChatGPT解析用户请求,将其分解为多个任务,并根据其知识规划任务顺序和依赖关系。
接着,进行模型选择。LLM根据HuggingFace中的模型描述将解析后的任务分配给专家模型。
然后执行任务。专家模型在推理端点上执行分配的任务,并将执行信息和推理结果记录到LLM中。
最后是响应生成。LLM总结执行过程日志和推理结果,并将摘要返回给用户。

假如给出这样一个请求:
请生成一个女孩正在看书的图片,她的姿势与example.jpg中的男孩相同。然后请用你的声音描述新图片。
可以看到HuggingGPT是如何将它拆解为6个子任务,并分别选定模型执行得到最终结果的。
通过将AI模型描述纳入提示中,ChatGPT可以被视为管理人工智能模型的大脑。因此,这一方法可以让ChatGPT能够调用外部模型,来解决实际任务。
简单来讲,HuggingGPT是一个协作系统,并非是大模型。
它的作用就是连接ChatGPT和HuggingFace,进而处理不同模态的输入,并解决众多复杂的人工智能任务。
所以,HuggingFace社区中的每个AI模型,在HuggingGPT库中都有相应的模型描述,并将其融合到提示中以建立与ChatGPT的连接。
随后,HuggingGPT将ChatGPT作为大脑来确定问题的答案。
到目前为止,HuggingGPT已经围绕ChatGPT在HuggingFace上集成了数百个模型,涵盖了文本分类、目标检测、语义分割、图像生成、问答、文本到语音、文本到视频等24个任务。
实验结果证明,HuggingGPT可以在各种形式的复杂任务上表现出良好的性能。
网友热评
有网友称,HuggingGPT类似于微软此前提出的Visual ChatGPT,似乎他们把最初的想法扩展到了一组庞大的预训练模型上。

Visual ChatGPT是直接基于ChatGPT构建,并向其注入了许多可视化模型(VFMs)。文中提出了Prompt Manage。
在PM的帮助下,ChatGPT可以利用这些VFMs,并以迭代的方式接收其反馈,直到满足用户的要求或达到结束条件。

还有网友认为,这个想法确实与ChatGPT非常相似。以LLM为中心进行语义理解和任务规划,可以无限提升LLM的能力边界。通过将LLM与其他功能或领域专家相结合,我们可以创建更强大、更灵活的 AI 系统,能够更好地适应各种任务和需求。

这就是我一直以来对AGI的看法,人工智能模型能够理解复杂任务,然后将较小的任务分派给其他更专业的AI模型。

就像大脑一样,它也有不同的部分来完成特定的任务,听起来很符合逻辑。

以上是炫到爆炸!HuggingGPT在线演示惊艳亮相,网友亲测图像生成绝了的详细内容。更多信息请关注PHP中文网其他相关文章!

 评估大语模型中的毒性Apr 24, 2025 am 10:14 AM
评估大语模型中的毒性Apr 24, 2025 am 10:14 AM本文探讨了大语言模型(LLM)中的毒性至关重要问题以及用于评估和减轻它的方法。 LLM,为从聊天机器人到内容生成的各种应用程序提供动力,需要强大的评估指标,机智
 Rag Reranker的综合指南Apr 24, 2025 am 10:10 AM
Rag Reranker的综合指南Apr 24, 2025 am 10:10 AM检索增强发电(RAG)系统正在改变信息访问,但其有效性取决于检索到的数据的质量。 这是重读者变得至关重要的地方 - 充当搜索结果的质量过滤器,以确保仅确保
 如何使用Gemma 3&Docling构建多模式抹布?Apr 24, 2025 am 10:04 AM
如何使用Gemma 3&Docling构建多模式抹布?Apr 24, 2025 am 10:04 AM该教程通过在Google Colab中构建精致的多式联运检索一代(RAG)管道来指导您。 我们将使用Gemma 3(用于语言和视觉),文档(文档转换),Langchain等尖端工具
 可扩展AI和机器学习应用的射线指南Apr 24, 2025 am 10:01 AM
可扩展AI和机器学习应用的射线指南Apr 24, 2025 am 10:01 AM雷:扩展AI和Python应用程序的有力框架 Ray是一个革命性的开源框架,旨在轻松扩展AI和Python应用程序。 它的直观API使研究人员和开发人员可以通过其代码过渡
 如何将OpenAI MCP集成用于建筑代理?Apr 24, 2025 am 09:58 AM
如何将OpenAI MCP集成用于建筑代理?Apr 24, 2025 am 09:58 AMOpenAI通过支持人类的模型上下文协议(MCP)来涵盖互操作性,这是一种开源标准,简化了与不同数据系统的AI助手集成。这项合作为AI应用程序奠定了一个统一的框架
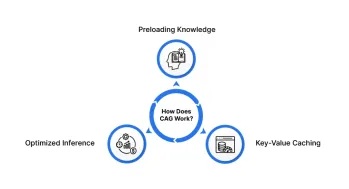 cache aigned Generation(CAG):它比抹布好吗?Apr 24, 2025 am 09:54 AM
cache aigned Generation(CAG):它比抹布好吗?Apr 24, 2025 am 09:54 AM缓存增强生成(CAG):一种更快,更有效的替代品 检索演出的一代(RAG)通过动态融合外部知识彻底改变了AI。但是,它对外部资源的依赖引入了潜伏期和
 胭脂:解码机器生成的文本的质量Apr 24, 2025 am 09:49 AM
胭脂:解码机器生成的文本的质量Apr 24, 2025 am 09:49 AM评估大型语言模型:深入研究胭脂指标 想象一个能够撰写诗歌,起草法律文件或总结复杂研究的AI。 我们如何客观地评估其表现? 作为大型语言模型(LLMS)Inc
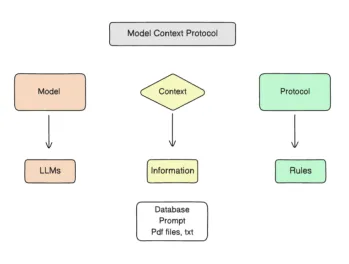 如何使用MCP:模型上下文协议-Analytics VidhyaApr 24, 2025 am 09:48 AM
如何使用MCP:模型上下文协议-Analytics VidhyaApr 24, 2025 am 09:48 AM使用模型上下文协议(MCP)为您的AI助手解锁现实世界数据的功能! 您可能已经使用LLM构建了应用程序,对代理进行了实验,甚至使用Langchain,Autogen或OpenAI的助手API。 令人印象深刻的a


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

SublimeText3汉化版
中文版,非常好用

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

SublimeText3 Linux新版
SublimeText3 Linux最新版

WebStorm Mac版
好用的JavaScript开发工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

