


arXiv论文“JPerceiver: Joint Perception Network for Depth, Pose and Layout Estimation in Driving Scenes“,上传于22年7月,报道关于澳大利亚悉尼大学陶大程教授和北京京东研究院的工作。

深度估计、视觉测程计(VO)和鸟瞰图(BEV)场景布局估计是驾驶场景感知的三个关键任务,这是自主驾驶中运动规划和导航的基础。虽然相互补充,但通常侧重于单独的任务,很少同时处理这三个任务。
一种简单的方法是以顺序或并行的方式独立地完成,但有三种缺点,即1)深度和VO结果受到固有的尺度多义问题的影响;2) BEV布局通常单独估计道路和车辆,而忽略显式叠加-下垫关系;3)虽然深度图是用于推断场景布局的有用几何线索,但实际上直接从前视图图像预测BEV布局,并没有使用任何深度相关信息。
本文提出一种联合感知框架JPerceiver来解决这些问题,从单目视频序列中同时估计尺度-觉察深度、VO以及BEV布局。用跨视图几何变换(cross-view geometric transformation,CGT),根据精心设计的尺度损失,将绝对尺度从道路布局传播到深度和VO。同时,设计一个跨视图和模态转换(cross-view and cross-modal transfer,CCT)模块,用深度线索通过注意机制推理道路和车辆布局。
JPerceiver以端到端的多任务学习方式进行训练,其中CGT尺度损失和CCT模块促进任务间知识迁移,利于每个任务的特征学习。
代码和模型可下载https://github.com/sunnyHelen/JPerceiver.
如图所示,JPerceiver分别由深度、姿态和道路布局三个网络组成,都基于编码器-解码器架构。深度网络旨在预测当前帧It的深度图Dt,其中每个深度值表示3D点与摄像头之间的距离。姿态网络的目标是预测在当前帧It及其相邻帧It+m之间姿态变换Tt→t+m。道路布局网络的目标是估计当前帧的BEV布局Lt,即俯视笛卡尔平面中道路和车辆的语义占用率。这三个网络在训练期间联合优化。
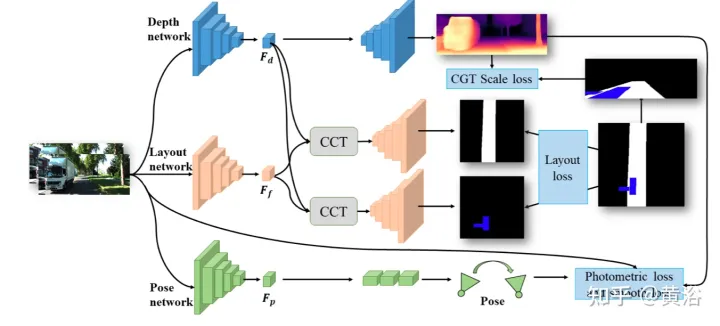
预测深度和姿态的两个网络以自监督方式用光度损失和平滑度损失进行联合优化。此外,还设计CGT尺度损失来解决单目深度和VO估计的尺度多义问题。
为实现尺度-觉察的环境感知,用BEV布局中的尺度信息,提出CGT的尺度损失用于深度估计和VO。由于BEV布局显示了BEV笛卡尔平面中的语义占用,分别覆盖自车前面Z米和左右(Z/2)米的范围。其提供一个自然距离场(natural distance field)z,每个像素相对于自车的度量距离zij,如图所示:
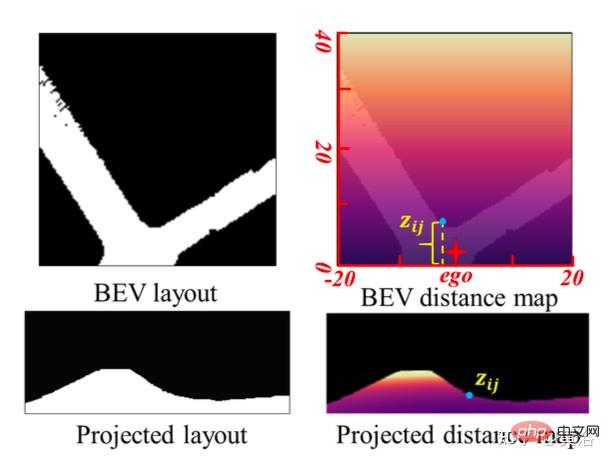
假设BEV平面是地面,其原点刚好在自车坐标系原点下面,基于摄像机外参可以通过单应性变换将BEV平面投影到前向摄像头。因此,BEV距离场z可以投影到前向摄像头中,如上图所示,用它来调节预测深度d,从而导出CGT尺度损失:
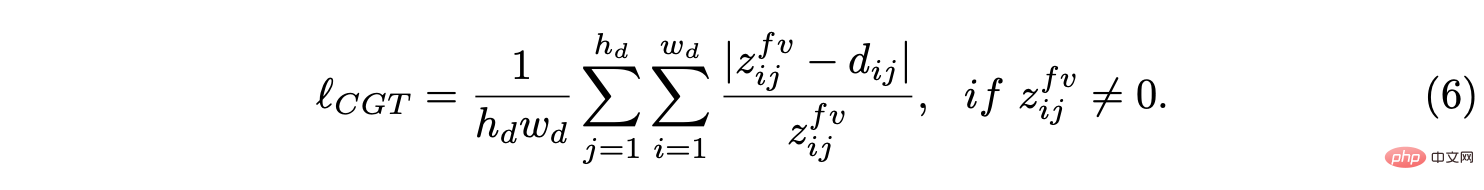
对于道路布局估计,采用了编码器-解码器网络结构。值得注意的是,用一个共享编码器作为特征提取器和不同的解码器来同时学习不同语义类别的BEV布局。此外,设CCT模块,以加强任务之间的特征交互和知识迁移,并为BEV的空间推理提供3-D几何信息。为了正则化道路布局网络,将各种损失项组合在一起,形成混合损失,并实现不同类的平衡优化。
CCT是研究前向视图特征Ff、BEV布局特征Fb、重转换的前向特征Ff′和前向深度特征FD之间的相关性,并相应地细化布局特征,如图所示:分两部分,即跨视图模块和跨模态模块的CCT-CV和CCT-CM。
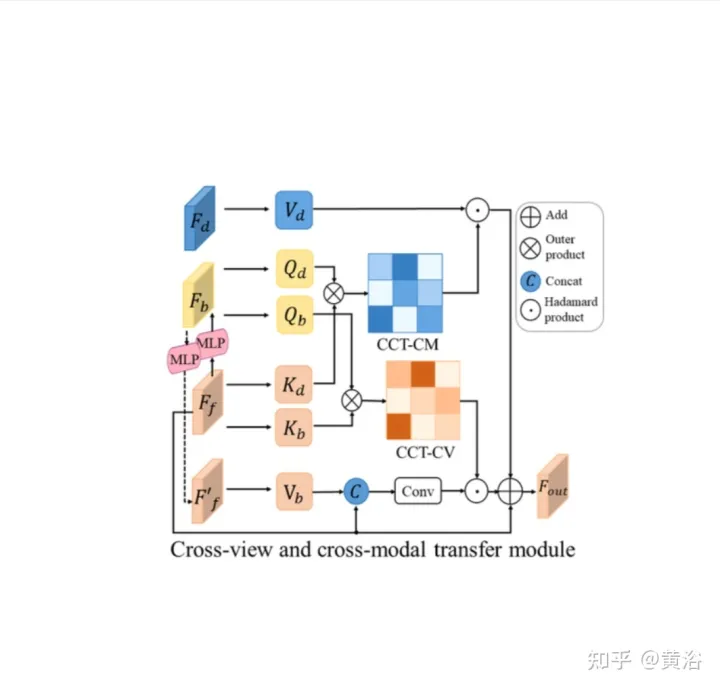
在CCT中,Ff和Fd由相应感知分支的编码器提取,而Fb通过一个视图投影MLP将Ff转换为BEV获得,一个循环损失约束的相同MLP将其重新转换为Ff′。
在CCT-CV,交叉注意机制用于发现前向视图和BEV特征之间的几何对应关系,然后指导前向视图信息的细化,并为BEV推理做好准备。为了充分利用前向视图图像特征,将Fb和Ff投影到patches:Qbi和Kbi,分别作为query和 key。
除了利用前向视图特征外,还部署CCT-CM来施加来自Fd的3-D几何信息。由于Fd是从前向视图图像中提取的,因此以Ff为桥来减少跨模态间隙并学习Fd和Fb之间的对应关系是合理的。Fd起Value的作用,由此获得与BEV信息相关有价值的3-D几何信息,并进一步提高道路布局估计的准确性。
在探索同时预测不同布局的联合学习框架过程中,不同语义类别的特征和分布存在很大差异。对于特征,驾驶场景中的道路布局通常需要连接,而不同的车辆目标必须分割。
对于分布,观察到的直线道路场景比转弯场景多,这在真实数据集中是合理的。这种差异和不平衡增加了BEV布局学习的难度,尤其是联合预测不同类别,因为在这种情况下,简单的交叉熵(CE)损失或L1损失会失效。将几种分割损失(包括基于分布的CE损失、基于区域的IoU损失和边界损失)合并为混合损失,预测每个类别的布局。
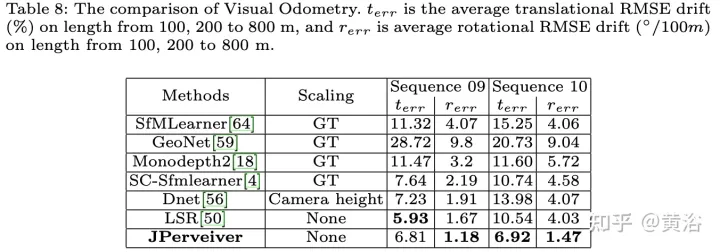
实验结果如下:
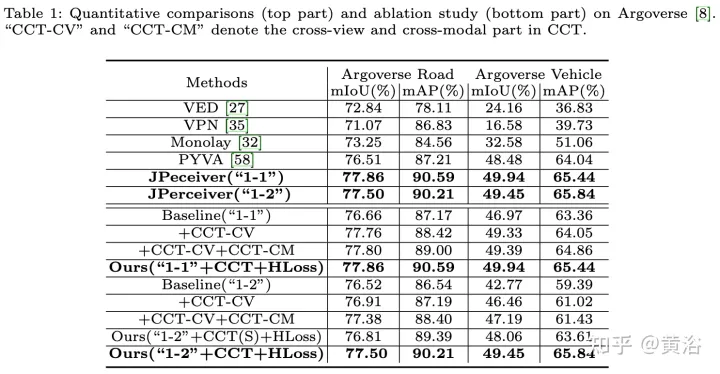
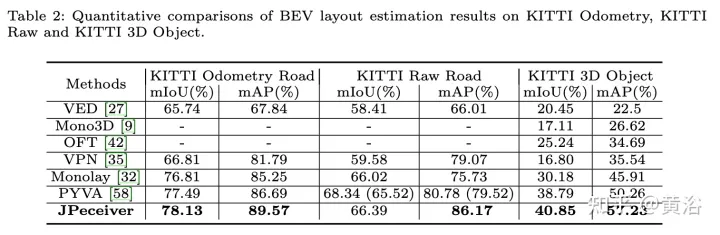
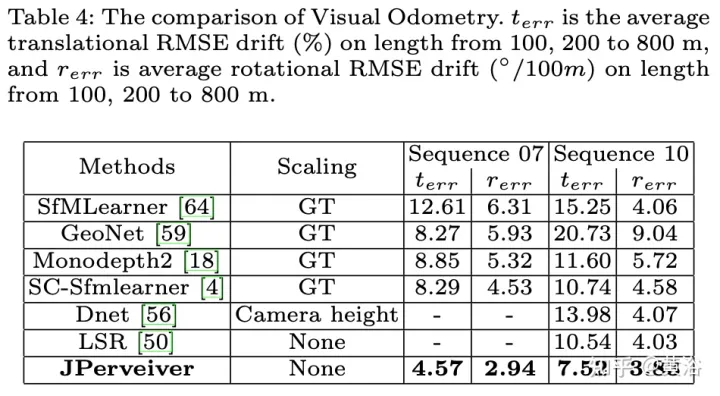
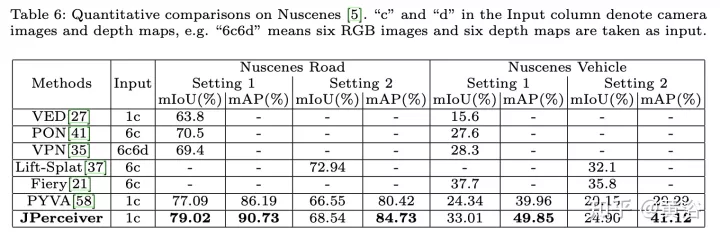
以上是联合驾驶场景中深度、姿态和道路估计的感知网络的详细内容。更多信息请关注PHP中文网其他相关文章!

![无法使用chatgpt!解释可以立即测试的原因和解决方案[最新2025]](https://img.php.cn/upload/article/001/242/473/174717025174979.jpg?x-oss-process=image/resize,p_40) 无法使用chatgpt!解释可以立即测试的原因和解决方案[最新2025]May 14, 2025 am 05:04 AM
无法使用chatgpt!解释可以立即测试的原因和解决方案[最新2025]May 14, 2025 am 05:04 AMChatGPT无法访问?本文提供多种实用解决方案!许多用户在日常使用ChatGPT时,可能会遇到无法访问或响应缓慢等问题。本文将根据不同情况,逐步指导您解决这些问题。 ChatGPT无法访问的原因及初步排查 首先,我们需要确定问题是出在OpenAI服务器端,还是用户自身网络或设备问题。 请按照以下步骤进行排查: 步骤1:检查OpenAI官方状态 访问OpenAI Status页面 (status.openai.com),查看ChatGPT服务是否正常运行。如果显示红色或黄色警报,则表示Open
 计算ASI的风险始于人类的思想May 14, 2025 am 05:02 AM
计算ASI的风险始于人类的思想May 14, 2025 am 05:02 AM2025年5月10日,麻省理工学院物理学家Max Tegmark告诉《卫报》,AI实验室应在释放人工超级智能之前模仿Oppenheimer的三位一体测试演算。 “我的评估是'康普顿常数',这是一场比赛的可能性
 易于理解的解释如何编写和撰写歌词和推荐工具May 14, 2025 am 05:01 AM
易于理解的解释如何编写和撰写歌词和推荐工具May 14, 2025 am 05:01 AMAI音乐创作技术日新月异,本文将以ChatGPT等AI模型为例,详细讲解如何利用AI辅助音乐创作,并辅以实际案例进行说明。我们将分别介绍如何通过SunoAI、Hugging Face上的AI jukebox以及Python的Music21库进行音乐创作。 通过这些技术,每个人都能轻松创作原创音乐。但需注意,AI生成内容的版权问题不容忽视,使用时务必谨慎。 让我们一起探索AI在音乐领域的无限可能! OpenAI最新AI代理“OpenAI Deep Research”介绍: [ChatGPT]Ope
 什么是chatgpt-4?对您可以做什么,定价以及与GPT-3.5的差异的详尽解释!May 14, 2025 am 05:00 AM
什么是chatgpt-4?对您可以做什么,定价以及与GPT-3.5的差异的详尽解释!May 14, 2025 am 05:00 AMChatGPT-4的出现,极大地拓展了AI应用的可能性。相较于GPT-3.5,ChatGPT-4有了显着提升,它具备强大的语境理解能力,还能识别和生成图像,堪称万能的AI助手。在提高商业效率、辅助创作等诸多领域,它都展现出巨大的潜力。然而,与此同时,我们也必须注意其使用上的注意事项。 本文将详细解读ChatGPT-4的特性,并介绍针对不同场景的有效使用方法。文中包含充分利用最新AI技术的技巧,敬请参考。 OpenAI发布的最新AI代理,“OpenAI Deep Research”详情请点击下方链
 解释如何使用chatgpt应用程序!日本支持和语音对话功能May 14, 2025 am 04:59 AM
解释如何使用chatgpt应用程序!日本支持和语音对话功能May 14, 2025 am 04:59 AMCHATGPT应用程序:与AI助手释放您的创造力!初学者指南 ChatGpt应用程序是一位创新的AI助手,可处理各种任务,包括写作,翻译和答案。它是一种具有无限可能性的工具,可用于创意活动和信息收集。 在本文中,我们将以一种易于理解的方式解释初学者,从如何安装chatgpt智能手机应用程序到语音输入功能和插件等应用程序所独有的功能,以及在使用该应用时要牢记的要点。我们还将仔细研究插件限制和设备对设备配置同步
 如何使用中文版Chatgpt?注册程序和费用的说明May 14, 2025 am 04:56 AM
如何使用中文版Chatgpt?注册程序和费用的说明May 14, 2025 am 04:56 AMChatGPT中文版:解锁中文AI对话新体验 ChatGPT风靡全球,您知道它也提供中文版本吗?这款强大的AI工具不仅支持日常对话,还能处理专业内容,并兼容简体中文和繁体中文。无论是中国地区的使用者,还是正在学习中文的朋友,都能从中受益。 本文将详细介绍ChatGPT中文版的使用方法,包括账户设置、中文提示词输入、过滤器的使用、以及不同套餐的选择,并分析潜在风险及应对策略。此外,我们还将对比ChatGPT中文版和其他中文AI工具,帮助您更好地了解其优势和应用场景。 OpenAI最新发布的AI智能
 5 AI代理神话,您需要停止相信May 14, 2025 am 04:54 AM
5 AI代理神话,您需要停止相信May 14, 2025 am 04:54 AM这些可以将其视为生成AI领域的下一个飞跃,这为我们提供了Chatgpt和其他大型语言模型聊天机器人。他们可以代表我们采取行动,而不是简单地回答问题或产生信息
 易于理解使用Chatgpt创建和管理多个帐户的非法性的解释May 14, 2025 am 04:50 AM
易于理解使用Chatgpt创建和管理多个帐户的非法性的解释May 14, 2025 am 04:50 AM使用chatgpt有效的多个帐户管理技术|关于如何使用商业和私人生活的详尽解释! Chatgpt在各种情况下都使用,但是有些人可能担心管理多个帐户。本文将详细解释如何为ChatGpt创建多个帐户,使用时该怎么做以及如何安全有效地操作它。我们还介绍了重要的一点,例如业务和私人使用差异,并遵守OpenAI的使用条款,并提供指南,以帮助您安全地利用多个帐户。 Openai


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

Dreamweaver Mac版
视觉化网页开发工具

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

