


本篇文章带大家详细了解MySQL表的CURD操作,希望对大家有所帮助!

一、SQL语句
操作关系型数据库的编程语言,定义了一套操作关系型数据库的统一标准,简称SQL。
- SQL通用语法
1 . SQL语句可以单行或多行书写,以分号结尾。
2 . SQL语句可以使用空格/缩进来增强语句的可读性。
3 . MySQL数据库的SQL语句不区分大小写,关键字建议使用大写。
- 注释
- 单行注释: – 注释内容 或者使用 # 注释内容 。
- 多行注释:/* 注释内容 */
- SQL语句分类
| 分类 | 说明 |
|---|---|
| DDL(deifnition) | 数据定义语言(用来定义数据库对象,数据库,表,字段) |
| DML(manipulation) | 数据操纵语言(对数据库 表中的是数据进行增删改) |
| DQL(query) | 数据查询语言,用来查询数据库中表的记录 |
| DCL(control) | 数据控制语言,用来创建数据库用户,控制数据库的访问权限 |
二、 基础表操作
- 创建表
同一个数据库中,不能有两个表的名字相同,表名和列名不能和SQL的关键词重复。
语法:
create table 表名(定义列1, 定义列2, .......); 列 -> 变量名 数据类型
- 举例:
mysql> create table if not exists book(
-> book_name varchar(32) comment '图书名称',
-> book_author varchar(32)comment '图书作者' ,
-> book_price decimal(12,2) comment '图书价格',
-> book_category varchar(12) comment '图书分类',
-> publish_data timestamp
-> )character set utf8mb4;
Query OK, 0 rows affected (0.04 sec)- 查看库中的表
-
语法:
show tables;
-
举例:
mysql> show tables; +--------------------+ | Tables_in_mytestdb | +--------------------+ | book | +--------------------+ 1 row in set (0.00 sec)
- 查看表结构
-
语法:
desc 表名;
举例:

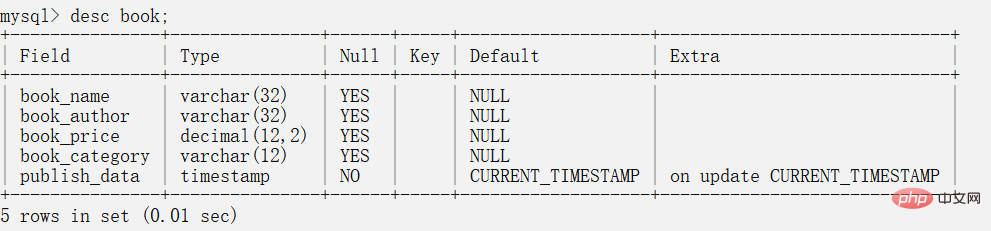
MySQL数据库中的表结构主要包含以下几种信息: 字段名称,字段类型,是否允许为空,索引类型。默认值,扩充信息
- 删除表
- 语法:
drop table 表名
- 举例 :
mysql> desc test1; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | name | varchar(10) | YES | | NULL | | | age | int(11) | YES | | NULL | | +-------+-------------+------+-----+---------+-------+ 2 rows in set (0.02 sec) mysql> drop table test1; Query OK, 0 rows affected (0.04 sec) mysql> desc test1; ERROR 1146 (42S02): Table 'mytestdb.test1' doesn't exist
- 重命名表
-
语法:
rename table old_name to new_name;
-
举例:
mysql> rename table book to eBook; Query OK, 0 rows affected (0.05 sec) mysql> show tables; +--------------------+ | Tables_in_mytestdb | +--------------------+ | ebook | +--------------------+ 1 row in set (0.00 sec)
三、MySQL 中的增删查改操作
CRUD 即增加(Create)、查询(Retrieve)、更新(Update)、删除(Delete)四个单词的首字母缩写
案例:
-- 创建一张图书表 mysql> create table if not exists book( -> book_name varchar(32) comment '图书名称', -> book_author varchar(32)comment '图书作者' , -> book_price decimal(12,2) comment '图书价格', -> book_category varchar(12) comment '图书分类', -> publish_data timestamp -> )character set utf8mb4;
- 增加(insert语句)
-
单行插入(全列)
insert into 表名 values(对应列的参数列表); -- 一次插入一行
-
多行插入(全列)
insert into 表名 values(对应列的实参列表), (对应列的参数列表), (对应列的参数列表); -- 一次插入多行 -- 一次插入多行
-
指定列插入
- values 后面( )中的内容, 个数和类型要和表名后面( )中指定的结构匹配.
- 未被指定的列会以默认值进行填充.
insert into 表名 (需要插入的列) values(对应列的参数列表); -- 一次插入一行 insert into 表名 (需要插入的列) values(对应列的参数列表), (), ().... -- 一次插入多行
-
案例
# 单行输入 mysql> insert into book values('计算机网络','谢希仁',45,'计算机类','2020-12-25 12:51:00'); Query OK, 1 row affected (0.01 sec) #多行输入 mysql> insert into book values('计算机组成原理','王峰',45,'硬件类','2020-12-12 12:00:00'), -> ('微机原理','李华',97,'硬件类','2000-12-19 20:00:00'); Query OK, 2 rows affected (0.04 sec) Records: 2 Duplicates: 0 Warnings: 0 #指定列插入 mysql> insert into book(book_name,book_author,publish_data) values ('软件工程','张三','2020-05-06 12:00:00'); Query OK, 1 row affected (0.02 sec) -
插入数据后的表如图所示:

在MySQL当中 , 多条记录逐次插入的效率是要低于一次把多条纪录一起插入的 ,原因如下:
- 网络请求和响应时间开销 , 每次插入都会有一定的时间开销.
- 数据库服务器是把数据保存在硬盘上的 , IO操作时,操作的次数带来的影响大于数据量.
- 每一次sql操作,内部开启的事务也会占据一定的开销.
- 查询(select语句)
- 全列查询
语法
select * from 表名 -- * 表示通配符, 可以匹配表中的所有列.
企业级别的数据库中慎用, 容易把I/O或者网络带宽吃满,如果有外边的用户客户端要通过宽带访问服务器时,服务器就无法做出正确的响应.
示例
select * from book;

- 指定列查询
select 列名... from 表名
- 示例
mysql> select book_name from book; +----------------+ | book_name | +----------------+ | 计算机网络 | | 计算机组成原理 | | 微机原理 | | 软件工程 | +----------------+ 4 rows in set (0.01 sec) mysql> select book_author,book_price from book; +-------------+------------+ | book_author | book_price | +-------------+------------+ | 谢希仁 | 45.00 | | 王峰 | 45.00 | | 李华 | 97.00 | | 张三 | NULL | +-------------+------------+ 4 rows in set (0.00 sec)
- 查询你字段为表达式
select 字段或表达式, 字段或表达式... from 表名;
- 示例
-- 查询图书涨价10元后所有图书的名称作者和价格 mysql> select book_name ,book_author,book_price + 10 from book; +----------------+-------------+-----------------+ | book_name | book_author | book_price + 10 | +----------------+-------------+-----------------+ | 计算机网络 | 谢希仁 | 55.00 | | 计算机组成原理 | 王峰 | 55.00 | | 微机原理 | 李华 | 107.00 | | 软件工程 | 张三 | NULL | +----------------+-------------+-----------------+ 4 rows in set (0.00 sec)
- 将表达式或者字段指定别名查询
mysql中支持给所查询的表达式取一个别名 , 使用 as 可以使查询结果更加直观 , 代码的可读性也会更强.
select 列名或表达式 as 别名, ... from 表名;
- 示例
-- 将涨价20元后的图书价格取为别名newprice mysql> select book_name,book_author,book_price + 20 as newprice from book; +----------------+-------------+----------+ | book_name | book_author | newprice | +----------------+-------------+----------+ | 计算机网络 | 谢希仁 | 65.00 | | 计算机组成原理 | 王峰 | 65.00 | | 微机原理 | 李华 | 117.00 | | 软件工程 | 张三 | NULL | +----------------+-------------+----------+ 4 rows in set (0.00 sec)
- 去重查询
select distinct 列名 from 表名
- 示例
--book 表中插入一条重复的book_name数据 mysql> insert into book values('计算机网络','张华',89,'计算机类','2020-11-23 11:00:00'); Query OK, 1 row affected (0.00 sec) mysql> select book_name from book; +----------------+ | book_name | +----------------+ | 计算机网络 | | 计算机组成原理 | | 微机原理 | | 软件工程 | | 计算机网络 | +----------------+ 5 rows in set (0.00 sec) mysql> select distinct book_name from book; +----------------+ | book_name | +----------------+ | 计算机网络 | | 计算机组成原理 | | 微机原理 | | 软件工程 | +----------------+ 4 rows in set (0.00 sec)
查询结果当中,没有了重复的book _ name 元素,达到了去重效果.
- 排序查询
select 列名 from 表名 order by 列名 asc(升序)/desc(降序); # 想要排序的列
- 示例
# 按照书的价格升序进行排列 mysql> select book_name,book_price from book order by book_price asc; +----------------+------------+ | book_name | book_price | +----------------+------------+ | 软件工程 | NULL | | 计算机网络 | 45.00 | | 计算机组成原理 | 45.00 | | 计算机网络 | 89.00 | | 微机原理 | 97.00 | +----------------+------------+ 5 rows in set (0.00 sec) #按照书的价格降序进行排列 mysql> select book_name,book_price from book order by book_price desc; +----------------+------------+ | book_name | book_price | +----------------+------------+ | 微机原理 | 97.00 | | 计算机网络 | 89.00 | | 计算机网络 | 45.00 | | 计算机组成原理 | 45.00 | | 软件工程 | NULL | +----------------+------------+ 5 rows in set (0.00 sec)
- 使用排序查询时 , 升序查询 asc 可以省略, 即默认为升序排列, null值一定为其中最小的.
- 可以对多个字段进行排序,优先级按照书写的顺序进行.
- 示例
# 查询按照价格升序 ,年份降序 select name,price,age from book order by price asc,age desc; #查询按照总成绩进行降序 select name,english+math+chinese as total from grade order by total desc;
- 条件查询
当我们使用查询时, 通常具有各种各样的前提条件 , 此时就需要使用条件查询来完成.
select 列名.. from 表名..where + 条件
比较运算符
| 运算符 | 说明 |
|---|---|
| >, >=, 22a72d2ffe40d3f003f38d41f5439d04 | 等于,null 安全,例如 null 96b4fef55684b9312718d5de63fb7121 null 的结果是 true(1) |
| !=, a8093152e673feb7aba1828c43532094 | 不等于 |
| between a0 and a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 true(1) |
| in (option, …) | 如果是 option 中的任意一个,返回 true(1) |
| is null | 是 null |
| is not null | 不是 null |
| like | 模糊匹配; % 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
逻辑运算符
| 运算符 | 说明 |
|---|---|
| and | 多个条件必须为 true , 结果才为true |
| or | 任意一个条件为true 结果才为true |
| not | 条件为true , 结果为false |
注:
WHERE条件可以使用表达式,但不能使用别名。
AND的优先级高于OR,在同时使用时,需要使用小括号()包裹优先执行的部分
- 案例
-- 查询图书价格低于50的图书作者和图书名称 mysql> select book_name,book_author from book where book_price < 50; +----------------+-------------+ | book_name | book_author | +----------------+-------------+ | 计算机网络 | 谢希仁 | | 计算机组成原理 | 王峰 | +----------------+-------------+ 2 rows in set (0.05 sec) -- 查询图书价格等于97的图书作者 mysql> select book_name ,book_author from book where book_price = 97; +-----------+-------------+ | book_name | book_author | +-----------+-------------+ | 微机原理 | 李华 | +-----------+-------------+ 1 row in set (0.00 sec) -- 查询图书价格在50 - 100 之间的图书名称 mysql> select book_name from book where book_price between 50 and 100; +------------+ | book_name | +------------+ | 微机原理 | | 计算机网络 | +------------+ 2 rows in set (0.02 sec)\ -- 查询图书价格在此范围内的图书名称 mysql> select book_name from book where book_price in (12,45); +----------------+ | book_name | +----------------+ | 计算机网络 | | 计算机组成原理 | +----------------+ 2 rows in set (0.00 sec)
模糊查询
- % 匹配任意多个(包括 0 个)字符
- _ 匹配严格的一个字符
#查询姓张的作者的书本价格书名. mysql> select book_price,book_name,book_author from book where book_author like '张%'; +------------+------------+-------------+ | book_price | book_name | book_author | +------------+------------+-------------+ | NULL | 软件工程 | 张三 | | 89.00 | 计算机网络 | 张华 | +------------+------------+-------------+ 2 rows in set (0.00 sec) # 查询前缀为'计算机'后缀为七个字的书籍名称 mysql> select book_name from book where book_name like '计算机____'; +----------------+ | book_name | +----------------+ | 计算机组成原理 | +----------------+ #查询前缀为'计算机'的书籍名称并去重 mysql> select distinct book_name from book where book_name like '计算机%'; +----------------+ | book_name | +----------------+ | 计算机网络 | | 计算机组成原理 | +----------------+ 2 rows in set (0.00 sec)
- 分页查询
分页查询即将查询出的结果 , 按页进行呈现,并不是一次性展现出来,这种模式就是分页查询, mysql当中使用limit来实现分页查询.
- limit 子句当中接受一个或者两个参数 , 这两个参数的值为0 或者正整数
两个参数的limit子句的用法
select 元素1,元素2 from 表名 limit offset,count; #offset参数指定要返回的第一行的偏移量。第一行的偏移量为0,而不是1。 #count指定要返回的最大行数。
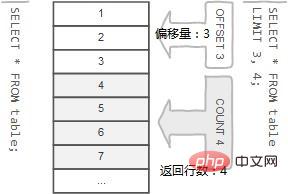
示例:
mysql> select book_author from book limit 2, 3; +-------------+ | book_author | +-------------+ | 李华 | | 张三 | | 张华 | +-------------+ 3 rows in set (0.02 sec) #表示获取列表当中偏移量为2(表示从第3行开始), 最大行数为3的作者名称
带有一个参数的limit子句的用法
select 列名1.列名2 from 表名 limit count; # 表示从结果集的开头返回的最大行数为count; # 获取前count行的记录
等同于
select 列名1 ,列名2 from 表名 limit 0 , count;# 第一行的偏移量为0
示例
mysql> select book_price from book limit 5; +------------+ | book_price | +------------+ | 45.00 | | 45.00 | | 97.00 | | NULL | | 89.00 | +------------+ 5 rows in set (0.00 sec) # 获取表中前五行的图书价格 , 最大行数为5
-
limit 结合 order by 语句 和其他条件可以获取n个最大或者最小值
select book_name,book_price from book order by book_price desc limit 3; #获取价格前三高的图书名称和图书价格 mysql> select book_price,book_name from book order by book_price desc limit 3; +------------+------------+ | book_price | book_name | +------------+------------+ | 97.00 | 微机原理 | | 89.00 | 计算机网络 | | 45.00 | 计算机网络 | +------------+------------+ 3 rows in set (0.01 sec)
使用limit 获取第n高个最大值
偏移量从
0开始,所以要指定从n - 1 开始,然后取一行记录
#示例:获取价格第二高的图书名称 mysql> select book_name from book order by book_price desc limit 1,1; +------------+ | book_name | +------------+ | 计算机网络 | +------------+ 1 row in set (0.00 sec)
- 修改(update)
MySQL当中使用update关键字来对数据进行修改 , 既可以修改单列又可以修改多列.
update 表名 set 列名1 = 值 , 列名2 = 值 ... where 限制条件下修改
SET子句指定要修改的列和新值。要更新多个列,请使用以逗号分隔的列表。以字面值,表达式或子查询的形式在每列的赋值中来提供要设置的值。- 第三,使用WHERE子句中的条件指定要更新的行。
WHERE子句是可选的。 如果省略WHERE子句,则UPDATE语句将更新表中的所有行。
示例:
#将书名为'软件工程'的图书价格修改为66元 mysql> update book set book_price = 66 where book_name = '软件工程'; Query OK, 1 row affected (0.05 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> select book_price from book where book_name = '软件工程'; +------------ | book_price | +------------+ | 66.00 | +------------+ 1 row in set (0.00 sec) #将所有的图书价格修改为原来的二倍 mysql> update book set book_price = 2 * book_price; Query OK, 5 rows affected (0.02 sec) Rows matched: 5 Changed: 5 Warnings: 0 #更新成功 mysql> select book_price from book; +------------+ | book_price | +------------+ | 90.00 | | 90.00 | | 194.00 | | 132.00 | | 178.00 | +------------+ 5 rows in set (0.00 sec)
- 删除(delete)
要从表中删除数据,需要使用delete 语句, delete 语句的 用法如下
delete from 表名 where + 条件
首先指定需要删除数据的表,其次使用条件指定where子句中删除的行记录, 如果行匹配条件,这些行记录将会删除.
WHERE子句是可选的。如果省略WHERE子句,DELETE语句将删除表中的所有行 , 请注意,一旦删除数据,它就会永远消失。因此,在执行DELETE语句之前,应该先备份数据库,以防万一要找回删除过的数据。
示例
#删除图书表中图书单价大于150的图书记录 mysql> delete from book where book_price > 150; Query OK, 2 rows affected (0.01 sec) mysql> select book_price from book; +------------+ | book_price | +------------+ | 90.00 | | 90.00 | | 132.00 | +------------+ 3 rows in set (0.00 sec)
MySQL中delete 语句也可以结合limit语句 和 order by 语句来控制删除的数量和条件
【相关推荐:mysql视频教程】
以上是一文详解MySQL表的CURD操作的详细内容。更多信息请关注PHP中文网其他相关文章!

 说明InnoDB重做日志和撤消日志的作用。Apr 15, 2025 am 12:16 AM
说明InnoDB重做日志和撤消日志的作用。Apr 15, 2025 am 12:16 AMInnoDB使用redologs和undologs确保数据一致性和可靠性。1.redologs记录数据页修改,确保崩溃恢复和事务持久性。2.undologs记录数据原始值,支持事务回滚和MVCC。
 在解释输出(类型,键,行,额外)中要查找的关键指标是什么?Apr 15, 2025 am 12:15 AM
在解释输出(类型,键,行,额外)中要查找的关键指标是什么?Apr 15, 2025 am 12:15 AMEXPLAIN命令的关键指标包括type、key、rows和Extra。1)type反映查询的访问类型,值越高效率越高,如const优于ALL。2)key显示使用的索引,NULL表示无索引。3)rows预估扫描行数,影响查询性能。4)Extra提供额外信息,如Usingfilesort提示需要优化。
 在解释中使用临时状态以及如何避免它是什么?Apr 15, 2025 am 12:14 AM
在解释中使用临时状态以及如何避免它是什么?Apr 15, 2025 am 12:14 AMUsingtemporary在MySQL查询中表示需要创建临时表,常见于使用DISTINCT、GROUPBY或非索引列的ORDERBY。可以通过优化索引和重写查询避免其出现,提升查询性能。具体来说,Usingtemporary出现在EXPLAIN输出中时,意味着MySQL需要创建临时表来处理查询。这通常发生在以下情况:1)使用DISTINCT或GROUPBY时进行去重或分组;2)ORDERBY包含非索引列时进行排序;3)使用复杂的子查询或联接操作。优化方法包括:1)为ORDERBY和GROUPB
 描述不同的SQL交易隔离级别(读取未读取,读取,可重复的读取,可序列化)及其在MySQL/InnoDB中的含义。Apr 15, 2025 am 12:11 AM
描述不同的SQL交易隔离级别(读取未读取,读取,可重复的读取,可序列化)及其在MySQL/InnoDB中的含义。Apr 15, 2025 am 12:11 AMMySQL/InnoDB支持四种事务隔离级别:ReadUncommitted、ReadCommitted、RepeatableRead和Serializable。1.ReadUncommitted允许读取未提交数据,可能导致脏读。2.ReadCommitted避免脏读,但可能发生不可重复读。3.RepeatableRead是默认级别,避免脏读和不可重复读,但可能发生幻读。4.Serializable避免所有并发问题,但降低并发性。选择合适的隔离级别需平衡数据一致性和性能需求。
 MySQL与其他数据库:比较选项Apr 15, 2025 am 12:08 AM
MySQL与其他数据库:比较选项Apr 15, 2025 am 12:08 AMMySQL适合Web应用和内容管理系统,因其开源、高性能和易用性而受欢迎。1)与PostgreSQL相比,MySQL在简单查询和高并发读操作上表现更好。2)相较Oracle,MySQL因开源和低成本更受中小企业青睐。3)对比MicrosoftSQLServer,MySQL更适合跨平台应用。4)与MongoDB不同,MySQL更适用于结构化数据和事务处理。
 MySQL索引基数如何影响查询性能?Apr 14, 2025 am 12:18 AM
MySQL索引基数如何影响查询性能?Apr 14, 2025 am 12:18 AMMySQL索引基数对查询性能有显着影响:1.高基数索引能更有效地缩小数据范围,提高查询效率;2.低基数索引可能导致全表扫描,降低查询性能;3.在联合索引中,应将高基数列放在前面以优化查询。
 MySQL:新用户的资源和教程Apr 14, 2025 am 12:16 AM
MySQL:新用户的资源和教程Apr 14, 2025 am 12:16 AMMySQL学习路径包括基础知识、核心概念、使用示例和优化技巧。1)了解表、行、列、SQL查询等基础概念。2)学习MySQL的定义、工作原理和优势。3)掌握基本CRUD操作和高级用法,如索引和存储过程。4)熟悉常见错误调试和性能优化建议,如合理使用索引和优化查询。通过这些步骤,你将全面掌握MySQL的使用和优化。
 现实世界Mysql:示例和用例Apr 14, 2025 am 12:15 AM
现实世界Mysql:示例和用例Apr 14, 2025 am 12:15 AMMySQL在现实世界的应用包括基础数据库设计和复杂查询优化。1)基本用法:用于存储和管理用户数据,如插入、查询、更新和删除用户信息。2)高级用法:处理复杂业务逻辑,如电子商务平台的订单和库存管理。3)性能优化:通过合理使用索引、分区表和查询缓存来提升性能。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

SublimeText3 Linux新版
SublimeText3 Linux最新版

Dreamweaver CS6
视觉化网页开发工具

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

