
英特尔助力构建开源大规模稀疏模型训练 / 预测引擎 DeepRec

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2023-04-08 22:01:101656浏览
DeepRec(PAI-TF)是阿里巴巴集团统一的开源推荐引擎(https://github.com/alibaba/DeepRec),主要用于稀疏模型训练和预测,可支撑千亿特征、万亿样本的超大规模稀疏训练,在训练性能和效果方面均有明显优势;目前DeepRec已支持淘宝搜索、推荐、广告等场景,并广泛应用于淘宝、天猫、阿里妈妈、高德等业务。
英特尔自2019年以来就与阿里巴巴 PAI团队紧密合作,将英特尔人工智能(Artificial Intelligence,AI)技术应用到DeepRec中,针对算子、子图、runtime、框架层和模型等多个层面进行优化,以充分发挥英特尔软硬件优势,助力阿里巴巴加速内外部AI业务性能。
DeepRec主要优势
当前主流的开源引擎对超大规模稀疏训练场景的支持尚有一定局限,例如,不支持在线训练、特征无法动态加载、线上部署迭代不方便等,特别是性能难以达到业务需求的问题尤为明显。为解决上述问题,DeepRec基于TensorFlow1.15针对稀疏模型场景进行了深度定制优化,主要措施包含以下三类:
模型效果:主要通过增加EmbeddingVariable(EV)动态弹性特征功能以及改进Adagrad Optimizer来实现优化。EV功能解决了原生Variable size大小难以预估、特征冲突等问题,并提供了丰富的特征准入和淘汰策略等进阶功能;同时,针对特征出现频次进行冷热自动配置特征维度问题,增加了高频特征表达力,缓解了过拟合,能够明显提高稀疏模型效果;
训练和推理性能:针对稀疏场景,DeepRec在分布式、子图、算子、Runtime等方面进行了深度性能优化,包括分布式策略优化、自动流水线SmartStage、自动图融合、Embedding和Attention等图优化、常见稀疏算子优化、内存管理优化,大幅降低了内存使用量,显著加速了端到端的训练和推理性能;
部署及Serving :DeepRec支持增量模型导出和加载,实现了10TB级别的超大模型分钟级别的在线训练和更新上线,满足了业务对时效性的高要求;针对稀疏模型中特征存在冷热倾斜的特性,DeepRec提供了多级混合存储(可达四级混合存储,即HBM+DRAM+PMem+SSD)的能力,可在提升大模型性能的同时降低成本。
英特尔技术助力DeepRec实现高性能
英特尔与阿里巴巴 PAI团队的紧密合作在实现以上三个独特优势中都发挥了重要作用,DeepRec三大优势也充分体现了英特尔技术的巨大价值:
在性能优化方面,英特尔超大规模云软件团队与阿里巴巴紧密合作,针对CPU平台,从算子、子图、框架、runtime等多个级别进行优化,充分利用英特尔® 至强® 可扩展处理器的各种新特征,更大程度发挥硬件优势;
为了提升DeepRec在CPU平台的易用性,还搭建了modelzoo来支持绝大部分主流推荐模型,并将DeepRec的独特EV功能应用到这些模型中,实现了开箱即用的用户体验。
同时,针对超大规模稀疏训练模型EV对存储和KV查找操作的特殊需求,英特尔傲腾创新中心团队提供基于英特尔® 傲腾TM 持久内存(简称“PMem”)的内存管理和存储方案,支持和配合DeepRec多级混合存储方案,满足了大内存和低成本需求;可编程解决方案事业部团队使用FPGA实现对Embedding的KV查找功能,大幅提升了Embedding查询能力,同时可释放更多的CPU资源。 结合CPU、PMem和FPGA的不同硬件特点,从系统角度出发,针对不同需求更加充分地发挥英特尔软硬件优势,可加速DeepRec在阿里巴巴 AI业务中的落地,并为整个稀疏场景的业务生态提供更优的解决方案。
英特尔® DL Boost为DeepRec提供关键性能加速
英特尔® DL Boost(英特尔® 深度学习加速)对DeepRec的优化,主要体现在框架优化、算子优化、子图优化和模型优化四个层面。
- 英特尔 x86 平台 AI 能力演进- 英特尔® DL Boost
自英特尔® 至强® 可扩展处理器问世以来,通过从 AVX 256 升级到 AVX-512,英特尔将 AVX 的能力提高了一倍,极大地提升了深度学习训练和推理能力;而第二代英特尔® 至强® 可扩展处理器中又引入 DL Boost_VNNI,大幅提升了 INT8 乘加计算性能;自第三代英特尔® 至强® 可扩展处理器之后,英特尔推出支持BFloat16(BF16)数据类型的指令集,来进一步提高深度学习训练和推理性能。随着硬件技术的不断创新和发展,英特尔将在下一代至强® 可扩展处理器推出新的AI处理技术,进一步提高 VNNI 和 BF16 从 1 维-向量到 2 维-矩阵的能力。上述的硬件指令集技术在DeepRec的优化中均已有所应用,使得针对不同的计算需求可使用不同的硬件特征,也验证了英特尔® AVX-512和BF16非常适合稀疏场景的训练和推理加速。
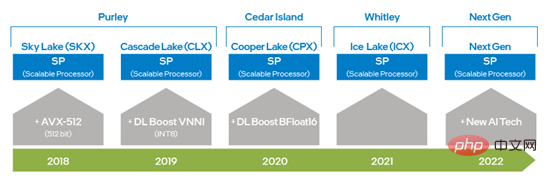
图一 英特尔 x86 平台 AI 能力演进图
- 框架优化
DeepRec集成了英特尔开源的跨平台深度学习性能加速库oneDNN(oneAPI Deep Neural Network Library),并且将oneDNN原有的线程池修改,统一成DeepRec的Eigen线程池,减少了线程池切换开销,避免了不同线程池之间竞争而导致的性能下降问题。oneDNN已经针对大量主流算子实现了性能优化,包括MatMul、BiasAdd、LeakyReLU等在稀疏场景中的常见算子,能够为搜广推模型提供强有力的性能支撑,并且oneDNN中的算子也支持BF16数据类型,与搭载BF16指令集的第三代英特尔® 至强® 可扩展处理器同时使用,可显著提升模型训练和推理性能。
在DeepRec编译选项中,只需加入 “--config=mkl_threadpool”,便可轻松开启oneDNN优化。
- 算子优化
oneDNN虽可用来大幅提升计算密集型算子的性能,但搜索广告推荐模型中存在着大量稀疏算子,如Select、DynamicStitch、Transpose、Tile、SparseSegmentMean等,这些算子的原生实现大部分存在一定的访存优化空间,对此可采用针对性方案实现额外优化。该优化调用AVX-512指令,只需在编译命令中加入 “--copt=-march=skylake-avx512”即可开启。以下为其中两个优化案例。
案例一:Select算子实现原理是依据条件来做元素的选择,此时可采用英特尔® AVX-512的mask load方式,如图二左图所示,以减少原先由if条件带来大量判断所导致的时间开销,然后再通过批量选择提升数据读写效率,最终线上测试表明,性能提升显著;

图二 Select算子优化案例
案例二:同样,可以使用英特尔® AVX-512的unpack和shuffle指令对transpose算子进行优化,即通过小Block的方式对矩阵进行转置,如图二右图所示,最终经线上测试表明,性能提升同样十分显著。
- 子图优化
图优化是当前AI性能优化的主要有效手段之一。同样的,当DeepRec应用在大规模稀疏场景下时,通常存在着以embedding特征为主的大量特征信息处理,并且embedding中包含了大量小型算子;为了实现通用的性能提升,优化措施在DeepRec中加入了fused_embedding_lookup功能,对embedding子图进行融合,减少了大量冗余操作,同时配合以英特尔® AVX-512指令加速计算,最终embedding子图性能提升显著。
通过在tf.feature_column.embedding_column(..., do_fusion=True) API将do_fusion设置为True,即可开启embedding子图优化功能。
- 模型优化
基于CPU平台,英特尔在DeepRec构建了涵盖WDL、DeepFM、DLRM、DIEN、DIN、DSSM、BST、MMoE、DBMTL、ESMM等多个主流模型的独有推荐模型集合,涉及召回、排序、多目标等多种常见的场景;并针对硬件平台进行性能优化,相较于其他框架,为这些模型基于Criteo等开源数据集在CPU平台上带来极大的性能提升。
其中表现最突出的当属混合精度的BF16和Float32的优化实现。通过在DeepRec中增加自定义控制DNN层数据类型的功能,来满足稀疏场景高性能和高精度的需求;开启优化的方式如图三所示,通过keep_weights保留当前variable的数据类型为Float32,用于防止梯度累加导致的精度下降,而后再采用两个cast操作将DNN操作转换成BF16进行运算,依托第三代英特尔® 至强® 可扩展处理器所具备的BF16硬件运算单元,极大地提升DNN运算性能,同时通过图融合cast操作进一步提升性能。

图三 混合精度优化开启方式
为了能够展示BF16对模型精度AUC(Area Under Curve)和性能Gsteps/s的影响,针对现有modelzoo的模型都应用以上混合精度优化方式。阿里巴巴PAI团队使用DeepRec在阿里云平台的评测表明[1],基于Criteo数据集,使用BF16优化后,模型WDL精度或AUC可以逼近FP32,并且BF16模型的训练性能提升达1.4倍,效果显著。
未来,为了更大程度地发挥CPU平台硬件优势,尤其是将新硬件特征的效果最大化, DeepRec将从不同角度进一步实施优化,包括优化器算子、attention子图、添加多目标模型等,以便为稀疏场景打造更高性能的CPU解决方案。
使用PMem实现Embedding存储
对于超大规模稀疏模型训练和预测引擎(千亿特征、万亿样本、模型10TB级别),若全部采用动态随机存取存储器(Dynamic Random Access Memory,DRAM)来存储,会大幅提升总拥有成本 (Total Cost of Ownership,TCO),同时给企业的 IT 运维和管理带来巨大压力,让 AI 解决方案的落地遭遇挑战。
PMem具有更高存储密度和数据持久化优势,I/O 性能接近 DRAM ,成本更为经济实惠,可充分满足超大规模稀疏训练和预测在高性能和大容量两方面的需求。
PMem支持两种操作模式,即内存模式(Memory Mode)和应用直接访问模式(App Direct Mode)。在内存模式中,它与普通的易失性(非持久性)系统存储器完全一样,但成本更低,能在保持系统预算的同时实现更高容量,并在单台服务器中提供 TB 级别的内存总容量;相比于内存模式,应用直接访问模式则可以利用PMem的持久化特性。在应用直接访问模式下,PMem和与其相邻的DRAM内存都会被识别为可按字节寻址的内存,操作系统可以将PMem硬件作为两种不同的设备来使用,一种是FSDAX模式,PMem被配置成块设备,用户可以将其格式化成一个文件系统来使用; 另一种是DEVDAX模式,PMem被驱动为单个字符设备,依赖内核(5.1以上)提供的KMEM DAX特性,把PMem作为易失性内存使用,接入内存管理系统,作为一个和DRAM类似的、较慢较大的内存NUMA节点,应用可透明访问。
在超大规模特征训练中, Embedding 变量存储占用 90%以上的内存,内存容量会成为其瓶颈之一。将EV 存到PMem 可以打破这一瓶颈,创造多项价值,例如提高大规模分布式训练的内存存储能力、支持更大模型的训练和预测、减少多台机器之间的通信、提升模型训练性能,同时降低 TCO。
在Embedding多级混合存储中,PMem同样是打破DRAM瓶颈的极佳选择。目前将EV存到PMem已具备三种方式,且在如下这三种方式下运行micro-benchmark、WDL 模型和WDL-proxy模型,性能非常接近于将EV存到DRAM,这无疑使得其TCO获得了很大优势:
- 将PMem配置成内存模式来保存EV;
- 将PMem配置成应用直接访问FSDAX模式,并采用基于Libpmem库的分配器来保存EV;
- 将PMem配置成NUMA节点并采用基于Memkind库的分配器来保存EV。
阿里巴巴PAI团队在阿里云内存增强型实例ecs.re7p.16xlarge上采用3种保存EV的方式进行了Modelzoo中的WDL单机模型对比测试[2],这3种方式分别是将EV存到DRAM,采用基于Libpmem库的分配器来保存EV和采用基于Memkind库的分配器来保存EV,测试结果表明将EV存到PMem与将EV存到DRAM的性能非常接近。

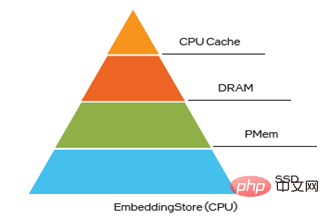
图四 Embedding多级混合存储
由此,下一步优化计划将采用PMem保存模型,把稀疏模型checkpoint文件存到持久内存中,来实现多个数量级的性能提升,摆脱目前用SSD保存恢复超大模型需要较长时间,且期间训练预测会中断的窘境。
FPGA加速Embedding Lookup
大规模稀疏训练及预测涵盖多种场景,例如分布式训练、单机和分布式预测以及异构计算训练等。它们与传统卷积神经网络(Convolutional Neural Network,CNN)或循环神经网络(Recurrent Neural Networks,RNN)相比有一个关键的不同,那就是 embedding table的处理,而这些场景中的Embedding table处理需求面临新的挑战:
- 巨大的存储容量要求(可达10TB或更多);
- 相对低的计算密度;
- 不规则的memory访问模式。
DeepRec通过PS-worker架构来支持超大规模任务场景。在PS-worker架构中,存储与计算分离,Embedding table以Key-Value的形式被存储在(几十、上百个)Parameter Servers中,这些PS为(几百、上千个)Worker提供存取、更新模型参数的服务,其关键的指标就是流通量和访问时延。而面对大规模稀疏模型训练和预测,现有框架中PS-worker的实现就显露了其瓶颈:
- 用软件通过多线程方式实现的KV engine成为了流通量的瓶颈;
- 基于TCP/RDMA实现的rpc带来的开销,使得Parameter Server在分布式扩展时成为明显的时延和性能瓶颈。
为了解决流通量瓶颈和时延的问题,优化中引入了支持CXL (Compute Express Link)的英特尔® AgilexTM I系列 FPGA,实施路径如图五所示:
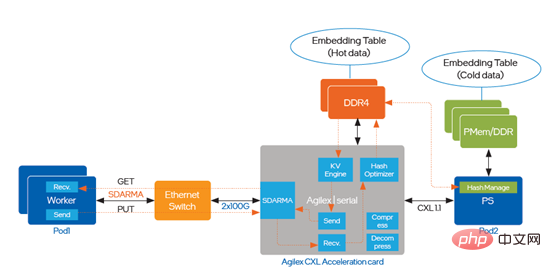
图五 引入英特尔®AgilexTM I系列 FPGA实施优化
- 通过FPGA实现硬件的KV engine可以饱和内存或网络带宽,解决流通量瓶颈问题;
- 通过自定义支持可靠传输的transport layer协议,在同一个FPGA中处理KV engine和网络协议,不经过主机CPU直接根据key处理value,以极低的时延和极小的抖动,消除Parameter Server在分布式扩展时的时延和性能瓶颈;
- 通过CXL提供的cache-coherent 连接支持HDM ( Host Managed Device Memory )访问,设备端(FPGA卡)上采用DDR4以支持热数据访问的高性能需求,主机端使用PMem支持冷数据的存储,极大化降低TCO;
- 以FPGA可以进一步实现embedding table的in-line处理,例如tensor 操作,或者实现压缩及解压缩在网络带宽限制方面的突破。
基于英特尔® AgilexTM I系列 FPGA的加速方案能在一个硬件平台支持上述所有场景,流通量显著提升,同时提供较低的访问时延。
总结
前文介绍了针对DeepRec在CPU、PMem和FPGA不同硬件的优化实现方案,并成功部署到阿里巴巴多个内部和外部业务场景,在实际业务中也获得了明显的端到端性能加速,从不同角度解决了超大规模稀疏场景面临的问题和挑战。众所周知,英特尔为AI应用提供了多样化的硬件选择,为客户选择更优性价比的AI方案提供了可能;与此同时,英特尔与阿里巴巴及广大客户正一同基于多样化硬件实施软硬一体的创新协作和优化,从而更充分地发挥英特尔技术和平台的价值。英特尔也期望继续和业界伙伴合作展开更深入地合作,持续为AI技术的部署落地贡献力量。
法律声明
英特尔并不控制或审计第三方数据。请您审查该内容,咨询其他来源,并确认提及数据是否准确。
性能测试结果基于2022年4月27日和2022年5月23日进行的测试,且可能并未反映所有公开可用的安全更新。详情请参阅配置信息披露。没有任何产品或组件是绝对安全的。
描述的成本降低情景均旨在在特定情况和配置中举例说明特定英特尔产品如何影响未来成本并提供成本节约。情况均不同。英特尔不保证任何成本或成本降低。
英特尔技术特性和优势取决于系统配置,并可能需要支持的硬件、软件或服务得以激活。产品性能会基于系统配置有所变化。没有任何产品或组件是绝对安全的。更多信息请从原始设备制造商或零售商处获得,或请见intel.com。
英特尔、英特尔标识以及其他英特尔商标是英特尔公司或其子公司在美国和/或其他国家的商标。
©英特尔公司版权所有
[1] 如欲了解更多性能测试详情,请访问https://github.com/alibaba/DeepRec/tree/main/modelzoo/WDL
[2] 如欲了解更多性能测试详情,请访问https://help.aliyun.com/document_detail/25378.html?spm=5176.2020520101.0.0.787c4df5FgibRE#re7p
以上是英特尔助力构建开源大规模稀疏模型训练 / 预测引擎 DeepRec的详细内容。更多信息请关注PHP中文网其他相关文章!