



前言
大家应该都看过布拉德.伯德执导、汤姆.克鲁斯主演的《碟中谍4吧》?茫茫人海的火车站,只要一眨眼的功夫已经被计算机识别出来,随即被特工盯梢;迎面相逢的美女是致命杀手,手机发出嘀嘀的报警声,上面已经显示美女的姓名和信息。这就是本文想要介绍的人脸识别算法,以及如果使用公有云AI平台训练模型。
作为目前人工智能领域中成熟较早、落地较广的技术之一,人脸识别的目的是要判断图片和视频中人脸的身份。从平常手机的刷脸解锁、刷脸支付,再到安防领域内的人脸识别布控,等等,人脸识别技术都有着广泛的应用。人脸是每个人与生俱来的特征,该特征具有唯一性并且不易被复制,从而为身份鉴别提供了必要的前提。
人脸识别的研究始于20世纪60年代,随着计算机技术和光学成像技术的发展不断提高,以及近几年神经网络技术的再次兴起,尤其是卷积神经网络在图像识别和检测中取得的巨大成功,使得人脸识别系统的效果得到了极大的提升。本文,我们从人脸识别技术的技术细节讲起,带你初步了解人脸识别技术的发展过程,文章的后半篇,我们将会使用ModelArts平台的自定义镜像,带你看看如何利用公有云的计算资源,快速训练一个可用的人脸识别模型。
正文
不管是基于传统图像处理和机器学习技术,还是利用深度学习技术,其中的流程都是一样的。如图1所示,人脸识别系统都包括人脸检测、对齐、编码以及匹配四个基本环节组成。所以该部分首先通过对基于传统图像处理和机器学习算法的人脸识别系统进行概述,就可以看出整个深度学习算法在人脸识别领域内发展的脉络。

人脸检测流程
传统机器学习算法
前面已经说过,人脸识别的目的就是要判断图像中的人脸身份是什么,所以就首先需要先把图像中的人脸检测出来,其实这一步归根结底就是一个目标检测的问题。传统的图像目标检测算法主要有三部分组成,建议框生成、特征工程以及分类,包括著名的RCNN系列算法的优化思路也是基于这三部分进行的。
首先是建议框生成,该步骤最简单的想法就是在图片中crop出来一堆待检测框,然后检测该框内是否存在目标,如果存在,则该框在原图中的位置即为目标检测出的位置,因此在该步骤中对目标的覆盖率越大,则建议框生成策略越好。常见的建议框生成策略有sliding window、Selective Search、Randomized Prim等等,生成大量的候选框,如下图所示。

得到大量的候选框后,传统的人脸检测算法接下来最主要的部分就是特征工程。特征工程其实就是利用算法工程师的专家经验对不同场景的人脸提取各种特征,例如边缘特征、形状形态学特征、纹理特征等等,具体的算法是技术有LBP、Gabor、Haar、SIFT等等特征提取算法,将一张以二维矩阵表示的人脸图片转换成各种特征向量的表示。
得到特征向量之后,就可以通过传统的机器学习分类器对特征进行分类,得到是否是人脸的判断,例如通过adaboost、cascade、SVM、随机森林等等。通过传统分类器分类之后就可以得到人脸的区域、特征向量以及分类置信度等等。通过这些信息,我们就可以完成人脸对齐、特征表示以及人脸匹配识别的工作。
以传统方法中,经典的HAAR+AdaBoost的方法为例,在特征提取阶段,首先会利用haar特征在图片中提取出很多简单的特征。Haar特征如下图所示。为了满足不同大小人脸的检测,通常会利用高斯金字塔对不同分辨率的图像进行Haar特征的提取。
Haar特征的计算方法是将白色区域内的像素和减去黑色区域,因此在人脸和非人脸的区域内,得到的值是不一样的。一般在具体实现过程中,可以通过积分图的方法快速实现。一般在归一化到20*20的训练图片中,可供使用的Haar特征数在一万个左右,因此在这种特征规模的情况下,可以利用机器学习的算法进行分类和识别。
得到Haar特征后,可以利用Adaboost进行分类,Adaboost算法是一种将多个比较弱的分类方法合在一起,组合出新的强分类方法。根据该级联分类器,和训练好的各个特征选择阈值,就可以完成对人脸的检测。
从上述方法可以看出,传统的机器学习算法是基于特征的算法,因此需要大量的算法工程师的专家经验进行特征工程和调参等工作,算法效果也不是很好。而且人工设计在无约束环境中对不同变化情况都鲁棒很困难的。过去的图像算法是工程师更多的是通过传统的图像处理方法,根据现实场景和专家经验提取大量的特征,然后对提取的特征再进行统计学习的处理,这样整体算法的性能就非常依赖于现实场景和专家经验,对于人脸这种类别巨大,每类样本不均衡情况严重的无约束场景效果并不是很好。因此,近几年随着深度学习在图像处理中取得的巨大成功,人脸识别技术也都以深度学习为主,并且已经达到了非常好的效果。
深度学习在人脸识别领域的应用
在深度学习的人脸识别系统中,该问题被分成了一个目标检测问题和一个分类问题,而目标检测问题在深度学习中本质还是一个分类问题和回归问题,因此随着卷积神经网络在图片分类上的成功应用,人脸识别系统的效果得到了快速且巨大的提升,并以此诞生了大量的视觉算法公司,并将人脸识别应用在了社会生活的各个方面。
其实利用神经网络来做人脸识别并不是什么新思想,1997年就有研究者为人脸检测、眼部定位和人脸识别提出了一种名为基于概率决策的神经网络的方法。这种人脸识别 PDBNN 被分成了每一个训练主体一个全连接子网络,以降低隐藏单元的数量和避免过拟合。研究者使用密度和边特征分别训练了两个 PBDNN,然后将它们的输出组合起来得到最终分类决定。但是受限于当时算力和数据的严重不足,算法相对简单,因此该算法并没有得到很好的效果。随着仅今年反向传播理论和算力框架等的日趋成熟,人脸识别算法的效果才开始得到巨大的提升。
在深度学习中,一个完整的人脸识别系统也包括图1所示的四个步骤,其中第一步骤叫做人脸检测算法,本质也是一个目标检测算法。第二个步骤叫做人脸对齐,目前又基于关键点的几何对齐和基于深度学习的人脸对齐。第三个步骤特征表示,在深度学习中是通过分类网络的思想,提取分类网络中的一些feature层作为人脸的特征表示,然后用相同的方式对标准人脸像进行处理,最后通过比对查询的方式完成整体的人脸识别系统。下面主要对人脸检测和人脸识别算法的发展进行简单综述。
人脸检测
深度学习在图像分类中的巨大成功后很快被用于人脸检测的问题,起初解决该问题的思路大多是基于CNN网络的尺度不变性,对图片进行不同尺度的缩放,然后进行推理并直接对类别和位置信息进行预测。另外,由于对feature map中的每一个点直接进行位置回归,得到的人脸框精度比较低,因此有人提出了基于多阶段分类器由粗到细的检测策略检测人脸,例如主要方法有Cascade CNN、 DenseBox和MTCNN等等。
MTCNN是一个多任务的方法,第一次将人脸区域检测和人脸关键点检测放在了一起,与Cascade CNN一样也是基于cascade的框架,但是整体思路更加的巧妙合理,MTCNN总体来说分为三个部分:PNet、RNet和ONet,网络结构如下图所示。
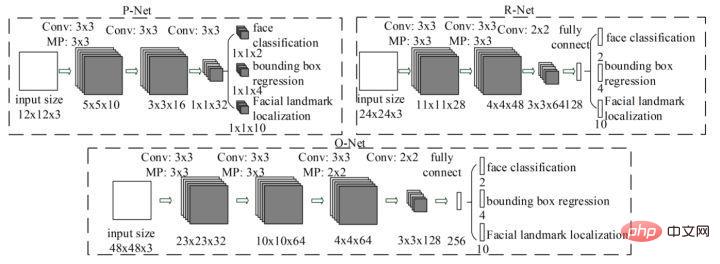
首先PNet网络对输入图片resize到不同尺寸,作为输入,直接经过两层卷积后,回归人脸分类和人脸检测框,这部分称之为粗检测。将粗检测得到的人脸从原图中crop出来后,在输入的R-Net,再进行一次人脸检测。最后将得到的人脸最终输入O-Net,得到的O-Net输出结果为最终的人脸检测结果。MTCNN整体流程相对比较简单,能够快速的进行部署和实现,但是MTCNN的缺点也很多。包括多阶段任务训练费时,大量中间结果的保存需要占用大量的存储空间。另外,由于改网络直接对feature点进行bounding box的回归,对于小目标人脸检测的效果也不是很好。还有,该网络在推理的过程中为了满足不同大小人脸检测需要,要将人脸图片resize到不同尺寸内,严重影响了推理的速度。
随着目标检测领域的发展,越来越多的实验证据证明目标检测中更多的瓶颈在于底层网络语义低但定位精度相对较高和高层网络语义高但定位精度低的矛盾,目标检测网络也开始流行anchor-based的策略和跨层融合的策略,例如著名的Faster-rcnn、SSD和yolo系列等。因此,人脸检测算法也越来越多的利用anchor和多路输出来满足不同大小人脸检出的效果,其中最著名的算法就是SSH网络结构。
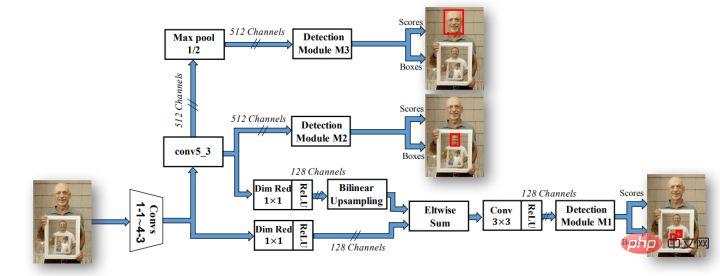
从上图中可以看出,SSH网络已经有对不同网络层输出进行处理的方法,只需要一遍推理就能完成不同大小人脸的检测过程,因此称之为Single Stage。SSH的网络也比较简单,就是对VGG不同卷积层惊醒了分支计算并输出。另外还对高层feature进行了上采样,与底层feature做Eltwise Sum来完成底层与高层的特征融合。另外SSH网络还设计了detection module和context module,其中context module作为detection module的一部分,采用了inception的结构,获取更多上下文信息以及更大的感受野。
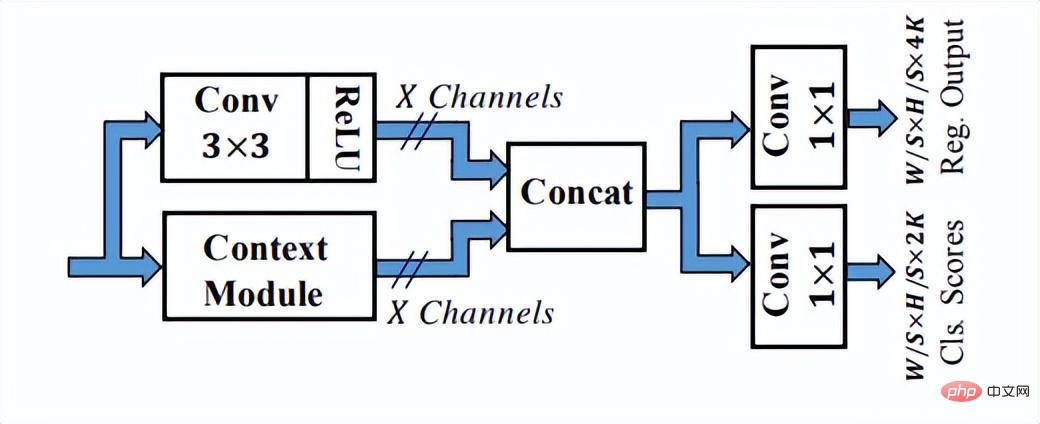
SSH中的detection module模块
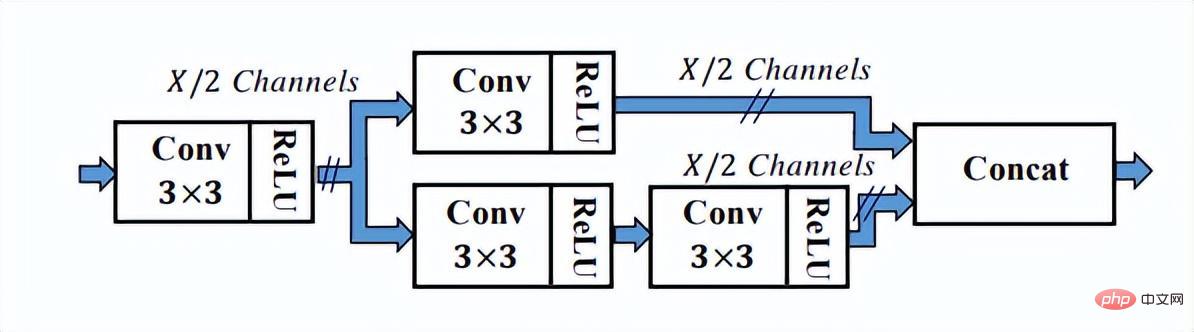
SSH中detection module里的context module模块
SSH利用1×1卷积对输出最终的回归和分类的分支结果,并没有利用全连接层,因此可以保证不同尺寸图片的输入都能得到输出的结果,也是响应了当时全卷积设计方式的潮流。遗憾的是该网络并没有输出landmark点,另外其实上下文结构也没有用到比较流行的特征金字塔结构,VGG16的backbone也相对较浅,随着人脸优化技术的不断进行,各种各样的trick也都日趋成熟。因此,最后向大家介绍一下目前人脸检测算法中应用比较广的Retinaface网络。
Retinaface由google提出,本质是基于RetinaNet的网络结构,采用特征金字塔技术,实现了多尺度信息的融合,对检测小物体有重要的作用。网络结构如下所示。
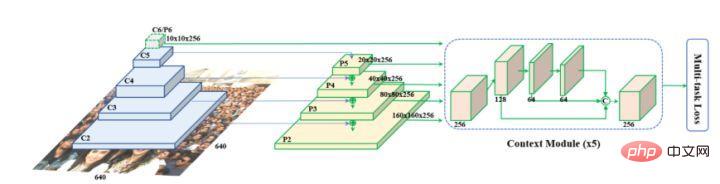
从上图可以看出,Retinaface的backbone网络为常见的卷积神经网络,然后加入特征金子塔结构和Context Module模块,进一步融合上下文的信息,并完成包括分类、检测、landmark点回归以及图像自增强的多种任务。
因为人脸检测的本质是目标检测任务,目标检测未来的方向也适用于人脸的优化方向。目前在目标检测中小目标、遮挡目标的检测依旧很困难,另外大部份检测网络更多的开始部署在端侧,因此基于端侧的网络模型压缩和重构加速等等更加考验算法工程师对与深度学习检测算法的理解和应用。
人脸识别
人脸识别问题本质是一个分类问题,即每一个人作为一类进行分类检测,但实际应用过程中会出现很多问题。第一,人脸类别很多,如果要识别一个城镇的所有人,那么分类类别就将近十万以上的类别,另外每一个人之间可获得的标注样本很少,会出现很多长尾数据。根据上述问题,要对传统的CNN分类网络进行修改。
我们知道深度卷积网络虽然作为一种黑盒模型,但是能够通过数据训练的方式去表征图片或者物体的特征。因此人脸识别算法可以通过卷积网络提取出大量的人脸特征向量,然后根据相似度判断与底库比较完成人脸的识别过程,因此算法网络能不能对不同的人脸生成不同的特征,对同一人脸生成相似的特征,将是这类embedding任务的重点,也就是怎么样能够最大化类间距离以及最小化类内距离。
在人脸识别中,主干网络可以利用各种卷积神经网络完成特征提取的工作,例如resnet,inception等等经典的卷积神经网络作为backbone,关键在于最后一层loss function的设计和实现。现在从两个思路分析一下基于深度学习的人脸识别算法中各种损失函数。
思路1:metric learning,包括contrastive loss, triplet loss以及sampling method
思路2:margin based classification,包括softmax with center loss, sphereface, normface, AM-sofrmax(cosface) 和arcface。
1. Metric Larning
(1)Contrastive loss
深度学习中最先应用metric learning思想之一的便是DeepID2了。其中DeepID2最主要的改进是同一个网络同时训练verification和classification(有两个监督信号)。其中在verification loss的特征层中引入了contrastive loss。
Contrastive loss不仅考虑了相同类别的距离最小化,也同时考虑了不同类别的距离最大化,通过充分运用训练样本的label信息提升人脸识别的准确性。因此,该loss函数本质上使得同一个人的照片在特征空间距离足够近,不同人在特征空间里相距足够远直到超过某个阈值。(听起来和triplet
loss有点像)。
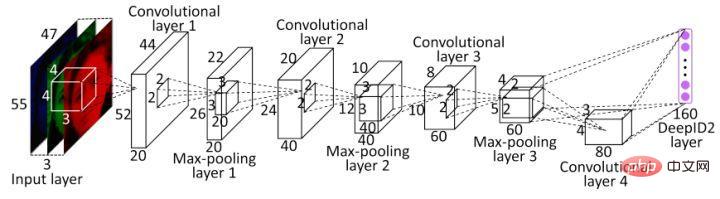
Contrastive loss引入了两个信号,并通过两个信号对网络进行训练。其中识别信号的表达式如下:
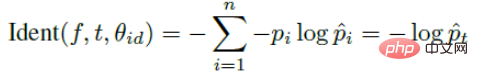
验证信号的表达式如下:
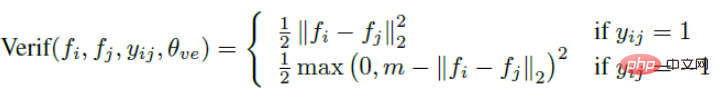
基于这样的信号,DeepID2在训练的时候就不是以一张图片为单位了,而是以Image Pair为单位,每次输入两张图片,为同一人则为1,如果不是同一人则为-1.
(2)Triplet loss from FaceNet
这篇15年来自Google的FaceNet同样是人脸识别领域分水岭性质的工作。它提出了一个绝大部分人脸问题的统一解决框架,即:识别、验证、搜索等问题都可以放到特征空间里做,需要专注解决的仅仅是如何将人脸更好的映射到特征空间。
Google在DeepID2的基础上,抛弃了分类层即Classification Loss,将Contrastive Loss改进为Triplet loss,只为了一个目的:学习到更好的feature。
直接贴出Triplet loss的损失函数,其输入的不再是Image Pair,而是三张图片(Triplet),分别为Anchor Face, Negative Face和Positive Face。Anchor与Positive Face为同一人,与Negative Face为不同的人。那么Triplet loss的损失函数即可表示为:
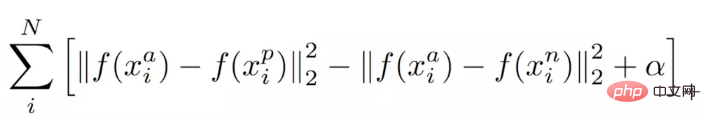
该式子的直观解释为:在特征空间里Anchor与Positive的距离要小于Anchor与Negative的距离并超过一个Margin Alpha。他与Contrastive loss的直观区别由下图所示。
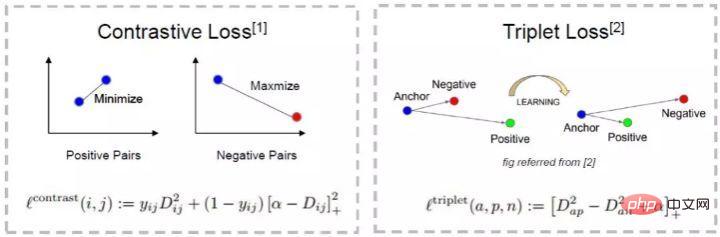
(3)Metric learning的问题
上述的两个loss function效果很不错,而且也符合人的客观认知,在实际项目中也有大量的应用,但该方法仍有一些不足之处。
- 模型训练依赖大量的数据,拟合过程很慢。由于contrastive loss和triplet loss都是基于pair或者triplet的,需要准备大量的正负样本,,训练很长时间都不可能完全遍历所有可能的样本间组合。网上有博客说10000人、500000张左右的亚洲数据集上花一个月才能完成拟合。
- Sample方式影响模型的训练。比如对于triplet loss来说,在训练过程中要随机的采样anchor face, negative face以及positive face,好的样本采样能够加快训练速度和模型收敛,但是在随机抽取的过程中很难做到非常好。
- 缺少对hard triplets的挖掘,这也是大多数模型训练的问题。比如说在人脸识别领域中,hard negatives表示相似但不同的人,而hard positive表示同一个人但完全不同的姿态、表情等等。而对hard example进行学习和特殊处理对于提高识别模型的精度至关重要。
2. 对于Metric Learning不足进行修正的各种trick
(1)Finetune
参考论文:Deep Face Recognition
在论文《Deep Face Recognition》中,为了加快triplet loss的训练,坐着先用softmax训练人脸识别模型,然后移除顶层的classification layer,然后用triplet loss对模型进行特征层finetune,在加速训练的同时也取得了很不错的效果。该方法也是现在训练triplet loss时最常用的方法。
(2)对Triplet loss的修改
参考论文:In Defense of the Triplet Loss for Person Re-Identification
该作者说出了Triplet loss的缺点。对于Triplet loss训练所需要的一个三元组,anchor(a)、positive(p)、negative(n)来说,需要从训练集中随机挑选。由于loss function的驱动,很有可能挑选出来的是很简单的样本组合,即很像的正样本以及很不像的负样本,而让网络一直在简单样本上进行学习,会限制网络的范化能力。因此坐着修改了triplet loss并添加了新的trick,大量实验证明,这种改进版的方法效果非常好。
在Google提供的facenet triplet loss训练时,一旦选定B triplets集合,数据就会按照顺序排好的3个一组,那么总共的组合就有3B种,但是这些3B个图像实际上有多达种有效的triplets组合,仅仅使用3B种就很浪费。
在该片论文中,作者提出了一个TriHard loss,其核心思想是在triplet loss的基础上加入对hard example的处理:对于每一个训练的batch, 随机挑选P个ID的行人,每个行人随机挑选K张不同的图片,即一个batch含有P×K张图片。之后对于batch中的每一张图片a,我们可以挑选一个最难的正样本和一个最难的负样本和a组成一个三元组。首先我们定义和a为相同ID的图片集为A,剩下不同ID的图片图片集为B,则TriHard损失表示为:
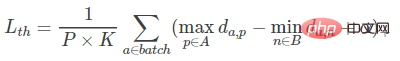
其中是人为设定的阈值参数。TriHard loss会计算a和batch中的每一张图片在特征空间的欧氏距离,然后选出与a距离最远(最不像)的正样本p和距离最近(最像)的负样本n来计算三元组损失。其中d表示欧式距离。损失函数的另一种写法如下:

另外,作者在轮中也提出了几个实验得到的观点:
- 平方后的欧式距离不如开方后的真实欧氏距离(后续会简单提一下原因)
- 提出了Soft-Margin损失函数替代原始的Triplet loss表达式,soft-margin能够使得损失函数更加平滑,避免函数收敛在bad local处,能够一定程度上加速算法收敛。
- 引进了Batch Hard Sampling
该方法考虑了hard example后效果比传统的triplet loss好。
(3)对loss以及sample方法的修改
参考论文:Deep Metric Learning via Lifted Structured Feature Embedding
该论文首先提出了现有的三元组方法无法充分利用minibatch SGD training的training batches的优势,创造性的将the vector of pairwise distances转换成the matrix of pairwise
distance,然后设计了一个新的结构化损失函数,取得了非常好的效果。如下图所示,是contrastice embedding,triplet embedding以及lifted structured embedding三种方式的采样示意图。
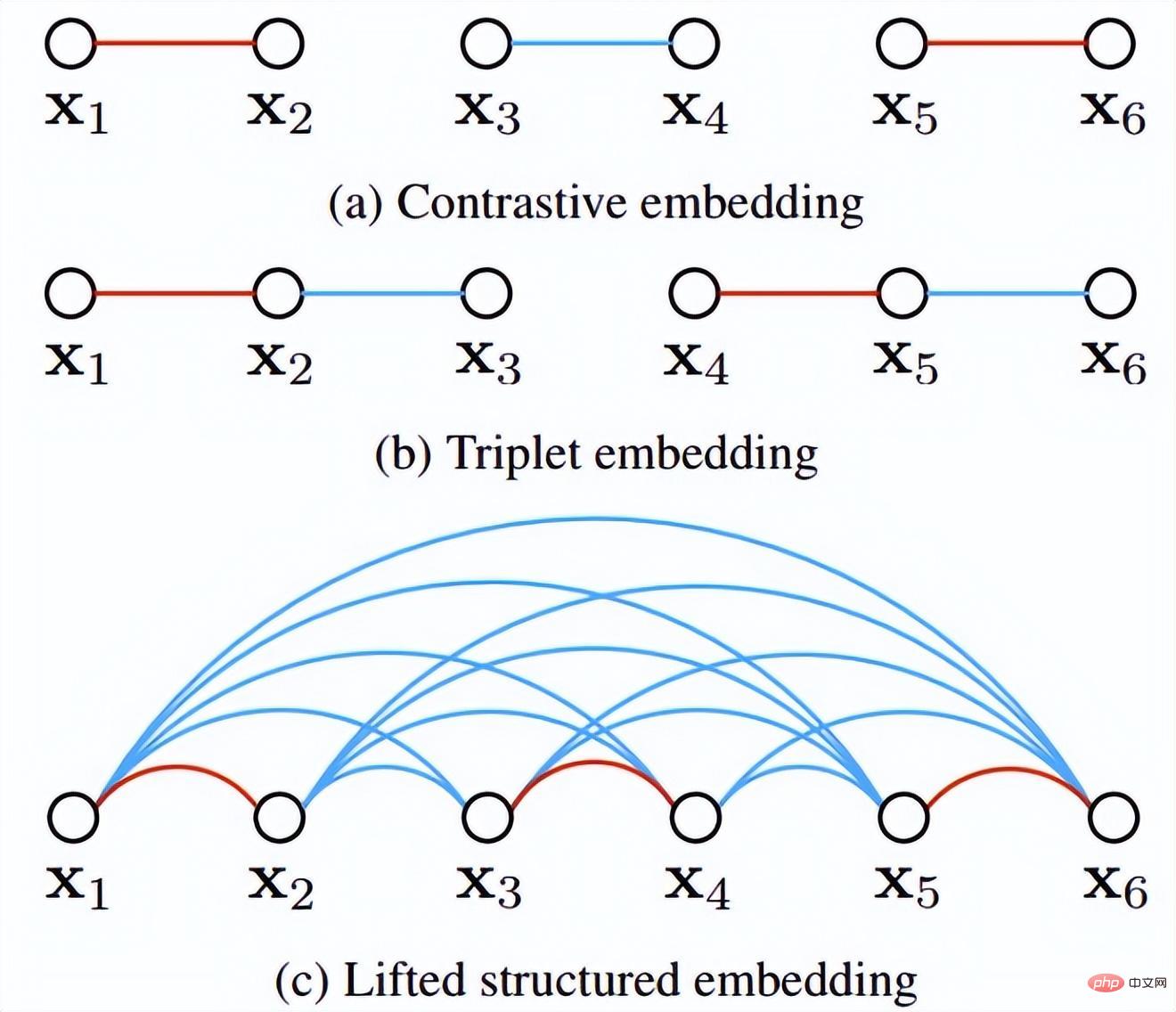
直观上看,lifted structured embedding涉及的分类模式更多,作者为了避免大量数据造成的训练困难,作者在此基础上给出了一个结构化的损失函数。如下图所示。
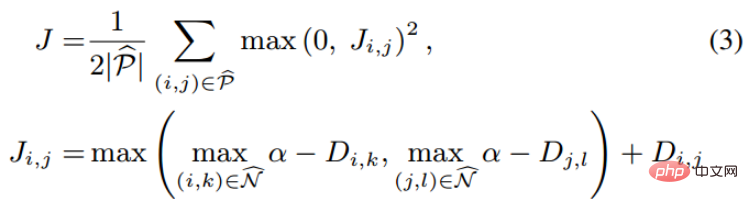
其中P是正样本集合,N是负样本集合。可以看到对比上述的损失函数,该损失函数开始考虑一个样本集合的问题。但是,并不是所有样本对之间的negative edges都携带了有用的信息,也就是说随机采样的样本对之间的negative edges携带了非常有限的信息,因此我们需要设计一种非随机的采样方法。
通过上述的结构化损失函数我们可以看到,在最终计算损失函数时,考虑了最像和最不像的hard pairs(也就是损失函数中max的用处),也就相当于在训练过程中添加了difficult
neighbors的信息了训练mini-batch,通过这种方式训练数据能够大概率的搜寻到hard negatives和hard positives的样本,而随着训练的不断进行,对hard样本的训练也将实现最大化类间距离和最小化类内距离的目的。
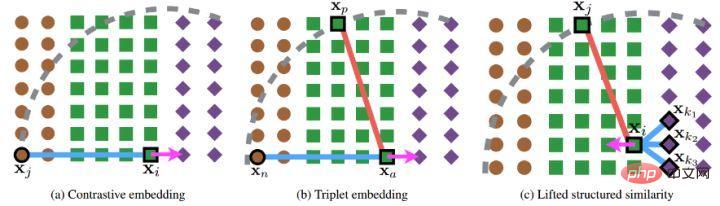
如上图所示,该文章在进行metric learning的时候并没有随机的选择sample pairs,而是综合了多类样本之间较难区分者进行训练。此外,文中还提到了以为的寻求max的过程或者寻求single hardest negative的过程会导致网络收敛到一个bad local optimum,我猜想可能是因为max的截断效应,使得梯度比较陡峭或者梯度间断点过多。作者进一步改进了loss
function,采用了smooth upper bound,即下式所示。
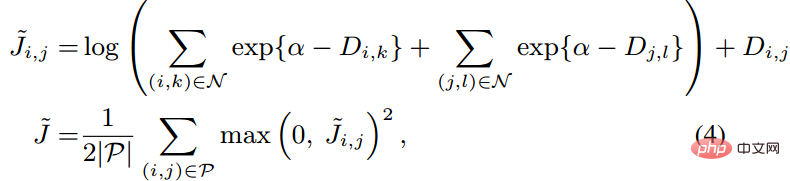
(4)对sample方式和对triplet loss的进一步修改
参考论文:Sampling Matters in Deep Embedding Learning
- 对采样方式的修改
文章指出hard negative样本由于anchor的距离较小,这是如果有噪声,那么这种采样方式就很容易受到噪声的影响,从而造成训练时的模型坍塌。FaceNet曾经提出一种semi-hard negative mining的方法,它提出的方法是让采样的样本不是太hard。但是根据作者的分析认为,sample应该在样本中进行均匀的采样,因此最佳的采样状态应该是在分散均匀的负样本中,既有hard,又有semi-hard,又有easy的样本,因此作者提出了一种新的采样方法Distance weighted sampling。
在现实状态下,我们队所有的样本进行两两采样,计算其距离,最终得到点对距离的分布有着如下的关系:
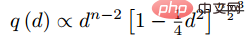
那么根据给定的距离,通过上述函数的反函数就可以得到其采样概率,根据该概率决定每个距离需要采样的比例。给定一个anchor,采样负例的概率为下式:
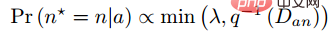
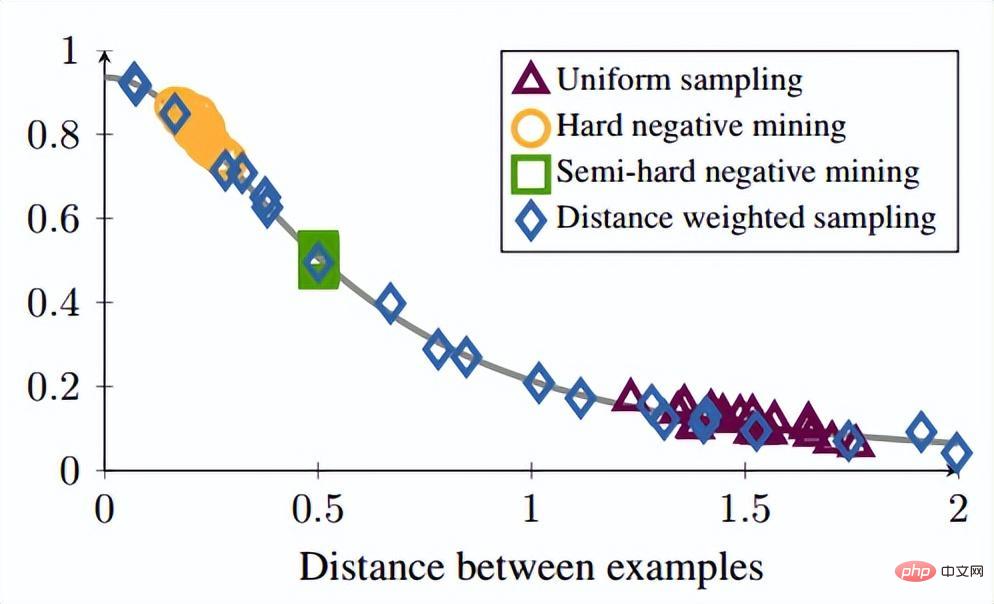
由于训练样本与训练梯度强相关,因此作者也绘制出了采样距离、采样方法与数据梯度方差的关系,如下图所示。从图中可以看出,hard negative mining方法采样的样本都处于高方差的区域,如果数据集中有噪声的话,采样很容易受到噪声的影响,从而导致模型坍塌。随机采样的样本容易集中在低方差的区域,从而使得loss很小,但此时模型实际上并没有训练好。Semi-hard negative mining采样的范围很小,这很可能导致模型在很早的时候就收敛,loss下降很慢,但实际上此时模型也还没训练好;而本文提出的方法,能够实现在整个数据集上均匀采样。
- 对loss function的修改
作者在观察constractive loss和triplet loss的时候发现一个问题,就是负样本在非常hard的时候loss函数非常的平滑,那么也就意味着梯度会很小,梯度小对于训练来说就意味着非常hard的样本不能充分训练,网络得不到hard样本的有效信息,因此hard样本的效果就会变差。所以如果在hard样本周围loss不是那么平滑,也就是深度学习中经常用的导数为1(像relu一样),那么hard模式会不会就解决了梯度消失的问题。另外loss function还要实现triplet loss对正负样本的兼顾,以及具备margin设计的功能,也就是自适应不同的数据分布。损失函数如下:
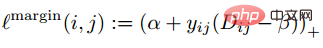
我们称anchor样本与正例样本之间的距离为正例对距离;称anchor样本与负例样本之间的距离为负例对距离。公式中的参数beta定义了正例对距离与负例对距离之间的界限,如果正例对距离Dij大于beta,则损失加大;或者负例对距离Dij小于beta,损失加大。A控制样本的分离间隔;当样本为正例对时,yij为1,样本为负例对时,yij为-1。下图为损失函数曲线。
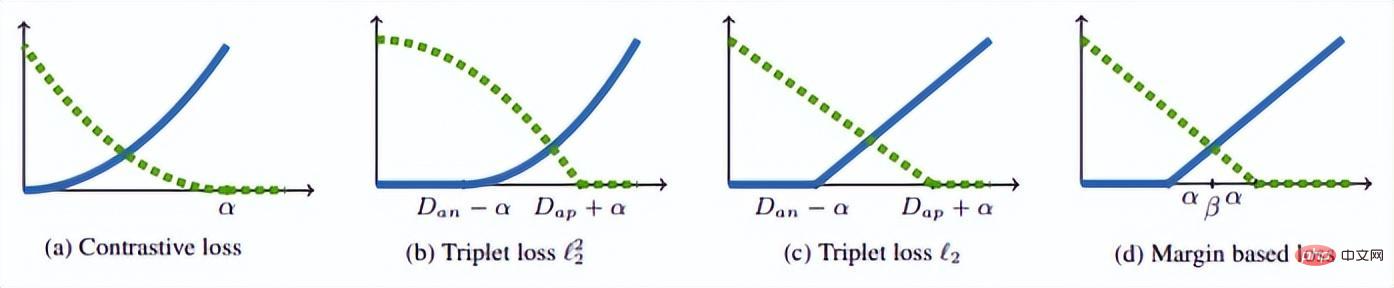
从上图可以看出为什么在非常hard的时候会出现梯度消失的情况,因为离0点近的时候蓝色的线越来越平滑,梯度也就越来越小了。另外作者对的设置也进行了调优,加入了样本偏置、类别偏置以及超参,对损失函数进一步优化,能够根据训练过程自动修改的值。
3. Margin Based Classification
Margin based classification不像在feature层直接计算损失的metric learning那样对feature加直观的强限制,是依然把人脸识别当 classification 任务进行训练,通过对 softmax
公式的改造,间接实现了对 feature 层施加 margin 的限制,使网络最后得到的 feature 更 discriminative。
(1)Center loss
参考论文:A Discriminative Feature Learning Approach for Deep Face Recognition
ECCV 2016的这篇文章主要是提出了一个新的Loss:Center Loss,用以辅助Softmax Loss进行人脸的训练,为了让同一个类别压缩在一起,最终获取更加discriminative的features。center loss意思即为:为每一个类别提供一个类别中心,最小化min-batch中每个样本与对应类别中心的距离,这样就可以达到缩小类内距离的目的。下图为最小化样本和类别中心距离的损失函数。
为每个batch中每个样本对应的类别中心,和特征的维度一样,用欧式距离作为高维流形体距离表达。因此,在softmax的基础上,center loss的损失函数为:
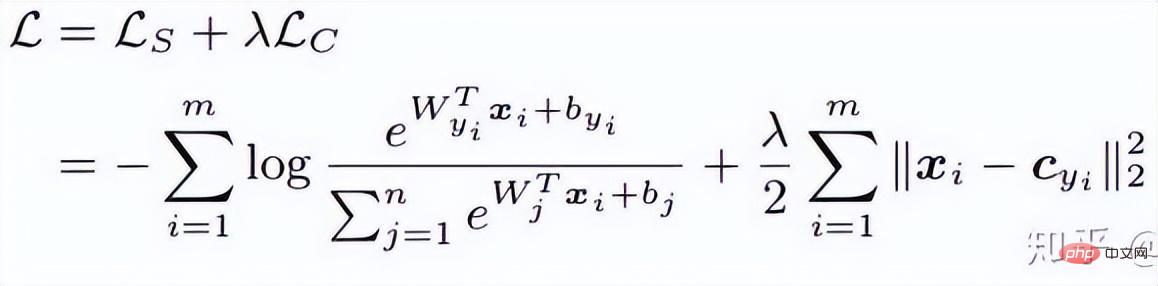
个人理解Center loss就如同在损失函数中加入了聚类的功能,随着训练的进行,样本自觉地聚类在每一个batch的中心,进一步实现类间差异最大化。但是我觉得,对于高维特征,欧氏距离并不能反映聚类的距离,因此这样简单的聚类并不能在高维上取得更好的效果。
(2)L-Softmax
原始的Softmax的目的是使得,将向量相乘的方式变换为向量的模与角度的关系,即,在这个基础上,L-Softmax希望可以通过增加一个正整数变量m,可以看到:
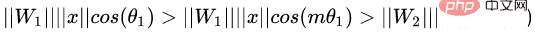
使得产生的决策边界可以更加严格地约束上述不等式,让类内的间距更加的紧凑,让类间的间距更加有区分性。所以基于上式和softmax的公式,可以得到L-softmax的公式为:
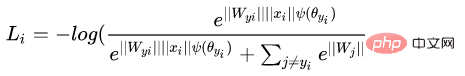
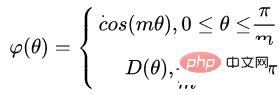
由于cos是减函数,所以乘以m会使得内积变小,最终随着训练,类本身之间的距离会增大。通过控制m的大小,可以看到类内和类间距离的变化,二维图显示如下:
作者为了保障在反向传播和推理过程中能够满足类别向量之间的角度都能够满足margin的过程,并保证单调递减,因此构建了一种新的函数形式:
有人反馈L-Softmax调参难度较大,对m的调参需要反复进行,才能达到更好的效果。
(3)Normface
参考论文:NormFace: L2 Hypersphere Embedding for Face Verification
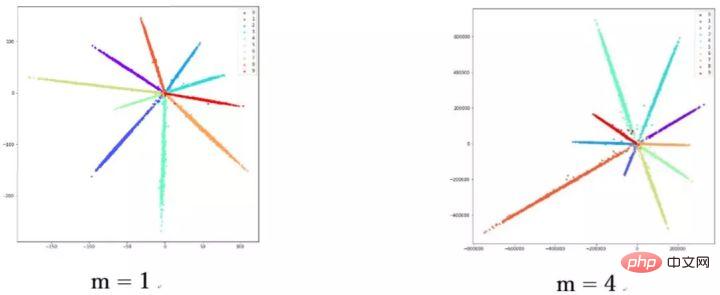
这篇论文是一篇很有意思的文章,文章对于权重与特征归一化做了很多有意思的探讨。文章提出,sphereface虽然好,但是它不优美。在测试阶段,sphereface通过特征间的余弦值来衡量相似性,即以角度为相似性度量。但在训练过程中也有一个问题,权重没有归一化,loss
function在训练过程中减小的同时,会使得权重的模越来越大,所以sphereface损失函数的优化方向并不是很严谨,其实优化的方向还有一部分去增大特征的长度了。有博主做实验发现,随着m的增大,坐标的尺度也在不断增大,如下图所示。
因此作者在优化的过程中,对特征做了归一化处理。相应的损失函数也如下所示:
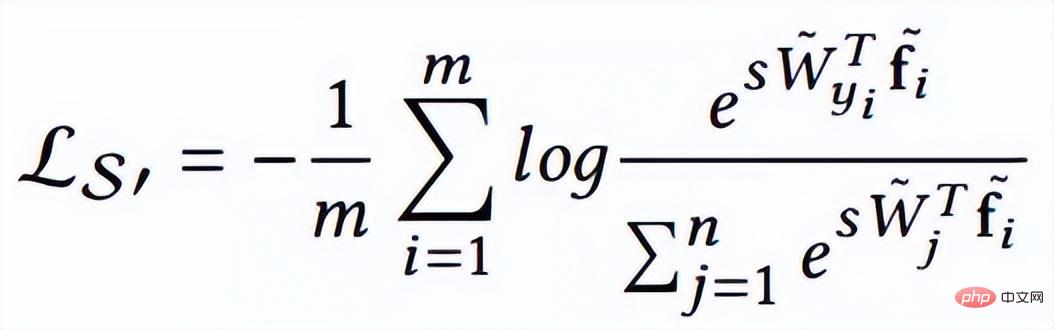
其中W和f都为归一化的特征,两个点积就是角度余弦值。参数s的引入是因为数学上的性质,保证了梯度大小的合理性,原文中有比较直观的解释,可以阅读原论文,并不是重点。s既可以变成可学习的参数,也可以变成超参,论文作者给了很多推荐值,可以在论文中找到。其实,FaceNet中归一化的欧氏距离,和余弦距离是统一的。
4. AM-softmax/CosFace
参考论文:Additive Margin Softmax for Face Verification
CosFace: Large Margin Cosine Loss for Deep Face Recognition
看上面的论文,会发现少了一个东西,那就是margin,或者说是margin的意味少了一些,所以AM-softmax在归一化的基础上有引入了margin。损失函数如下:
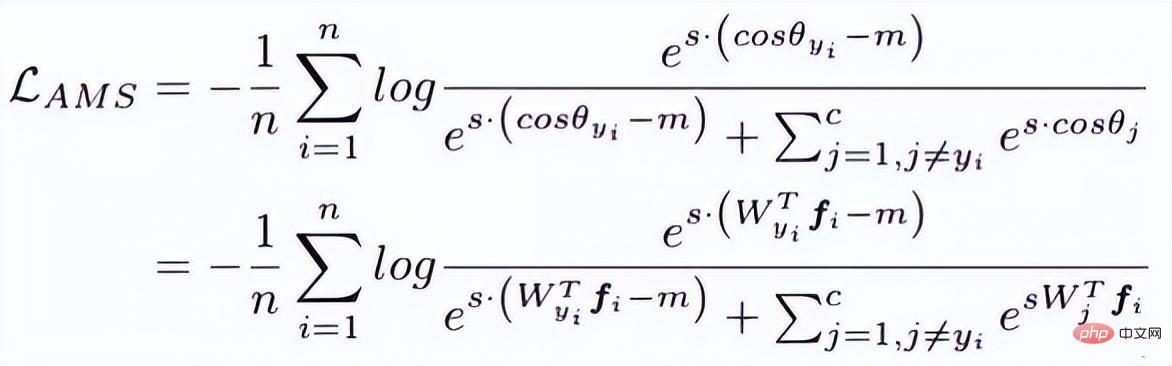
直观上来看,-m比更小,所以损失函数值比Normface里的更大,因此有了margin的感觉。m是一个超参数,控制惩罚,当m越大,惩罚越强。该方法好的一点是容易复现,而且没有很多调参的tricks,效果也很好。
(1)ArcFace
与 AM-softmax 相比,区别在于 Arcface 引入 margin 的方式不同,损失函数:
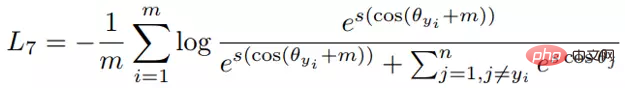
乍一看是不是和 AM-softmax一样?注意 m 是在余弦里面。文章指出基于上式优化得到的特征间的 boundary 更为优越,具有更强的几何解释。
然而这样引入 margin 是否会有问题?仔细想 cos(θ+m) 是否一定比 cos(θ) 小?
最后我们用文章中的图来解释这个问题,并且也由此做一个本章 Margin-based Classification 部分的总结。
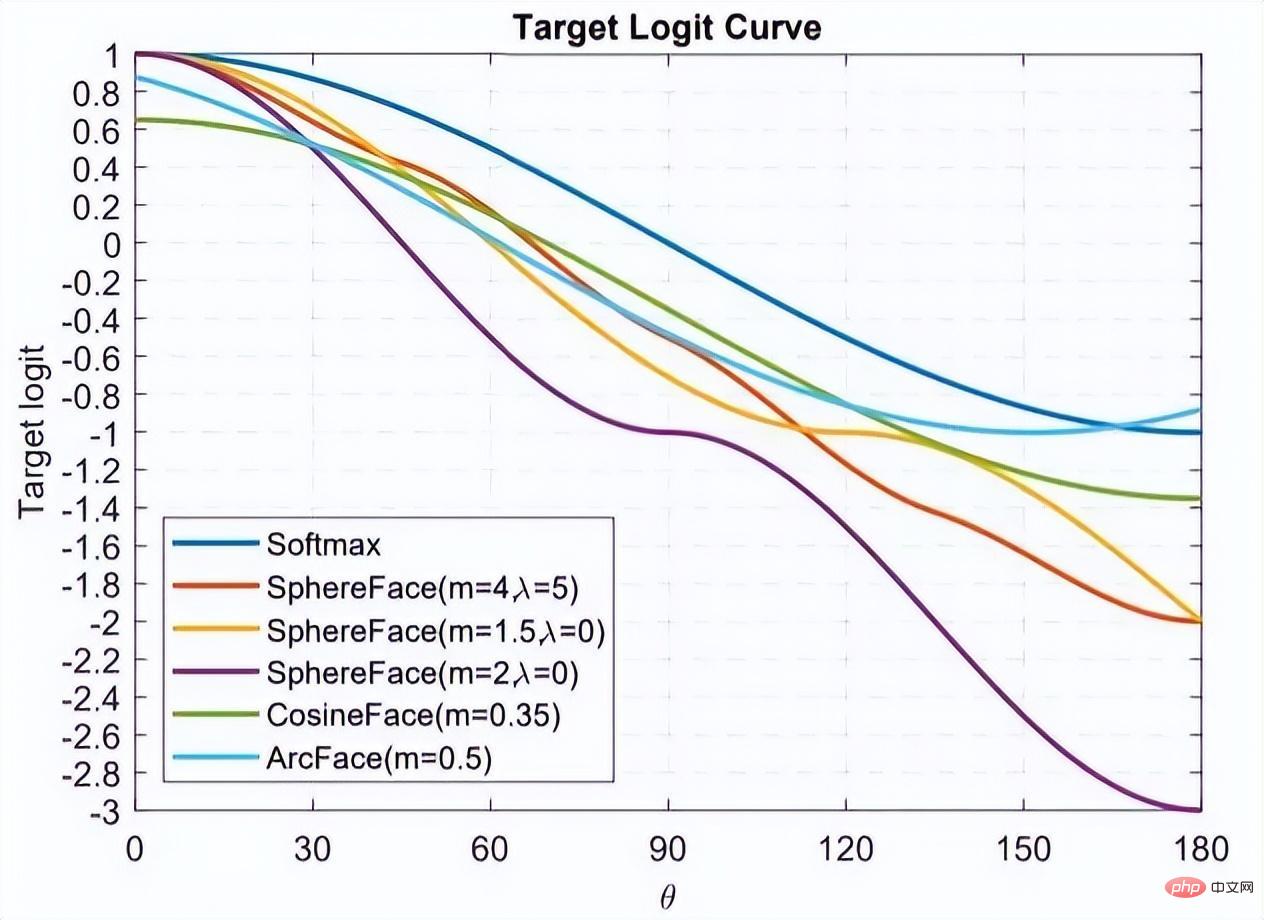
这幅图出自于 Arcface,横坐标为 θ 为特征与类中心的角度,纵坐标为损失函数分子指数部分的值(不考虑 s),其值越小损失函数越大。
看了这么多基于分类的人脸识别论文,相信你也有种感觉,大家似乎都在损失函数上做文章,或者更具体一点,大家都是在讨论如何设计上图的 Target logit-θ 曲线。
这个曲线意味着你要如何优化偏离目标的样本,或者说,根据偏离目标的程度,要给予多大的惩罚。两点总结:
1. 太强的约束不容易泛化。例如 Sphereface 的损失函数在 m=3 或 4 的时候能满足类内最大距离小于类间最小距离的要求。此时损失函数值很大,即 target logits 很小。但并不意味着能泛化到训练集以外的样本。施加太强的约束反而会降低模型性能,且训练不易收敛。
2. 选择优化什么样的样本很重要。Arcface 文章中指出,给予 θ∈[60° , 90°] 的样本过多惩罚可能会导致训练不收敛。优化 θ ∈ [30° , 60°] 的样本可能会提高模型准确率,而过分优化 θ∈[0° , 30°] 的样本则不会带来明显提升。至于更大角度的样本,偏离目标太远,强行优化很有可能会降低模型性能。
这也回答了上一节留下的疑问,上图曲线 Arcface 后面是上升的,这无关紧要甚至还有好处。因为优化大角度的 hard sample 可能没有好处。这和 FaceNet 中对于样本选择的 semi-hard 策略是一个道理。
Margin based classification 延伸阅读
1. A discriminative feature learning approach for deep face recognition [14]
提出了 center loss,加权整合进原始的 softmax loss。通过维护一个欧式空间类中心,缩小类内距离,增强特征的 discriminative power。
2. Large-margin softmax loss for convolutional neural networks [10]
Sphereface 作者的前一篇文章,未归一化权重,在 softmax loss 中引入了 margin。里面也涉及到 Sphereface 的训练细节。
使用ModelArts训练人脸模型
人脸识别算法实现解释
本文我们部署的人脸识别算法模型主要包括两部分:
- 第一部分为人脸检测算法模型,该模型将图片中的人脸进行识别,返回人脸的位置信息;
- 第二部分为人脸特征表示算法模型,也称之为识别模型。这个部分将crop出的人脸图像embedding到一个固定维度大小的向量,然后利用该向量与底库进行比对,完成人脸识别的整体流程。
如下图所示,整体算法实现的流程分为线下和线上两个部分,在每次对不同的人进行识别之前首先利用训练好的算法生成人脸标准底库,将底库数据保存在modelarts上。然后在每次推理的过程中,图片输入会经过人脸检测模型和人脸识别模型得到人脸特征,然后基于该特征在底库中搜索相似对最高的特征,完成人脸识别的过程。

在实现过程中,我们采用了基于Retinaface+resnet50+arcface的算法完成人脸图像的特征提取,其中Retinaface作为检测模型,resnet50+arcface作为特征提取模型。
在镜像中,运行训练的脚本有两个,分别对应人脸检测的训练和人脸识别的训练。
- 人脸检测的训练脚本为:
run_face_detection_train.sh
该脚本的启动命令为
<span style="color: rgb(111, 66, 193); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">sh</span> run_face_detection_train.sh data_path model_output_path
其中model_output_path为模型输出的路径,data_path为人脸检测训练集的输入路径,输入的图片路径结构如下:
detection_train_data/train/images/label.txtval/images/label.txttest/images/label.txt
- 人脸识别的训练脚本为:
run_face_recognition_train.sh
该脚本的启动命令为
<span style="color: rgb(111, 66, 193); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">sh</span> run_face_recognition_train.sh data_path model_output_path
其中model_output_path为模型输出的路径,data_path为人脸检测训练集的输入路径,输入的图片路径结构如下:
recognition_train_data/cele.idxcele.lstcele.recproperty
- 底库生成的脚本:
run_generate_data_base.sh
该脚本的启动命令为:
<span style="color: rgb(111, 66, 193); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">sh</span> run_generate_data_base.sh data_path detect_model_path recognize_model_path db_output_path
其中data_path为底库输入路径,detect_model_path为检测模型输入路径,recognize_model_path为识别模型输入路径,db_output_path为底库输出路径。
- 底库生成的脚本:
run_face_recognition.sh
该脚本的启动命令为:
<span style="color: rgb(111, 66, 193); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">sh</span> run_generate_data_base.sh data_path db_path detect_model_path recognize_model_path
其中data_path为测试图片输入路径,db_path为底库路径,detect_model_path为检测模型的输入路径,recognize_model_path为识别模型的输入路径
训练过程
华为云ModelArts有训练作业的功能,可以用来作模型训练以及对模型训练的参数和版本进行管理。这个功能对于多版本迭代开发的开发者有一定的帮助。训练作业中有预置的一些镜像和算法,当前对于常用的框架均有预置镜像(包括Caffe, MXNet, Pytorch, TensorFlow )和华为自己的昇腾芯片的引擎镜像(Ascend-Powered-Engine)。
本文我们会基于ModelArts的自定义镜像特性,上传自己在本机调试完毕的完整镜像,利用华为云的GPU资源训练模型。
我们是想在华为云上的ModelArts基于网站上常见的明星的数据训练完成一个人脸识别模型。在这个过程中,由于人脸识别网络是工程师自己设计的网络结构,所以需要通过自定义镜像进行上传。所以整个人脸训练的过程分为以下九步:
- 构建本地Docker环境
- 从华为云下载基础镜像
- 根据自己需求构建自定义镜像环境
- 导入训练数据到自定义镜像
- 导入人脸识别底库到自定义镜像
- 导入预训练模型到自定义镜像
- 上传自定义镜像到SWR
- 使用华为云训练作业进行训练
- 使用华为云进行推理工作
构建本地Docker环境
Docker环境可以在本地计算机进行构建,也可以在华为云上购买一台弹性云服务器进行Docker环境构建。全过程参考Docker官方的文档进行:
https://docs.docker.com/engine/install/binaries/#install-static-binaries
从华为云下载基础镜像
官网说明网址:
https://support.huaweicloud.com/engineers-modelarts/modelarts_23_0085.html#modelarts_23_0085__section19397101102
我们训练需要使用到的是MXNet的环境,首先需要从华为云上下载相对应的自定义镜像的基础镜像。官网给出的下载命令如下:

在训练作业基础镜像的规范里,找到了这个命令的解释。
https://support.huaweicloud.com/engineers-modelarts/modelarts_23_0217.html
根据我们的脚本要求,我使用的是cuda9的镜像:

官方还给出了另一种方法,就是使用docker file的。基础镜像的dockerfile也是在训练作业基础镜像的规范里找到的。可以参考一下的dockerfile:
https://github.com/huaweicloud/ModelArts-Lab/tree/master/docs/custom_image/custom_base
根据自己需求构建自定义镜像环境
由于比较懒,所以还是没有使用Dockerfile的方式自己构建镜像。我采用的是另一种方式!
因为我们的需求就是cuda 9 还有一些相关的python依赖包,假设官方的镜像提供的是cuda 9的,我们大可以在训练脚本中跟着这个教程加一个requirement.txt。简单高效快捷就能解决需求!!!下面是教程~~~
https://support.huaweicloud.com/modelarts_faq/modelarts_05_0063.html
上传自定义镜像到SWR
官网教程:
- https://support.huaweicloud.com/engineers-modelarts/modelarts_23_0085.html#modelarts_23_0085__section19397101102
- https://support.huaweicloud.com/usermanual-swr/swr_01_0011.html
上传镜像的页面写着,文件解压后不得超过2GB。但是官方提供的基础镜像就3.11GB,我们加上需要的预训练的模型后镜像是5+GB,所以不能使用页面进行上传的工作,必须使用客户端。上传镜像首先要创建组织,
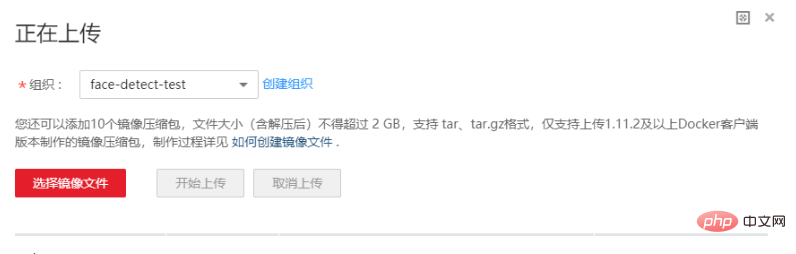
如果觉得产品文档理解还是比较难,可以尝试一下SWR页面的pull/push镜像体验:

这里后面引导了客户如何将本地镜像推上云端,第一步是登陆仓库:
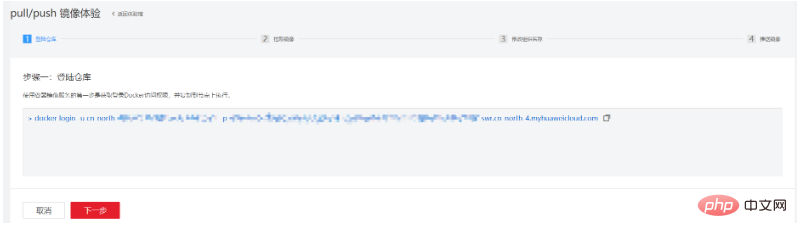
第二步拉取镜像,这个我们就用自己打的自定义镜像代替,
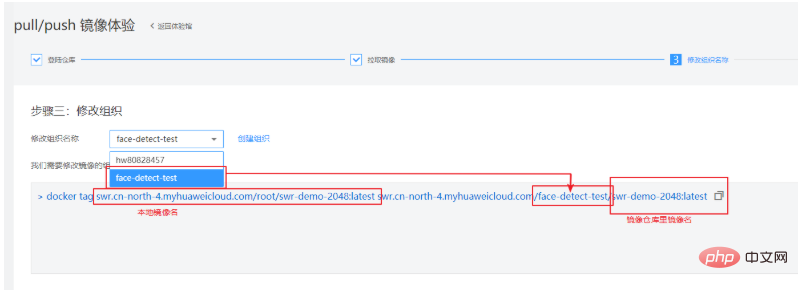
第三步修改组织,使用根据产品文档创建的组织名。在这一步需要将本地的一个镜像重命名为云上识别的镜像命。具体看下图解释:
第四步推送镜像,
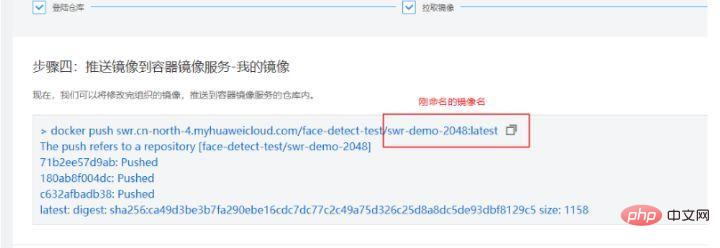
当熟练掌握这四步技巧的时候,可以脱离这个教程,使用客户端进行上传。使用客户端登陆然后上传。客户端登陆可以使用生成临时docker loging指令。这个页面在”我的镜像“-> ”客户端上传“->”生成临时docker login指令“中:
在本地docker环境中,使用这个生成的临时docker login指令登陆后,使用下面的命令进行上传镜像:

使用华为云训练作业进行训练
华为云ModelArts提供训练作业给用户进行模型训练。在训练作业中有预置镜像和可以选择自定义镜像。预置的镜像包含市面上大部分框架,没有特殊要求的时候,使用这些框架的镜像进行训练也是很方便的。本次测试还是使用的自定义镜像。
自定义镜像中不仅需要在镜像中进行配置自己的环境,假如改变了训练作业启动的方式,还需要修改训练的启动脚本。从华为云ModelArts官网拉取下来的官方镜像的/home/work/路径下有一个启动脚本”run_train.sh”,自定义的启动脚本需要基于这个脚本进行修改。主要是要注意
“dls_get_app”,这个是从OBS下载相关的命令。其他的部分根据自己的训练脚本进行修改。
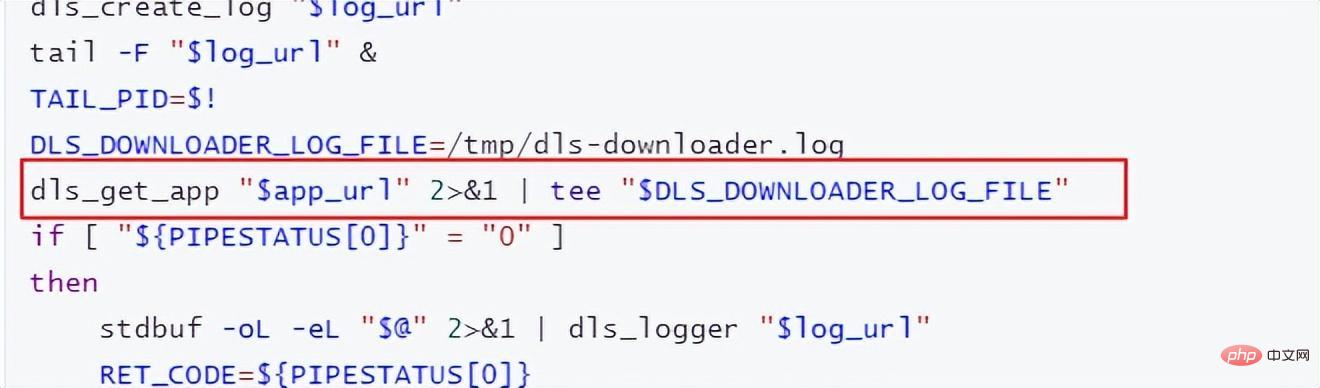
如果需要上传训练结果或者模型到OBS,需要参考”dls_get_app”加”dls_upload_model”的命令。在我们这次训练中,上传的脚本如下:

训练作业进行调试的时候,当前可以使用免费提供的一小时V100。ModelArts的训练作业一个比较好的地方是方便了我们版本管理。版本中会记录所有通过运行参数传入到训练脚本里的所有参数,还可以使用版本对比进行参数对比。还有个比较方便的地方是可以基于某一个版本进行修改,减少了重新输入所有参数这一步骤,比较方便调试。
在训练作业中训练完成后,还可以在ModelArts中进行模型部署上线。
后记
目前针对人脸识别算法的优化已经到达一个瓶颈期,但是在技术层面针对人脸面部结构的相似性、人脸的姿态、年龄变化、复杂环境的光照变化、人脸的饰物遮挡等还面临这很多的问题,因此基于多种算法技术的融合解决人脸识别中的各种问题仍然在安防、互联网中有着巨大的市场。另外,随着人脸支付的逐渐完善,人脸识别系统也应用于银行、商场等等,因此人脸识别的安全问题和防攻击问题也是一个亟待解决的问题,例如活体检测、3D面部识别等等。
最后,人脸识别作为目前深度学习中应用比较成熟的项目,其发展还与深度学习本身技术发展息息相关,目前在很多优化上,深度学习最大的缺点是没有相应的数学理论支撑,优化所提升的性能也很有限,因此对深度学习算法本身的研究也是未来的重点。
以上是一文看懂人脸识别算法技术发展脉络的详细内容。更多信息请关注PHP中文网其他相关文章!

 Gemma范围:Google&#039;用于凝视AI的显微镜Apr 17, 2025 am 11:55 AM
Gemma范围:Google&#039;用于凝视AI的显微镜Apr 17, 2025 am 11:55 AM使用Gemma范围探索语言模型的内部工作 了解AI语言模型的复杂性是一个重大挑战。 Google发布的Gemma Scope是一种综合工具包,为研究人员提供了一种强大的探索方式
 谁是商业智能分析师以及如何成为一位?Apr 17, 2025 am 11:44 AM
谁是商业智能分析师以及如何成为一位?Apr 17, 2025 am 11:44 AM解锁业务成功:成为商业智能分析师的指南 想象一下,将原始数据转换为驱动组织增长的可行见解。 这是商业智能(BI)分析师的力量 - 在GU中的关键作用
 如何在SQL中添加列? - 分析VidhyaApr 17, 2025 am 11:43 AM
如何在SQL中添加列? - 分析VidhyaApr 17, 2025 am 11:43 AMSQL的Alter表语句:动态地将列添加到数据库 在数据管理中,SQL的适应性至关重要。 需要即时调整数据库结构吗? Alter表语句是您的解决方案。本指南的详细信息添加了Colu
 业务分析师与数据分析师Apr 17, 2025 am 11:38 AM
业务分析师与数据分析师Apr 17, 2025 am 11:38 AM介绍 想象一个繁华的办公室,两名专业人员在一个关键项目中合作。 业务分析师专注于公司的目标,确定改进领域,并确保与市场趋势保持战略一致。 simu
 什么是Excel中的Count和Counta? - 分析VidhyaApr 17, 2025 am 11:34 AM
什么是Excel中的Count和Counta? - 分析VidhyaApr 17, 2025 am 11:34 AMExcel 数据计数与分析:COUNT 和 COUNTA 函数详解 精确的数据计数和分析在 Excel 中至关重要,尤其是在处理大型数据集时。Excel 提供了多种函数来实现此目的,其中 COUNT 和 COUNTA 函数是用于在不同条件下统计单元格数量的关键工具。虽然这两个函数都用于计数单元格,但它们的设计目标却针对不同的数据类型。让我们深入了解 COUNT 和 COUNTA 函数的具体细节,突出它们独特的特性和区别,并学习如何在数据分析中应用它们。 要点概述 理解 COUNT 和 COU
 Chrome在这里与AI:每天都有新事物!Apr 17, 2025 am 11:29 AM
Chrome在这里与AI:每天都有新事物!Apr 17, 2025 am 11:29 AMGoogle Chrome的AI Revolution:个性化和高效的浏览体验 人工智能(AI)正在迅速改变我们的日常生活,而Google Chrome正在领导网络浏览领域的负责人。 本文探讨了兴奋
 AI的人类方面:福祉和四人底线Apr 17, 2025 am 11:28 AM
AI的人类方面:福祉和四人底线Apr 17, 2025 am 11:28 AM重新构想影响:四倍的底线 长期以来,对话一直以狭义的AI影响来控制,主要集中在利润的最低点上。但是,更全面的方法认识到BU的相互联系
 您应该知道的5个改变游戏规则的量子计算用例Apr 17, 2025 am 11:24 AM
您应该知道的5个改变游戏规则的量子计算用例Apr 17, 2025 am 11:24 AM事情正稳步发展。投资投入量子服务提供商和初创企业表明,行业了解其意义。而且,越来越多的现实用例正在出现以证明其价值超出


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

Dreamweaver Mac版
视觉化网页开发工具

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

