



线程和进程是计算机操作系统的基础概念,在程序员中属于高频词汇,那如何理解呢?Node.js 中的进程和线程又是怎样的呢?下面本篇文章就来带大家深入了解一下Node中的进程和线程。有一定的参考价值,有需要的朋友可以参考一下,希望对大家有所帮助。

一、进程和线程
1.1、专业性文字定义
- 进程(Process),进程是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础,进程是线程的容器。【相关教程推荐:nodejs视频教程、编程教学】
- 线程(Thread),线程是操作系统能够进行运算调度的最小单位,被包含在进程之中,是进程中的实际运作单位。
1.2、通俗理解
以上描述比较硬,看完可能也没看懂,还不利于理解记忆。那么我们举个简单的例子:
假设你是某个快递站点的一名小哥,起初这个站点负责的区域住户不多,收取件都是你一个人。给张三家送完件,再去李四家取件,事情得一件件做,这叫单线程,所有的工作都得按顺序执行。
后来这个区域住户多了,站点给这个区域分配了多个小哥,还有个小组长,你们可以为更多的住户服务了,这叫多线程,小组长是主线程,每个小哥都是一个线程。
快递站点使用的小推车等工具,是站点提供的,小哥们都可以使用,并不仅供某一个人,这叫多线程资源共享。
站点小推车目前只有一个,大家都需要使用,这叫冲突。解决的方法有很多,排队等待或者等其他小哥用完后的通知,这叫线程同步。
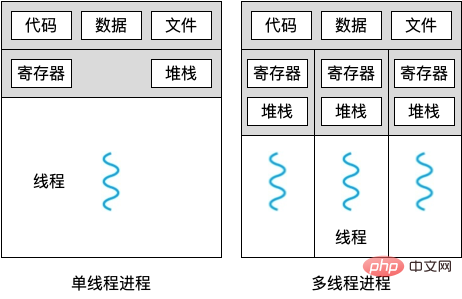
总公司有很多站点,各个站点的运营模式几乎一模一样,这叫多进程。总公司叫主进程,各个站点叫子进程。
总公司和站点之间,以及各个站点互相之间,小推车都是相互独立的,不能混用,这叫进程间不共享资源。各站点间可以通过电话等方式联系,这叫管道。各站点间还有其他协同手段,便于完成更大的计算任务,这叫进程间同步。
还可以看看阮一峰的 进程与线程的一个简单解释。
二、Node.js 中的进程和线程
Node.js 是单线程服务,事件驱动和非阻塞 I/O 模型的语言特性,使得 Node.js 高效和轻量。优势在于免去了频繁切换线程和资源冲突;擅长 I/O 密集型操作(底层模块 libuv 通过多线程调用操作系统提供的异步 I/O 能力进行多任务的执行),但是对于服务端的 Node.js,可能每秒有上百个请求需要处理,当面对 CPU 密集型请求时,因为是单线程模式,难免会造成阻塞。
2.1、Node.js 阻塞
我们利用 Koa 简单地搭建一个 Web 服务,用斐波那契数列方法来模拟一下 Node.js 处理 CPU 密集型的计算任务:
斐波那契数列,也称黄金分割数列,这个数列从第三项开始,每一项都等于前两项只和:0、1、1、2、3、5、8、13、21、......
// app.js
const Koa = require('koa')
const router = require('koa-router')()
const app = new Koa()
// 用来测试是否被阻塞
router.get('/test', (ctx) => {
ctx.body = {
pid: process.pid,
msg: 'Hello World'
}
})
router.get('/fibo', (ctx) => {
const { num = 38 } = ctx.query
const start = Date.now()
// 斐波那契数列
const fibo = (n) => {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1
}
fibo(num)
ctx.body = {
pid: process.pid,
duration: Date.now() - start
}
})
app.use(router.routes())
app.listen(9000, () => {
console.log('Server is running on 9000')
})
执行 node app.js 启动服务,用 Postman 发送请求,可以看到,计算 38 次耗费了 617ms,换而言之,因为执行了一个 CPU 密集型的计算任务,所以 Node.js 主线程被阻塞了六百多毫秒。如果同时处理更多的请求,或者计算任务更复杂,那么在这些请求之后的所有请求都会被延迟执行。

我们再新建一个 axios.js 用来模拟发送多次请求,此时将 app.js 中的 fibo 计算次数改为 43,用来模拟更复杂的计算任务:
// axios.js
const axios = require('axios')
const start = Date.now()
const fn = (url) => {
axios.get(`http://127.0.0.1:9000/${ url }`).then((res) => {
console.log(res.data, `耗时: ${ Date.now() - start }ms`)
})
}
fn('test')
fn('fibo?num=43')
fn('test')

可以看到,当请求需要执行 CPU 密集型的计算任务时,后续的请求都被阻塞等待,这类请求一多,服务基本就阻塞卡死了。对于这种不足,Node.js 一直在弥补。
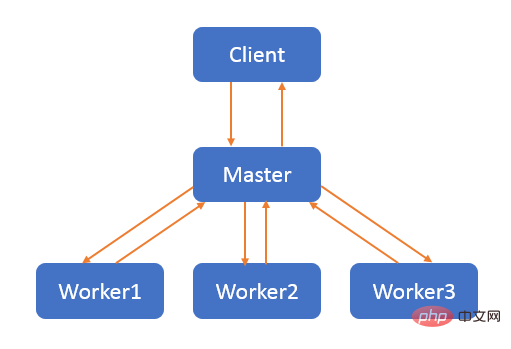
2.2、master-worker
master-worker 模式是一种并行模式,核心思想是:系统有两个及以上的进程或线程协同工作时,master 负责接收和分配并整合任务,worker 负责处理任务。
2.3、多线程
线程是 CPU 调度的一个基本单位,只能同时执行一个线程的任务,同一个线程也只能被一个 CPU 调用。如果使用的是多核 CPU,那么将无法充分利用 CPU 的性能。
多线程带给我们灵活的编程方式,但是需要学习更多的 Api 知识,在编写更多代码的同时也存在着更多的风险,线程的切换和锁也会增加系统资源的开销。
- worker_threads 工作线程,给 Node.js 提供了真正的多线程能力。
worker_threads 是 Node.js 提供的一种多线程 Api。对于执行 CPU 密集型的计算任务很有用,对 I/O 密集型的操作帮助不大,因为 Node.js 内置的异步 I/O 操作比 worker_threads 更高效。worker_threads 中的 Worker,parentPort 主要用于子线程和主线程的消息交互。
将 app.js 稍微改动下,将 CPU 密集型的计算任务交给子线程计算:
// app.js
const Koa = require('koa')
const router = require('koa-router')()
const { Worker } = require('worker_threads')
const app = new Koa()
// 用来测试是否被阻塞
router.get('/test', (ctx) => {
ctx.body = {
pid: process.pid,
msg: 'Hello World'
}
})
router.get('/fibo', async (ctx) => {
const { num = 38 } = ctx.query
ctx.body = await asyncFibo(num)
})
const asyncFibo = (num) => {
return new Promise((resolve, reject) => {
// 创建 worker 线程并传递数据
const worker = new Worker('./fibo.js', { workerData: { num } })
// 主线程监听子线程发送的消息
worker.on('message', resolve)
worker.on('error', reject)
worker.on('exit', (code) => {
if (code !== 0) reject(new Error(`Worker stopped with exit code ${code}`))
})
})
}
app.use(router.routes())
app.listen(9000, () => {
console.log('Server is running on 9000')
})
新增 fibo.js 文件,用来处理复杂计算任务:
const { workerData, parentPort } = require('worker_threads')
const { num } = workerData
const start = Date.now()
// 斐波那契数列
const fibo = (n) => {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1
}
fibo(num)
parentPort.postMessage({
pid: process.pid,
duration: Date.now() - start
})
执行上文的 axios.js,此时将 app.js 中的 fibo 计算次数改为 43,用来模拟更复杂的计算任务:

可以看到,将 CPU 密集型的计算任务交给子线程处理时,主线程不再被阻塞,只需等待子线程处理完成后,主线程接收子线程返回的结果即可,其他请求不再受影响。
上述代码是演示创建 worker 线程的过程和效果,实际开发中,请使用线程池来代替上述操作,因为频繁创建线程也会有资源的开销。
线程是 CPU 调度的一个基本单位,只能同时执行一个线程的任务,同一个线程也只能被一个 CPU 调用。
我们再回味下,本小节开头提到的线程和 CPU 的描述,此时由于是新的线程,可以在其他 CPU 核心上执行,可以更充分的利用多核 CPU。
2.4、多进程
Node.js 为了能充分利用 CPU 的多核能力,提供了 cluster 模块,cluster 可以通过一个父进程管理多个子进程的方式来实现集群的功能。
- child_process 子进程,衍生新的 Node.js 进程并使用建立的 IPC 通信通道调用指定的模块。
- cluster 集群,可以创建共享服务器端口的子进程,工作进程使用 child_process 的 fork 方法衍生。
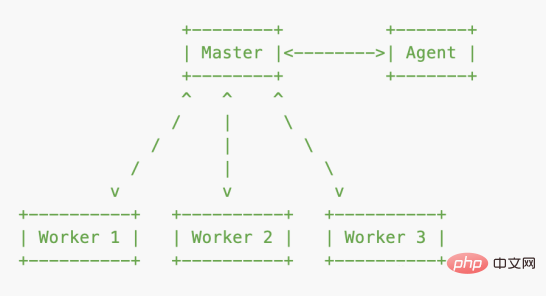
cluster 底层就是 child_process,master 进程做总控,启动 1 个 agent 进程和 n 个 worker 进程,agent 进程处理一些公共事务,比如日志等;worker 进程使用建立的 IPC(Inter-Process Communication)通信通道和 master 进程通信,和 master 进程共享服务端口。
新增 fibo-10.js,模拟发送 10 次请求:
// fibo-10.js
const axios = require('axios')
const url = `http://127.0.0.1:9000/fibo?num=38`
const start = Date.now()
for (let i = 0; i < 10; i++) {
axios.get(url).then((res) => {
console.log(res.data, `耗时: ${ Date.now() - start }ms`)
})
}
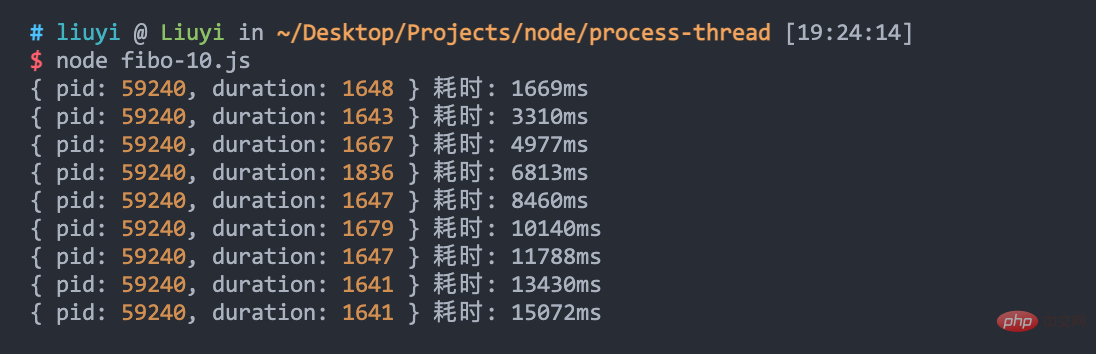
可以看到,只使用了一个进程,10 个请求慢慢阻塞,累计耗时 15 秒:
接下来,将 app.js 稍微改动下,引入 cluster 模块:
// app.js
const cluster = require('cluster')
const http = require('http')
const numCPUs = require('os').cpus().length
// const numCPUs = 10 // worker 进程的数量一般和 CPU 核心数相同
const Koa = require('koa')
const router = require('koa-router')()
const app = new Koa()
// 用来测试是否被阻塞
router.get('/test', (ctx) => {
ctx.body = {
pid: process.pid,
msg: 'Hello World'
}
})
router.get('/fibo', (ctx) => {
const { num = 38 } = ctx.query
const start = Date.now()
// 斐波那契数列
const fibo = (n) => {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1
}
fibo(num)
ctx.body = {
pid: process.pid,
duration: Date.now() - start
}
})
app.use(router.routes())
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`)
// 衍生 worker 进程
for (let i = 0; i < numCPUs; i++) {
cluster.fork()
}
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`)
})
} else {
app.listen(9000)
console.log(`Worker ${process.pid} started`)
}
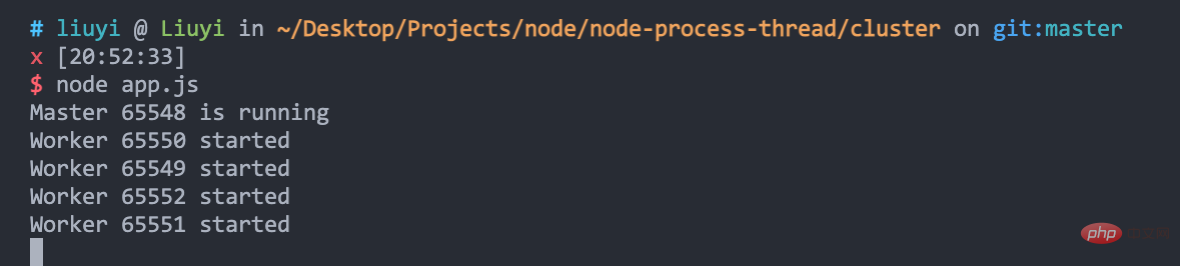
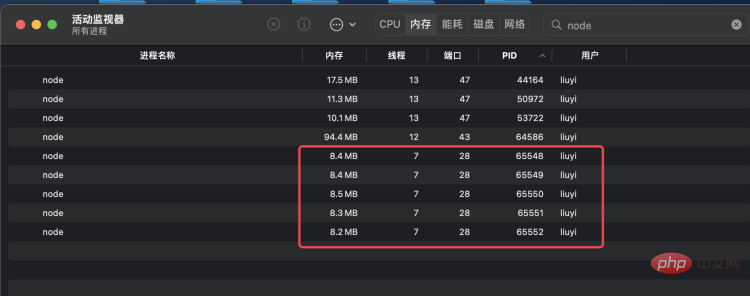
执行 node app.js 启动服务,可以看到,cluster 帮我们创建了 1 个 master 进程和 4 个 worker 进程:
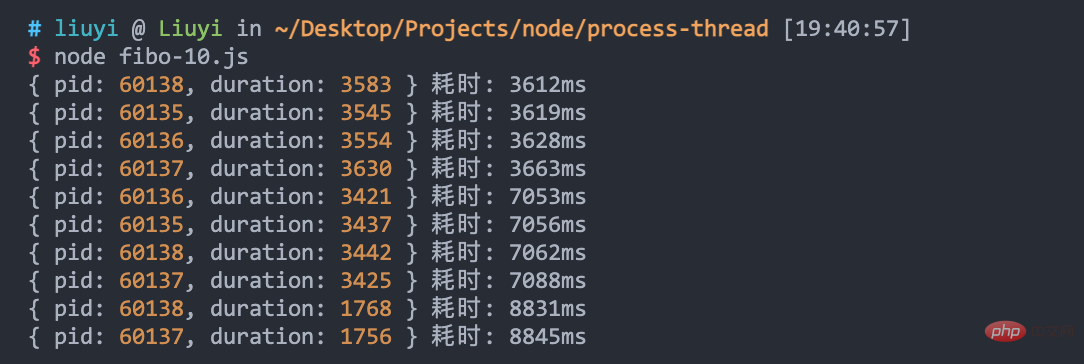
通过 fibo-10.js 模拟发送 10 次请求,可以看到,四个进程处理 10 个请求耗时近 9 秒:
当启动 10 个 worker 进程时,看看效果:
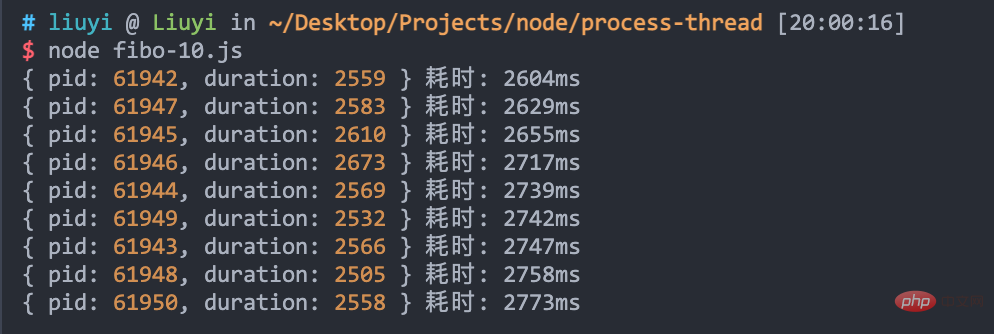
仅需不到 3 秒,不过进程的数量也不是无限的。在日常开发中,worker 进程的数量一般和 CPU 核心数相同。
2.5、多进程说明
开启多进程不全是为了处理高并发,而是为了解决 Node.js 对于多核 CPU 利用率不足的问题。
由父进程通过 fork 方法衍生出来的子进程拥有和父进程一样的资源,但是各自独立,互相之间资源不共享。通常根据 CPU 核心数来设置进程数量,因为系统资源是有限的。
三、总结
1、大部分通过多线程解决 CPU 密集型计算任务的方案都可以通过多进程方案来替代;
2、Node.js 虽然异步,但是不代表不会阻塞,CPU 密集型任务最好不要在主线程处理,保证主线程的畅通;
3、不要一味的追求高性能和高并发,达到系统需要即可,高效、敏捷才是项目需要的,这也是 Node.js 轻量的特点。
4、Node.js 中的进程和线程还有很多概念在文章中提到了但没展开细讲或没提到的,比如:Node.js 底层 I/O 的 libuv、IPC 通信通道、多进程如何守护、进程间资源不共享如何处理定时任务、agent 进程等;
5、以上代码可在 https://github.com/liuxy0551/node-process-thread 查看。
更多node相关知识,请访问:nodejs 教程!
以上是深入浅析Node中的进程和线程的详细内容。更多信息请关注PHP中文网其他相关文章!

 JavaScript是用C编写的吗?检查证据Apr 25, 2025 am 12:15 AM
JavaScript是用C编写的吗?检查证据Apr 25, 2025 am 12:15 AM是的,JavaScript的引擎核心是用C语言编写的。1)C语言提供了高效性能和底层控制,适合JavaScript引擎的开发。2)以V8引擎为例,其核心用C 编写,结合了C的效率和面向对象特性。3)JavaScript引擎的工作原理包括解析、编译和执行,C语言在这些过程中发挥关键作用。
 JavaScript的角色:使网络交互和动态Apr 24, 2025 am 12:12 AM
JavaScript的角色:使网络交互和动态Apr 24, 2025 am 12:12 AMJavaScript是现代网站的核心,因为它增强了网页的交互性和动态性。1)它允许在不刷新页面的情况下改变内容,2)通过DOMAPI操作网页,3)支持复杂的交互效果如动画和拖放,4)优化性能和最佳实践提高用户体验。
 C和JavaScript:连接解释Apr 23, 2025 am 12:07 AM
C和JavaScript:连接解释Apr 23, 2025 am 12:07 AMC 和JavaScript通过WebAssembly实现互操作性。1)C 代码编译成WebAssembly模块,引入到JavaScript环境中,增强计算能力。2)在游戏开发中,C 处理物理引擎和图形渲染,JavaScript负责游戏逻辑和用户界面。
 从网站到应用程序:JavaScript的不同应用Apr 22, 2025 am 12:02 AM
从网站到应用程序:JavaScript的不同应用Apr 22, 2025 am 12:02 AMJavaScript在网站、移动应用、桌面应用和服务器端编程中均有广泛应用。1)在网站开发中,JavaScript与HTML、CSS一起操作DOM,实现动态效果,并支持如jQuery、React等框架。2)通过ReactNative和Ionic,JavaScript用于开发跨平台移动应用。3)Electron框架使JavaScript能构建桌面应用。4)Node.js让JavaScript在服务器端运行,支持高并发请求。
 Python vs. JavaScript:比较用例和应用程序Apr 21, 2025 am 12:01 AM
Python vs. JavaScript:比较用例和应用程序Apr 21, 2025 am 12:01 AMPython更适合数据科学和自动化,JavaScript更适合前端和全栈开发。1.Python在数据科学和机器学习中表现出色,使用NumPy、Pandas等库进行数据处理和建模。2.Python在自动化和脚本编写方面简洁高效。3.JavaScript在前端开发中不可或缺,用于构建动态网页和单页面应用。4.JavaScript通过Node.js在后端开发中发挥作用,支持全栈开发。
 C/C在JavaScript口译员和编译器中的作用Apr 20, 2025 am 12:01 AM
C/C在JavaScript口译员和编译器中的作用Apr 20, 2025 am 12:01 AMC和C 在JavaScript引擎中扮演了至关重要的角色,主要用于实现解释器和JIT编译器。 1)C 用于解析JavaScript源码并生成抽象语法树。 2)C 负责生成和执行字节码。 3)C 实现JIT编译器,在运行时优化和编译热点代码,显着提高JavaScript的执行效率。
 JavaScript在行动中:现实世界中的示例和项目Apr 19, 2025 am 12:13 AM
JavaScript在行动中:现实世界中的示例和项目Apr 19, 2025 am 12:13 AMJavaScript在现实世界中的应用包括前端和后端开发。1)通过构建TODO列表应用展示前端应用,涉及DOM操作和事件处理。2)通过Node.js和Express构建RESTfulAPI展示后端应用。
 JavaScript和Web:核心功能和用例Apr 18, 2025 am 12:19 AM
JavaScript和Web:核心功能和用例Apr 18, 2025 am 12:19 AMJavaScript在Web开发中的主要用途包括客户端交互、表单验证和异步通信。1)通过DOM操作实现动态内容更新和用户交互;2)在用户提交数据前进行客户端验证,提高用户体验;3)通过AJAX技术实现与服务器的无刷新通信。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

SublimeText3汉化版
中文版,非常好用

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

WebStorm Mac版
好用的JavaScript开发工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

