
OpenMLDB 研发负责人第四范式系统架构师卢冕:开源机器学习数据库OpenMLDB:线上线下一致的生产级特征平台

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2023-04-08 21:41:071017浏览

嘉宾:卢冕
整理:墨色
2022年8月6日-7日,AISummit 全球人工智能技术大会如期举办。在会上,OpenMLDB 研发负责人第四范式系统架构师卢冕带来了主题演讲《开源机器学习数据库OpenMLDB:线上线下一致的生产级特征平台》,从人工智能工程化落地的数据和特征挑战、OpenMLDB线上线下一致的生产级特征计算平台、OpenMLDB v0.5:性能、成本、易用性增强,三个方面进行了分享。
现将演讲内容整理如下,希望对各位有所启发。
人工智能工程化落地的数据和特征挑战
如今,据统计,在人工智能落地过程中有95%的时间都是花费在数据上。虽然市面上有诸如MySQL之类各种各样的数据工具,但它们远远没有解决人工智能落地的难题。因此,先来了解一下数据问题。
如果大家有参与过一些机器学习的应用开发,应该对MLOps印象深刻,如下图所示:
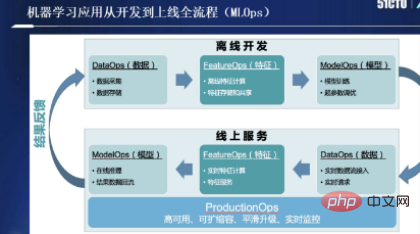
其实,当下对MLOps并没有严格的学术定义,整体上可将其分成离线开发和线上服务两个流程。每个流程中信息的载体,从数据、特征,到模型,会经历三种不同的载体,从离线开发流程一直走到线上服务流程。
接下来我们聚焦中间特征流程这一部分,了解到底是如何解决所面临的挑战的。
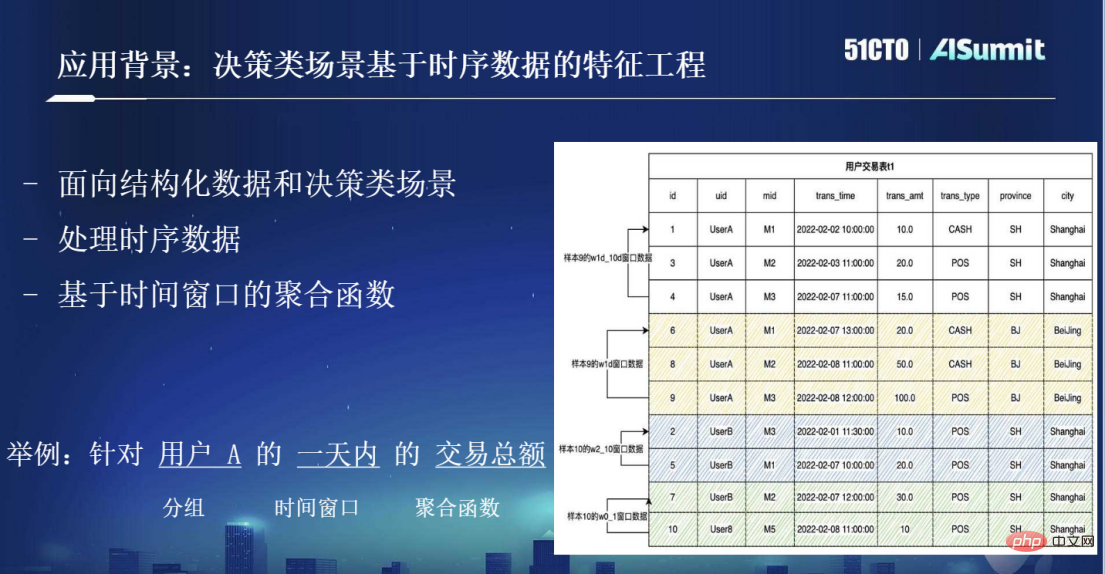
应用背景:决策类场景基于时序数据的特征工程
人工智能发展到现在主要有两种应用分类,一类是感知类,比如大家熟悉的人脸识别等都是感知类的AI应用,基本上会基于DNN算法进行。另一类是决策类的AI场景,比如淘宝购物的个性化推荐。此外还有一些像风控场景、反欺诈场景等都是AI在决策类中使用非常广泛的应用场景。
因此,我们现在讲的应用背景主要是针对这种决策类场景,最大的一个特点在于它的数据是一个二维表格的结构化数据,并且还是一个时序数据。如下图所示,用户交易表上有一个“trans_time”,代表了每一条记录所发生的时间点,连起来就是一个时序数据。基于时序数据的特征工程,最常见的一种处理方式就是基于时间窗口的聚合函数。例如针对用户一天内的交易总额等,这是决策类场景中特征工程常见的操作。
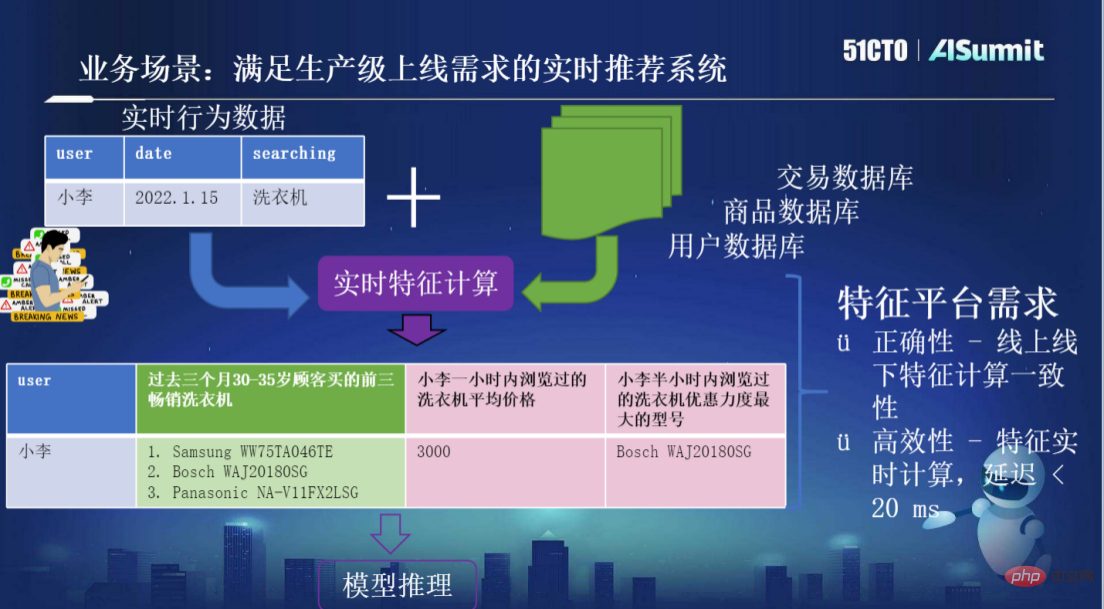
业务场景:满足生产级上线需求的实时推荐系统
当下,我们为什么要使用OpenMLDB?一个非常大的背景是要用真正的硬实时计算去满足AI需求。
什么是硬实时计算?它有两层含义,一层是指要用最新鲜的实时数据来达到最大的决策业务效果。比方要用过去10秒或1分钟内用户的点击行为来做决策业务,而不是过去一年或前年的数据。
另外很重要的一点是,做实时计算,用户一旦发出行为请求就需要在短时间内甚至是毫秒级去进行特征计算。
当前市面上有很多做批量计算/流式计算的产品,但还没有达到毫秒级的硬实时计算需求。
例如,如下图所示做一个满足生产级上线需求的实时推荐系统,用户小李做一个关键词为“洗衣机”的搜索,他需要在系统中把原始请求数据以及用户、商品、交易等信息数据合起来进行实时特征计算,然后产生一些更有意义的特征,即所谓的特征工程,产生特征的过程。比如系统会产生“过去三个月内某一年龄段顾客购买的前三畅销洗衣机”,这一类特征不需要强时效性,是基于较长历史数据进行计算的。但是,系统可能也会需要一些强时效性的数据,比如“过去一小时内/半小时内的浏览记录”等,系统得到新计算出来的特征后会给到模型进行推理。而这样的系统特征平台的需求主要有两个,一个是正确性,即线上线下特征计算一致性;另一个是高效性,即特征实时计算,延迟
特征计算开发到上线全生命周期
在没有OpenMLDB方法论之前,大家主要使用如下图所示的流程进行特征计算开发。
首先要做一个场景,数据科学家会使用Python/SparkSQL工具做离线特征抽取。数据科学家的KPI就是去做符合精度的业务需求模型,当模型质量达标后任务也就完成了。而特征脚本上线以后所面临的工程化挑战,如低延迟、高并发、高可用等并不是科学家的管辖范畴。
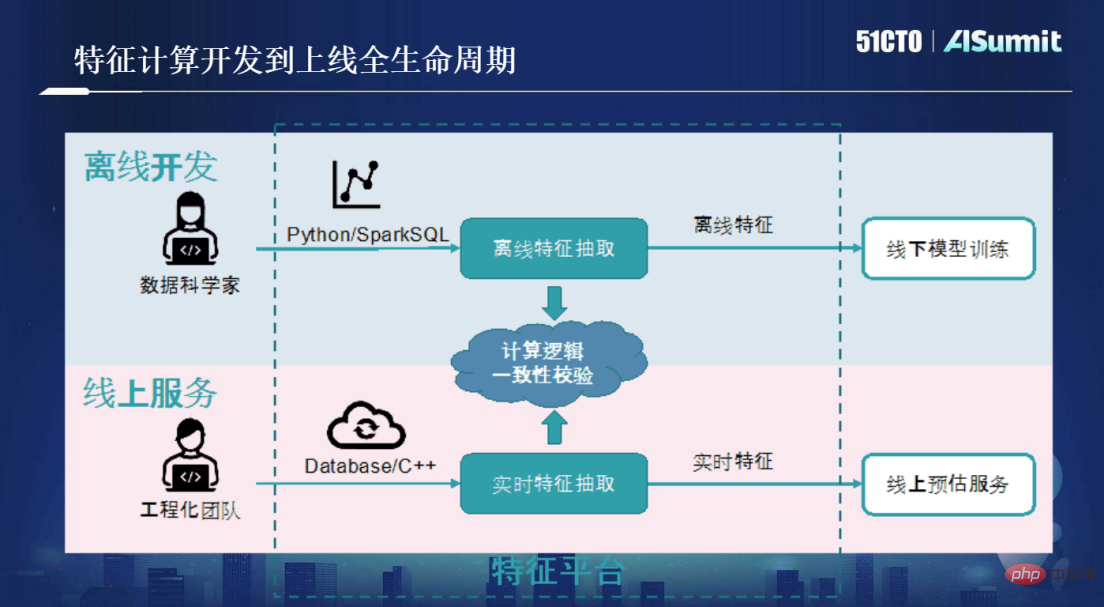
为了让数据科学家写的Python脚本上线,需要工程化团队介入,他们要做的就是把数据科学家所做的离线脚本进行重构、优化,使用C++/Database做实时特征抽取服务。这满足了低延迟、高并发、高可用的一系列工程化的需求,从而使特征脚本真正上线去做线上服务。
这一流程非常昂贵,需要两组技能团队的介入,而且他们所使用的工具不一样。两组流程走下来,还需要做计算逻辑的一致性校验,即数据科学家所开发的特征脚本的计算逻辑要与最后实时特征抽取上线的逻辑完全一致。这一需求看似明确、简单,但在一致性校验过程当中会引入大量的沟通成本、测试成本以及迭代开发成本。根据以往经验,项目越大则一致性校验需要的时间越长,成本非常大。
一般来说,在一致性校验过程中线上线下不一致的原因主要在于开发工具不一致,比如科学家用的是Python,工程化团队用的是数据库,工具能力有差异就可能会出现功能的妥协、不一致;还有就是对数据的定义、算法的定义,以及认知有差距等。
总而言之,基于传统两套流程的开发成本非常高昂,需要两组不同技能站的开发人员、两套系统的开发和运营,中间还要添加堆砌的校验、核对等。
而OpenMLDB提供了一个低成本开源解决方案。
OpenMLDB:线上线下一致的生产级特征计算平台
去年6月,OpenMLDB正式开源,是开源社区中的年轻项目,但已经在100多个场景中落地应用,覆盖超过300多个节点。
OpenMLDB是一个开源机器学习数据库,最主要功能是提供一个线上线下一致的特征平台。那么OpenMLDB是如何满足高性能和正确性的需求的?
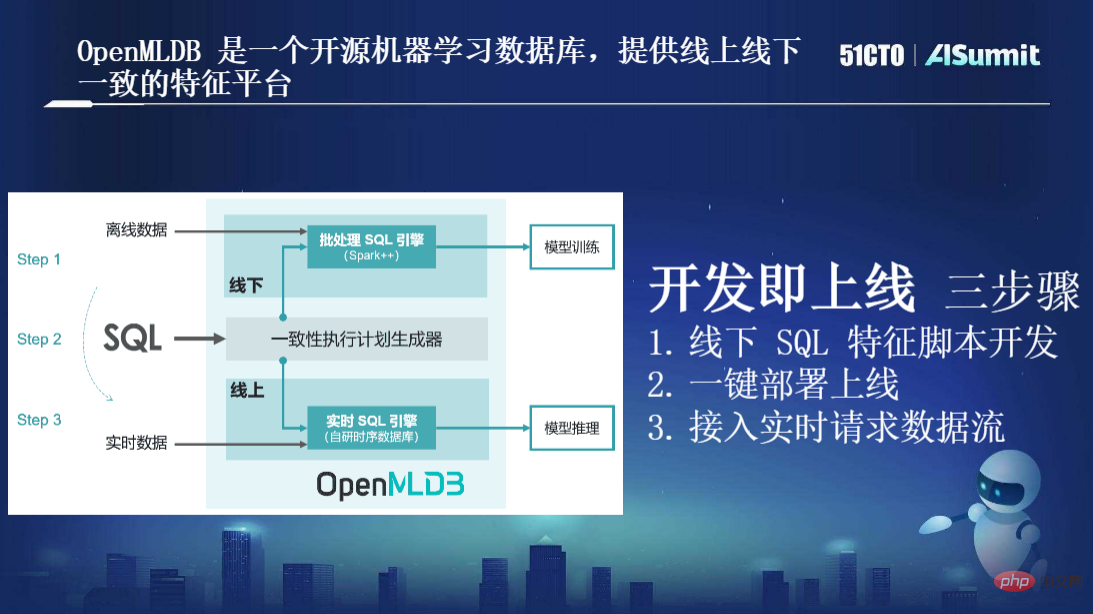
如上图所示,首先OpenMLDB使用的唯一编程语言就是SQL,不再有两套工具链,不管是数据科学家还是开发人员,都使用SQL表述特征。
其次,在OpenMLDB内部分出两套引擎,一套是“批处理SQL引擎”,基于Spark++进行源代码级别的优化,提供了更高性能的计算方式,并做了语法扩充;另外一套是“实时SQL引擎”,这一套是我们团队自研的资源时序数据库,默认是一个基于内存的存储引擎的时序数据库。基于“实时SQL引擎”,我们才可以达到线上高效的毫秒级实时计算,同时也保证高可用、低延迟、高并发。
在这两套引擎之间还有一个重要的“一致性执行计划生成器”,目的是保证线上线下执行计划逻辑的一致性。有了它可以天然保证线上线下一致性而不再需要人工进行校对。
总而言之,基于此架构,我们的最终目的是达成“开发即上线”的优化目标,主要包括三个步骤:线下SQL特征脚本开发;一键部署上线;接入实时请求数据流。
可以看出,相较于之前两套流程、两套工具链、两套开发人员的投入,这一套引擎最大的优势是节省了大量工程化成本,即只要数据科学家用SQL开发特征脚本,不再需要工程化团队做第二轮优化,便可直接上线,也不再需要中间的线上线下一致性校验的人工操作,省下了大量时间和成本。
下图展示了OpenMLDB从离线开发到线上服务的完整流程:
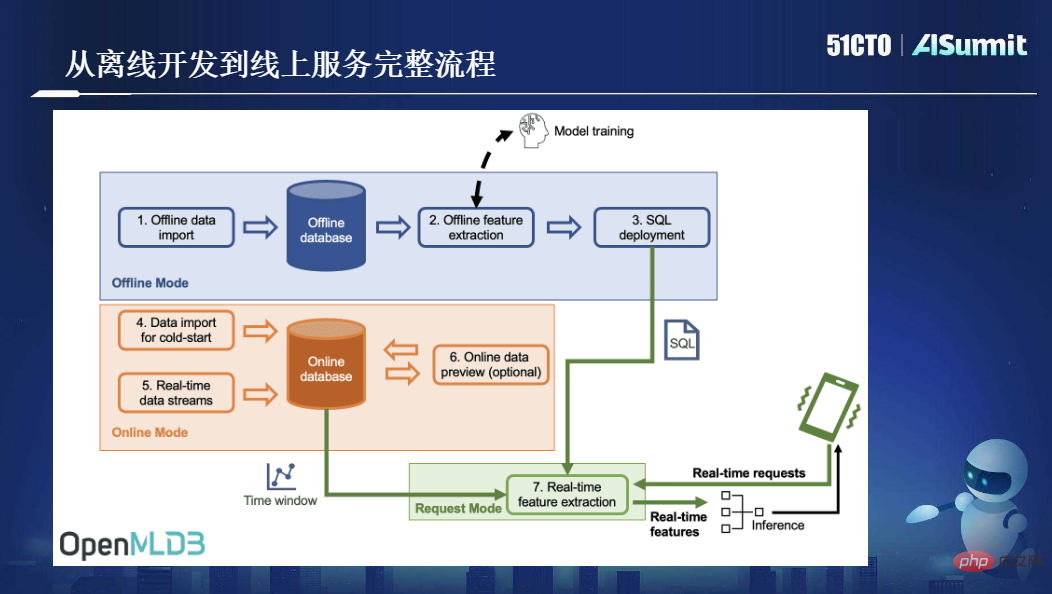
总体来看,OpenMLDB解决了一个核心问题——机器学习线上线下一致性;提供了一个核心特性——毫秒级实时特征计算。这两点是OpenMLDB所提供的最核心价值。
因为OpenMLDB有线上线下两套引擎,所以应用方式也不尽相同。下图展示了我们的推荐方式,可供参考:

接下来介绍一下OpenMLDB中的一些核心组件或特性:
特性一,线上线下一致性执行引擎,基于统一的底层计算函数,逻辑计划到物理计划的线上线下执行模式自适应调整,从而使得线上线下一致性得到天然保证。
特性二,高性能在线特征计算引擎,包括高性能双层跳表内存索引数据结构;实时计算+预聚合技术的混合优化策略;提供内存/磁盘两种存储引擎,满足不同性能和成本需求。
特性三,面向特征计算的优化的离线计算引擎,包括多窗口并行计算优化;数据倾斜计算优化;SQL语法扩展;针对特征计算优化的Spark发行版等。这些都使得在性能方面相较社区版大幅提升。
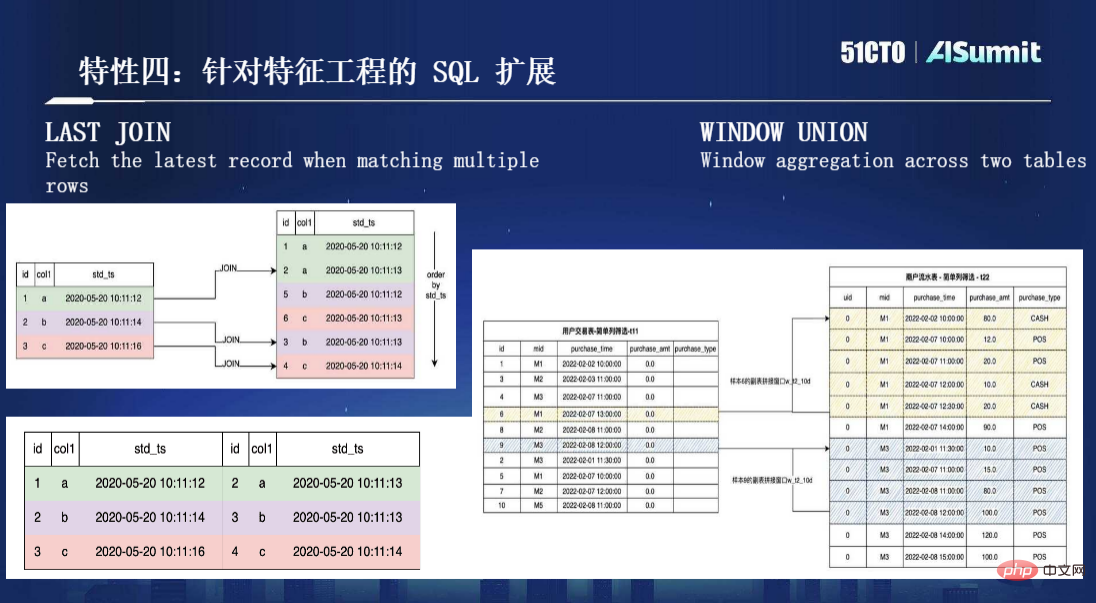
特性四,针对特征工程的SQL扩展。之前提到我们使用SQL做特征定义,但其实SQL并不是为特征计算设计的,所以在研究大量案例、累积使用经验以后,发现有必要对SQL语法做一些扩展,让它更好处理特征计算的场景。这里有两个比较重要的扩展,一个是LAST JOIN,另一个是比较常用的WINDOW UNION,具体如下图所示:
特性五,企业级特性支持。OpenMLDB作为一个分布式数据库,具有高可用、可无缝扩缩容、可平滑升级等特点,已经在很多企业案例中落地应用。
特性六,以SQL为核心的开发和管理,OpenMLDB还是一个数据库的管理,它与传统数据库较为相似,比如提供了CLI,那OpenMLDB就可以在整个CLI中实现整套流程,从离线特征计算、SQL方案上线到线上请求等,可以提供一个基于SQL和CLI的全流程开发体验。
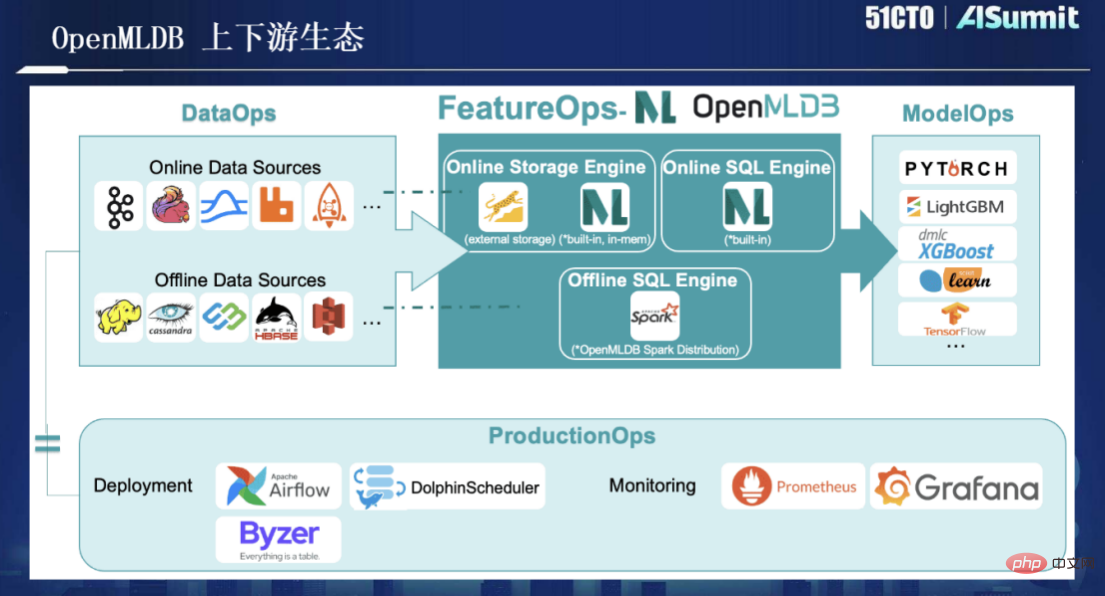
另外,OpenMLDB目前已经开源,关于其上下游生态的扩展,如下图所示:
OpenMLDB v0.5.0:性能、成本、易用性增强
接下来,介绍一下OpenMLDB v0.5的一个新版本,我们在三方面做了一些增强。
首先看一下OpenMLDB的发展历程。2021年6月,OpenMLDB开源,其实在这之前已经拥有了很多客户,并且从2017年就已经开始做第一行代码开发,技术的积累已有四五年的时间。
在开源后一周年里,我们迭代了大概五个版本。相较于以往版本,v0.5.0具有以下几个显著特点:
性能升级,聚合技术能够显著提升长窗口性能。预聚合优化使得在长窗口查询下,无论延迟还是吞吐,性能都提升了两个数量级。
成本降低,从v0.5.0版本开始,在线引擎提供基于内存和外存的两种引擎选择。基于内存,低延迟、高并发;较高使用成本提供毫秒级延迟响应。基于外存,对性能较不敏感;低成本使用落地基于SSD的典型配置下成本可下降75%。两种引擎上层业务代码无感知,零成本切换。
易用性增强。我们在v0.5.0版本中引入了用户自定义函数(UDF),这意味着如果SQL不能满足你的特征抽取逻辑表达,支持用户自定义函数,比如C/C++ UDF、UDF动态注册等,方便用户扩展计算逻辑,提升应用覆盖范围。
最后,感谢各位OpenMLDB开发者,从开源开始已经有接近100位贡献者在我们社区做过代码贡献,同时,我们也欢迎更多的开发者可以加入社区,贡献自己的力量,一起做更有意义的事情。
大会演讲回放及PPT已上线,进入官网查看精彩内容。
以上是OpenMLDB 研发负责人第四范式系统架构师卢冕:开源机器学习数据库OpenMLDB:线上线下一致的生产级特征平台的详细内容。更多信息请关注PHP中文网其他相关文章!