
完全掌握MySQL主从延迟的解决方法

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB转载
- 2022-06-29 15:03:563260浏览
本篇文章给大家带来了关于mysql的相关知识,其中主要整理了主从延迟的解决方法相关问题,包括了什么是主从延迟、主从延迟的来源、主从延迟的解决方案等等内容,下面一起来看一下,希望对大家有帮助。

推荐学习:mysql视频教程
之前项目中基于 MySQL 主从复制以及 AOP 的方式实现了读写分离,也写了博客记录了这个实现过程。既然配置了 MySQL 主从复制,那么自然会存在主从延迟,如何尽可能减小主从延迟对应用系统的影响是很有必要的思考点,我个人认为主从延迟的解决方案正是实现读写分离、MySQL 主从复制的精髓。
关于这个话题其实我之前就想着写篇博客分享一下,但一直没有提上日程。最近有读者在《SpringBoot实现MySQL读写分离》 中留言问到了这个问题,这也激励我写下了本文。关于这个问题,我阅读了很多资料和博客,并经过自己的实践实操,站在大佬的肩膀上总结下了这篇博客。
什么是主从延迟
在讨论如何解决主从延迟之前,我们先了解下什么是主从延迟。
为了完成主从复制,从库需要通过 I/O 线程获取主库中 dump 线程读取的 binlog 内容并写入到自己的中继日志 relay log 中,从库的 SQL 线程再读取中继日志,重做中继日志中的日志,相当于再执行一遍 SQL,更新自己的数据库,以达到数据的一致性。
与数据同步有关的时间点主要包括以下三个:
- 主库执行完一个事务,写入 binlog,将这个时刻记为 T1;
- 之后传给从库,将从库接收完这个 binlog 的时刻记为 T2;
- 从库执行完成这个事务,将这个时刻记为 T3。
所谓主从延迟,就是同一个事务,从库执行完成的时间与主库执行完成的时间之差,也就是 T3 - T1。
可以在备库上执行 show slave status 命令,它的返回结果里面会显示 seconds_behind_master,用于表示当前备库延迟了多少秒。seconds_behind_master 的计算方法是这样的:
- 每个事务的 binlog 里面都有一个时间字段,用于记录主库上写入的时间;
- 备库取出当前正在执行的事务的时间字段的值,计算它与当前系统时间的差值,得到
seconds_behind_master。
在网络正常的时候,日志从主库传给从库所需的时间是很短的,即 T2 - T1 的值是非常小的。也就是说,网络正常情况下,主从延迟的主要来源是从库接收完 binlog 和执行完这个事务之间的时间差。
由于主从延迟的存在,我们可能会发现,数据刚写入主库,结果却查不到,因为可能还未同步到从库。主从延迟越严重,该问题也愈加明显。
主从延迟的来源
主库和从库在执行同一个事务的时候出现时间差的问题,主要原因包括但不限于以下几种情况:
- 有些部署条件下,从库所在机器的性能要比主库性能差。
- 从库的压力较大,即从库承受了大量的请求。
- 执行大事务。因为主库上必须等事务执行完成才会写入 binlog,再传给备库。如果一个主库上语句执行 10 分钟,那么这个事务可能会导致从库延迟 10 分钟。
- 从库的并行复制能力。
主从延迟的解决方案
解决主从延迟主要有以下方案:
- 配合 semi-sync 半同步复制;
- 一主多从,分摊从库压力;
- 强制走主库方案(强一致性);
- sleep 方案:主库更新后,读从库之前先 sleep 一下;
- 判断主备无延迟方案(例如判断
seconds_behind_master参数是否已经等于 0、对比位点); - 并行复制 — 解决从库复制延迟的问题;
这里主要介绍我在项目中使用的几种方案,分别是半同步复制、实时性操作强制走主库、并行复制。
semi-sync 半同步复制
MySQL 有三种同步模式,分别是:
「异步复制」:MySQL 默认的复制即是异步的,主库在执行完客户端提交的事务后会立即将结果返给客户端,并不关心从库是否已经接收并处理。这样就会有一个问题,一旦主库宕机,此时主库上已经提交的事务可能因为网络原因并没有传到从库上,如果此时执行故障转移,强行将从提升为主,可能导致新主上的数据不完整。
「全同步复制」:指当主库执行完一个事务,并且所有的从库都执行了该事务,主库才提交事务并返回结果给客户端。因为需要等待所有从库执行完该事务才能返回,所以全同步复制的性能必然会收到严重的影响。
「半同步复制」:是介于全同步复制与全异步复制之间的一种,主库只需要等待至少一个从库接收到并写到 Relay Log 文件即可,主库不需要等待所有从库给主库返回 ACK。主库收到这个 ACK 以后,才能给客户端返回 “事务完成” 的确认。
MySQL 默认的复制是异步的,所以主库和从库的数据会有一定的延迟,更重要的是异步复制可能会引起数据的丢失。但是全同步复制又会使得完成一个事务的时间被拉长,带来性能的降低。因此我把目光转向半同步复制。从 MySQL 5.5 开始,MySQL 以插件的形式支持 semi-sync 半同步复制。
相对于异步复制,半同步复制提高了数据的安全性,减少了主从延迟,当然它也还是有一定程度的延迟,这个延迟最少是一个 TCP/IP 往返的时间。所以,半同步复制最好在低延时的网络中使用。
需要注意的是:
- 主库和从库都要启用半同步复制才会进行半同步复制功能,否则主库会还原为默认的异步复制。
- 如果在等待过程中,等待时间已经超过了配置的超时时间,没有收到任何一个从库的 ACK,那么此时主库会自动转换为异步复制。当至少一个半同步从节点赶上来时,主库便会自动转换为半同步复制。
半同步复制的潜在问题
在传统的半同步复制中(MySQL 5.5 引入),主库写数据到 binlog,并且执行 commit 提交事务后,会一直等待一个从库的 ACK,即从库写入 Relay Log 后,并将数据落盘,再返回给主库 ACK,主库收到这个 ACK 以后,才能给客户端返回 “事务完成” 的确认。
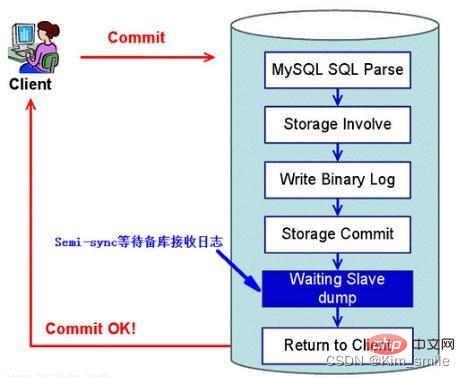
这样会出现一个问题,就是实际上主库已经将该事务 commit 到了存储引擎层,应用已经可以看到数据发生了变化,只是在等待返回而已。如果此时主库宕机,可能从库还没写入 Relay Log,就会发生主从库数据不一致。
为了解决上述问题,MySQL 5.7 引入了增强半同步复制。针对上面这个图,“Waiting Slave dump” 被调整到了 “Storage Commit” 之前,即主库写数据到 binlog 后,就开始等待从库的应答 ACK,直到至少一个从库写入 Relay Log 后,并将数据落盘,然后返回给主库 ACK,通知主库可以执行 commit 操作,然后主库再将事务提交到事务引擎层,应用此时才可以看到数据发生了变化。
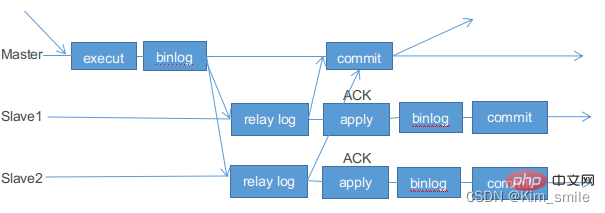
当然之前的半同步方案同样支持,MySQL 5.7.2 引入了一个新的参数
rpl_semi_sync_master_wait_point进行控制。这个参数有两种取值:
- AFTER_SYNC:这个是新的半同步方案,Waiting Slave dump 在 Storage Commit 之前。
- AFTER_COMMIT:这个是老的半同步方案。
在 MySQL 5.5 - 5.6 使用 after_commit 的模式下,客户端事务在存储引擎层提交后,在主库等待从库确认的过程中,主库宕机了。此时,结果虽然没有返回给当前客户端,但事务已经提交了,其他客户端会读取到该已提交的事务。如果从库没有接收到该事务或者未写入 relay log,同时主库宕机了,之后切换到备库,那么之前读到的事务就不见了,出现了幻读,也就是数据丢失了。
MySQL 5.7 默认值则是 after_sync,主库将每个事务写入 binlog,传给从库并刷新到磁盘 (relay log)。主库等到从库返回 ack 之后,再提交事务并且返回 commit OK 结果给客户端。 即使主库 crash,所有在主库上已经提交的事务都能保证已经同步到从库的 relay log 中,解决了 after_commit 模式带来的幻读和数据丢失问题,故障切换时数据一致性将得到提升。因为从库没有写入成功的话主库也不会提交事务。并且在 commit 之前等待从库 ACK,还可以堆积事务,有利于 group commit 组提交,有利于提升性能。
但这样也会有个问题,假设主库在存储引擎提交之前挂了,那么很明显这个事务是不成功的,但由于对应的 Binlog 已经做了 Sync 操作,从库已经收到了这些 Binlog,并且执行成功,相当于在从库上多了数据(从库上有该数据而主库没有),也算是有问题的,但多了数据一般不算严重的问题。它能保证的是不丢数据,多了数据总比丢数据要好。
一主多从
如果从库承担了大量查询请求,那么从库上的查询操作将耗费大量的 CPU 资源,从而影响了同步速度,造成主从延迟。那么我们可以多接几个从库,让这些从库来共同分担读的压力。
简而言之,就是加机器,方法简单粗暴,但也会带来一定成本。
强制走主库方案
如果某些操作对数据的实时性要求比较苛刻,需要反映实时最新的数据,比如说涉及金钱的金融类系统、在线实时系统、又或者是写入之后马上又读的业务,这时我们就得放弃读写分离,让此类的读请求也走主库,这就不存延迟问题了。
当然这也失去了读写分离带给我们的性能提升,需要适当取舍。
并行复制
一般 MySQL 主从复制有三个线程参与,都是单线程:Binlog Dump 线程、IO 线程、SQL 线程。复制出现延迟一般出在两个地方:
- SQL 线程忙不过来(主要原因);
- 网络抖动导致 IO 线程复制延迟(次要原因)。
日志在备库上的执行,就是备库上 SQL 线程执行中继日志(relay log)更新数据的逻辑。
在 MySQL 5.6 版本之前,MySQL 只支持单线程复制,由此在主库并发高、TPS 高时就会出现严重的主备延迟问题。从 MySQL 5.6 开始有了多个 SQL 线程的概念,可以并发还原数据,即并行复制技术。这可以很好的解决 MySQL 主从延迟问题。
从单线程复制到最新版本的多线程复制,中间的演化经历了好几个版本。其实说到底,所有的多线程复制机制,都是要把只有一个线程的 sql_thread,拆成多个线程,也就是都符合下面的这个多线程模型:
coordinator 就是原来的 sql_thread,不过现在它不再直接更新数据了,只负责读取中转日志和分发事务。真正更新日志的,变成了 worker 线程。而 worker 线程的个数,就是由参数 slave_parallel_workers 决定的。
由于 worker 线程是并发运行的,为了保证事务的隔离性以及不会出现更新覆盖问题,coordinator 在分发的时候,需要满足以下这两个基本要求:
- 更新同一行的两个事务,必须被分发到同一个 worker 中(避免更新覆盖)。
- 同一个事务不能被拆开,必须放到同一个 worker 中(保证事务隔离性)。
各个版本的多线程复制,都遵循了这两条基本原则。
以下是按表分发策略和按行分发策略,可以帮助理解 MySQL 官方版本并行复制策略的迭代:
-
按表分发策略:如果两个事务更新不同的表,它们就可以并行。因为数据是存储在表里的,所以按表分发,可以保证两个 worker 不会更新同一行。
- 按表分发的方案,在多个表负载均匀的场景里应用效果很好,但缺点是:如果碰到热点表,比如所有的更新事务都会涉及到某一个表的时候,所有事务都会被分配到同一个 worker 中,就变成单线程复制了。
-
按行分发策略:如果两个事务没有更新相同的行,则它们在备库上可以并行。显然,这个模式要求 binlog 格式必须是 row。
- 按行并行复制的方案解决了热点表的问题,并行度更高,但缺点是:相比于按表并行分发策略,按行并行策略在决定线程分发的时候,需要消耗更多的计算资源。
MySQL 5.6 版本的并行复制策略
MySQL 5.6 版本,支持了并行复制,只是支持的粒度是按库并行(基于 Schema)。
其核心思想是:不同 schema 下的表并发提交时的数据不会相互影响,即从库可以对 relay log 中不同的 schema各分配一个类似 SQL 线程功能的线程,来重放 relay log 中主库已经提交的事务,保持数据与主库一致。
如果在主库上有多个 DB,使用这个策略对于从库复制的速度可以有比较大的提升。但通常情况下都是单库多表,那基于库的并发也就没有什么作用,根本无法并行重放,所以这个策略用得并不多。
MySQL 5.7 的并行复制策略
MySQL 5.7 引入了基于组提交的并行复制,参数 slave_parallel_workers 设置并行线程数,由参数 slave-parallel-type 来控制并行复制策略:
- 配置为 DATABASE,表示使用 MySQL 5.6 版本的按库并行策略;
- 配置为 LOGICAL_CLOCK,表示使用基于组提交的并行复制策略;
利用 binlog 的组提交 (group commit) 机制,可以得出一个组提交的事务都是可以并行执行的,原因是:能够在同一组里提交的事务,一定不会修改同一行(由于 MySQL 的锁机制),因为事务已经通过锁冲突的检验了。
基于组提交的并行复制具体流程如下:
- 在一组里面一起提交的事务,有一个相同的 commit_id,下一组就是 commit_id+1;commit_id 直接写到 binlog 里面;
- 传到备库应用的时候,相同 commit_id 的事务分发到多个 worker 执行;
- 这一组全部执行完成后,coordinator 再去取下一批执行。
所有处于 prepare 和 commit 状态的事务都是可以在备库上并行执行的。
binlog 的组提交的两个有关参数:
- binlog_group_commit_sync_delay 参数,表示延迟多少微秒后才调用 fsync 刷盘;
- binlog_group_commit_sync_no_delay_count 参数,表示累积多少次以后才调用 fsync。
这两个参数是用于故意拉长 binlog 从 write 到 fsync 的时间,以此减少 binlog 的写盘次数。在 MySQL 5.7 的并行复制策略里,它们可以用来制造更多的“同时处于 prepare 阶段的事务”。可以考虑调整这两个参数值,来达到提升备库复制并发度的目的。
推荐学习:mysql视频教程
以上是完全掌握MySQL主从延迟的解决方法的详细内容。更多信息请关注PHP中文网其他相关文章!