


arXiv论文“Graph-DETR3D: Rethinking Overlapping Regions for Multi-View 3D Object Detection“,22年6月,中科大、哈工大和商汤科技的工作。

从多个图像视图中检测3-D目标是视觉场景理解的一项基本而富有挑战性的任务。由于其低成本和高效率,多视图3-D目标检测显示出了广阔的应用前景。然而,由于缺乏深度信息,通过3-D空间中的透视图去精确检测目标,极其困难。最近,DETR3D引入一种新的3D-2D query范式,用于聚合多视图图像以进行3D目标检测,并实现了最先进的性能。
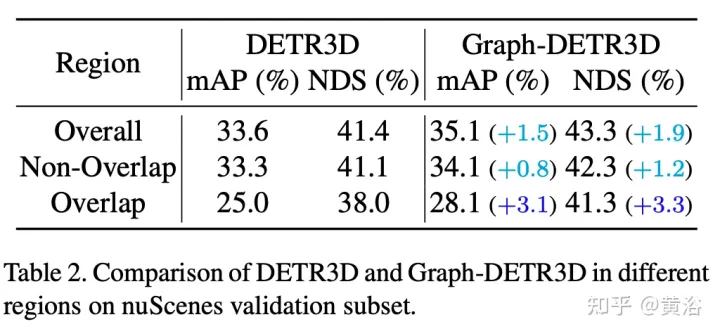
本文通过密集的引导性实验,量化了位于不同区域的目标,并发现“截断实例”(即每个图像的边界区域)是阻碍DETR3D性能的主要瓶颈。尽管在重叠区域中合并来自两个相邻视图的多个特征,但DETR3D仍然存在特征聚合不足的问题,因此错过了充分提高检测性能的机会。
为了解决这个问题,提出Graph-DETR3D,通过图结构学习(GSL)自动聚合多视图图像信息。在每个目标查询和2-D特征图之间构建一个动态3D图,以增强目标表示,尤其是在边界区域。此外,Graph-DETR3D得益于一种新的深度不变(depth-invariant)多尺度训练策略,其通过同时缩放图像大小和目标深度来保持视觉深度的一致性。
Graph-DETR3D的不同在于两点,如图所示:(1)动态图特征的聚合模块;(2)深度不变的多尺度训练策略。它遵循DETR3D的基本结构,由三个组件组成:图像编码器、transformer解码器和目标预测头。给定一组图像I={I1,I2,…,IK}(由N个周视摄像机捕捉),Graph-DETR3D旨在预测感兴趣边框的定位和类别。首先用图像编码器(包括ResNet和FPN)将这些图像变成一组相对L个特征图级的特征F。然后,构建一个动态3-D图,通过动态图特征聚合(dynamic graph feature aggregation,DGFA)模块广泛聚合2-D信息,优化目标查询的表示。最后,利用增强的目标查询输出最终预测。
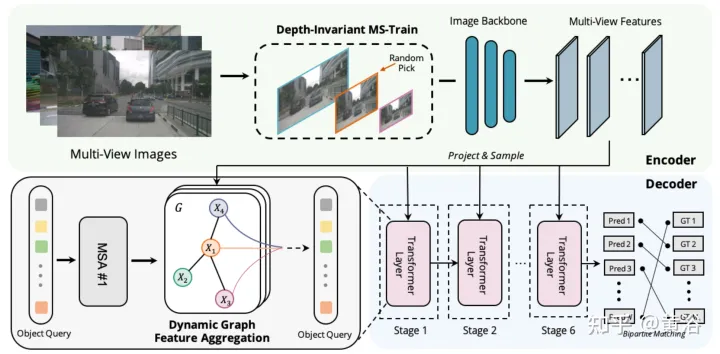
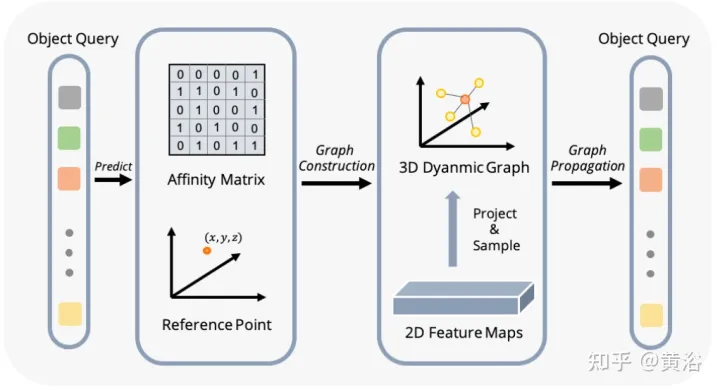
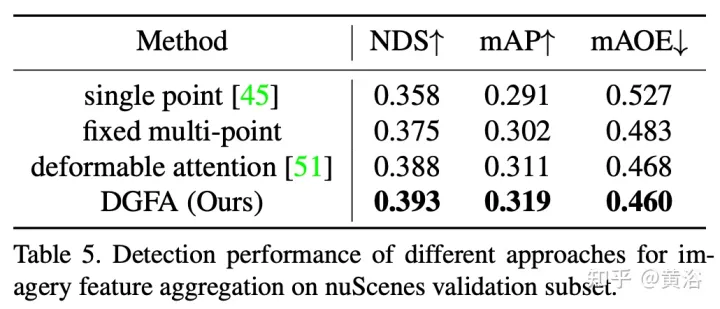
如图显示动态图特征聚合(DFGA)过程:首先为每个目标查询构造一个可学习的3-D图,然后从2-D图像平面采样特征。最后,通过图连接(graph connections)增强了目标查询的表示。这种相互连接的消息传播(message propagation)方案支持对图结构构造和特征增强的迭代细化方案。
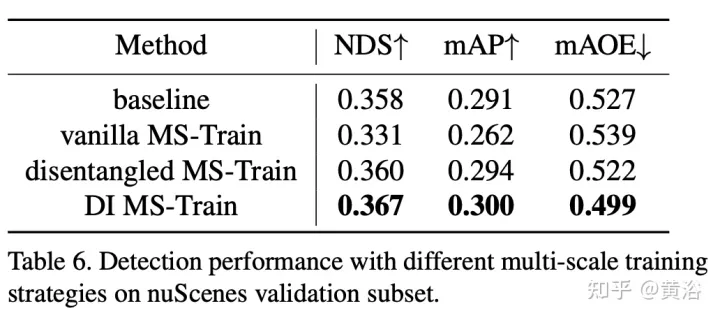
多尺度训练是2D和3D目标检测任务中常用的数据增强策略,经证明有效且推理成本低。然而,它很少出现在基于视觉的3-D检测方法中。考虑到不同输入图像大小可以提高模型的鲁棒性,同时调整图像大小和修改摄像机内参来实现普通多尺度训练策略。
一个有趣的现象是,最终的性能急剧下降。通过仔细分析输入数据,发现简单地重新缩放图像会导致透视-多义问题:当目标调整到较大/较小的比例时,其绝对属性(即目标的大小、到ego point的距离)不会改变。
作为一个具体示例,如图显示这个多义问题:尽管(a)和(b)中所选区域的绝对3D位置相同,但图像像素的数量不同。深度预测网络倾向于基于图像的占用面积来估计深度。因此,图中的这种训练模式可能会让深度预测模型糊涂,并进一步恶化最终性能。

为此从像素透视重新计算深度。算法伪代码如下:

如下是解码操作:

重新计算的像素大小是:
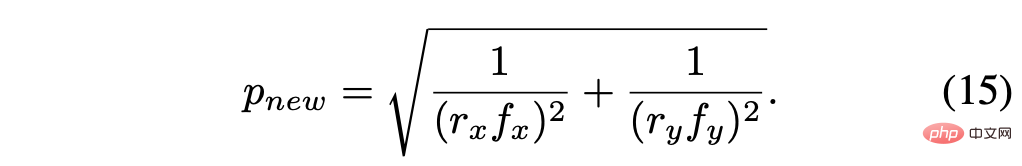
假设尺度因子r = rx = ry,则简化得到:
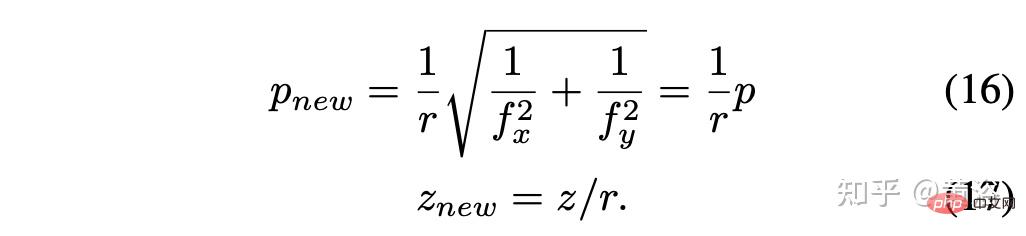
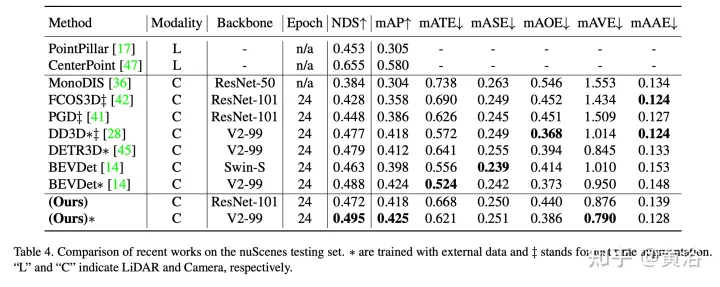
实验结果如下:
注:DI = Depth-Invariant
以上是Graph-DETR3D: 在多视角3D目标检测中对重叠区域再思考的详细内容。更多信息请关注PHP中文网其他相关文章!

![无法使用chatgpt!解释可以立即测试的原因和解决方案[最新2025]](https://img.php.cn/upload/article/001/242/473/174717025174979.jpg?x-oss-process=image/resize,p_40) 无法使用chatgpt!解释可以立即测试的原因和解决方案[最新2025]May 14, 2025 am 05:04 AM
无法使用chatgpt!解释可以立即测试的原因和解决方案[最新2025]May 14, 2025 am 05:04 AMChatGPT无法访问?本文提供多种实用解决方案!许多用户在日常使用ChatGPT时,可能会遇到无法访问或响应缓慢等问题。本文将根据不同情况,逐步指导您解决这些问题。 ChatGPT无法访问的原因及初步排查 首先,我们需要确定问题是出在OpenAI服务器端,还是用户自身网络或设备问题。 请按照以下步骤进行排查: 步骤1:检查OpenAI官方状态 访问OpenAI Status页面 (status.openai.com),查看ChatGPT服务是否正常运行。如果显示红色或黄色警报,则表示Open
 计算ASI的风险始于人类的思想May 14, 2025 am 05:02 AM
计算ASI的风险始于人类的思想May 14, 2025 am 05:02 AM2025年5月10日,麻省理工学院物理学家Max Tegmark告诉《卫报》,AI实验室应在释放人工超级智能之前模仿Oppenheimer的三位一体测试演算。 “我的评估是'康普顿常数',这是一场比赛的可能性
 易于理解的解释如何编写和撰写歌词和推荐工具May 14, 2025 am 05:01 AM
易于理解的解释如何编写和撰写歌词和推荐工具May 14, 2025 am 05:01 AMAI音乐创作技术日新月异,本文将以ChatGPT等AI模型为例,详细讲解如何利用AI辅助音乐创作,并辅以实际案例进行说明。我们将分别介绍如何通过SunoAI、Hugging Face上的AI jukebox以及Python的Music21库进行音乐创作。 通过这些技术,每个人都能轻松创作原创音乐。但需注意,AI生成内容的版权问题不容忽视,使用时务必谨慎。 让我们一起探索AI在音乐领域的无限可能! OpenAI最新AI代理“OpenAI Deep Research”介绍: [ChatGPT]Ope
 什么是chatgpt-4?对您可以做什么,定价以及与GPT-3.5的差异的详尽解释!May 14, 2025 am 05:00 AM
什么是chatgpt-4?对您可以做什么,定价以及与GPT-3.5的差异的详尽解释!May 14, 2025 am 05:00 AMChatGPT-4的出现,极大地拓展了AI应用的可能性。相较于GPT-3.5,ChatGPT-4有了显着提升,它具备强大的语境理解能力,还能识别和生成图像,堪称万能的AI助手。在提高商业效率、辅助创作等诸多领域,它都展现出巨大的潜力。然而,与此同时,我们也必须注意其使用上的注意事项。 本文将详细解读ChatGPT-4的特性,并介绍针对不同场景的有效使用方法。文中包含充分利用最新AI技术的技巧,敬请参考。 OpenAI发布的最新AI代理,“OpenAI Deep Research”详情请点击下方链
 解释如何使用chatgpt应用程序!日本支持和语音对话功能May 14, 2025 am 04:59 AM
解释如何使用chatgpt应用程序!日本支持和语音对话功能May 14, 2025 am 04:59 AMCHATGPT应用程序:与AI助手释放您的创造力!初学者指南 ChatGpt应用程序是一位创新的AI助手,可处理各种任务,包括写作,翻译和答案。它是一种具有无限可能性的工具,可用于创意活动和信息收集。 在本文中,我们将以一种易于理解的方式解释初学者,从如何安装chatgpt智能手机应用程序到语音输入功能和插件等应用程序所独有的功能,以及在使用该应用时要牢记的要点。我们还将仔细研究插件限制和设备对设备配置同步
 如何使用中文版Chatgpt?注册程序和费用的说明May 14, 2025 am 04:56 AM
如何使用中文版Chatgpt?注册程序和费用的说明May 14, 2025 am 04:56 AMChatGPT中文版:解锁中文AI对话新体验 ChatGPT风靡全球,您知道它也提供中文版本吗?这款强大的AI工具不仅支持日常对话,还能处理专业内容,并兼容简体中文和繁体中文。无论是中国地区的使用者,还是正在学习中文的朋友,都能从中受益。 本文将详细介绍ChatGPT中文版的使用方法,包括账户设置、中文提示词输入、过滤器的使用、以及不同套餐的选择,并分析潜在风险及应对策略。此外,我们还将对比ChatGPT中文版和其他中文AI工具,帮助您更好地了解其优势和应用场景。 OpenAI最新发布的AI智能
 5 AI代理神话,您需要停止相信May 14, 2025 am 04:54 AM
5 AI代理神话,您需要停止相信May 14, 2025 am 04:54 AM这些可以将其视为生成AI领域的下一个飞跃,这为我们提供了Chatgpt和其他大型语言模型聊天机器人。他们可以代表我们采取行动,而不是简单地回答问题或产生信息
 易于理解使用Chatgpt创建和管理多个帐户的非法性的解释May 14, 2025 am 04:50 AM
易于理解使用Chatgpt创建和管理多个帐户的非法性的解释May 14, 2025 am 04:50 AM使用chatgpt有效的多个帐户管理技术|关于如何使用商业和私人生活的详尽解释! Chatgpt在各种情况下都使用,但是有些人可能担心管理多个帐户。本文将详细解释如何为ChatGpt创建多个帐户,使用时该怎么做以及如何安全有效地操作它。我们还介绍了重要的一点,例如业务和私人使用差异,并遵守OpenAI的使用条款,并提供指南,以帮助您安全地利用多个帐户。 Openai


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

SublimeText3汉化版
中文版,非常好用

Dreamweaver CS6
视觉化网页开发工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

