



本篇文章给大家带来了关于Python的相关知识,其中主要介绍了关于pytorch模型保存与加载中的一些问题实战记录,下面一起来看一下,希望对大家有帮助。

【相关推荐:Python3视频教程 】
一、torch中模型保存和加载的方式
1、模型参数和模型结构保存和加载
torch.save(model,path) torch.load(path)
2、只保存模型的参数和加载——这种方式比较安全,但是比较稍微麻烦一点点
torch.save(model.state_dict(),path) model_state_dic = torch.load(path) model.load_state_dic(model_state_dic)
二、torch中模型保存和加载出现的问题
1、单卡模型下保存模型结构和参数后加载出现的问题
模型保存的时候会把模型结构定义文件路径记录下来,加载的时候就会根据路径解析它然后装载参数;当把模型定义文件路径修改以后,使用torch.load(path)就会报错。
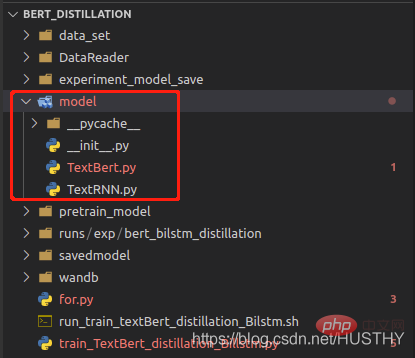
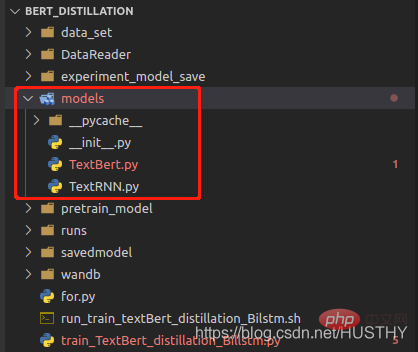

把model文件夹修改为models后,再加载就会报错。
import torch from model.TextRNN import TextRNN load_model = torch.load('experiment_model_save/textRNN.bin') print('load_model',load_model)
这种保存完整模型结构和参数的方式,一定不要改动模型定义文件路径。
2、多卡机器单卡训练模型保存后在单卡机器上加载会报错
在多卡机器上有多张显卡0号开始,现在模型在n>=1上的显卡训练保存后,拷贝在单卡机器上加载
import torch from model.TextRNN import TextRNN load_model = torch.load('experiment_model_save/textRNN_cuda_1.bin') print('load_model',load_model)
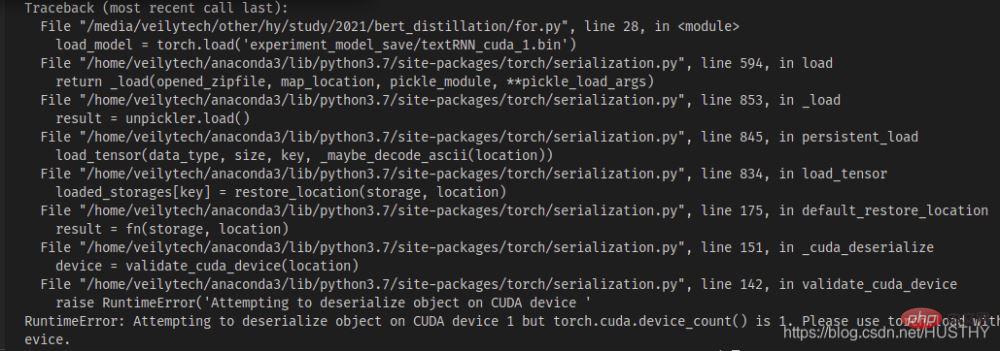
会出现cuda device不匹配的问题——你保存的模代码段 小部件型是使用的cuda1,那么采用torch.load()打开的时候,会默认的去寻找cuda1,然后把模型加载到该设备上。这个时候可以直接使用map_location来解决,把模型加载到CPU上即可。
load_model = torch.load('experiment_model_save/textRNN_cuda_1.bin',map_location=torch.device('cpu'))
3、多卡训练模型保存模型结构和参数后加载出现的问题
当用多GPU同时训练模型之后,不管是采用模型结构和参数一起保存还是单独保存模型参数,然后在单卡下加载都会出现问题
a、模型结构和参数一起保然后在加载

torch.distributed.init_process_group(backend='nccl')
模型训练的时候采用上述多进程的方式,所以你在加载的时候也要声明,不然就会报错。
b、单独保存模型参数
model = Transformer(num_encoder_layers=6,num_decoder_layers=6) state_dict = torch.load('train_model/clip/experiment.pt') model.load_state_dict(state_dict)
同样会出现问题,不过这里出现的问题是参数字典的key和模型定义的key不一样

原因是多GPU训练下,使用分布式训练的时候会给模型进行一个包装,代码如下:
model = torch.load('train_model/clip/Vtransformers_bert_6_layers_encoder_clip.bin') print(model) model.cuda(args.local_rank) 。。。。。。 model = nn.parallel.DistributedDataParallel(model,device_ids=[args.local_rank],find_unused_parameters=True) print('model',model)
包装前的模型结构:

包装后的模型
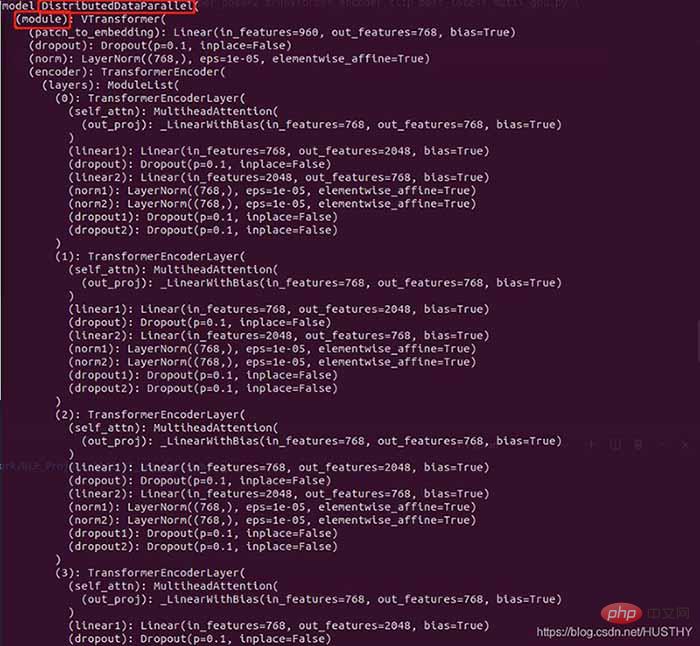
在外层多了DistributedDataParallel以及module,所以才会导致在单卡环境下加载模型权重的时候出现权重的keys不一致。
三、正确的保存模型和加载的方法
if gpu_count > 1:
torch.save(model.module.state_dict(),save_path)
else:
torch.save(model.state_dict(),save_path)
model = Transformer(num_encoder_layers=6,num_decoder_layers=6)
state_dict = torch.load(save_path)
model.load_state_dict(state_dict)这样就是比较好的范式,加载不会出错。
【相关推荐:Python3视频教程 】
以上是pytorch模型保存与加载中的一些问题实战记录的详细内容。更多信息请关注PHP中文网其他相关文章!

 Python中的合并列表:选择正确的方法May 14, 2025 am 12:11 AM
Python中的合并列表:选择正确的方法May 14, 2025 am 12:11 AMTomergelistsinpython,YouCanusethe操作员,estextMethod,ListComprehension,Oritertools
 如何在Python 3中加入两个列表?May 14, 2025 am 12:09 AM
如何在Python 3中加入两个列表?May 14, 2025 am 12:09 AM在Python3中,可以通过多种方法连接两个列表:1)使用 运算符,适用于小列表,但对大列表效率低;2)使用extend方法,适用于大列表,内存效率高,但会修改原列表;3)使用*运算符,适用于合并多个列表,不修改原列表;4)使用itertools.chain,适用于大数据集,内存效率高。
 Python串联列表字符串May 14, 2025 am 12:08 AM
Python串联列表字符串May 14, 2025 am 12:08 AM使用join()方法是Python中从列表连接字符串最有效的方法。1)使用join()方法高效且易读。2)循环使用 运算符对大列表效率低。3)列表推导式与join()结合适用于需要转换的场景。4)reduce()方法适用于其他类型归约,但对字符串连接效率低。完整句子结束。
 Python执行,那是什么?May 14, 2025 am 12:06 AM
Python执行,那是什么?May 14, 2025 am 12:06 AMpythonexecutionistheprocessoftransformingpypythoncodeintoExecutablestructions.1)InternterPreterReadSthecode,ConvertingTingitIntObyTecode,whepythonvirtualmachine(pvm)theglobalinterpreterpreterpreterpreterlock(gil)the thepythonvirtualmachine(pvm)
 Python:关键功能是什么May 14, 2025 am 12:02 AM
Python:关键功能是什么May 14, 2025 am 12:02 AMPython的关键特性包括:1.语法简洁易懂,适合初学者;2.动态类型系统,提高开发速度;3.丰富的标准库,支持多种任务;4.强大的社区和生态系统,提供广泛支持;5.解释性,适合脚本和快速原型开发;6.多范式支持,适用于各种编程风格。
 Python:编译器还是解释器?May 13, 2025 am 12:10 AM
Python:编译器还是解释器?May 13, 2025 am 12:10 AMPython是解释型语言,但也包含编译过程。1)Python代码先编译成字节码。2)字节码由Python虚拟机解释执行。3)这种混合机制使Python既灵活又高效,但执行速度不如完全编译型语言。
 python用于循环与循环时:何时使用哪个?May 13, 2025 am 12:07 AM
python用于循环与循环时:何时使用哪个?May 13, 2025 am 12:07 AMuseeAforloopWheniteratingOveraseQuenceOrforAspecificnumberoftimes; useAwhiLeLoopWhenconTinuingUntilAcIntiment.ForloopSareIdeAlforkNownsences,而WhileLeleLeleLeleLoopSituationSituationSituationsItuationSuationSituationswithUndEtermentersitations。
 Python循环:最常见的错误May 13, 2025 am 12:07 AM
Python循环:最常见的错误May 13, 2025 am 12:07 AMpythonloopscanleadtoerrorslikeinfiniteloops,modifyingListsDuringteritation,逐个偏置,零indexingissues,andnestedloopineflinefficiencies


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

SublimeText3汉化版
中文版,非常好用

Dreamweaver Mac版
视觉化网页开发工具

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

