



本篇文章给大家带来了关于java的相关知识,主要为大家详细介绍了如何基于Java实现一个复杂关系表达式过滤器。文中的示例代码讲解详细,下面一起来看一下,希望对大家有帮助。

推荐学习:《java视频教程》
背景
最近,有一个新需求,需要后台设置一个复杂的关系表达式,根据用户指定ID,解析该用用户是否满足该条件,后台设置类似于禅道的搜索条件

但是不同的是禅道有且仅有两个组,每个组最多三个条件
而我们这边组与关系可能是更复杂的,组中有组,每个条件都是有且或关系的。由于保密原因,原型就不发出来了。
看到这个需求,作为一个后端,第一时间想到的是类似QLEpress这类的表达式框架,只要构建一个表达式,通过解析表达式即可快速对目标用户进行筛选,但是可惜的是前端同学不干了,因为作为使用vue或react这类数据驱动的框架来说,将表达式转换为为上述的一个表单太难了 ,所以想了一下,决定自己定义一个数据结构,实现表达式解析。方便前端同学的处理。
分析准备
虽然是用类实现表达式,但是其本质上依旧还是个表达式,我们列举一个简单的表达式:设条件为a,b,c,d,我们随意构造一个表达式:
boolean result=a>100 && b=10 || (c != 3 && d 5a1b319c9256b5adbf09f78b85738671100 中的100)。
另外,还有关联关系(且、或)和计算优先级这几个属性组成。
于是我们对表达式进行简化:
令a>100 =>A,b=10 =>B,c!=3=>C ,dc849c18f1683bfc1ac5adfe2d1f542bdD,于是我们得到:
result=A && B || (C && D)
现在问题来了,如何处理优先级呢?
如上表达式,很明显,这是一个大学里学过的标准的中序表达式,于是,我们画一下它的树形图:
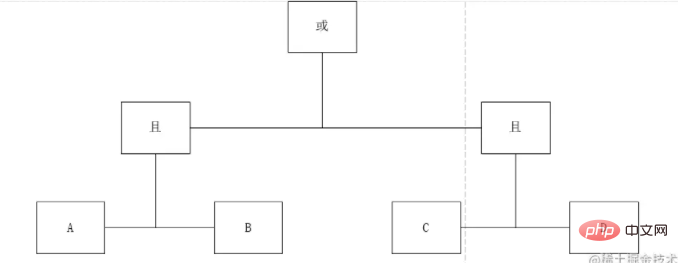
根据这个图,我们可以明显的看到,A且B 和C且D是同一级别,于是,我们按照这个理论设计一个层级的概念Deep,我们标注一下,然后再对节点的类型做一下区分,可得:
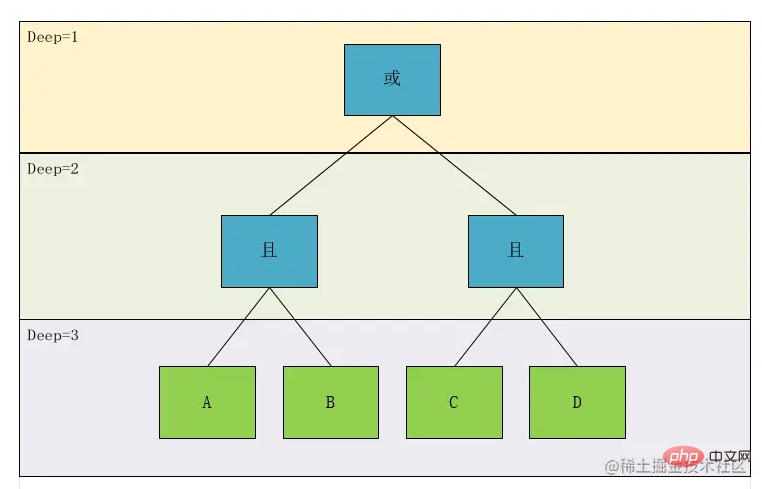
我们可以看到作为叶子节点(上图绿色部分),相对于其计算计算关系,遇到了一定是优先计算的,所以对于深度的优先级,我们仅需要考虑非叶子节点即可,即上图中的蓝色节点部分,于是我们得到了,计算优先级这个概念我们可以转换为表达式的深度。
我们再看上面这个图,Deep1 的关系是Deep2中 A且B 和 C且D两个表达式计算出的结果再进行与或关系的,我们设A 且B 为 G1, C且D为 G2,于是我们发现关系节点关联的类型有两种类型,一种是条件Condition ,一种是组Group
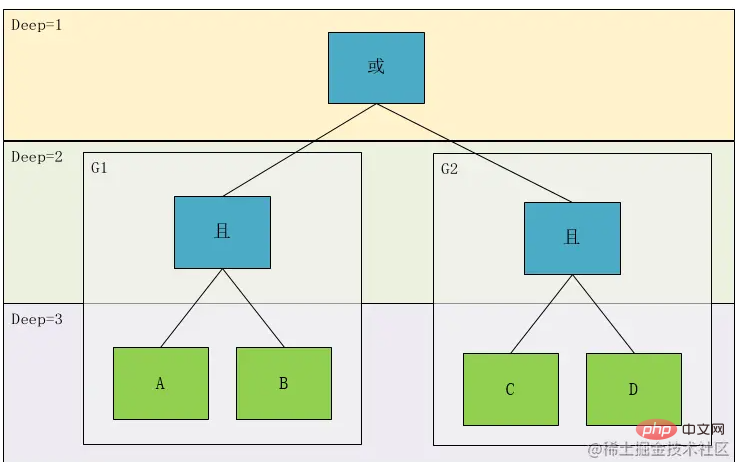
至此,这个类的雏形基本就确定了。这个类包含 关联关系(Relation)、判断字段(Field)、运算符(Operator)、运算值(Values)、类型(Type)、深度(Deep)
但是,有个问题,上面的分析中,我们在将表达式转换成树,现在我们试着将其还原,于是我们一眼可以得到其中一种表达式:
result=(A && B)||(C && D)
很显然,和我们的原来的表达式并不一致,这是因为我们上述仅能记录表达式的计算顺序,而不能完全准确的表示这个表达式,这是因为在我们解析表达式的过程中,不仅是有深度、还有一个时序关系,即从左到右的顺序表示,而此时G1中的内容实际上在原表达式中的深度应该是1而不是2,然后我们引入序号的概念,将原来树变成有向的图即:
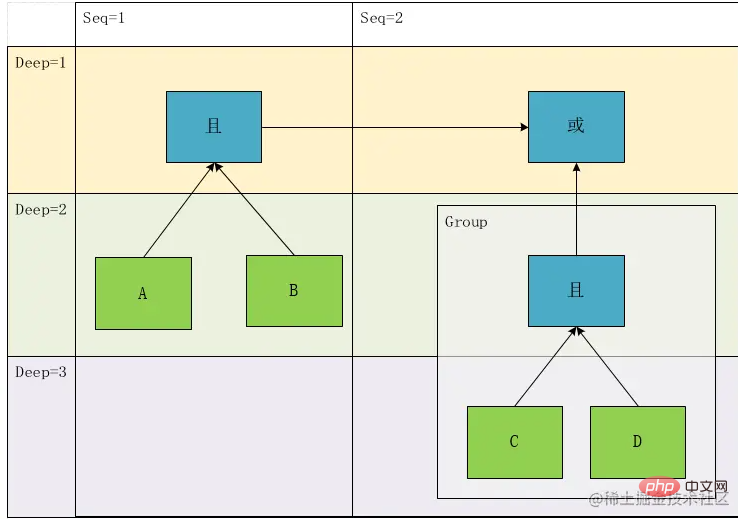
根据这个图,我们就还原出有且唯一的一个表达式了:result= A && B ||(C && D)。
好了,我们分析了半天,原理说完了,回到最初始的问题:前后端怎么实现?对着上图想象一下,貌似还是无法处理,因为这个结构还是太复杂了。对于前端,数据最好是方便遍历的,对于后端,数据最好是方便处理的,于是这时候我们需要将上面这个图转换成一个数组。
实现方式
上面说到了需要一个数组的结构,我们具体分析一下这个部分
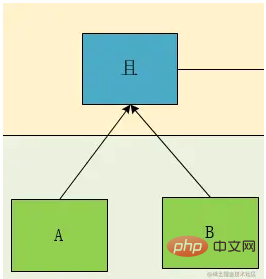
我们发现作为叶子节点,可以始终优先计算,所以我们可以将其压缩,并将关系放置在其中一个表达式中形成 ^A -> &&B或 A&& -> B$ 的形式,这里我用正则的开始(^) 和结束($) 表示了一下开始 和 结束 的概念,这里为了与产品原型保持一致我们用第一种方式,即关系符号表示与前一个元素的关系,于是我们再分析一下:
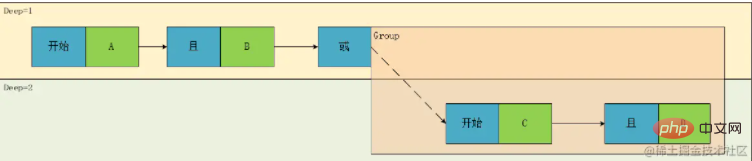
再对序号进行改造:
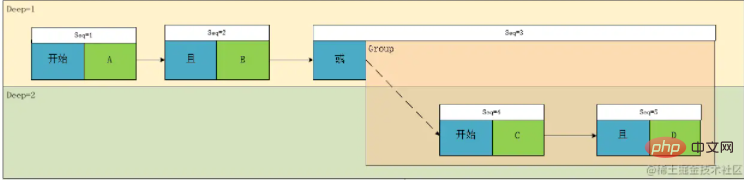
于是我们得到最终的数据结构:
@Data
@AllArgsConstructor
@NoArgsConstructor
@Accessors(chain = true)
public class ExpressDto {
/**
* 序号
*/
private Integer seq;
/**
* 深度(运算优先级)
*/
private Integer deep;
/**
* 关系运算符
*/
private String relation;
/**
* 类型
*/
private String type;
/**
* 运算条件
*/
private String field;
/**
* 逻辑运算符
*/
private String operator;
/**
* 运算值
*/
private String values;
/**
* 运算结果
*/
private Boolean result;
}现在数据结构终于完成,既方便存储,又(相对)方便前台展示,现在构造一个稍微复杂的表达式
A &&(( B || C )|| (D && E)) && F
换成数组对象,开始用BEGIN标识,表达式类型用CONDITION表示,组用GROUP表示。
[
{"seq":1,"deep":1,relation:"BEGIN","type":"CONDITION","field"="A"...},
{"seq":2,"deep":1,relation:"AND","type":"GROUP","field":""...},
{"seq":3,"deep":2,relation:"BEGIN","type":"GROUP","field":""...},
{"seq":4,"deep":3,relation:"BEGIN","type":"CONDITION","field":"B"...},
{"seq":5,"deep":3,relation:"OR","type":"CONDITION","field":"C"...},
{"seq":6,"deep":2,relation:"OR","type":"GROUP","field":""...},
{"seq":7,"deep":3,relation:"BEGIN","type":"CONDITION","field":"D"...},
{"seq":8,"deep":3,relation:"AND","type":"CONDITION","field":"E"...},
{"seq":9,"deep":1,relation:"AND","type":"CONDITION","field":"F"...}
]现在就剩最后一个问题:如何通过这个json对数据进行过滤了
由于数组对象的本质依旧是一个中缀表达式,所以其本质依旧是一个中缀表达式的解析,关于解析原理,这里不多介绍,简单的说就是通过数据栈和符号栈根据括号(在我们这里称为组)进行遍历,想了解更多,可以通过下面这篇文章复习一下
于是我们定义三个变量:
//关系 栈 Deque<String> relationStack=new LinkedList(); //结果栈 Deque<Boolean> resultStack=new LinkedList(); // 当前深度 Integer nowDeep=1;
通过遍历数组,将关系与结果入栈,当发现需要优先计算的时候,从结果栈中取出两个值,从关系栈中取出关系运算符,计算后再次入栈,等待下一次计算
for (ExpressDto expressDto:list) {
if(!StringUtils.equals(expressDto.getType(),"GROUP")){
//TODO 进行具体单个表达式计算并获取结果
resultStack.push(expressDto.getResult());
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
if(deep==0 && resultStack.size()>1){ //由于已处理小于0的deep,当前deep理论上是>=0的,0表示同等级,需要立即运算
relationOperator(relationStack, resultStack);
}
}else{
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
}
}
private void relationOperator(Deque<String> relationStack, Deque<Boolean> resultStack) {
Boolean lastResult= resultStack.pop();
Boolean firstResult= resultStack.pop();
String relation=relationStack.pop();
if(StringUtils.equals(relation,"AND")){
resultStack.push(firstResult&& lastResult) ;
return;
}
if(StringUtils.equals(relation,"OR")){
resultStack.push( firstResult|| lastResult);
return;
}else{
throw new RuntimeException("表达式解析异常:关系表达式错误");
}
}再说一下注意的边界事项:
1.首先我们同级中关联关系仅存在且、或两种,而这两种的计算优先级是一样的。故同一个Deep下,从左到右依次遍历计算即可。
2.当遇到GROUP的类型时,相当于遇到了"(",我们可以发现它后面的元素Deep +1 直到Deep -1为止")"结束,而括号中的元素需要优先计算,也就是说"()"所产生优先级通过Deep 和Type=GROUP 共同控制
3.当Deep减少时,意味着遇到了")",此时结束的Group的数量等于Deep减少的数量,针对")"结束,每遇到一个")" 都需要对该级括号进行检查,是否同级别的元素是否已经计算完毕。
/**
* 处理层级遗留元素
*
* @param relationStack
* @param resultStack
*/
private void computeBeforeEndGroup(Deque<String> relationStack, Deque<Boolean> resultStack) {
boolean isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");//防止group中仅有一个判断条件
while(!isBeginSymbol){//上一个运算符非BEGIN,说明该group中还有运算需要优先处理,正常这里应该仅循环一次
relationOperator(relationStack, resultStack);
isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");
}
if(isBeginSymbol){
relationStack.pop();//该优先级处理完毕,将BEGIN运算符弹出
}
}4.当遍历结束发现最后一个元素Deep不等于1时,意味着有括号结束,这时,同样需要进行括号结束处理
最后上完整代码:
/**
* 表达式解析器
* 表达式规则:
* 关系relation属性有:BEGIN、AND、OR 三种
* 表达式类型 Type 属性有:GROUP、CONDITION 两种
* 深度 deep 属性 根节点为 1,每增加一个括号(GROUP)deep+1,括号结束deep-1
* 序号req:初始值为1,往后依次递增,用于防止表达式解析顺序错误
* exp1:表达式:A &&(( B || C )|| (D && E)) && F
* 分解对象:
* [
* {"seq":1,"deep":1,relation:"BEGIN","type":"CONDITION","field"="A"...},
* {"seq":2,"deep":1,relation:"AND","type":"GROUP","field":""...},
* {"seq":3,"deep":2,relation:"BEGIN","type":"GROUP","field":""...},
* {"seq":4,"deep":3,relation:"BEGIN","type":"CONDITION","field":"B"...},
* {"seq":5,"deep":3,relation:"OR","type":"CONDITION","field":"C"...},
* {"seq":6,"deep":2,relation:"OR","type":"GROUP","field":""...},
* {"seq":7,"deep":3,relation:"BEGIN","type":"CONDITION","field":"D"...},
* {"seq":8,"deep":3,relation:"AND","type":"CONDITION","field":"E"...},
* {"seq":9,"deep":1,relation:"AND","type":"CONDITION","field":"F"...}
* ]
*
* exp2:(A || B && C)||(D && E && F)
* [
* {"seq":1,"deep":1,relation:"BEGIN","type":"GROUP","field":""...},
* {"seq":2,"deep":2,relation:"BEGIN","type":"CONDITION","field":"A"...},
* {"seq":3,"deep":2,relation:"OR","type":"CONDITION","field":"B"...},
* {"seq":4,"deep":2,relation:"AND","type":"CONDITION","field":"C"...},
* {"seq":5,"deep":1,relation:"OR","type":"GROUP","field":""...},
* {"seq":6,"deep":2,relation:"BEGIN","type":"CONDITION","field":"D"...},
* {"seq":7,"deep":2,relation:"AND","type":"CONDITION","field":"E"...},
* {"seq":8,"deep":2,relation:"AND","type":"CONDITION","field":"F"...}
* ]
*
*
* @param list
* @return
*/
public boolean expressProcessor(Listlist){
//关系 栈
Deque relationStack=new LinkedList();
//结果栈
Deque resultStack=new LinkedList();
// 当前深度
Integer nowDeep=1;
Integer seq=0;
for (ExpressDto expressDto:list) {
// 顺序检测,防止顺序错误
int checkReq=expressDto.getSeq()-seq;
if(checkReq!=1){
throw new RuntimeException("表达式异常:解析顺序异常");
}
seq=expressDto.getSeq();
//计算深度(计算优先级),判断当前逻辑是否需要处理括号
int deep=expressDto.getDeep()-nowDeep;
// 赋予当前深度
nowDeep=expressDto.getDeep();
//deep 减小,说明有括号结束,需要处理括号到对应的层级,deep减少数量等于组(")")结束的数量
while(deep++ < 0){
computeBeforeEndGroup(relationStack, resultStack);
}
if(!StringUtils.equals(expressDto.getType(),"GROUP")){
//TODO 进行具体单个表达式计算并获取结果
resultStack.push(expressDto.getResult());
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
if(deep==0 && resultStack.size()>1){ //由于已处理小于0的deep,当前deep理论上是>=0的,0表示同等级,需要立即运算
relationOperator(relationStack, resultStack);
}
}else{
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
}
}
//遍历完毕,处理栈中未进行运算的节点
while(nowDeep-- > 0){ // 这里使用 nowdeep>0 的原因是最后deep=1的关系表达式也需要进行处理
computeBeforeEndGroup(relationStack, resultStack);
}
if(resultStack.size()!=1){
throw new RuntimeException("表达式解析异常:解析结果数量异常解析数量:"+resultStack.size());
}
return resultStack.pop();
}
/**
* 处理层级遗留元素
*
* @param relationStack
* @param resultStack
*/
private void computeBeforeEndGroup(Deque<String> relationStack, Deque<Boolean> resultStack) {
boolean isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");//防止group中仅有一个判断条件
while(!isBeginSymbol){//上一个运算符非BEGIN,说明该group中还有运算需要优先处理,正常这里应该仅循环一次
relationOperator(relationStack, resultStack);
isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");
}
if(isBeginSymbol){
relationStack.pop();//该优先级处理完毕,将BEGIN运算符弹出
}
}
/**
* 关系运算处理
* @param relationStack
* @param resultStack
*/
private void relationOperator(Deque relationStack, Deque resultStack) {
Boolean lastResult= resultStack.pop();
Boolean firstResult= resultStack.pop();
String relation=relationStack.pop();
if(StringUtils.equals(relation,"AND")){
resultStack.push(firstResult&& lastResult) ;
return;
}
if(StringUtils.equals(relation,"OR")){
resultStack.push( firstResult|| lastResult);
return;
}else{
throw new RuntimeException("表达式解析异常:关系表达式错误");
}
} 简单写了几个测试用例:
/**
* 表达式:A
*/
@Test
public void expTest0(){
ExpressDto E1=new ExpressDto().setDeep(1).setResult(false).setSeq(1).setType("CONDITION").setField("A").setRelation("BEGIN");
List<ExpressDto> list = new ArrayList();
list.add(E1);
boolean re=expressProcessor(list);
Assertions.assertFalse(re);
}
/**
* 表达式:(A && B)||(C || D)
*/
@Test
public void expTest1(){
ExpressDto E1=new ExpressDto().setDeep(1).setSeq(1).setType("GROUP").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(2).setResult(true).setSeq(2).setType("Condition").setField("A").setRelation("BEGIN");
ExpressDto E3=new ExpressDto().setDeep(2).setResult(false).setSeq(3).setType("Condition").setField("B").setRelation("AND");
ExpressDto E4=new ExpressDto().setDeep(1).setSeq(4).setType("GROUP").setRelation("OR");
ExpressDto E5=new ExpressDto().setDeep(2).setResult(true).setSeq(5).setType("Condition").setField("C").setRelation("BEGIN");
ExpressDto E6=new ExpressDto().setDeep(2).setResult(false).setSeq(6).setType("Condition").setField("D").setRelation("OR");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
list.add(E6);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
}
/**
* 表达式:A && (B || C && D)
*/
@Test
public void expTest2(){
ExpressDto E1=new ExpressDto().setDeep(1).setResult(true).setSeq(1).setType("Condition").setField("A").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(1).setSeq(2).setType("GROUP").setRelation("AND");
ExpressDto E3=new ExpressDto().setDeep(2).setResult(false).setSeq(3).setType("Condition").setField("B").setRelation("BEGIN");
ExpressDto E4=new ExpressDto().setDeep(2).setResult(false).setSeq(4).setType("Condition").setField("C").setRelation("OR");
ExpressDto E5=new ExpressDto().setDeep(2).setResult(true).setSeq(5).setType("Condition").setField("D").setRelation("AND");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
boolean re=expressProcessor(list);
Assertions.assertFalse(re);
E4.setResult(true);
list.set(3,E4);
re=expressProcessor(list);
Assertions.assertTrue(re);
E1.setResult(false);
list.set(0,E1);
re=expressProcessor(list);
Assertions.assertFalse(re);
}
@Test
public void expTest3(){
ExpressDto E1=new ExpressDto().setDeep(1).setResult(true).setSeq(1).setType("Condition").setField("A").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(1).setSeq(2).setType("GROUP").setRelation("OR");
ExpressDto E3=new ExpressDto().setDeep(2).setResult(true).setSeq(3).setType("Condition").setField("B").setRelation("BEGIN");
ExpressDto E4=new ExpressDto().setDeep(2).setSeq(4).setType("GROUP").setRelation("AND");
ExpressDto E5=new ExpressDto().setDeep(3).setResult(true).setSeq(5).setType("Condition").setField("C").setRelation("BEGIN");
ExpressDto E6=new ExpressDto().setDeep(3).setResult(false).setSeq(6).setType("Condition").setField("D").setRelation("OR");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
list.add(E6);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
}
/**
* 表达式:A &&(( B || C )|| (D && E))
*/
@Test
public void expTest4(){
ExpressDto E1=new ExpressDto().setDeep(1).setSeq(1).setType("CONDITION").setResult(true).setField("A").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(1).setSeq(2).setType("GROUP").setRelation("AND");
ExpressDto E3=new ExpressDto().setDeep(2).setSeq(3).setType("GROUP").setRelation("BEGIN");
ExpressDto E4=new ExpressDto().setDeep(3).setSeq(4).setType("CONDITION").setResult(true).setField("B").setRelation("BEGIN");
ExpressDto E5=new ExpressDto().setDeep(3).setSeq(5).setType("CONDITION").setResult(true).setField("C").setRelation("OR");
ExpressDto E6=new ExpressDto().setDeep(2).setSeq(6).setType("GROUP").setRelation("OR");
ExpressDto E7=new ExpressDto().setDeep(3).setSeq(7).setType("CONDITION").setResult(false).setField("D").setRelation("BEGIN");
ExpressDto E8=new ExpressDto().setDeep(3).setSeq(8).setType("CONDITION").setResult(false).setField("E").setRelation("AND");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
list.add(E6);
list.add(E7);
list.add(E8);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
}
/**
* 表达式:(A)
*/
@Test
public void expTest5(){
ExpressDto E1=new ExpressDto().setDeep(1).setSeq(1).setType("GROUP").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(2).setResult(true).setSeq(2).setType("Condition").setField("A").setRelation("BEGIN");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
E2.setResult(false);
list.set(1,E2);
Assertions.assertFalse(expressProcessor(list));
}测试结果:
写在最后
至此,一个表达式解析就完成了,让我们回过来再看这张图:
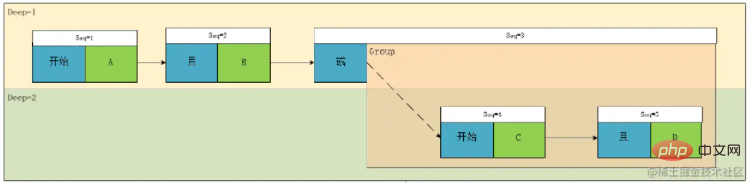
我们可以发现,其实Seq3 的作用其实仅仅是标识了一个组的开始并记录该组与同级别的其他元素的关联关系,其实,这里还可以进行一次优化:我们发现每当一个组的开始的第一个节点其前置关联关系一定是Begin,Deep+1,实际上我们可以考虑将Group的关联关系放在这个节点上,然后仅仅通过Deep的增减控制组的关系,这样,我们就不需要类型为表达式或组的这个字段了,而且数组长度也会因此减少,但是个人认为理解起来会麻烦一点。这里说一下大概改造思路,代码就不放出来了:
- 将代码中有关Type="GROUP"的判断改为通过deep的差值=1进行判断
- 深度判断入栈逻辑修改
- 在存储关系符号的时候还要存储一下这个关系符号对应的深度
- 在处理同深度遗留元素时,即:
computeBeforeEndGroup()方法中, 原方法是通过Begin元素进行区分Group是否处理完成,现需要改成通过下一个符号的深度是否和当前深度是否相同进行判断,并删除掉有关BEGIN元素的弹出的逻辑
推荐学习:《java视频教程》
以上是实例介绍基于Java实现一个复杂关系表达式过滤器的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

Atom编辑器mac版下载
最流行的的开源编辑器

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

Dreamweaver CS6
视觉化网页开发工具

